
基于优异的调度性能,Gödel Scheduler 拥有在超大集群规模 (20k+ Nodes, 1000k+ Pods)、超高业务负载 (1k+ Incoming Pods/s)、超多复杂场景 (ML/批流/潮汐混部等) 下长期稳定运行的能力。
Gödel Scheduler 是字节跳动开源的在离线统一调度器,旨在使用同一套调度器来统一调度和管理在离线业务,实现资源并池,从而在提升资源利用率和资源弹性的同时,优化业务成本和体验,降低运维压力。
当前,Gödel Scheduler 的单分片调度吞吐可达 2500+ Pods/s (10x Kube Scheduler),多分片调度吞吐可达 5000+ Pods/s,这离不开大量创造性的构思。
本文将以几个经典优化为例,阐述基于这些构思所衍生的算法设计思想与数据结构应用,说明其对提升 Gödel Scheduler 调度性能并最终解决实际问题所发挥的巨大作用。
设计一:增量更新
前置介绍
与 Kube Scheduler 相似,Gödel Scheduler 同样维护了 In Memory 的 Cache 与 Snapshot。
Cache:
维护各类 Resource Object 的组织关系,有助于快速获得汇聚信息 (如节点已被使用的资源总量),提高调度算法的执行效率
会伴随着 Event 触发实时变动,且数据维护需要对整个 Cache 加锁
Snapshot:
规避当前调度轮次期间 Event 带来的影响,保证调度过程中的数据一致性
单个调度轮次期间数据只读,不需要加锁
每次调度流程的起始都需要将 Cache 的最新数据同步 Clone 到 Snapshot 中供串行的调度流程取用,因此数据同步的效率就格外关键。
问题产生与解决
相比于 Kube Scheduler,Gödel Scheduler 拥有更复杂的调度功能、需要承载更大规模的集群与应用,并由此带来了更多种类的缓存信息与更大量级的数据同步规模。此前,伴随着业务上量与集群规模自然增长,大量生产集群都频繁出现了各类缓存信息全量克隆所产生的性能问题,并严重拖垮了调度吞吐与调度时延。
❓ 思考:在前后两次调度的时间间隔中,并非 Cache 中所有的数据单元都发生了改动;实际上,我们只需要识别出发生了变动的部分,并将这部分以 “增量” 的形式覆盖到前一轮调度的 Snapshot 即可满足数据同步需求。
具体来说:
1. 假定前一轮调度时,Snapshot 已经完整的拷贝了 Cache 中的 Node 0, Node 1, ..., Node 5;当前调度轮次发起时,Cache 中的 Node 1 & Node 3 发生了更新、Node 5 被删除、Node 6 被新增。Snapshot 应当如何感知?
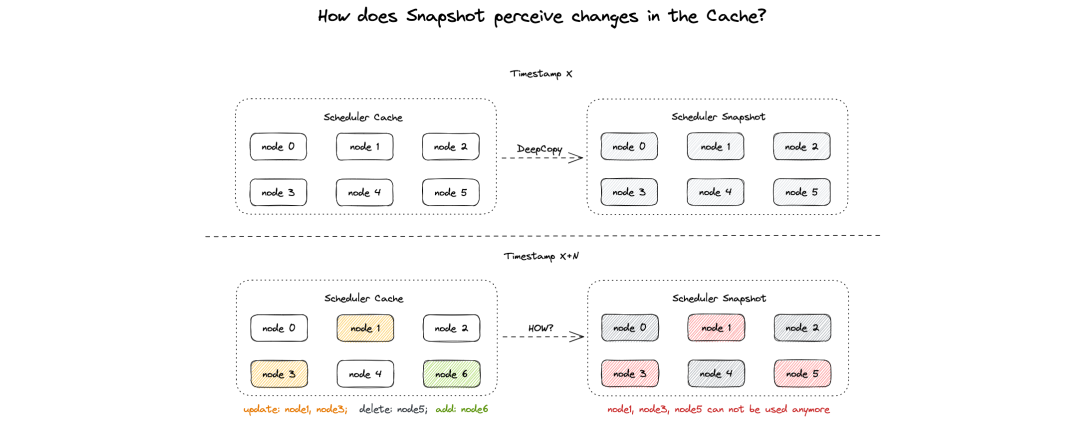
很显然,在不做特殊维护的情况下,除非遍历比对所有对象,否则 Snapshot 很难得知 Cache 基于某个时刻起发生了哪些变动。
2. 如果我们手动赋予每个对象特定时序,并按时序(如时序降序)维护对象列表,则一段连续时间内的 Cache 变动都能够被映射到一段连续时序内。以前一轮次调度所对应的全局时序值作为基准,当前大于该全局时序值的所有对象对于该基准来说都是 “增量”。
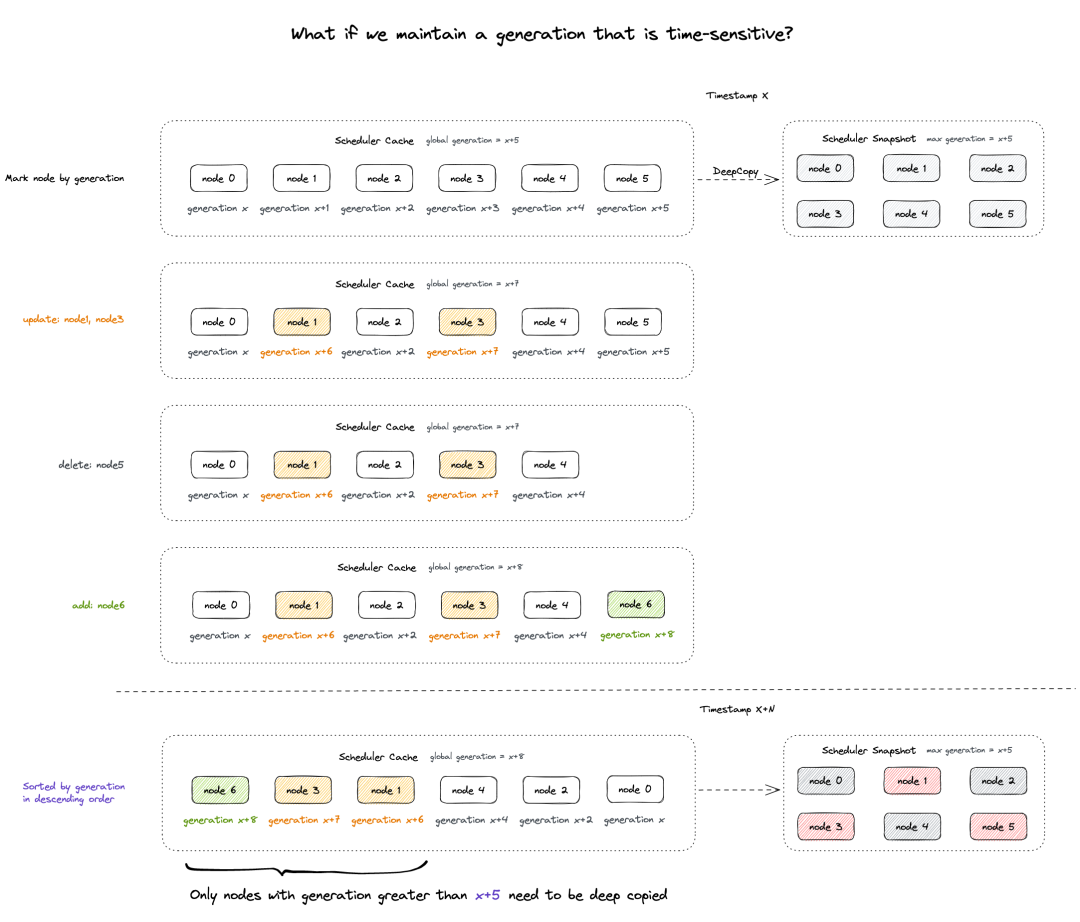
按照时间发生顺序组织所有对象,并将前一轮次的全局时序值 (x+5) 记录在 Snapshot 中,则后续产生变动的对象的时序值都将大于该基准值,由此感知 “增量” 并做局部更新。
3. 将前述数据维护过程做进一步抽象:本质上 Cache 与 Snapshot 中需要向上层暴露的都是一个能够提供 Get & Set 接口的存储 (GenerationStore);区别在于,Cache ListStore 的存储内部需要能够维护时序,而 Snapshot RawStore 只关心存储对象本身。
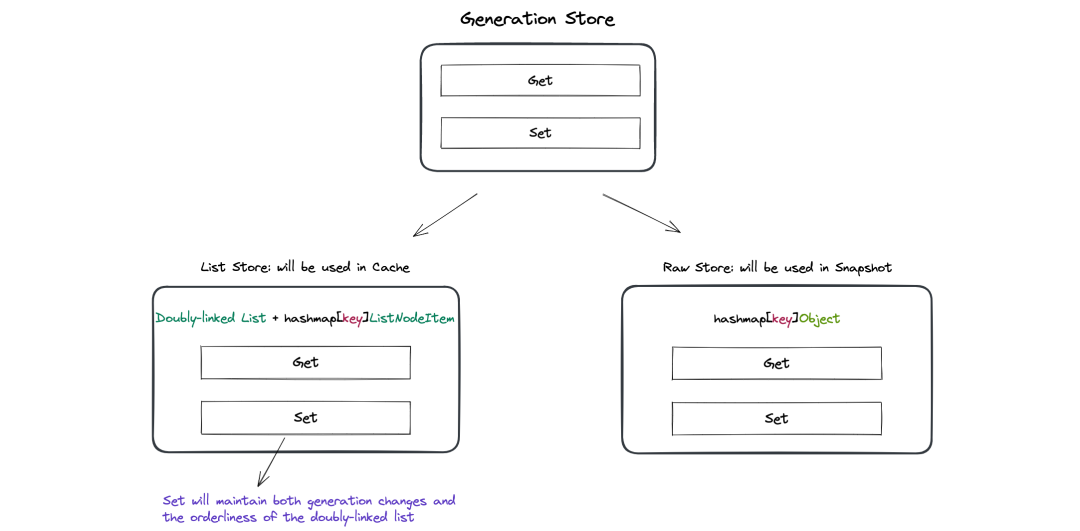
通过逻辑抽象并将各类数据全面接入增量更新,大幅降低了缓存信息的数据同步损耗,显著提升了调度吞吐并优化调度时延。
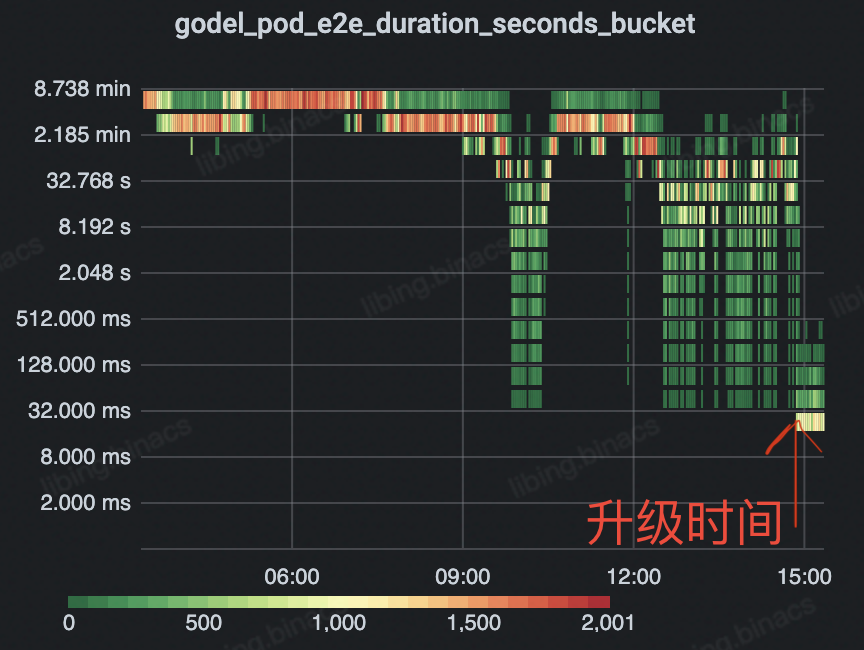
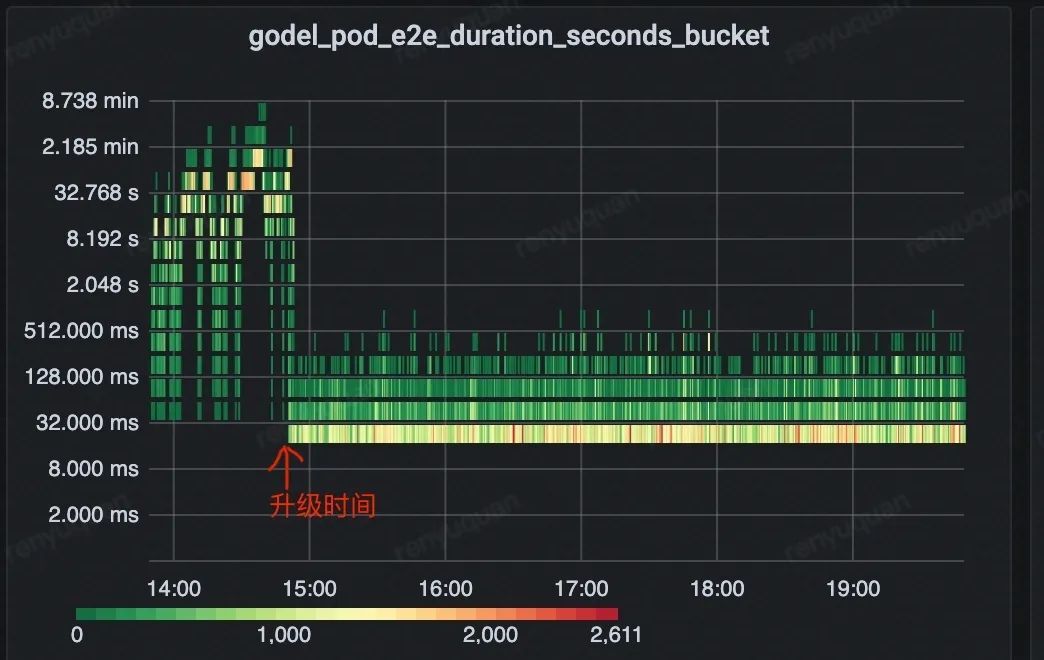
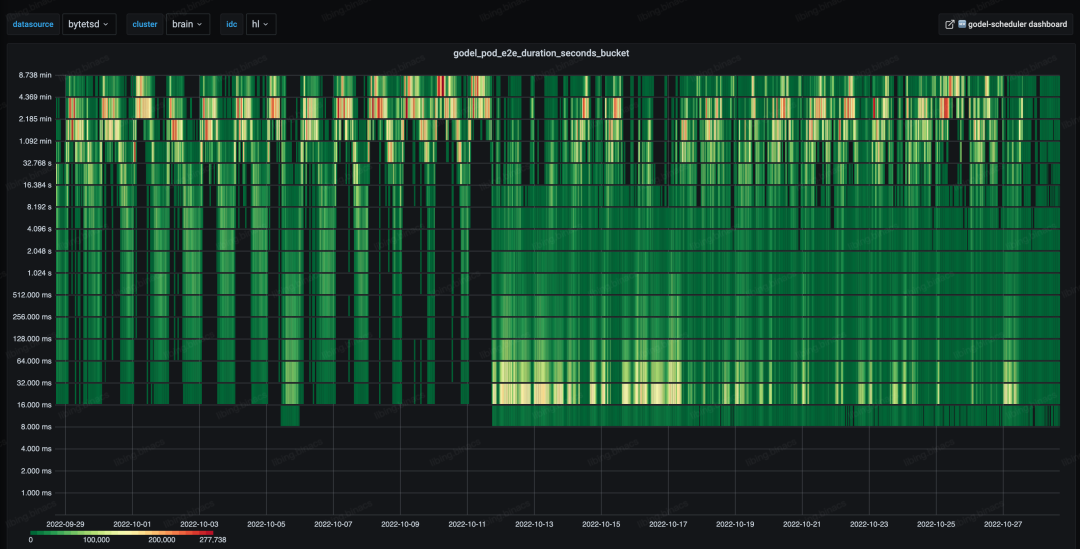
如下图所示,整体 e2e 调度时延由分钟级下降至毫秒级并保持长期稳定,有 4 个数量级的优化。
设计二:离散化节点列表
前置介绍
出于调度效率的考量,单个 Pod 调度时不会遍历集群中的所有可行节点,而是只遍历特定数量或特定比例后立即停止,因而每一个 Pod 的调度都存在一定的空间局部性。
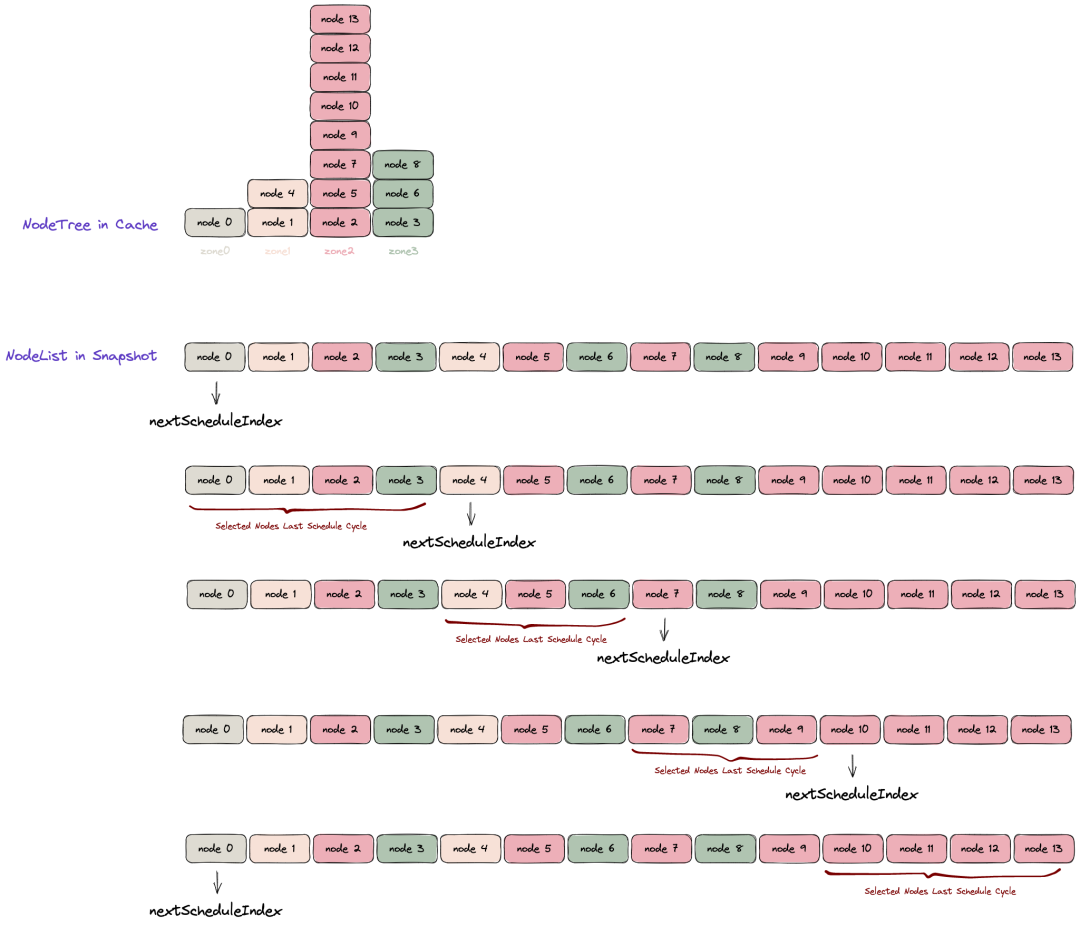
在这样的前提下,原始逻辑中为了尽力实现调度时的天然离散,Scheduler Cache 会按拓扑域维护一颗 Node Tree (二维数组)。Update Snapshot 时,会将 NodeTree 压缩为一维列表并存储于 Snapshot 中,并在每次调度时以取模轮转的形式取用。
问题产生与解决
容易看到,前述 NodeList 的生成过程存在明显的问题:通过压平 Node Tree 构建的 NodeList 在拓扑域层面并不真正离散,其只能保证每个 Zone 在靠前的部分均匀分布,而靠后的部分则会被某个数量较多的 Zone 节点完全占据,导致部分 Pod 错误地产生拓扑域倾向性。
更严重的问题在于:NodeList 会由于任意 Node 的 Add / Delete 等场景频繁触发整个列表的完全重建,而其重建过程涉及对整个节点存储的遍历和相应的内存分配与回收。在 20k+ Nodes、Incoming Workload 接近 1k Pods/s 的超大规模集群中,频繁重建 NodeList 的计算开销达到了整体进程开销的 50+%,严重影响调度效率。
❓ 思考:
1. 怎样实现真正的拓扑域离散?
等价于任何节点在 NodeList 的下标位置完全随机
2. 如何避免频繁重建的开销,低成本地维护 NodeList?
理想情况下,单个元素的增删应当能够在 O(1) 的时间复杂度内完成增加:直接追加到线性列表末尾删除:将待删除元素与列表末尾元素交换,随后移除末尾元素(此时需要结合 HashMap 以实现元素下标索引,用以支持元素交换)更新:删除 + 增加
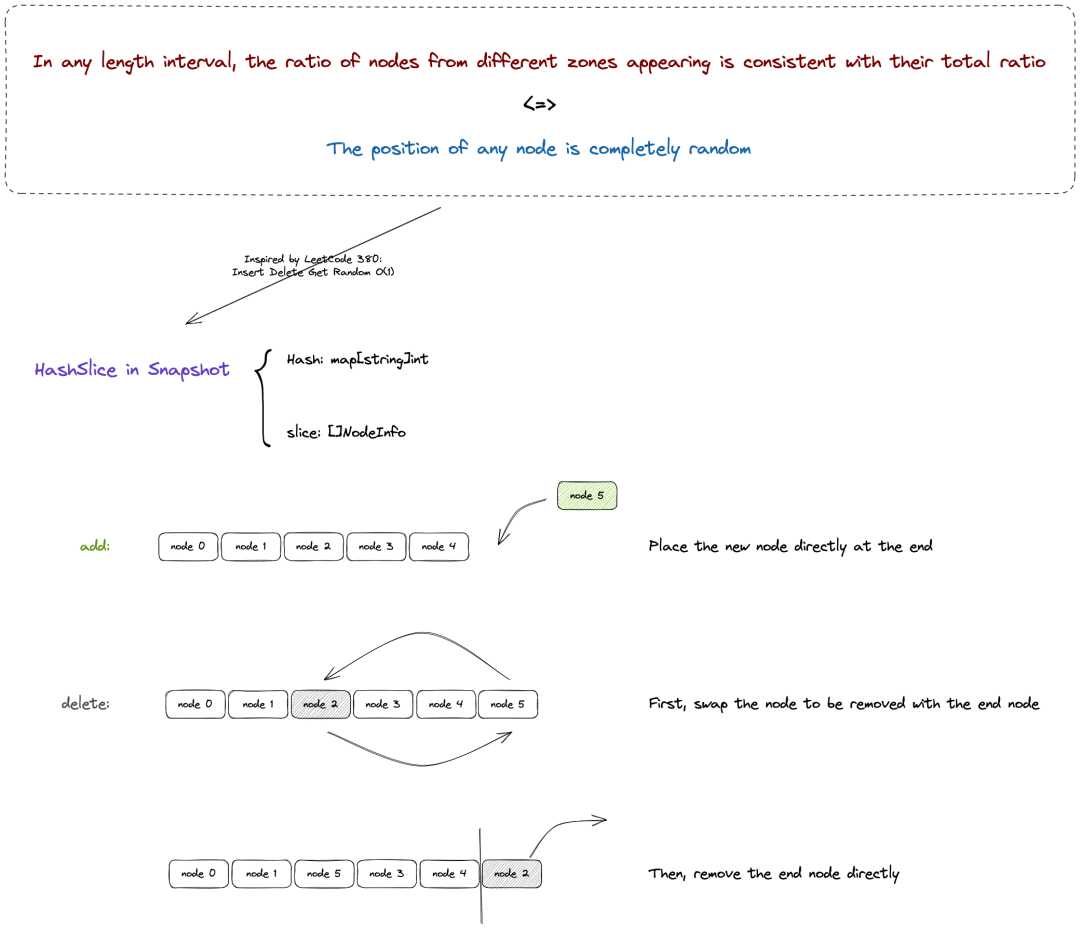
由于整个集群所有节点发生 Add/Delete/Update 的随机性,容易得知 NodeList 中任意下标元素所对应的节点是完全随机的;更进一步地,任意长度的一段连续区间内每个下标所对应的节点都是随机的,则该连续区间内任意拓扑域出现比例的数学期望均与其全局统计比例一致,进而能够保证拓扑域的离散。
通过重新设计 NodeList 维护机制,我们解决了多个超大规模生产集群出现的性能问题,并以更低的开销获得了更好的节点离散效果。
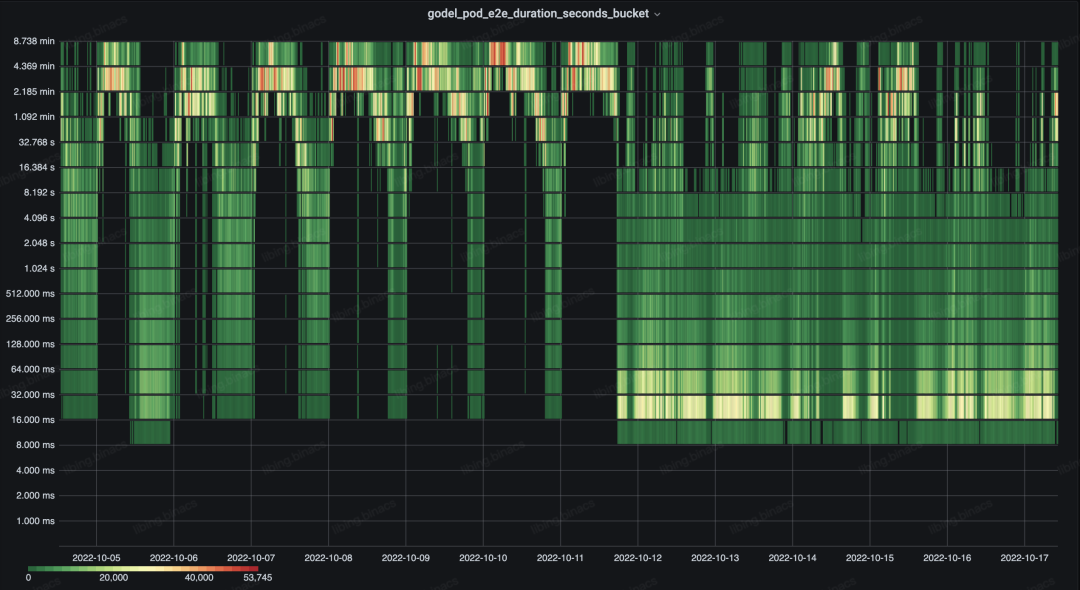
如下图所示,2022-10-11 下午升级后,整体 e2e 调度时延的主要热力分布由分钟级下降至毫秒级。
设计三:启发式剪枝算法
前置介绍
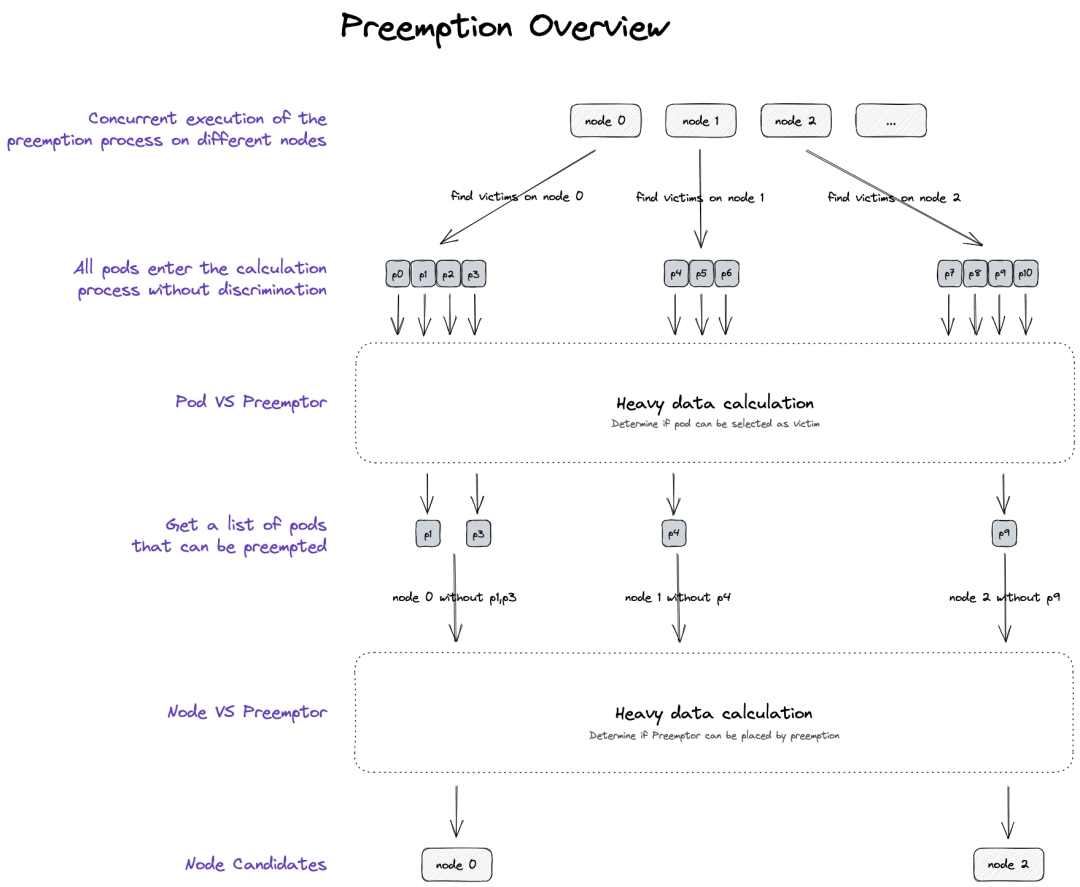
Gödel Scheduler 中,单个 Unit 的调度被划分为 Scheduling + Preempting 两大阶段。正常 Scheduling Filter 机制下 Pod 无法被摆放到特定节点的情况下,将会通过 Preempting 触发抢占行为,并尝试通过驱逐部分 Pods 来实现调度摆放的目的。
抢占过程需要通过大量计算逻辑以得出 "抢占哪个节点""驱逐哪些 Pods" 的决策,因而一直是部分调度场景下的 CPU 热点。抢占的本质其实是一颗搜索树,其主体流程如下:
问题产生与解决
大规模生产环境中,在线业务负载有着明显的潮汐特征。我们会将高优的在线业务与低优的离线任务在同个资源池混部,并伴随在线业务的扩缩去动态调整离线运行的规模,进而保证全天候的资源利用率。
在高优在线业务返场时,由于整体资源水位较高,将不得不对此前占据了集群资源的低优任务发起抢占,短时间内即产生极高的抢占频率,严重拖垮性能、影响在线返场效率。
❓ 思考:假定计算逻辑无法改变,如何减少参与计算的数据规模?
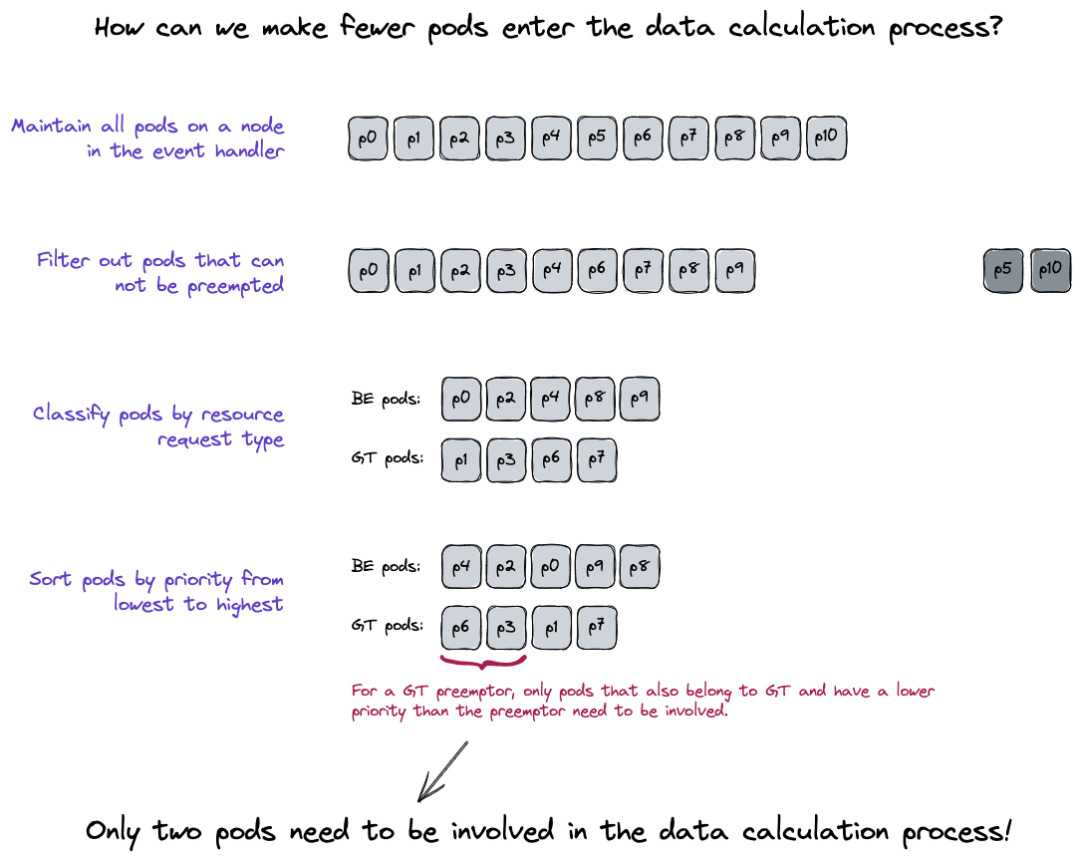
1. 如何减少参与计算逻辑的 Pod 的规模?
考虑到 Pod Priority 是抢占的基本原则,可以提前对节点上的存量 Pods 进行分类和排序。则对于当前要调度的 Pod 来说,它最多能够抢占的 Pods 是确定的,需要考虑的 Pods 的数量得以大幅降低。
2. 如何减少参与计算逻辑的 Node 的规模?
💡 一个设想:能否在不进入复杂计算逻辑之前,就能对 "能否成功抢占" 做一个粗略的估算?
乐观地假设当前 Pod 可以抢占优先级较低的所有 Pod(实际上部分 Pod 可能由于 PDB 保护等规则无法被抢占),则其可释放的资源总量是明确的。如果有办法获取这部分可释放资源量并将其与节点剩余资源相加,则可以得到当前 Pod 在抢占情况下最多可以利用的资源总量,若该总量仍然不满足 Pod Request 那么当前节点的抢占行为必然失败(启发式剪枝)。
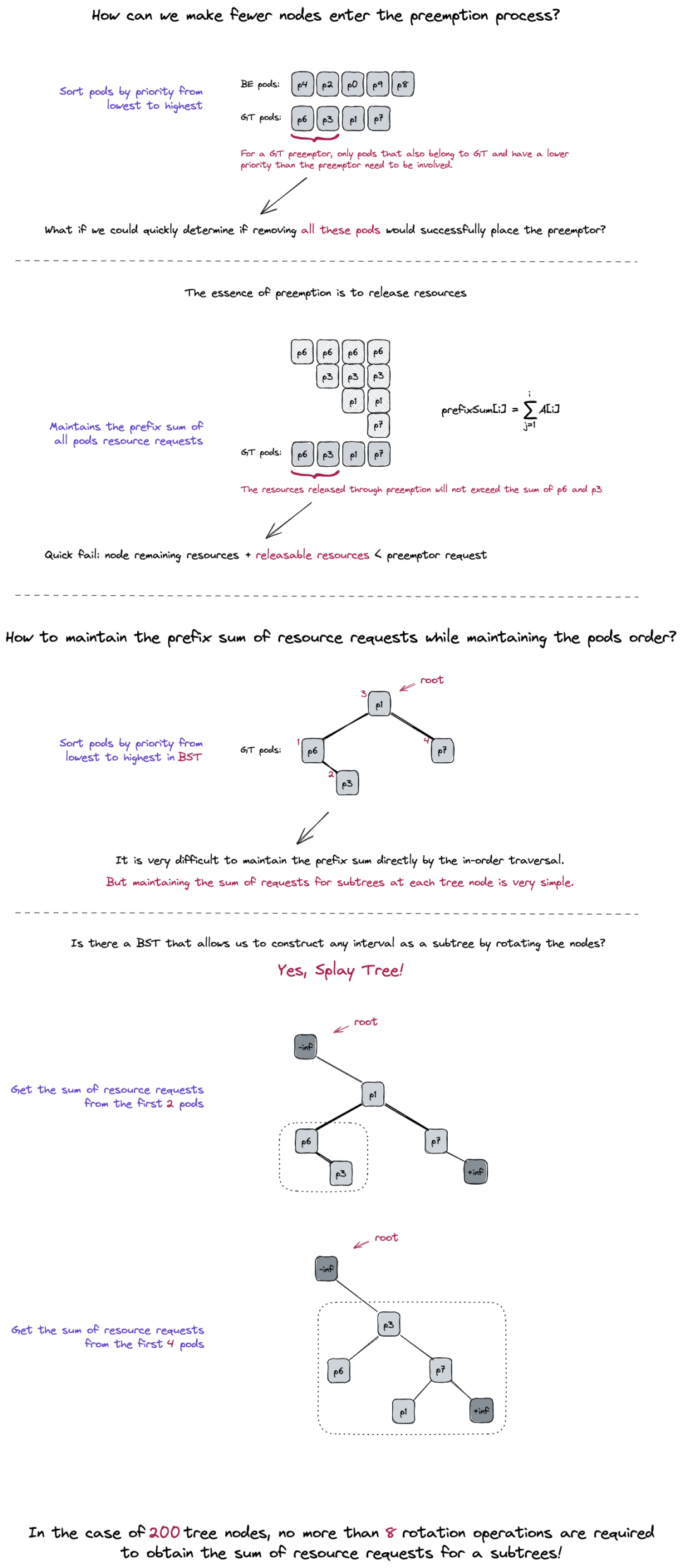
💡 更进一步:如何快速获取节点上对于要调度的当前 Pod 的可释放资源量?
基于节点上的 Pods 已经按照 Priority 排序的前提,如果能为每个位置记录其资源维度的前缀和,则对于要调度的当前 Pod 的特定的 Priority,只要找到最后一个小于该 Priority 的位置,该位置的前缀和即为所求。
🥊 挑战:节点上的 Pods 会以极高的频率动态添加和删除,如何低成本的维护有序结构与资源前缀和?
我们可以将其拆解为两个子问题:
维护有序性:Balanced Binary Search Tree
维护资源前缀和:将【前缀和问题】抽象为【区间和问题】,进而将【线性的区间和】转化为【结构化的子树求和】。借助 Splay-Tree,能够在维护有序性的同时维护子树性质(资源维度求和),并通过 Splay 伸展操作动态调整树结构、通过子树和来得到所需前缀和
3. 最终效果:在搜索树上实现了高效的剪枝。
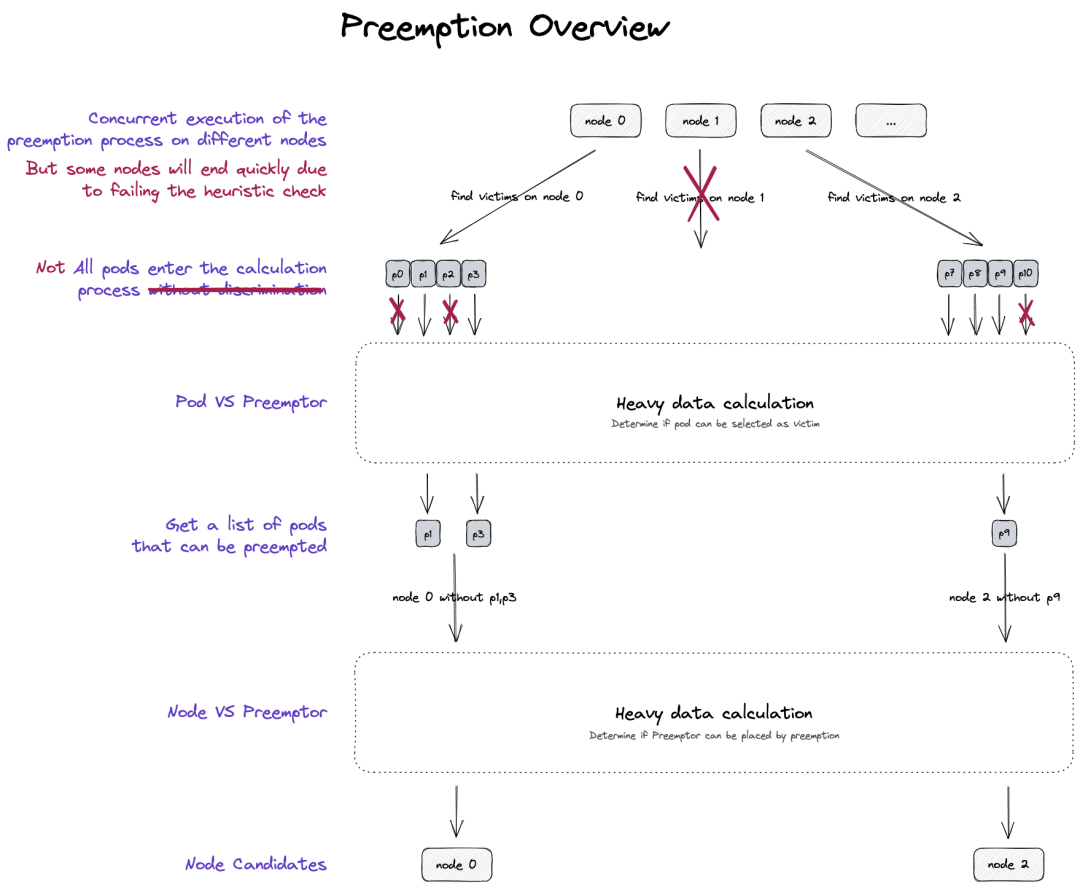
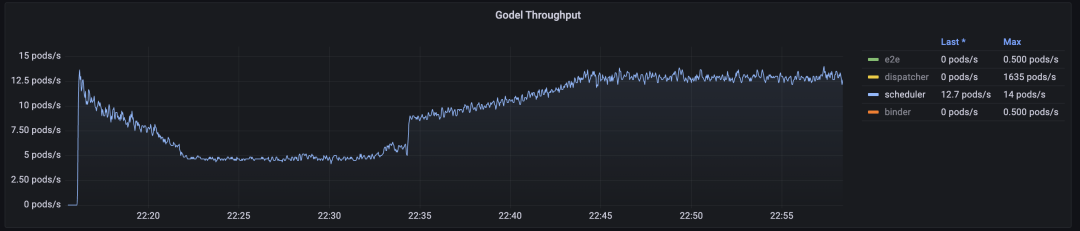
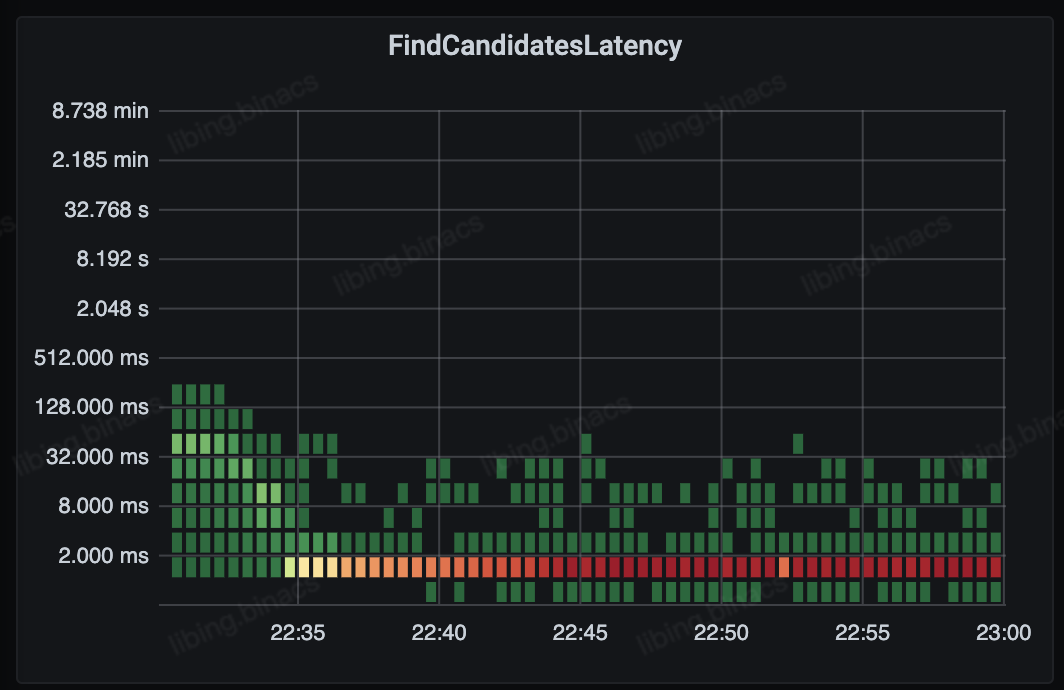
基于 Pod & Nodes 的多维剪枝策略,我们使得抢占吞吐能够快速回升、抢占时延大幅降低,并能在 2ms 内快速过滤无法抢占的情况。
成果与未来规划
基于前述多项设计与优化,Gödel Scheduler 在通用场景下的调度吞吐取得了极大的突破。目前,单分片的 Gödel Scheduler 已经能够游刃有余地应对字节跳动绝大多数业务场景,多分片也能提供更长期稳定的业务负载处理能力。
除此之外,Gödel Scheduler 对集群资源高水位等多个细分场景也做了大量创造性的设计优化并取得了显著收益,我们将在未来逐步迁移这些优化至开源版本中。
Gödel 调度器目前已开源,真诚欢迎社区开发者和企业加入社区,与我们一起参与项目共建,项目地址:github.com/kubewharf/godel-scheduler
文章专题推荐:字节跳动云原生创新实践与开源之路




