
历史累积的测试套件既测试得太多也测试得太少
软件系统的特性通常随着版本的发布不断增长,它们的测试套件也是如此。这会导致测试执行时间变得越来越长。对于手动测试来说,这意味着测试人员要付出更多的努力,从而直接导致更高的成本。对于自动化测试,这意味着开发人员在得到测试结果之前需要等待更长的时间。我们看到许多自动化测试套件的执行时间从几分钟到几小时增加到几天甚至几周,特别是当涉及到硬件时。这种缓慢的速度令人感到煎熬,会间接导致更高的成本,修复两周前出现的问题比修复一小时前出现的问题更难,因为在这期间发生了更多的变化。
具有讽刺意味的是,成本如此之高的测试套件通常在发现 Bug 方面表现不佳。一方面,被测试的软件经常会有些部分不会被测试到。另一方面,它们通常包含了大量的冗余,测试到的部分会被重复测试。这些部分的 Bug 会导致成百上千的测试失败。因此,这些测试套件既不有效(因为它们测试不到某些部分)也不高效(因为它们包含冗余测试)。
当然,这并不是一个新发现。大多数团队早就放弃了针对每一个变更执行整个测试套件,甚至也不针对每一个新发布版本执行整个测试套件。相反,他们要么每隔几周执行一次(这会延迟发现 Bug,导致修复它们的成本变得更高),要么只执行测试套件的子集(这会遗漏许多本可以被发现的 Bug)。
本文提供了更好的解决方案,使用来自被测系统和测试本身的数据来优化测试工作。团队可以在更短的时间内(通过减少执行不太可能检测到 Bug 的测试)发现更多的 Bug(确保测试了 Bug 密集区域)。
通过分析开发过程数据来优化测试
如果一个测试套件效率低下,那么其后果对开发和测试团队来说是显而易见的:测试工作量很大,但仍然会有很多 Bug 不会被发现,并进入生产环境。
然而,由于在大型组织中,没有人拥有完整的信息,对于如何解决这个问题(或者是谁的错),通常会有不同的——经常是冲突的——意见。基于部分信息提出的观点很难被证实或反驳,如果人们把注意力放在与他们的观点相一致的东西上,而不是大局,那么团队(或团队的团队)在很长一段时间内都不会有改进。
例如,有时候,经验丰富的测试人员会责怪开发人员在实现新特性时破坏了太多现有功能。作为回应,测试人员将更多的精力放在回归测试上。与此同时,开发人员指责测试人员测试新功能 Bug 的速度太慢。随着测试人员把更多的精力放在回归测试上,新特性中的 Bug 会在更晚的时候才有可能被发现。由于开发人员很晚才发现新特性中的 Bug,所以修复通常是在回归测试完成之后。如果这样的修复在不同的位置导致 Bug 出现,测试人员就没有机会通过回归测试捕获它们。
具有讽刺意味的是,这种局面为两个团队的观点提供了支撑,让两个团队更加认为他们的观点是正确的,但这也让问题变得更糟。
这些团队必须停止争论一般性的问题,比如原则上需要多少回归测试,他们要做的是看一下数据,看看现在一个特定的变更需要哪些测试。软件存储库,如版本控制系统、问题跟踪器或持续集成系统,包含了大量与软件相关的数据,这些数据可以帮助我们基于数据而不是意见对测试做出优化。
为此,我们基本上可以对在软件开发期间收集了大量数据的存储库进行分析,这样就可以得出一些与测试过程有关的问题的答案。
过去哪里出现的 Bug 最多?我们可以从中了解到什么?
版本历史记录和问题跟踪器包含了过去在哪里修复过 Bug 的信息。这些信息可以被提取出来,并用于计算不同组件的 Bug 密度。
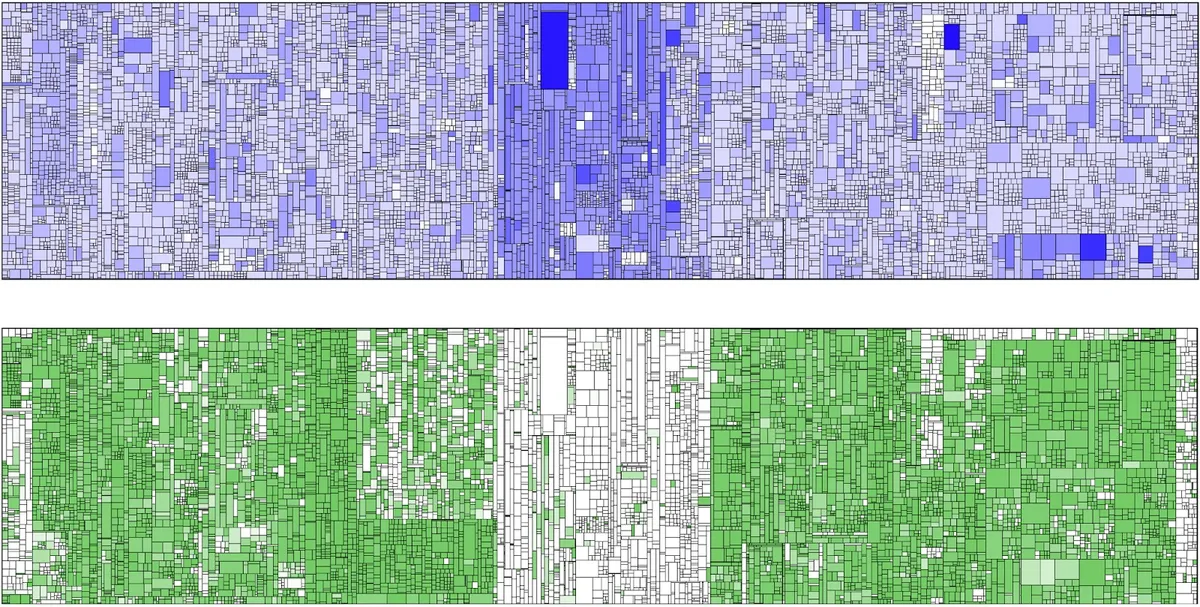
这显示了在一个系统中,一个组件的每行代码修复密度比系统平均修复密度高了一个数量级,如上面的蓝色矩形树图所示。每个矩形代表一个文件,其面积与文件的代码行数相对应。蓝色阴影越深,表示这个文件越是经常进行 Bug 修复。
在矩形树图的中心位置有一簇文件,蓝色比其他部分更深。
下面的矩形树图显示了自动化测试的覆盖范围。白色表示未覆盖,绿色表示测试覆盖的增加(绿色越深表示覆盖越多)。值得注意的是,中心的组件包含了大量的历史 Bug,但几乎没有被自动化测试覆盖。
经过与团队的讨论,发现了这个组件测试过程的一个系统性问题:开发人员已经为其他所有组件编写了单元测试,但缺少为这个组件编写单元测试的测试框架。开发人员已经提了一个改进测试框架的 Ticket。在实现所需的测试框架之前,他们系统性地跳过了为这个组件编写的单元测试。由于团队不知道这些 Bug 的影响,导致 Ticket 一直呆在 backlog 没有被解决。
在上述的分析揭示了 Bug 的影响之后,Ticket 很快就得到了解决,并编写了缺失的单元测试。在此之后,这个组件中的新 Bug 数量不再高于其他组件。
未测试的变更(测试间隙)在哪里
测试间隙(Gap)是指未被测试到的新代码或修改过的代码的区域。团队通常会特别仔细地尝试测试新代码和修改过的代码,因为从直觉(和经验研究)上看,它们比没有被修改的代码区域包含更多的 Bug。
测试间隙分析通过结合两个数据源来揭示测试间隙:版本控制系统和代码覆盖信息。
首先,我们从版本控制系统中计算两个软件版本(例如上一个版本和要发布的下一个版本)之间的所有变更,因为根据我们的直觉(和经验研究)认为这些区域是最容易出错的。

这个矩形树图描绘的是一个包含大约 150 万行代码的业务信息系统。30 名开发人员花了 6 个月的时间来准备下一个版本。每个白色矩形表示一个组件,每个黑色矩形表示一个代码函数。组件和函数的面积与代码行数相对应。灰色矩形中的代码自上次发布以来没有发生变化。红色矩形是新代码,橙色矩形是修改过的代码。树图显示了哪些区域变化相对较小(例如左半部分),哪些区域变化很大(例如右侧的组件)。
其次,我们收集了所有测试覆盖率数据。收集过程是完全自动化的,不管是对于自动测试还是手动测试来说。更具体地说,我们使用代码覆盖概要来捕获发生的所有测试活动的测试覆盖信息。不同的编程语言甚至是不同的编译器可能需要不同的分析器,但它们通常适用于所有较为流行的编程语言。

这个树图显示了上述系统的测试覆盖率。它结合了自动化测试(在本例中是单元测试和集成测试)和手动测试(5 名测试人员花了一个月执行手动系统级回归测试)的覆盖范围。灰色矩形表示测试期间未被执行的函数,绿色矩形表示已被执行的函数。
最后,我们将这些信息结合起来,找到那些没有被测试到的变更,从而找出所谓的测试间隙。

在这个树图中,我们并不关心没有发生变更的代码。因此,它们使用灰色表示(与测试期间是否被执行无关)。新代码和修改过的代码用不同的颜色表示:如果是在测试期间执行的,则用绿色表示。如果不是,则新代码用红色表示,修改的代码用橙色表示。
在这个例子中(在计划发布日期的前一天),我们看到几个组件(包含数万行代码)在测试期间根本没有被执行。
团队可以基于测试间隙分析慎重决定是否要将这些测试间隙(即未测试的新代码或修改过的代码)交付到生产环境中。在某些情况下,这不是问题(例如,如果未测试的功能还没有被使用),但通常情况下最好要对关键功能进行额外的测试。
在上面的例子中,团队决定不发布,因为未被测试的功能非常重要。发布被推迟了三周,大多数测试间隙被数以千计额外的(手动和自动)测试用例覆盖到了,他们因此可以捕捉(并修复)关键的 Bug。
现在哪些测试最有价值
如果我们对代码变更和测试覆盖率进行持续的分析,就可以自动计算出自上次测试套件执行以来哪些代码发生了变更。我们可以明确地选择那些执行了这些代码区域的测试用例。相比重新运行所有测试,运行这些受影响的测试用例能够更快地发现新 Bug(因为不涉及变更的测试无法发现由这些变更引入的新 Bug)。
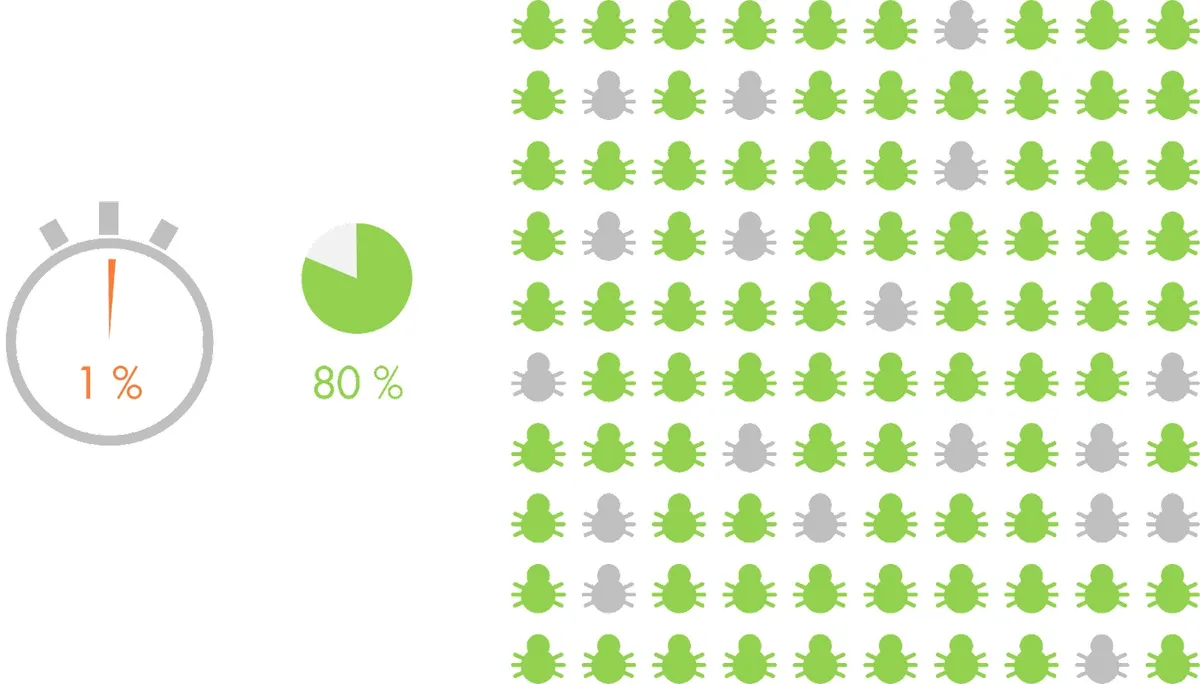
这种测试影响分析加速了开发人员的反馈。根据我们的经验,我们发现我们可以在 1%的时间(运行整个测试套件所花费的时间)内发现 80%的 Bug(运行整个测试套件所能发现的 Bug),或者在 2%的时间内发现 90%的 Bug(关于变更驱动测试的更多细节可以参看这里)。
一般来说,哪些测试最有价值
一些测试本身就需要消耗昂贵的资源。例如,我们的一些客户在昂贵的硬件上执行测试套件。每个测试运行包括数万个单独的测试,需要数周的时间来执行,并集成来自不同团队的组件。而这些测试又很重要,因为没有这些测试软件就不能发布。
对于这种大型、昂贵的测试套件来说,一个真正的问题是“海量 Bug”:一个位于中心位置的 Bug 会导致数百甚至数千个测试用例失败。如果被测试的系统版本包含大量 Bug,那么整个测试就会被破坏,因为在数以千计失败的测试中很难再进一步找到其他 Bug。因此,测试团队在开始执行大型、昂贵的测试套件之前,需要确保所测试的系统不包含质量缺陷。
为了防止出现海量 Bug 现象,团队使用了验收测试套件(也叫作冒烟测试套件),在执行大型、昂贵的测试之前必须先通过验收测试套件。验收测试套件将执行所有测试中的一小部分,这些测试极有可能会发现会导致众多测试失败的 Bug。
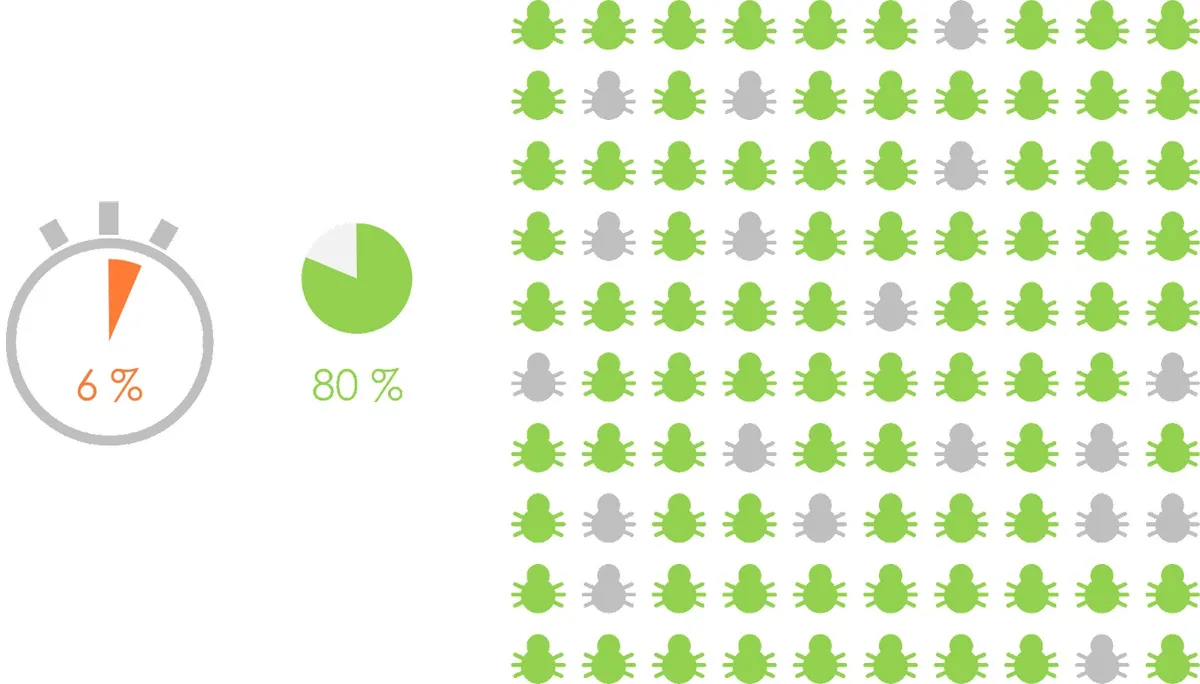
我们可以根据特定的代码覆盖率信息从现有的测试集中选择一个最佳的验收测试套件(在最短的时间内覆盖最多的代码)。我们发现所谓的“贪婪”优化算法比较有效:它们从一个空集开始,逐步添加每秒覆盖最多代码行的测试。然后,它们继续添加那些覆盖了还没有被之前的测试覆盖到的代码行的用例。重复这个选择过程,直到验收测试套件的时间预算用完为止。在我们的研究中,我们发现我们用这种方法选择的验收测试套件可以在 6%的时间内(执行整个测试套件所需的时间)找到 80%的 Bug(整个测试套件可以检测到的 Bug)。
我们在一个项目中将这种选择验收测试套件的方法与测试专家手动选择的验收测试套件进行了比较。对于前两年的历史测试执行数据,优化选择的验收测试套件发现的 Bug 比专家手动选择的套件多两倍。
这种方法不如测试影响分析(只需要 1%的时间就能找到 80%的 Bug),但是当可用的信息较少时(我们不需要知道自最后一次执行测试以来的所有代码变更),可以使用这种方法。
如何在项目中开始使用测试智能分析
测试智能分析可以为各种问题提供基于数据驱动的答案。因此,你很有可能会尝试使用它们,看看它们能揭示出有关系统的哪些信息。
如果从正在被测试的系统的特定问题开始会更加有效,变更管理会因此更有可能取得成功,因为说服同事和经理解决问题比尝试新工具来得更容易。
根据我们的经验,在使用测试智能分析之前,可以先考虑以下这些问题:
是否有太多的 Bug 从测试环境进入到生产环境?通常,造成 Bug 的根本原因就是测试间隙(即尚未被测试的新代码或修改过的代码区域)。测试间隙分析有助于在发布之前发现并解决它们。
整个测试套件的执行时间是否太长?测试影响分析可以识别出 1%发现 80%新 Bug 的测试用例,这大大缩短了反馈周期。
一旦采用了测试智能分析,就可以很容易地用它们来回答其他问题。因此,团队很少只使用一种分析手段。但要解决实质性的问题,总是要卖出第一步。
作者简介
Elmar Jürgens 写了一篇关于静态分析的博士论文,现在仍然活跃在软件质量分析领域。2009 年,他联合创立了 CQSE GmbH,帮助开发团队更有效地使用分析工具。Jürgens 经常在研究会议(如 ICSE、ICPC)和行业活动(如 GTD、OOP、JAX)上发言。Jürgens 在 2015 年被评为 ACM 德国分会的 Junior Fellow。
查看英文原文:
https://www.infoq.com/articles/process-data-find-more-bugs/




