
当服务器宕机的那一刻,时间仿佛也停滞了。
前不久,国际数据公司 IDC 发布了《中国公有云服务市场(2023 上半年)跟踪》报告。该报告显示,2023 年上半年中国公有云服务整体市场规模(IaaS/PaaS/SaaS)为 190.1 亿美元。其中,IaaS(基础设施即服务)市场规模为 112.9 亿美元,同比增速 13.2%;PaaS(平台即服务)市场规模为 32.9 亿美元,同比增速为 26.3%。
伴随着 AIGC 技术的崛起,云计算市场增长迅速。但另一方面我们也不得不注意到,最近半年来互联网基础设施宕机事件频发,服务器这个曾经被我们视为坚不可摧的巨人,如今却倒在了自己的重量之下。它的宕机,像一座大山瞬间崩塌,带来的震动与影响远远超出了人们的想象。
当宕机事件发生,我们就犹如被困在了一座孤岛上,只能眼睁睁地看着外面的世界在不断运转,这些曾经熟悉的工具都变得遥不可及,也给客户带来了无尽的失望和不满。
最后,我们开始反思这一切的根源。是什么导致了这场技术灾难?是技术不够先进,还是管理存在问题?是对风险的评估有误,还是对备份方案的准备不足?
本文总结了近半年来的云宕机事故,以期能沉淀出更加清醒的认知,降低类似事件发生的频率。
宕机事件频发,云基础设施靠不住了?
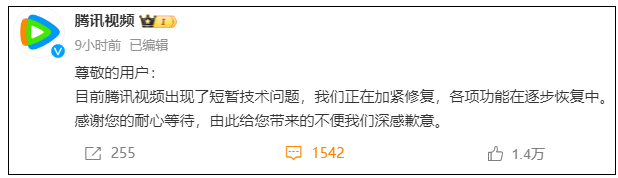
腾讯视频 App“崩了”,回应称出现短暂技术问题
12 月 3 日晚,腾讯视频出现网络故障,有网友反馈出现首页无法加载内容、VIP 用户看不了会员视频等情况。稍晚些时候,@腾讯视频就“App 崩了”发布致歉声明:
尊敬的用户:目前腾讯视频出现了短暂技术问题,我们正在加紧修复,各项功能在逐步恢复中。感谢您的耐心等待,由此给您带来的不便我们深感歉意。
除了腾讯视频,近期遭遇宕机事件的还有滴滴、语雀、Boss、钉钉、淘宝、闲鱼盘等多个 App。
阿里云一个月内崩完了再崩
11 月 27 日,阿里云服务器遭遇了近两小时的中断,影响到中国和美国的客户,这是该业务一个月内第二次宕机。
随后,11 月 28 日,阿里云在网站上发布的声明中表示,北京时间 2023 年 11 月 27 日 09 时 16 分起,阿里云监控检测到资料库产品的控制台和 OpenAPI 访问异常,称问题已于当天 10 点 58 分解决。
受到此次事件影响的主要是北京、上海、杭州、深圳、青岛、香港以及美东、美西等多个地区的数据库产品,包括 PostgreSQL、Redis 和 MySQL 等。
而类似的事故,在双十一刚过的第二天,也就是 11 月 12 日刚刚发生过。
11 月 12 日,阿里云发生了宕机,旗下的钉钉、淘宝、闲鱼等产品皆受到了不同程度的影响,此次事故还影响到了使用阿里云的一些企业级客户,受影响地区从东亚和东南亚,覆盖到了中东和北美。经过数小时的修复后,服务恢复正常。
有人猜测,阿里云 11 月 27 日的宕机甚至可能造成了滴滴出行 App 崩了一夜,但业内人士认为这种情况概率比较低。
滴滴崩了一夜
11 月 27 日深夜,上海、北京、广州等多地滴滴用户反馈,滴滴出行 App 无法使用,显示网络异常,地图无法加载,用户无法使用定位功能且无法打车。
“滴滴崩了”的话题也登上微博热搜。热搜话题下不少用户发帖表达自己在使用滴滴 App 过程中遇到的“离谱”问题。
有用户反馈虽然打到了车,但同时来了好几辆车,有的用户遇到来了三辆、有用户遇到来了四辆车,无法取消,无法联系客服。
从各平台上的反馈来看,此次滴滴平台在接单、定位、计费等环节上都出现了问题。
有网约车司机表示,昨晚 App 崩溃时刚好在接单,“从晚上 10 点 20 分开始什么都做不了,客服电话也进不了线。目前恢复了少部分功能,但不能正常使用,很多错单乱单,还出现了多位司机接同一单的现象。”
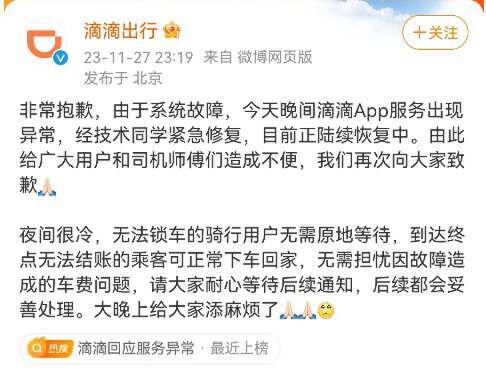
27 日深夜,滴滴出行对滴滴 App 服务出现异常进行了回复,滴滴出行称:非常抱歉,由于系统故障,今天晚间滴滴 App 服务出现异常,技术目前正陆续恢复中。由此给广大用户和司机师傅们造成不便,再次向大家致歉。
经过一夜维修,滴滴在 28 日早上 7:31 分做出回应称“滴滴网约车等服务已恢复”。
语雀突发 P0 级事故,宕机 8 小时
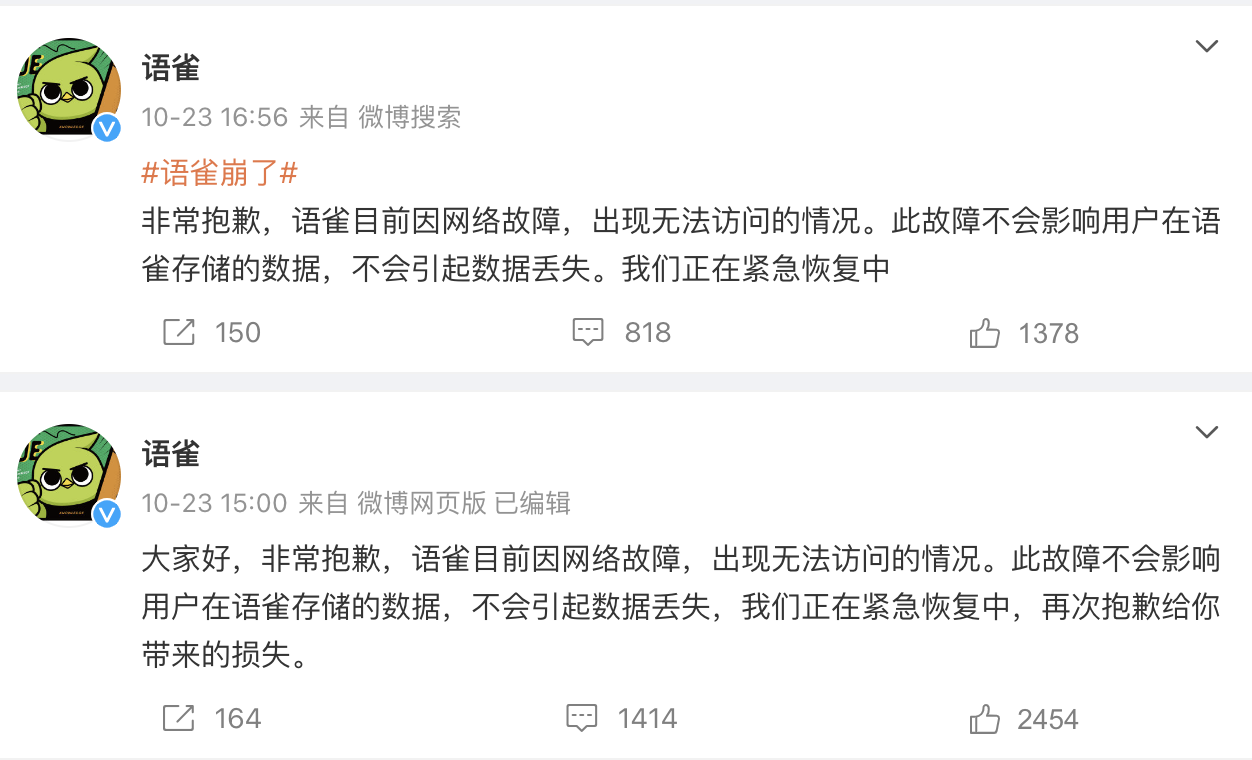
10 月 23 日 14 时左右,在程序员节的前一天,蚂蚁集团旗下的在线文档编辑与协同工具语雀发生服务器故障,在线文档和官网目前均无法打开。当日 15 时,语雀发布官方声明称,“目前因网络故障,出现无法访问的情况。此故障不会影响用户在语雀存储的数据,不会引起数据丢失,我们正在紧急恢复中,再次抱歉给你带来的损失。”
随后,“语雀崩了”登上话题热搜,有网友表示自己的公司项目文档都在语雀上,文档打不开严重影响工作进度;有网友将自己整理的面试题放在了语雀上,宕机时正好赶上电话面试,想查答案都无从下手;也有网友对语雀的运维提出质疑,认为“长时间的故障明显是存储出现了问题,用户数据可能丢失了,在紧急恢复”。
从故障发生到完全恢复正常,语雀整个宕机时间将近 8 小时,如此长时间的宕机已经达到了 P0 级事故,并在网络上引发巨大讨论。
肯德基 App 崩了,13 元买五人餐
11 月 14 日,“肯德基 App 崩了”冲上微博热搜第一。有网友爆料称,肯德基 App 崩溃期间,还出现了大 Bug,14.9 元+139 元的套餐同时加入购物车,领取“-10 的优惠券”,再把那个双人餐退掉,就可以 13 元买五人餐。
当日晚些时候,肯德基官方客服表示,刚才系统确实崩溃了,但目前已经修复完成,用户可以重新登录使用。
月活用户超 4000 万,BOSS 崩了
9 月 15 日,据媒体报道,在线招聘 App BOSS 直聘崩了。当天 11 时前后,许多用户涌入“BOSS 直聘”官微的最新博文中留言,抱怨无法刷新页面,发信息也发不出去,给客服反馈也没有任何回应。
有网友透露,这已经是 BOSS 直聘今年第三次出现网络崩溃。随后网络上流传一张截图显示:9 月 15 日 10 点 15 分 26 秒,在线统计超过 4700 万人在刷 BOSS 直聘,导致服务器超荷载,正努力维护中。随后 BOSS 直聘官博辟谣,称服务器崩了是真的,网传数据是假的,BOSS 直聘月活为 4360 万人。
探究大厂 App 排队宕机背后的真相
在互联网大厂的 App 频繁出现宕机后,一众网友将宕机背后的原因归结为裁员、降本增效等行为,以此来讽刺互联网大厂缺乏稳定性的系统服务,但这真的是事件背后的真相吗?
在QCon中国 15 周年之际,InfoQ 特别邀请了云器科技联合创始人兼 CTO 关涛、贝联珠贯合伙人王元良、趣丸科技技术保障部负责人刘亚丹,参与「大会早班车·QCon15 周年特别策划」直播栏目,围绕“稳定性出了大问题,是降本增效的锅?”相关话题展开讨论。
降本会带来哪些问题?
在全球降本增效的大环境下,在一定程度上降低成本成为了所有公司的普遍共识,也是一种显而易见的大趋势,那么降本会带来哪些问题呢?
趣丸科技技术保障部负责人刘亚丹认为:降本主要涉及两个维度——砍人和砍资源,而不同纬度则会带来不同的问题。
在砍人的维度上,可能会出现以下问题:
测试不充分: 由于人员减少,测试可能无法覆盖到所有的情况,导致上线出现问题;
开发人员不足: 开发人员减少可能导致项目延迟,影响整体进度;
上线验收不完整: 由于人手不足,上线后的验收可能不够严格,存在潜在问题;
如果资源被砍,则可能会出现以下问题:
容量不足: 预估的用户量超过实际承载能力,导致系统崩溃或性能下降;
配置问题: 上线后需要配置验收,但由于资源减少,可能存在配置不当的情况。
稳定性问题到底是不是降本造成的?
那么,是不是不降本,就能保证稳定性了?云器科技联合创始人兼 CTO 关涛认为,稳定性的危机一直存在,虽然我们能够察觉到一些故障,但未显露的潜在问题更为庞大,显露出的问题只是冰山一角。即便选择不走“降本”的路径,稳定性问题仍然存在。
只是,如果选择了降低成本,那么就要在保证稳定性的前提下进行成本优化,这就需要在事前进行详细评估,事中制定相应的预案并进行演练,然后在确保这些工作完成后,再考虑进行降本操作。比如在进行降本操作前,需要对目标进行详细的评估,思考能否成功节省 80%的成本,或者是否可以先推高 5%的 Cluster。还需要假设系统的任何一个部分都可能发生故障,并制定相应的预案。例如,如果资源调度模块出现故障,应如何恢复等,这些都需要提前考虑清楚。
谁是稳定性第一责任人?宕机了谁该背锅?
尽管考虑到了种种可能出现的问题,但系统在运行时到底会发生什么突发意外却是未知的,一旦出现了问题,该有谁来负责?
就此问题,王元良表示,从首席执行官(CEO)的角度来说,稳定性是 CTO 的责任。
如果 CTO 重视稳定性的问题,这将会对整个企业产生影响,包括内部的各个层面。管理者可以将自己的理念、血液或者说灵魂注入整个组织,并且大多数公司面对故障时都应该去思考如何改进,而不是追责。
关涛则称,“的确应该由公司一号位来负责,但比起对事故负责,对发生的故障进行复盘更为重要。”
“第一责任人应该位于公司的首位,这并非是要完全推卸责任,而是在一般情况下确实存在资源投入比例的问题。也就是说,公司需要在稳定性、业务开发以及技术底座沉淀上进行资源投入,而这个投入的比例不同确实会影响整个公司的发展方向。因此,从这个角度来看,如果一定要明确个第一责任人,那一定是公司的一号位。”
此外,就如何拆分稳定性的问题关涛也给出了他的方法论。他表示,首先,要区分研发和运维的责任。明确这个故障究竟是研发的问题还是运维的问题。其次,要明确到底是谁负责解决问题。
在云器科技,如果将故障分成 P1、P2、P3、P4,最底层 P4 是最不严重的故障,最不严重的故障会交给一线的研发同学来解决。也就是说,如果故障真的是研发的 Bug 或者 SRE 操作失误,那么这个责任就在最底层。P3 层交给一线的 Leader,到了三级可能就不再是某一个程序人员的责任,而是一线 Leader 的责任。
之所以造成此类故障,可能是故障发生之前没有做好事前预判,故障中也没有抓住稳定性问题,事后缺乏兜底措施,演练不够,爆炸半径控制不够等一系列问题。P1、P2 的故障就需要 TO(Technical Owner)来负责,也就是当更大的故障发生时,说明在机制、防范措施以及整个公司资源调配方面没有做好,包括 SRE 和研发的协同层面。因此,在云器科技内部,采用的是这种模式来看待故障。关涛表示,目前来看,这种模式运行状况还不错,也没有出现特别大的问题,可以为行业提供一些参考。
同时,关涛也表示,这种波动性在公司的运营中是很常见的。有时候,公司可能会因为对系统稳定性的过度自信或者资源限制等原因,而没有对系统进行适当的扩展或者备份。然而,当系统遇到超出预期的流量或者负载时,就可能出现故障。
这种经验通常是非常宝贵的。在事后分析中,公司可以更深入地了解故障的原因,包括系统瓶颈、潜在的容量不足以及其他可能的问题。这些信息可以用来改进系统的设计和运营策略,以增强系统的稳定性和性能。
小结:降本势在必行,但我们要“健康”降本
以目前企业总体经营状况来看,降本在一段时间内仍是一个势在必行的方向,但更重要的是要实现“健康”降本。这里的“健康”降本是指在企业进行降本的过程中,不能以牺牲系统的稳定性和性能为代价。
在实现“健康”降本时,一些关键的考虑因素必须要提前考虑清楚:
首先,是合理规划。在降本之前,需要进行全面的规划和评估。这包括对当前系统的稳定性、性能和容量进行深入的分析,以及评估所需的资源和预算。
王元良认为,在数字化领域,能力、成本、人力和硬件等因素都至关重要。然而,对于许多企业来说,尤其是那些大型传统企业,他们往往无法清晰地呈现成本。尽管这些企业拥有强大的流程功能,但他们无法明确说明每个部门使用了哪些成本以及云服务的具体部分,这使得他们难以做出明智的决策。
为了解决这个问题,最首要做的就是清晰地了解账单。然而,目前看来,从首席执行官到单个使用节点的整个评估过程尚未完全打通。这不仅影响了企业的决策过程,也阻碍了他们优化运营成本的能力。因此,建立一个完善的评估体系,使得从首席执行官到单个使用节点的所有层面都能明确自己的成本和责任,是非常必要的。
随着数字化和信息化程度的提高,IT 成本、硬件人力成本以及一些运维手段成本逐年增加。特别是随着大语言模型的推出,这种趋势对企业的运营产生了深远的影响。因此,将成本可视化并建立完善的评估体系可能是未来企业的必然选择。
其次,是充分了解风险。我们需要有一个成本决策中心,将财务、研发、运维和产品的资源管理方案整合在一起,然后设立一个机制,在这个机制中对过去发生的花费以及未来可能采取的技术手段、优化等方面达成共识。
刘亚丹强调说,共识不仅仅是关于省下多少钱,其背后省下的钱所带来的风险也是大家需要了解的。
再次,以创新技术代替粗暴地乱砍项目。关涛认为:稳定性是健康的 FinOps(降本增效)的前提,不稳定的 FinOps 是危险的,甚至可能是致命的。FinOps 不仅仅是砍成本,很多 FinOps 是靠技术手段去解决。就比如说调度系统的混部技术,是用技术手段高效率地实现在线和离线的混合使用,同时做到成本最低。它更多的是一个技术问题,而不是砍人或者砍项目的问题。
12 月 28-29 日,QCon 全球软件开发大会即将落地上海,中国科学院外籍院士、国际数据库专家樊文飞院士,英特尔大数据技术全球 CTO 戴金权等大咖会亲临现场分享大数据、芯片、架构等方向的前沿洞见。这次会议主要探讨大模型的全面技术架构的进化,不仅有跟大模型本身相关的推理加速、AI Agent、GenAI,还有架构的演进思路、性能优化,以及以智能代码助手为代表的研发效能提升等方向,会议目前 9 折优惠中,感兴趣的朋友可以扫码屏幕下方的二维码添加小助手,了解参会详情。





