
本文最初发布于 Travis Fischer 的个人博客。
这是一个系列文章的第一篇,从更实际的角度探讨“Twitter 算法开源”会是什么样子。
简介
埃隆·马斯克最近呼吁开源 Twitter 的算法,我作为一名热衷于开源且经验丰富的软件工程师,受此启发开始研究这个领域。我的主要目标是尝试回答下面这个问题:
Twitter 算法开源究竟会是什么样子?为了回答这个问题,我们首先需要回答一些相关问题:
为什么要开源 Twitter 的算法?
当我们说“Twitter 的算法”时是指什么?
Twitter 的核心数据模型是什么样子的?
Twitter 的网络图是什么样子的?
推特的算法推送是如何工作的?
我们应该了解的主要工程挑战是什么?
动机
马斯克为什么要接管 Twitter?用他自己的话说:
我们对 Twitter 这个公共平台的信任程度越高,文明的风险就越小。马斯克的动机很明确,与他的惯常做法一致。这也是他如此努力地在火星上建立一个可持续发展的殖民地的原因,也是他投入资源了解 AI 超级智能的潜在危险的原因,还是他如此坚持应对气候变化的原因。
他的指导性动机是为了增加人类拥有积极未来的可能性。
与我们大多数人不同的是,为了达成目标,他有能力在这个过程中投入大量的资金。无论是通过投入个人财富,还是通过投入他作为世界上最成功的连续创业者的丰富经验,他目标的纯粹性、奉献精神和实际成果都无可辩驳。
马斯克和 Twitter 前首席执行官杰克都认为,增加 Twitter 核心算法的透明度和可选性会使全世界受益。围绕言论自由、审查制度、隐私、机器人军团、回声室......有太多合理的担忧。从根本上讲,这都是些微妙难解的话题,对它们进行有意义的改进的唯一方法——同时最大限度地提高公众对平台和彼此的信任感——将是围绕处理方式提供更高的透明度。
因此,剩下的目标就是“开源 Twitter 的算法”,这在理论上听起来非常好,而且实际上可能有利于Twitter的核心业务,这就比较难理解了。因此,让我们看看能否从工程的角度增进对这个对话的了解。
Twitter 是如何工作的
主时间线视图
Twitter 为用户提供了两个版本的主时间线视图:默认的算法推送“主页”以及 “最新推文”。最新推文视图更简单一些,上面是一个推文的逆时列表,来自你直接关注的账户。这曾经是默认视图,直到Twitter在2016年推出了算法推送。
算法推送是大多数人使用 Twitter 的方式,因为默认设置影响很大。Twitter 对算法推送的描述如下:
你在 Twitter 上所关注的账户的推文流,以及我们根据你经常互动的账户、参与讨论的推文以及其他更多信息推荐的你可能感兴趣的其他内容。这个“以及其他更多信息”中隐含着很多复杂的东西。我们稍后会深入地探讨下,但首先让我们了解下,为什么 Twitter 要使用算法推送。理由很简单,就是用户体验:
你在 Twitter 上关注了数百人-——也许是数千人——当打开 Twitter 时,你可能会觉得自己错过了他们一些最重要的推文。今天,我们很高兴地分享一个新的时间线功能,帮助你追踪你所关注的人的最佳推文。(来源;2016)从用户体验的角度来看,这种解释很有道理,而且,算法推送无疑为 Twitter 试验这个产品提供了更多的自由。
然而,真正的动机是,算法推送是由 Twitter 目前采用的广告驱动的商业模式所推动的。推送更多相关内容⇒更高的参与度⇒更多的广告收入。这是一个被证明有效的、经典的社交网络策略。
好了,我们在更高层次上了解了 Twitter 的算法推送,现在让我们更深入地了解下它底层的工作机制。
核心数据模型
要理解像 Twitter 这样的复杂系统,一个比较好的方法是,从理解它的核心数据模型开始,然后从那里开始一步步往上。这些资源模型以及它们之间的关系构成了 Twitter 所有高层业务逻辑的基础。
我们将重点关注Twitter公共API的最新版本(v2),该版本最初于 2020 年发布。
核心资源模型
核心推文关系
时间线(Timelines)—— 来自特定账户的逆时推文流。
喜欢(Likes)—— 喜欢推文是一种核心的用户互动行为,表达对推文的兴趣。请注意,“喜欢”在历史上曾被称为“收藏”。
转发(Retweets)—— 转发让你可以将另一个用户的推文的阅读范围扩大到你自己的受众。
核心用户关系
屏蔽(Blocks)—— 屏蔽帮助人们限制特定账户联系他们、查看他们的推文以及关注他们。
静音(Mutes) —— 将一个账户静音,让你可以从自己的时间线上删除一个账户的推文,而不需要取消关注或屏蔽该账户。被静音的账户不会知道你把他静音了,你可以在任何时候取消静音。
龟背上的世界
Twitter 的公共 API 还暴露了其他资源模型(如空间、列表、媒体、投票、地点等)和其他关系(如提及、引用推文、书签、隐藏回复等)。为了尽可能地专注重点内容,我们将暂时忽略这些。
请记住,这也只是公共 API。在内部,像 Twitter 这样的平台是一个由服务、数据库、缓存、工作流、人以及所有把它们整合在一起的粘结剂所组成的复杂网络。我毫不怀疑,Twitter 在其公共和内部 API 的不同层次上使用了不同的抽象,这取决于各种因素,如 API 的使用对象、性能要求、隐私要求,等等。如果想要简单地了解下这种复杂性,可以阅读《Twitter背后的基础设施:规模》(2017)。
换句话说,就是龟背上的世界,我们有意限制了自己,只考虑几只乌龟——但其他的乌龟是存在的,在我们讨论的过程中,一定要牢记这点。

Sam Hollingsworth《龟背上的世界》
网络图
像 Twitter 这样的社交网络就是超大图的实例,节点是用户和推文的模型,边则是回复、转发和喜欢等互动的模型。
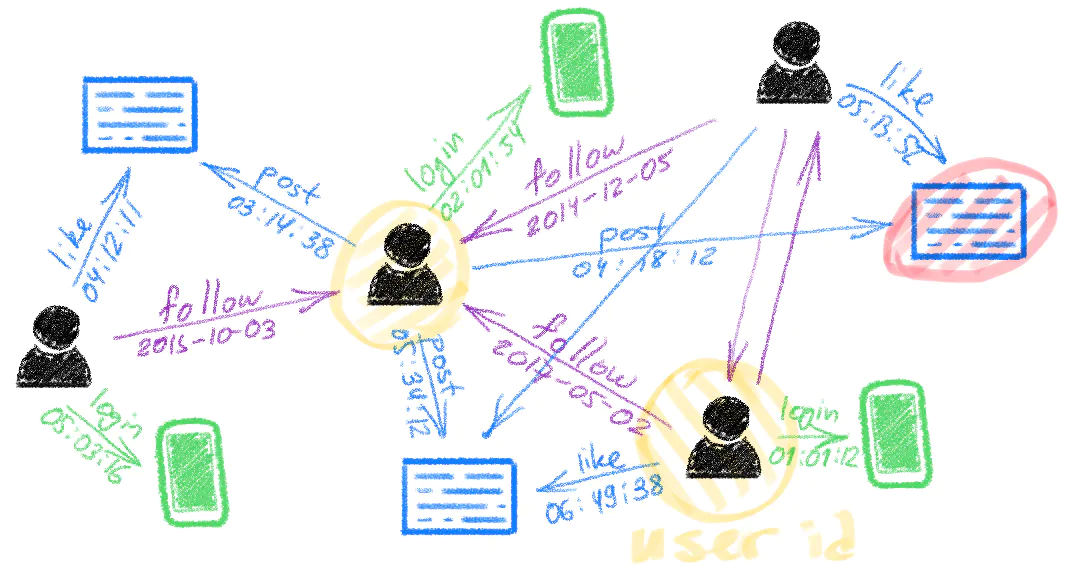
Twitter 动态网络图的可视化,作者是Michael Bronstein,来自 Twitter 的Graph ML部门(2020)。
推特的核心商业价值有很大一部分来自于这个庞大的由用户、推文和互动构成的基础数据集。每当你登录、查看推文、点击推文、查看用户资料、发布推文、回复推文等——你在 Twitter 上的每一次互动都会被记录到内部数据库。
从 Twitter 的公共 API 获得的数据只是 Twitter 内部跟踪数据中的一小部分。这一点很重要,因为 Twitter 的内部推荐算法可以获得所有这些丰富的互动数据,而任何开源工作都可能仅能使用一个有限的数据集。
推送算法
摘自“在Twitter时间线上使用大规模深度学习(2017)”:在引入排名算法之前,时间线的构成很容易描述:你所关注的人自你上次访问以来的所有推文都被收集起来,并按时间倒序显示。虽然这个概念很容易理解,但要为 Twitter 数以亿计的用户可靠地提供这种体验则是一项巨大的基础设施和运营挑战。
对于排名,我们额外做了些调整。在收集到所有推文之后,会有一个相关性模型对每条推文进行评分。该模型的得分预测了一条推文对你来说有多大的意义和吸引力。然后,得分最高的推文会显示在你的时间线上方,其余的则显示在下方。“
推特的算法推送是由一个个性化推荐系统提供的,用于预测你最有可能与哪些推文和用户互动。关于这个推荐系统,最重要的两个方面是:
用来训练 ML 模型的基础数据。这就是我们上面所描述的 Twitter 的大规模专有网络图。
在确定相关性时考虑的排名信息。让我们深入了解下这些排名信息,以理解 Twitter 的“相关性”是什么意思。
排名信息
摘自“在Twitter时间线上使用大规模深度学习(2017)”:为了预测某条推文是否会吸引你,我们的模型考虑了以下特征(或要点):
推文本身:它的新近度,存在的媒体卡(图像或视频),总互动数(如转发和喜欢的数量)。
推文作者:你过去与这个作者的互动,你与他们联系的强度,你们关系的起源。
你:你在过去觉得有吸引力的推文,你使用推特的频率和程度。我们考虑的特征及其各种互动的清单在不断增加,为我们的模型提供了更多存在细微差别的行为模式。“
这个 2017 年的排名信息描述可能有点过时,但我毫不怀疑,这些核心信息在 2022 年仍然高度相关。这份清单很可能已经推广到几十甚至几百个重点机器学习模型,它们支撑着 Twitter 的算法。
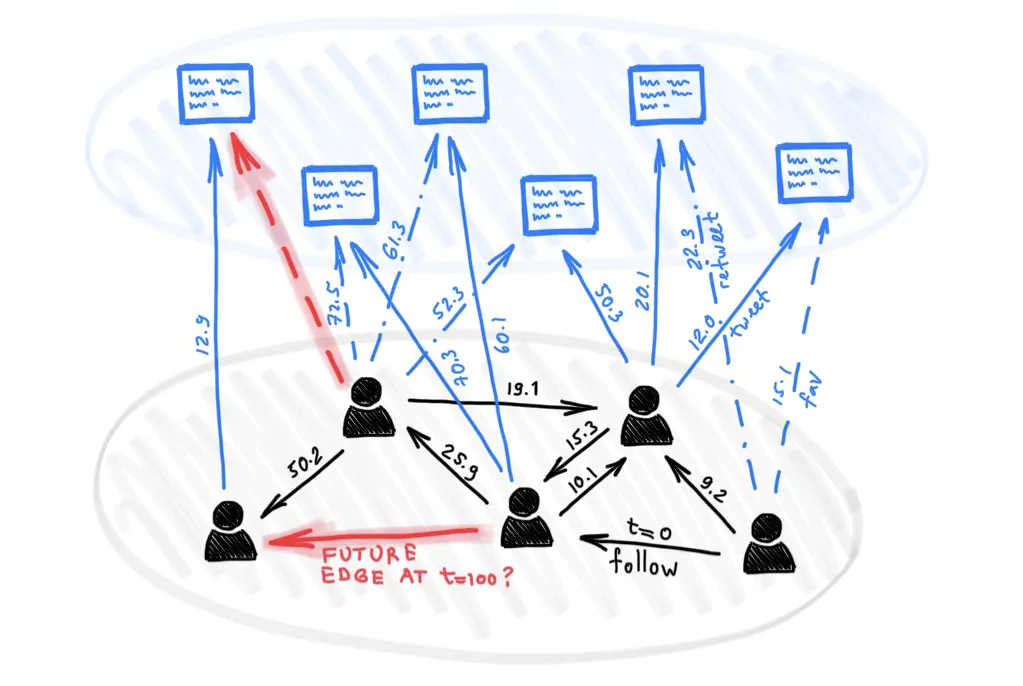
一个深度学习模型的可视化,用于确定一个用户在未来关注另一个用户的可能性。这个模型代表了 Twitter 内部各种推荐系统的一小部分。图片来源:动态图上的深度学习;2021年
算法推送伪代码
如果你是一名开发人员,那么这段 TypeScript 伪代码可能更有助于说明 Twitter 的算法推送是如何工作的:
export abstract class TwitterAlgorithmicFeed { /** * 伪代码,帮助理解Twitter算法推送的工作原理。 */ async getAlgorithmicTimelineForUser(user: User): Promise<Timeline> { const rawTimeline = await this.getRawTimelineForUser(user) const relevantTweets = await this.getPotentiallyRelevantTweetsForUser(user) const mergedTimeline = await this.mergeTimelinesForUserBasedOnRelevancy( user, rawTimeline, relevantTweets ) return this.injectAdsForUserIntoTimeline(user, mergedTimeline) } /** * 返回特定用户所关注的用户的推文流,按时间逆向排序。 */ abstract getRawTimelineForUser(user: User): Promise<Timeline> /** * 返回给定时间内按与给定用户相关度排序的推文流。 * * 仅考虑给定用户没有关注的用户的推文。 */ abstract getPotentiallyRelevantTweetsForUser(user: User): Promise<Timeline> /** * 返回按与给定用户相关性排序的推文流,同时考虑最新推文的原始时间线, * 以及包含潜在相关推文的网络图时间线子集。 */ abstract mergeTimelinesForUserBasedOnRelevancy( user: User, rawTimeline: Timeline, relevantTweets: Timeline ): Promise<Timeline> /** * 返回一个推文流,将广告注入给定用户的时间线。 */ abstract injectAdsForUserIntoTimeline( user: User, timeline: Timeline ): Promise<Timeline>}TypeScript 伪代码用于理解 Twitter 的算法推送是如何工作的。请注意,这只是为了演示,已经大幅简化。GitHub上有完整的源代码。
工程注意事项
将 Twitter 算法推送的各个方面开源,难免会遇到一些重大的工程挑战。

Twitter 的一位高级工程经理对开源 Twitter 的算法推送作出了这样的反应。
规模
第一个挑战是规模。Twitter 的网络图非常大。为了保证良好的用户体验,工程和运营方面的挑战往往超过了其他必要的考虑。
以下几点可以帮助你了解我们正在谈论的规模:
Twitter 的网络图包含数以亿计的节点和数十亿的边。(来源;2021年)
推特全球月活跃用户超过 3 亿。(来源;2019年)
平均每秒钟有~6K 条推文发布,超过 600 万次获取时间线的查询。(来源;2020年)
“发生在推特上的公共对话通常每天产生数以亿计的推文和转发。这可能使得 Twitter 成为世界上最大的图结构数据生产者之一,可能仅次于大型强子对撞机”。(来源;2020年)简单地说,大多数开发者甚至大多数公司都没有能力在实验环境中处理如此大量的数据,更不用说在类似生产的环境里。
为了应对这一挑战,Twitter 为特定的 API 合作伙伴提供公共Tweet Firehose的1%抽样版本,以及获取更小过滤流子集的能力。
此外,Twitter 的规模在构建图机器学习算法时提出了一些独特的挑战,因为他们的网络图必须在强一致性与最终一致性之间做选择。这使事情变得复杂,因为不能保证图中的每一个节点都有相同的特征。
实时
Twitter 的实时性带来了另一个独特的挑战。用户希望 Twitter 尽可能地接近实时,这意味着底层网络图是高度动态的,延迟成为一个真实的用户体验问题。当用户刷新推送的推文时,他们希望得到近乎即时的结果,而且是全球范围内秒级刷新。在底层网络图不断变化的情况下,要有效地做到这一点非常困难。
时序图网络是 Twitter Research 的一个有趣的开源项目。他们提出了一个在高度动态图(随着时间的推移而变化)上进行深度学习的框架,将图表示为时间事件的序列。
可靠性
另一个主要挑战是平台的可靠性。数以亿计的人将 Twitter 作为自己在线数字身份的核心组成部分。在运行像 Twitter 这样的全球性平台时,要保证可靠且良好的用户体验和正常运行时间预期,其固有的工程和运营挑战难以想象。
安全 &隐私
摘自“重建Twitter的公共API(2020年)”:“平台从一开始就最关心的一个方面是,提供健康的公共对话服务,保护 Twitter 用户的个人数据。
新平台将所有与安全和隐私相关的逻辑推给后端服务,严格规定了相关业务逻辑的位置。其结果是,API 层与此逻辑无关,隐私决策统一应用于所有的 Twitter 客户端和 API。
通过隔离做出决策的地方,我们可以防止数据暴露不一致。这样,你在 iOS 应用程序中看到的内容将与你通过 API 编程查询得到的内容相同。“
小结(截至目前)
希望这篇文章能帮助你了解 Twitter 的算法推送是如何工作的,它的底层网络图是什么样子的,以及一些主要的工程考虑因素(在规模很大时是一个非常有挑战性的问题)。
这里有一些深层问题,我会在后续的文章中回答:
推特算法开源究竟会是什么样子?
是否有可能抽象出运行像 Twitter 这样的全球性生产系统所需的所有工程复杂性,并制定一份真正有用的开源软件规范或 API?
在无法访问 Twitter 的全部数据集的情况下,有可能产生有意义的结果吗?
有意义在这里到底是什么意思?我们将如何定义成功?
为了使之成为现实,需要做什么?
有什么实际的建议可以帮助改善现状?(因为我们没有 430 亿美元来购买 Twitter)
原文连接:What would open sourcing the Twitter algorithm actually look like?




