
我是 Harish SG,一名在德克萨斯大学达拉斯分校攻读网络安全硕士学位的安全研究员,目前在思科担任 AI 安全工程师,曾经参与过微软漏洞赏金计划和谷歌 VRP 项目。
我分享这篇文章主要是为了提升公众意识和进行教育交流,所表达的观点纯属个人立场,与我在思科的工作立场无关。
免责声明:我并非 AI 领域的研究员或专家,只是专注于大语言模型安全方面的研究。我的研究完全基于对 LLM 及其功能特性的个人理解和分析。
本文专注于我近期在 AI 领域的调研,旨在推动开源模型达到甚至超越闭源模型的性能,特别是提升当前顶尖模型——如 Claude Sonnet 3.5——的推理能力,使其能够与 OpenAI 的 O1-preview 和 O1-mini 模型相媲美(OpenAI 宣称这些模型具备相当于博士级专家的智能水平)。
什么是 LLM 推理?
LLM 推理指的是模型的这些能力:
逻辑思考;
做出推断;
解决复杂问题;
根据可用信息做出合理的决策。
尽管大语言模型并没有专门被训练用于执行推理任务,但它们有时候表现出类似推理的能力。
为什么 LLM 推理很重要?
LLM 推理能力之所以重要,有这几个原因:
更深入的理解:如果 LLM 展现出真正的推理能力,将意味着它们能够超越简单的模式识别,对世界有更深刻的洞察力。
问题解决:提升推理能力将使得 LLM 在处理复杂问题时更加高效。
决策制定:具有强大推理能力的 LLM 能够在人类面临复杂决策时提供有价值的辅助。
泛化:增强的推理能力将助力 LLM 在未曾遇见过的任务上表现得更为出色,提高它们的泛化水平。
实际应用:推理能力的增强可以推动科学探索、政策制定和教育、医疗等领域个性化服务的进步。例如,设想一个自主 AI 智能体,它接收时间序列数据集,可以识别出难以察觉或耗时的模式,并利用这些信息进行精准的预测。
当 OpenAI 推出 O1 和 O1-mini 时,我意识到,如果 AI 能够通过深入思考来解决更复杂的问题,这将是向人工通用智能(AGI)迈出的一大步,也是利用 AI 解决复杂问题的创新。后来,我突发奇想:如果我们能够提升当前顶尖模型——比如 Claude Sonnet 3.5——的推理能力,使其达到甚至超越 O1 模型的水平,那将会怎样呢?
在阅读了一些资料,如东北大学的“反思”论文和 reddit 上的一些评论后,我决定创建一种新的提示词范式,结合动态思维链 + 反思 + 口头强化,尝试将其作为一个实验来付诸实践。
编码和解决数学问题的提示词示例:
Begin by enclosing all thoughts within
tags, exploring multiple angles and approaches. Break down the solution into clear steps within
tags. Start with a 20-step budget, requesting more for complex problems if needed. Use
tags after each step to show the remaining budget. Stop when reaching 0. Continuously adjust your reasoning based on intermediate results and reflections, adapting your strategy as you progress.
Regularly evaluate progress using
tags. Be critical and honest about your reasoning process. Assign a quality score between 0.0 and 1.0 using
tags after each reflection. Use this to guide your approach: 0.8+: Continue current approach
0.5-0.7: Consider minor adjustments
Below 0.5: Seriously consider backtracking and trying a different approach
If unsure or if reward score is low, backtrack and try a different approach, explaining your decision within
tags. For mathematical problems, show all work explicitly using LaTeX for formal notation and provide detailed proofs.
Explore multiple solutions individually if possible, comparing approaches in reflections.
Use thoughts as a scratchpad, writing out all calculations and reasoning explicitly.
Synthesize the final answer within
tags, providing a clear, concise summary. Conclude with a final reflection on the overall solution, discussing effectiveness, challenges, and solutions. Assign a final reward score.
提示词范式解释
动态思维链、反思和口头强化学习相结合,创建了一个具有高度适应性和响应性的问题解决系统。这个过程从思维链生成初始推理路径开始,然后通过反思机制进行评估和完善。在每个反思阶段之后,模型以奖励分数(用于指导未来的推理步骤)的形式接收口头强化。
这个循环过程使得模型能够不断优化输出,适应不断变化的条件,并有效应对复杂的场景。例如,在涉及多阶段决策的复杂任务中,如自动驾驶导航,模型可能会首先采用动态思维链来探索可能的行动路径。
在遇到障碍或环境发生变化时,反思机制使其能够重新评估并调整策略,而口头强化分数则提供了具体的行动调整指导。这就有了一个能够从经验中持续学习并不断进步的 AI 系统,随着时间的推移,其推理能力得到显著提升,在应对动态变化的真实世界问题时展现出更加强大的问题解决技能。
提示词范式的基准测试
我想知道这个提示词范式的有效性,尽管已经能够回答经典的问题,如“计算单词 strawberry 中 r 的个数”和“比较 0.9 和 0.11 哪个更大”等。
据我所知,只有 O1 和 O1 mini 能够全部回答正确,得益于它们内部的推理机制。
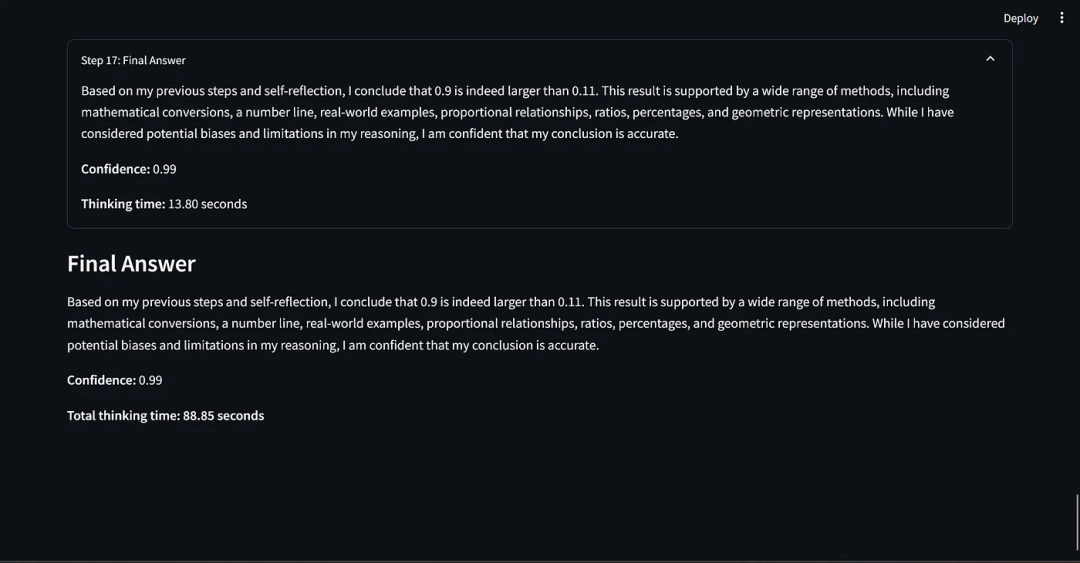
我为基准测试创建了两组数据集。
第一组数据集来自 JEE Advanced(联合入学考试)和 UPSC(印度公务员考试)预选考试。
JEE Advanced 被认为是全球最难的本科入学考试之一,专为那些有志于进入印度最顶尖学府——印度理工学院的学生而设。
UPSC 公务员考试被誉为全球竞争最激烈的考试之一,吸引了众多希望在印度政府机构中担任行政职务的考生。其综合性的通识测试覆盖了广泛的知识领域,可以作为对大语言模型进行严格和全面评估的有效工具。
这些问题设计得非常严格,旨在深入考察考生的概念理解、问题解决能力,以及在物理、数学、化学、社会科学等多个领域应用知识的能力。
用于评估的工具和脚本:
脚本使用 Streamlit 创建一个 Web 应用程序,通过 Groq API 为开源模型生成 AI 响应,通过其他 API 为闭源模型,如 gpt4o、o1 和 Claude 生成响应。
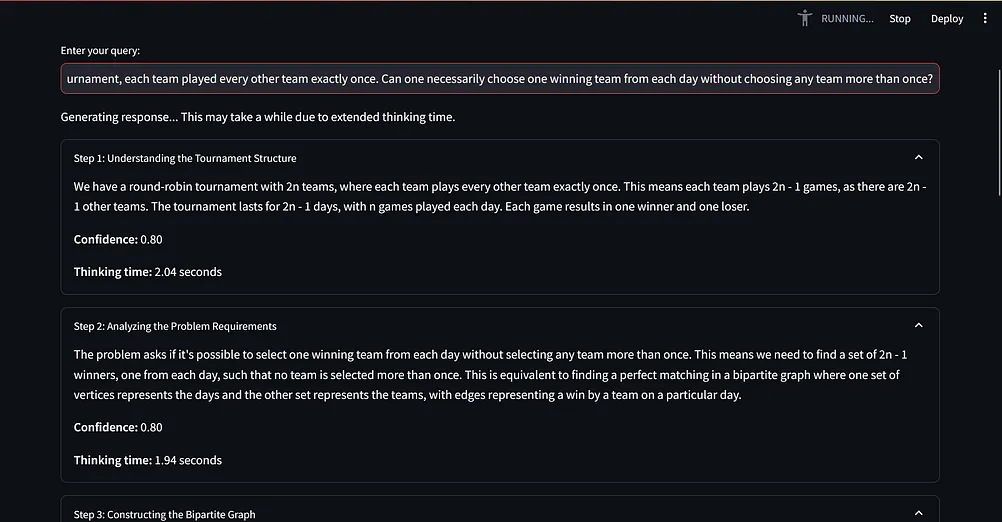
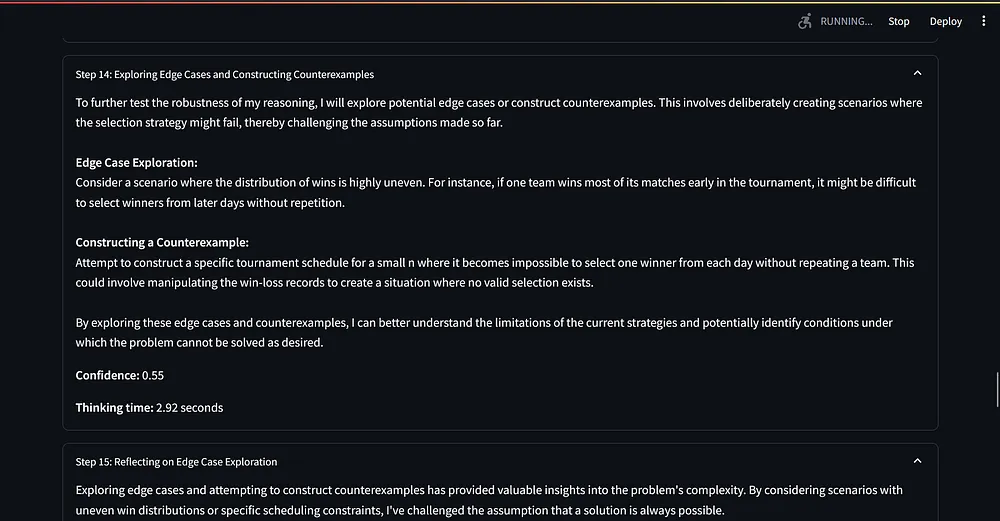
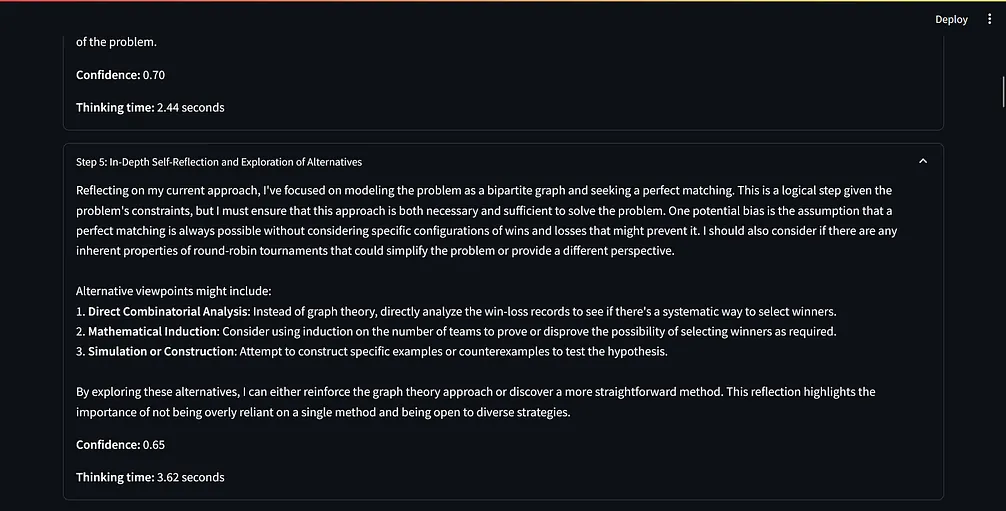
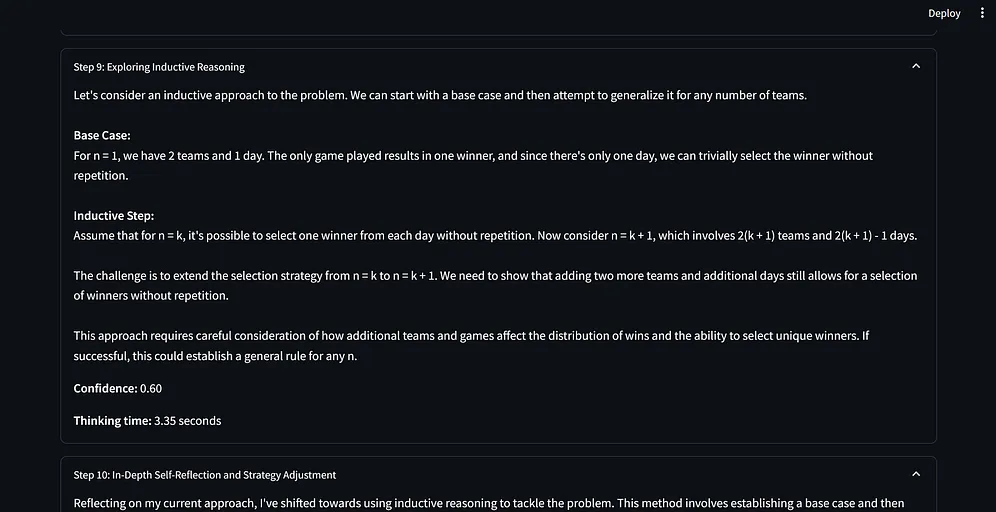
它包含了一个系统提示词(从“你是一个 AI 助手,需要一步一步解释你的推理过程……”开始),用于指导 AI 的推理过程。
这个提示词指示 AI 使用动态思维链、反思和口头强化学习技术。
AI 将其推理分解为清晰的步骤,每个步骤都有标题、内容、置信度分数和思考时间。
每经过三个步骤,AI 都会进行一次自我反思,考虑潜在的偏见和不同的观点。
脚本在得出最终答案之前至少执行 15 个步骤,确保对给定的查询进行彻底的分析。
我修改了 Benjamin Klieger 的脚本,其原始版本在这里:https://github.com/bklieger-groq/g1。
为了实现这些逻辑,我对原始版本进行了修改。用户向 AI 系统提出一个问题,系统需要提供足够的时间从多种角度思考问题,并最终给出解决方案。在这一过程中,我尝试模仿人类解决复杂问题时的思考方式,将其应用于 AI 系统中。这一灵感来源于 Aravind Srinivas 在接受 Lex Fridman 采访时所分享的观点。
基准测试结果分析
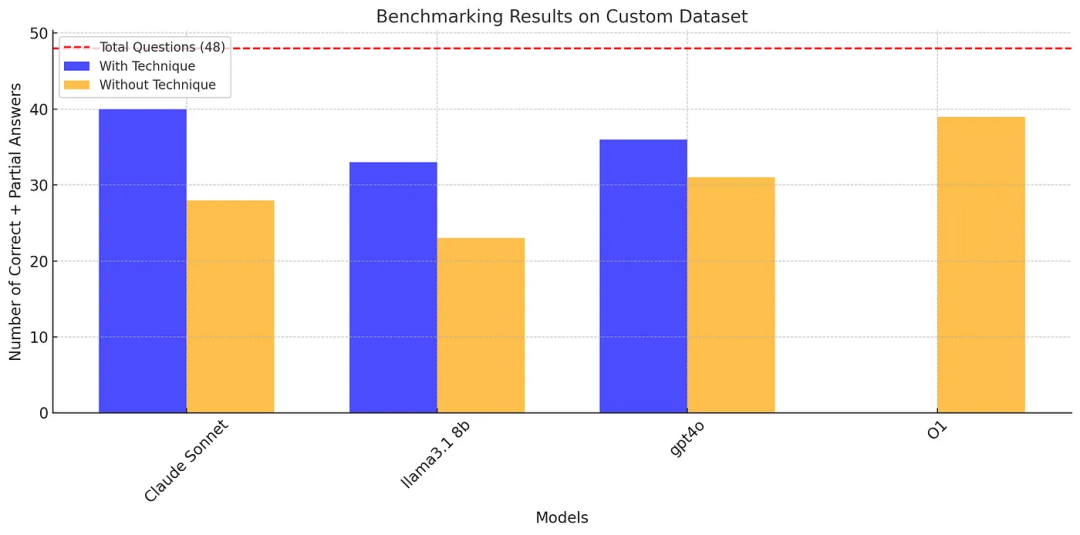
结果表明,应用动态思维链、反思和口头强化学习技术显著提升了大多数模型的性能,特别是 Claude Sonnet 和 Llama 3.1 8b。
A. 应用了这个范式的 Claude Sonnet 获得了最高分(40/48),在数学、物理和化学问题上表现出色。Llama 3.1 8b(33/48)和 GPT-4O(36/48)的表现在应用了这个范式后也得到了显著改进。
B. 在没有应用这个范式的情况下,除了 O1,所有模型的表现都有所下降。值得注意的是,O1 在没有应用任何范式的情况下得分为 39/48,表明其具有强大的固有问题解决能力。
可以看出,Claude Sonnet 3.5 有能力超越 O1。
这个基准测试有点宽松,即对于部分正确的答案也给了分数。
注意:在进行这次基准测试时,Meta 还没有发布 llama 3.2。
OpenAI 声称 O1 在国际数学奥林匹克问题上能够获得 83% 的分数。使用我们的提示词范式,Claude Sonnet 在第一次尝试中能够获得 50% 的分数,如果多次尝试,Claude Sonnet 3.5 有可能会超越 O1。



针对 Putnam 数据集的基准测试
什么是 Putnam 数学竞赛?
William Lowell Putnam 数学竞赛,通常被称为 Putnam 竞赛,是美国和加拿大本科生极具挑战性的数学竞赛。以下是竞赛的关键点及其难度评级。
竞赛结构:
在每年 12 月的第一个星期六举行。
包括两个持续 3 个小时的环节,每个环节有 6 个问题。
每个问题分值为 10 分,最高总分为 120 分。
难度评级:
Putnam 竞赛被认为是全球最难的本科数学竞赛之一,其难度可以通过以下几个方面看出:
中位数分数:中位数分数通常为 0 或 1 分(满分 120 分)。这意味着超过一半的参与者要么完全解决不了问题,要么最多解决一个问题。
在竞赛的 85 年历史中,仅有五位参赛者荣获满分,这一事实突显了攻克所有竞赛题目的非凡挑战。
因此,如果以 1 至 10 的评分作为标准,10 代表最难,那么 Putnam 竞赛在本科数学竞赛中的难度评级应为 9 或 10。
我从 2013 年到 2023 年的 Putnam 竞赛试卷中挑选了大约 28 个问题。
基准测试结果分析
在这个基准测试中,llama3.1 70B、Claude Sonnet 和 o1 mini 解决了 14 个问题,而 O1 解决了 13 个问题,gpt4o 解决了 9 个问题。
乍一看,这个结果似乎好得令人难以置信!
我相信 gpt4o 表现不佳是因为它创建了 50 到 60 个推理链循环,最终给出了一些无意义的答案。
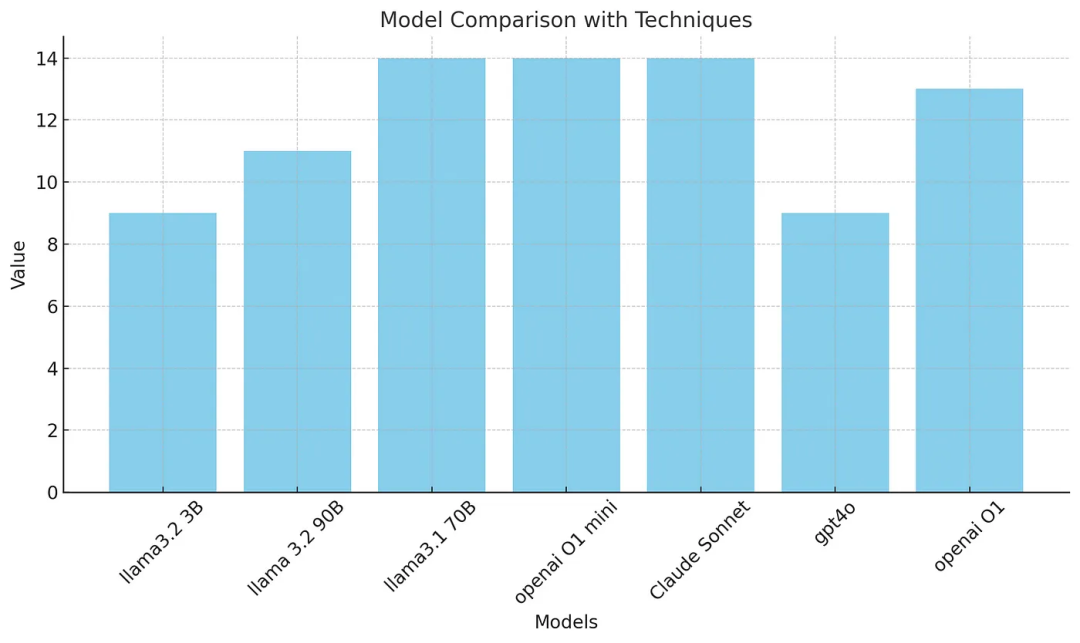
从上述的基准测试可以看到,采用我们的提示词范式后,Claude Sonnet 3.5 在需要较强推理能力的问题上表现优于 O1 和 O1 mini 以及其他小模型。
因此,我建议使用这种提示词范式作为系统提示词来获得更好的表现。
坦白讲,我目前没有足够的计算资源或预算来运行标准基准测试,如 MMLU、MMLU Pro、GPQA 等,如果有人想运行这些测试,请自便。同时,我已将本实验中使用的脚本、数据集以及一些证明过程开源。
代码仓库:https://github.com/harishsg993010/LLM-Research-Scripts
从这次实验中观察到的有关 LLM 的能力和现象:
LLM 能够创建自己的模拟场景。当我提出一个与矩阵相关的问题时,它探索了各种技术来解决问题,并在某个阶段开始根据不同情景构建自己的模拟场景来解决问题。
一些 LLM,如 Claude Sonnet 3.5、gpt4o 在解决复杂数学问题时需要超过 50 个内部推理步骤。
LLM 在回答多项选择题时表现得比回答开放式问题更为出色。
Claude Sonnet 3.5 解决 7 个问题就用掉了大约 100 万个 Token,之后我在实验中使用了 openrouter。
结 论
我认为大语言模型就像是一个阅读过数百万本书籍的人类,只是它还不知道如何利用这些数据来解决问题。因此,作为 LLM 的研究者和使用者,我们需要教会 LLM 如何利用这些知识来解决问题。
这种推理能力可以被应用于构建高效的工作流自动化,以应对 IT、网络安全、汽车等多个领域的问题。
企业可以部署较小的开源模型作为大模型(例如 gpt4o)的替代方案,用于处理需要推理能力的任务。
我知道,这个实验中的一些结果可能显得过于理想,有点令人难以置信。如果有人想再次进行验证,欢迎使用 GitHub 上的脚本和数据集。
原文链接:
声明:本文由 InfoQ 翻译,未经许可禁止转载。




