
在 Serverless 的浪潮下,用户的运维成本越来越低,但调度的粒度还是不够细,高密度部署解决方案将函数部署粒度进一步拆分,直达容器内部,通过调度策略能够充分压榨服务器资源(CPU、内存等)。在此基础上搭配业界标准的 Web-interoperable Runtime,让用户的开发成本、运维成本进一步降低,同时提高资源利用率。
本文整理自字节跳动架构师朱凯迪(死月)在 ArchSummit 全球架构师峰会(深圳站)上的演讲分享,主题为“Serverless 高密度部署与 Web-interoperable Runtime 在字节跳动的实践”。分享主要分为四部分:1、Serverless ⾼密度部署;2、Web-interoperable Runtime;3、高密度部署在字节跳动的实践;4、未来展望。
1 Serverless ⾼密度部署
首先,我们先讲一下 Serverless 高密度部署。传统的 Serverless 有这么几个方向,一个是低门槛,然后有 Hostless、Stateless、弹性、分布式,以及事件驱动。
传统 Serverless
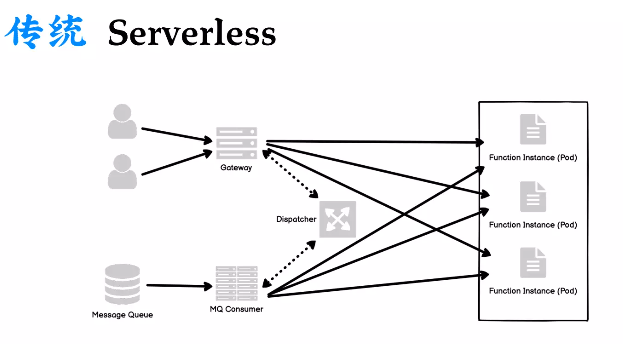
传统 Serverless 由于是事件驱动的,它的入口可以是 HTTP、消息队列或者定时任务,通过不同的 Triger 来触发函数,如果是 HTTP,则通过网关,如果是消息队列,则通过 MQ Consumer,最后分发到对应的函数 Instance。通常一个实例就是一个 Pod,Pod 里面通常会监听一个端口,传统 Serverless 的模型差不多就是这样的。
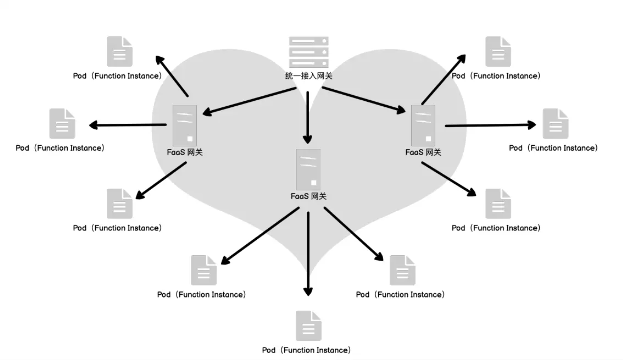
分层模型
我们再把它变成一个分层的模式来看,整个流量大概就是这么一个心型的脉络。流量首先进入一个统一的网关,再由第二层的 FaaS 网关去负载均衡到不同的 Pod,也就是刚才提到的函数实例,我们把这种方式称为一种二层调度,分别是机房调度或者说是 IaaS 层的调度,然后是 K8s 层的调度,相当于容器这一层的调度。在 2 层调度中,每一层都有它自己对应的交付时间,或者说弹性的时间。它们对应的交付时间分别是天级和分钟级或者秒级的交付。
交付时间会影响到 Serverless 的冷启动时间,通常在我们的实践过程中,函数的冷启动时间是不确定的,可以是几十秒,或者几秒,或者几百毫秒,这个跟不同的应用场景、不同的业务、不同的基础服务相关。其中有很多影响因素,比如设备性能、函数运行时、网络延迟、代码包大小,或者镜像大小等。总结起来,就是约等于一个容器的冷启动时间,它又影响着 Serverless 特性中非常重要的几点:一个是 Hostless,就是我们不需要管服务器;一个是 Stateless,就是无状态;以及弹性,一个函数用完,我们可以直接装垃圾筒扔掉,随起随停,用完就丢。这是我们现在 Serverless 很多情况下的一种使用方式,或者说 Serverless 本意就是想让大家这么做。流量来了马上启动起来,弹起实例,实例化出相应的函数;流量处理完了就马上删掉。这个做法对函数的冷启动有非常高的要求,冷启动的优化是在 Serverless 中大家需要去探索的一个课题。
高密度部署
冷启动优化
冷启动的优化方式有很多。对于供应商来说,可以更换设备提高一些性能,或者提升它的整个网络架构。对于业务方来说,可以用更轻量级的运行时。比如,如果它原来用 Java 之类的,可以换成 Node,也可以去合理组织函数代码,让函数更轻量,类似于微服务的方式。但是业务方不管怎么优化,最终启动时间还是约等于容器的冷启动时间。这个时候就有一个问题了,既然冷启动速度约等于容器时间,有什么东西可以比容器更快的?答案是有的,比如说弹起一个进程的时间肯定要比弹起一个容器的时间快,当然也有可能还有其它的方式,比如进程直接起好了,我们用线程去跑。所以我们在高密度部署里面,就有了两种方案,分别是进程和线程。

我们分别从四个维度对这两种方案做了比较,发现它们不同方面各有优劣。但我既要启动速度又要安全性,我们在进程的模式上加了一些黑魔法,让它的启动速度变得非常快,可以达到亚毫秒级别(≤ 1 毫秒)的启动。
三层调度
我们最终选了进程做高密度部署,它是一个三层调度,比之前的二层调度多了一层,就是在容器内部多了一个进程或者线程级别的调度,这个调度的交付时间可以做到非常快,到毫秒级甚至是亚毫秒级。
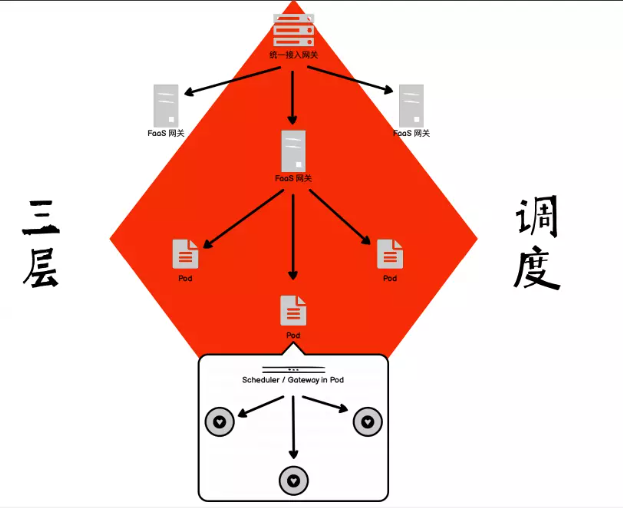
由于多了一层调度,之前的那个心型的脉络就变成了一个方块的脉络,流量从统一网关进到 FaaS 网关,再到 Pod,到了 Pod 之后,又多了一层节点,就是在容器内部又多了一个负载网关或者调度器,再流到不同的函数实例上去,这就是我们整个高密度部署的三层调度模式。
Executable as an Image 与 Process as a Container
业务方一般不想做运维的事,他们会觉得评估资源很烦,于是就怎么大怎么来,导致产生非常大的资源浪费。为什么业务方往往不愿意做这个评估?因为对于他们来说,估少了流量机器扛不住,如果要扩容,需要时间比较长,这个时候万一系统挂了就不好了,哪怕有熔断限流这些机制,部分用户不可用也是不好的。而高密度部署就可以帮他们解决问题,反正弹的快,可能一毫秒都不用就把函数弹起来了,流量来了马上弹起来,不用估直接用就好。这样就可以提高资源利用率。
弹性变高了,运维降低了,资源利用率也提高了,还会有什么问题呢?比如一个容器里面部署了多个函数,如果它们乱搞,最后一下子炸了,但没有做一些相应的资源限制和资源隔离,各函数之间可能就会相互影响。我们参考了云原生的 OCI 标准,提出 EaaI(Executable as an Image) 和 PaaC(Process as a Container),相当于跟 Docker 镜像和 Docker 容器对标,把可执行文件看成是镜像,把进程看成是容器。在启动的时候,可以理解为原来部署一个 Docker 容器,现在变成部署一个高密度的容器,高密度容器就是 PaaC,对应使用的二进制就是一个镜像,就是 EaaI。本质上它们就是一个可执行文件和进程,只不过我们在这中间加上了 OCI 的规范。开源社区有一个叫 RunC 的容器运行时,在 K8s 体系中容器可以通过 RunC 去启动,但是 RunC 只是用于启动容器的,并不能启动高密度容器。我们最后自研了一个叫 iku 的容器运行时,它是遵循 OCI 规范的容器运行时,用于启动高密度容器。而且我们的高密度容器也通过它做了一些资源的限制以及资源的隔离,就是规定一个容器只能用多少 CPU、多少内存,这个跟容器的限制是一样的。
2 Web-interoperable Runtime
Web-interoperable Runtime(Winter)是我们用于搭配高密度部署而研发的新函数运行时。首先解释一下,什么叫 Web-interoperable Runtime,它在以前有一个更糙且不严谨的名字,叫做 V8 Worker。因为好多厂商都基于 V8 做了 JavaScript 的运行时,但是后来经过标准化规范化之后,国际上的几家厂商就一起给它起了一个新的名字,并且开始做一些标准化的事情,组建了一个组织叫做 WinterCG(Web-interoperable Runtimes Community Group),它是由几家国际公司联合起来搞的 W3C 下的一个社区组,致力于做 Web-interoperable Runtime 标准化。
这里有一个核心的单词叫 interoperable,就是互通性,什么是互通性?就是运行时之间是可以互相替代、互相兼容的。各种浏览器之间就是 interoperable,经过标准化之后,大家 API 长的都一样,这就是所谓的互通性。Node.js 几个大版本也是开始往 Winter 上靠,市面上的 Winter 除了 Node.js 之外还有 Deno、CloudFlare Workers、Oxygen + Hydrogen 等等。我们自己也有一套自研的 Winter 运行时,叫 Hourai.js,它是用于我们的高密度部署的。
Winter 相较于 Node.js 来说,有一些很好的优势,比如低门槛,因为写 JS 的前端开发者们更熟悉浏览器 API。选择 Node.js 你要自己实现一个服务器,你要监听端口,自己去实现整个 HTTP 服务器,除此之外,你还要搞它的 PM2、运维、部署,等等。如果上了 Winter 就简单了,我们不需要监听端口,只需要监听 Fetch 事件,之后直接把它上到高密度部署,其他什么事都不需要管,它直接会触发事件,我们只要写里面的逻辑就可以了。

回顾一下,高密度部署是希望可以解决随起随停、用完就丢的问题,主打的是轻量以及启动速度快。Node 冷启动大概需要两百毫秒,那么 Serverless 函数至少要两百毫秒往上了,我们当然也可以通过池化,或者 snapshot 之类的来进行优化,但是为什么这么麻烦,为什么不直接一点?我们 iku 里面就提供了一个 ASSS 能力,即 Active Safety Strip Snapshot,专攻启动速度,最终达到了小于一毫秒。
3 高密度部署在字节跳动的实践
我们有一组实践数据,某服务迁移到线程级高密度部署,CPU 核数从原来 287 降低到 24,内存从原来 574G 降低到 39G。所以,高密度部署就约等于更高的资源利用率 + 更快的调度速度 + 更低的运维成本。

我们也做了其它的一些事情,比如往云原生上去靠,实现了 OpenTelemetry 这一套 API,Hourai.js 通过可观测性相关 API 传到它的 Agent,再到 Collector,最后再传到我们内部的一些系统,这就是整个 API 链路。
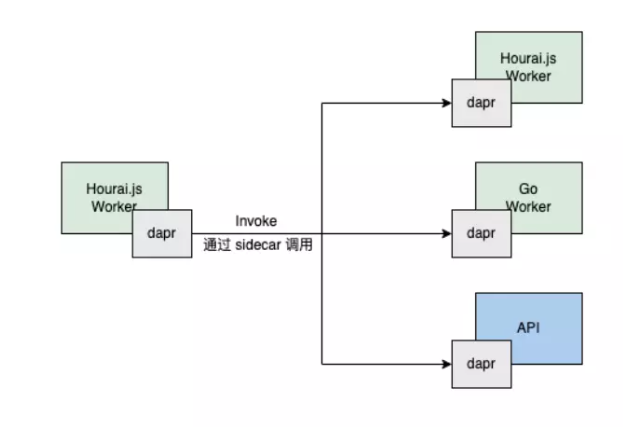
在多运行时调用上面,我们也有一套实践,就是遵循了 Dapr,在拿到 Dapr 的实例之后,直接 Invoke,把对应的参数传进去,不需要管多运行时的那些 SDK,这个就是云原生给我们带来的好处,大家既然上了 Serverless 干脆就全套上云原生。
我们还针对不同的场景做了抽象,它可以根据不同的业务需求来进行扩展,对上可以去接不同的网关层,对下可以接到不同的 IaaS 层,比如说私有化部署,它可能没有字节内部的 FaaS 环境,但很方便就能把我们的高密度部署部到类似于 ECS 的环境。
Serverless 还有一个非常合适的场景,就是流程编排。Serverless 流程编排是流程里面不同的 Function,一个一个节点流过去,它的高密度部署相较于传统的来说更适合这个方式,就是一个函数流过去,马上就启动这个函数,用完马上就丢,非常适合流程编排。因为高密度部署就是更高的资源利用率,更快的调用速度,以及更低的运维成本。因为它弹的更快,流程编排内容非常细粒度的东西就非常好上;然后更低运维成本对于编排的用户来说,关心的就是只要写下一小段代码片段就好了;更高的资源利用率也是毋庸置疑的。
关于 APP 网站,首屏速度非常重要,因为首屏时长的长短等同于一个用户的转化率,如何优化首屏时间也是一个亘古不变的课题。我们目前正在跟字节跳动的前端框架团队合作,就是用 Modern.JS,加上边缘机房,加上高密度部署以及 Winter,整理出了一套边缘上的高密度部署渲染方案,以此来提高首屏渲染的速度。
4 展望未来
未来在高密度部署方面,我们可以让 K8s 直接穿透我们的一个调度,穿透到容器内部来。因为我们也是遵循 OCI 标准的,理论上 K8s 可以直接调进来,不用先调到容器,容器再调进来,它可以直接穿透进来,启动我们的高密度容器,甚至,它可以抛弃容器,直接部署到物理机上,作为高密度容器让 K8s 直接调度,甚至可以替换掉 K8s,直接由我们的 iku 做整个调度。
在 Winter 这一方面,我们要做一个更极致的 ASSS 能力,以及分布式的极速启动能力,我们现在的 ASSS 能力都是以单机为单位的。另外,我们可以与社区一起去推进 WinterCG 的发展,往后会对外进行 ToB,或者之后有可能会去做一些开源的事情。
相关阅读:
Serverless Devs 重大更新,基于 Serverless 架构的 CI/CD 框架:Serverless-cd




