
在程序员的江湖里,流传着一些经典的老梗:
编程第一法则:如果代码莫名运行成功了,那就别动了~
架构第一法则:稳定运行多年的老系统,千万不要碰~
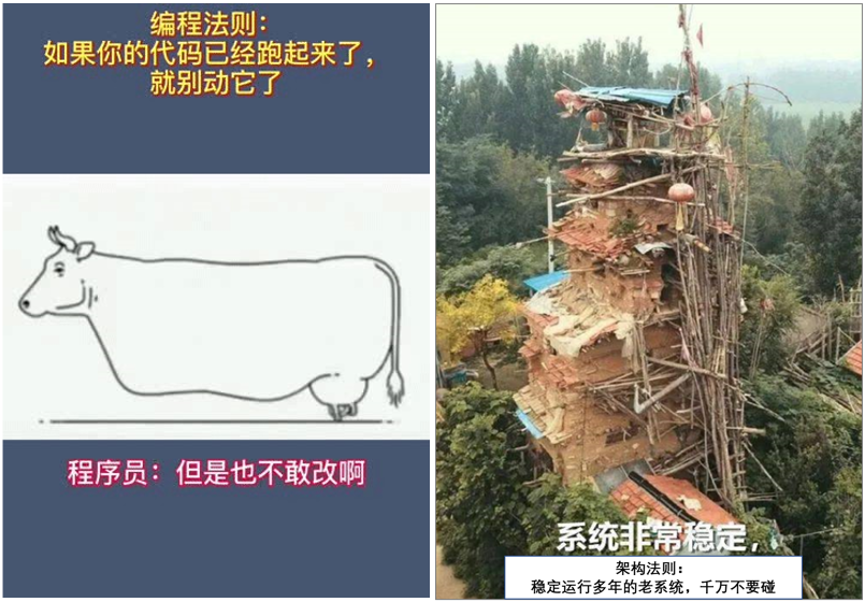
图片来自网络
初入行的程序员们接受前辈的洗礼,将如上的法则深深印入脑海,并广泛应用于日后的职业生涯中。
对于正在运行中的线上生产环境,不仅不敢乱碰,恨不得烧香供奉起来。
然而,技术系统的脆弱性来源是多方面的,不仅包含硬件的故障,代码的 Bug,还有架构和逻辑的漏洞,线上流量的各种突发性与不确定性等等。随着各个技术系统向云原生架构的迁移,架构中引入的依赖和不确定性也越来越多。
如何在日益复杂的技术架构下,实现系统的反脆弱,成为了一个程序员向架构师提升之路上的必修课。
2010 年,NetFlix 的工程师提出了混沌工程的概念,通过对线上生产系统主动注入故障,来验证系统在各种故障场景下的响应行为,提前识别并修复系统隐患。
它就像“疫苗”一样,故意将有害物质注入体内以防止未来疾病。对于复杂的技术系统,工程师们同样可以通过注入有限可控的故障,提前发现系统的弱点并进行修复,从而规避可能产生严重后果的大型故障。
混沌工程的引入,既是一个技术上的革新,也是一个观念上的突破。它抛弃行业前辈们过去死守的“线上系统千万不能碰”的老旧维稳观念,提出了“以攻代守”的稳定性建设的新思路,开启了在生产环境做攻防演练的新时代。
混沌工程在爱奇艺的发展
爱奇艺的攻防演练工作,最早是由各个业务自行组织开展的。如金融支付团队,因其业务特点对稳定性要求极高,很早就开展混沌工程相关工作。详见之前的文章《攻防大战的背后》。
在这个阶段,各个团队攻防演练使用的方法和工具都比较分散多样,没有形成一个统一的平台和工具标准。
在 2020 年初的疫情流量高峰期间,爱奇艺发生了一次播放失败故障。
在复盘后总结发现,这个大型故障其实是由一个小的网络抖动和代码 bug 引发的雪崩。这样的小问题平时隐藏在复杂的技术架构中,很难被一般的测试发现,然而庞大的系统却因为这一个小的异常,触发巨大的连锁反应。
自此,爱奇艺的技术团队开始大规模地在重点服务的生产环境里,推动落地常态化,标准化的攻防演练工作,同时建设了公司级的攻防演练平台—小鹿乱撞平台,用于支持各业务攻防演练的相关需求,提升攻防演练的安全性和执行效率。
截止到 2021 年 Q2,爱奇艺内部已有 20+重点业务通过小鹿乱撞平台进行攻防演练,平均每个重点服务的线上环境都经历了 3 到 4 轮的真实故障攻击演练。
小鹿乱撞平台的使用介绍
小鹿乱撞平台在爱奇艺承担着两个角色:
(1)业务自测:各业务系统的 Owner 可以通过小鹿乱撞平台,对自己系统的生产或测试环境进行故障自测,检验自己在服务中预设的各类高可用保障措施(报警/降级/熔断/灾备切流等)是否生效。
(2)红蓝攻防:由公司成立的独立的架构评估团队,从第三方视角,用随机化的攻击实验,验证重点业务系统的高可用水平,对关键服务进行第三方检验保障。

小鹿乱撞平台模块图
小鹿乱撞平台参考了公有云攻防演练优秀产品的设计,用户可以通过如下简单步骤来进行攻防配置:
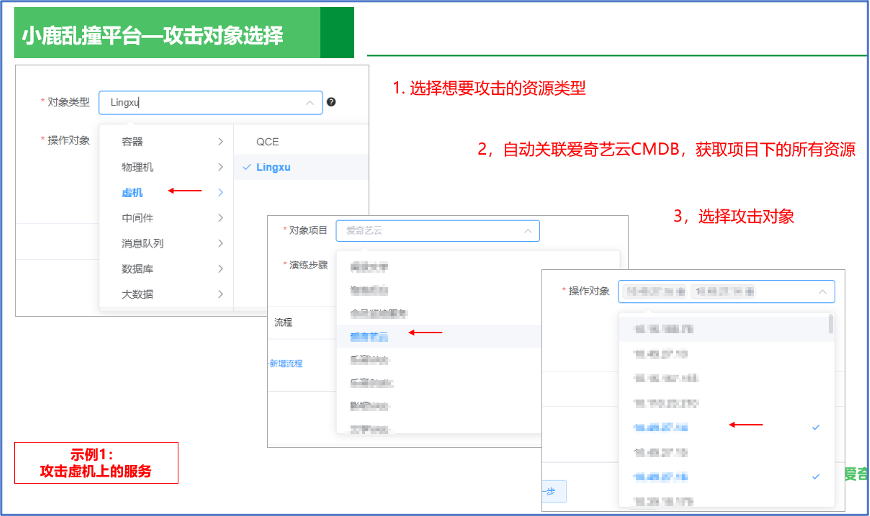
1.选择攻击对象
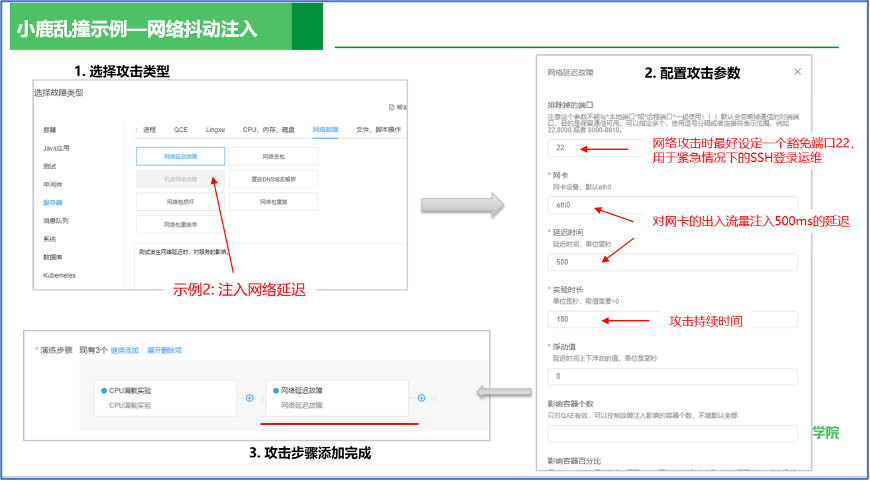
2.配置攻击方式
3.编排演练方案
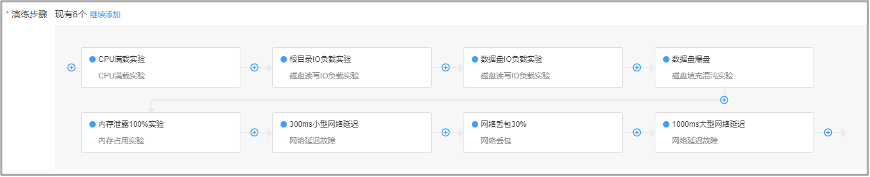
按照上面编排好的演练方案,提交审批之后就可以执行了。
4.演练观测
小鹿乱撞平台除了配置和编排演练方案之外,还打通了公司内部各个资源管理和监控观测系统,解决攻防演练中的权限,流程,可观测性等问题,为用户输出简洁有效的故障演练报告。
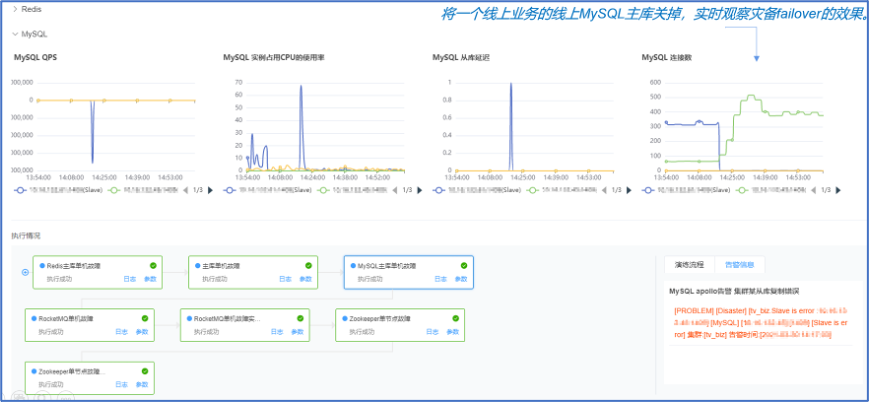
攻防演练进行中的观测:监控和告警
重点业务攻防演练案例介绍
案例一:视频播放服务 Couchbase 缓存故障演练
1.演练背景
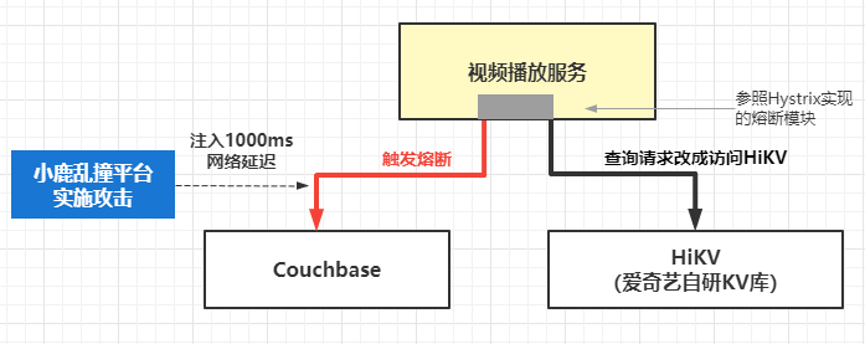
在上文提到的播放故障里,其中一个原因是由于网络抖动导致播放服务访问 Couchbase 的 SDK 连接使用异常,引发后续的连锁反应。
在故障后,播放服务的同学对架构中的依赖进行了一系列的熔断加固,当服务访问 Couchbase 依赖超时会触发自动熔断,服务请求改成访问备用 KV 数据库,并通过攻防演练重放网络故障,验证熔断加固的效果。
2.演练过程
在攻防演练中,我们选择攻击的方式是注入点对点网络故障,使视频播放服务所在的服务器与 Couchbase 集群之间增加 1000ms 延迟,模拟网络故障造成业务访问 Couchbase 超时。
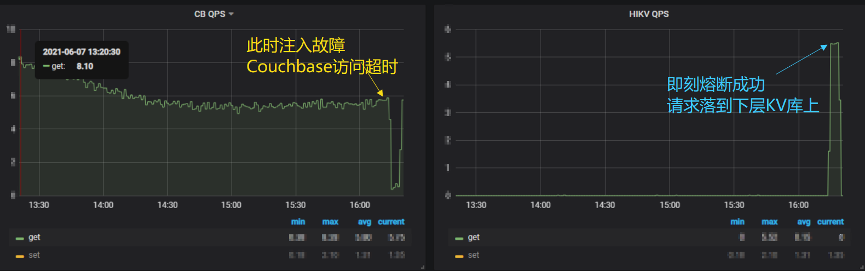
3.演练效果
顺利触发熔断,Couchbase 访问超时后,业务请求立即切换到 HiKV。
案例二:会员服务 Redis 分布式锁攻防演练
1.演练背景
爱奇艺会员服务团队统一切换到新的 Redis 分布式锁,并通过攻防演练检验新的分布式锁在各种故障极端场景下的可靠性。
2.演练过程
对 Redis 分布式锁进行三种不同故障攻击,分别检验分布式锁在这三类不同攻击下的效果表现:
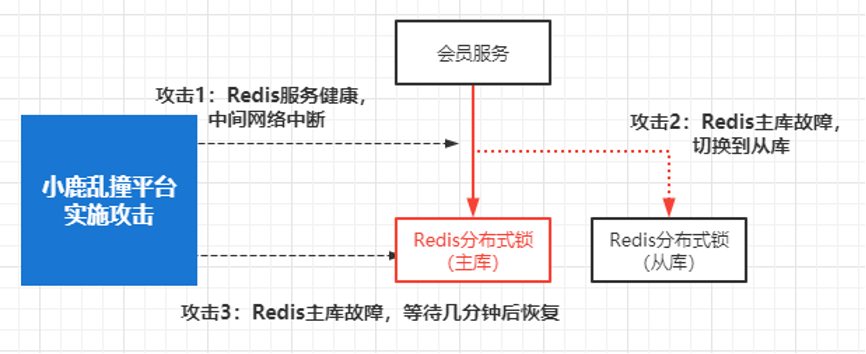
(1)场景 1:业务服务和 Redis 之间的网络断开,5 分钟后恢复
(2)场景 2:Redis 主库故障,触发主从切换到 Redis 从库
(3)场景 3:Redis 主库故障,不进行主从切换,经过 5 分钟后,重启 Redis 服务
3.演练效果
验证了 Redis 分布式锁在这三种极端场景下的业务影响,确定了业务侧在分布式锁故障期间的等待/重试等机制。根据 Redis 故障期间的分布式锁请求响应状况,指导业务调用方按照各自业务场景设置合理的等待间隔和重试配置等。
演练中常见的隐患和经验
回顾过去一年,在 20 多个业务线的生产环境里做攻防演练的经验,我们总结了一些具有普遍性或者较大危害性的问题,这里简单整理如下:
总结
在爱奇艺,经过一年多的混沌工程文化布道和系统性的线上攻防实操,核心业务的一线技术 Leader 都已经具备了相当的攻防意识。作者这里总结了各业务优秀的架构师们的两个共同特点:
1.零信任
任何一个服务都不是孤立的,包括 DNS、负载均衡、网关、虚机/容器、数据库、中间件、存储、网络、Cache 等大量基础服务依赖,以及大量的外部接口依赖,即使每个单独的依赖都有 99.99%的可用性,几十项依赖叠乘在一起的可用性也是不高的。
优秀的架构师从不会抱着一种 “某某依赖是基础服务,我的架构里假设它 100%可用,出了故障我直接给它甩锅” 的想法来做技术服务,而是尽量假设任意一个环节都可能出问题,以此来设计自己系统的高可用方案。
2.探索欲
优秀的技术负责人,对自己的服务架构的可靠性做到心中有数,能够明确地对着架构图中的任意一个点回答,这里的异常能抵挡,那里的异常会让服务故障。如果有不确定的异常点,会主动通过攻防演练进行探索。在测试/灰度等环境验证过的各类灾备/切流/熔断/降级机制,同样也敢去线上环境做攻击验证。
敢于对自己负责的线上服务进行真实攻击,是对未来云原生时代下架构师们的新要求,体现了技术 Leader 们的架构自信和技术自信。
自信源于对代码逻辑的深刻把握,对架构原理的理性思考,对业务责任的勇敢担当。
在未来云时代复杂的技术架构中,坚持这种技术自信,积极地参与到攻防演练的工作中,有利于加深架构理解,发现和修复服务隐患,为技术同学的能力成长开辟新前景,为公司业务的稳定发展保驾护航。
本文转载自:爱奇艺技术产品团队(ID:iQIYI-TP)




