
WeNet 是出门问问和西北工业大学联合开源的端到端语音识别⼯具,WeNet基于 PyTorch 生态提供了开发、训练和部署服务等一条龙服务方。自上线以来,在 GitHub 已经获取近千 star,受到业界的强烈关注。本文介绍了作业帮的 WeNet + ONNX 端到端语音识别推理方案,实验表明,相比 LibTorch,ONNX 的方案可获得 20%至 30%的速度提升。
一、Why ONNX?
ONNX(Open Neural Network Exchange)格式,是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架(如PyTorch, MXNet)可以采用相同格式存储模型数据并交互。将深度学习模型转为 ONNX 格式,可使模型在不同平台上进行再训练和推理。除了框架之间的互操作性之外,ONNX 还提供了一些优化,可以加速推理。
二、PyTorch 转 ONNX
将 PyTorch 模型转为 ONNX 格式在⼀定程度上是⽐较简单的,PyTorch 官⽹有较为详细的说明。
值得注意的是,PyTorch 转 ONNX 格式的 torch.onnx.export()⽅法需要 torch.jit.ScriptModule 而不是 torch.nn.Module,若传⼊的模型不是 SriptModule 形式,该函数会利用 tracing 的方式,通过追踪输⼊tensor 的流向,来记录模型运算时的所有操作并转为 ScriptModule。当然这种方式进行转换,会导致模型无法对动态的操作流进行捕获,比如对 torch.tensor 的动态切片操作会被当做固定的长度切片,一旦切片的长度发生变化便会引发错误。为了对这些动态操作流程进行保存,可以使用 scripting 的方式,直接将动态操作流改写为 ScriptModule。
三、具体困难和我们的解决方案
由于目前的 ONNX 主要还是应用在 CV 领域,在处理这种非序列模型时,转写和应用都比较方便,然而,其对 NLP、ASR 领域的序列模型,特别是涉及到流式解码的应用场景支持比较有限,将 PyTorch 训练的 U2 模型转为 ONNX 格式并在推理时调用,相对而言是个比较麻烦的事情。主要困难有两个:
1、不支持 torch.tensor 转 index 的切片操作
这点上面有提到,若使用 tracing 方式进行转写,对 torch.tensor 的切片,只可能是静态切片如:data[:3] = new_data,这里的 3 只能是固定值 3,不能是传入的 torch.tensor;或者依靠传入的 torch.tensor 作为 index,来对张量进行切片,如 data[torch.tensor([1, 2])] = new_data。除此之外是不支持其他动态切片方式的,如 data[:data.shape[0]]。WeNet 流式解码时,需要 encoder 对输⼊的 cache tensor 进行切片操作,这里当然可以通过一次次地传⼊需要切片的 index tensor 来进行切片,但这样做明显将模型变得复杂了很多,利用 scripting 的方式将需要切片的的操作直接改写为 ScriptModule 是更可取的方式,如 EncoderLayer 模块中,我们添加了
@torch.jit.scriptdef slice_helper(x, offset):return x[:, -offset: , : ]将
chunk = x.size(1) - output_cache.size(1)x_q = x[:, -chunk:, :]residual = residual[:, -chunk:, :]mask = mask[:, -chunk:, :]改写为
chunk = x.size(1) - output_cache.size(1)x_q = slice_helper(x, chunk)residual = slice_helper(residual, chunk)mask = slice_helper(mask, chunk)但是值得注意的是,若将 torch.nn.Module 转为 torch.jit.ScriptModule,模型在 PyTorch 上是无法进行计算的,即无法进行训练。按照通用做法,可以将训练代码和转写代码分为两部分,一个专门用来训练,一个专门读取模型并转写。实际上,也可以简单地在使用到 scripting 的模块中,添加 bool 属性 onnx_mode,在训练时设置为 False,转写时设置为 True 即可:
def set_onnx_mode(self, onnx_mode=False):self.onnx_mode = onnx_modechunk = x.size(1) - output_cache.size(1)if onnx_mode:x_q = slice_helper(x, chunk)residual = slice_helper(residual, chunk)mask = slice_helper(mask, chunk)else:x_q = x[:, -chunk:, :]residual = residual[:, -chunk:, :]mask = mask[:, -chunk:, :]2、不支持传入 NoneType 类型参数
对 WeNet 流式解码,encoder 部分在第一个 chunk 输入时,输入的 cache 都为 NoneType,而在后续 chunk 特征输⼊时,各 cache 会储存不同大小的值进行输入,这样做主要是为了避免重复地对每一帧特征进行计算。然而因为 ONNX 转写的模型不支持 NoneType 输入,无法简单地导出一个模型进行推理,最原始的想法是在导出 ONNX 模型的时候,通过调整输入不同值(不输入 cache、输入 cache),导出两个模型,在第一个 chunk 输入时使用前者,后续 chunk 输入时使用后者。这种方法减轻了代码量,但是明显不太适合,毕竟 encoder 部分参数占了整个模型一半以上,无论是线上还是本地化实现,两个 encoder 导致的体积增加是难以容忍的。
我们的方案是正常导出传入非 NoneType 参数的模型,但是在 runtime 调用时,第一个 chunk 不再输入 None,而是一个 dummy 的张量。subsampling_cache 及 elayers_output_cache 输入音频长度为 1、值为 0 的张量,conformer_cnn_cache 直接输入长度为 cnn_kernel_size - 1、值为 0 的张量(对应 causal CNN 前置的 padding)
batch_size = 1audio_len = 131x = torch.randn(batch_size, audio_len, 80, requires_grad=False)subsampling_cache = torch.randn(batch_size, 1, 256, requires_grad=False)elayers_output_cache = torch.randn(12, batch_size, 1, 256, requires_grad=False)conformer_cnn_cache = torch.randn(12, batch_size, 256, 14, requires_grad=False)对应的,训练完模型后,在导出模型时的 encoder 的实现代码中,需要将每次输⼊的第一帧音频特征舍去,它不参与实际运算。利用前文提到的 onnx_mode 属性,我们可以实现训练时正常使用所有特征,转 ONNX 模型时忽略掉第⼀帧,如在 attention 计算时,提取 x_q 的 chunk 需要改为
if onnx_mode:chunk = x.size(1) - output_cache.size(1) + 1else:chunk = x.size(1) - output_cache.size(1)除了上述两个较为明显的问题,转 ONNX 模型还有⼀些坑需要注意,比如前文提到 tracing 是通过追踪输入 tensor 的流向来定位参与的运算,而不能通过其他类型如 List[tensor],encoder 模块中的 forward_chunk 函数各个层的 cache tensor 不能使用使用 list 来保存,必须要通过 torch.cat 函数合并成 tensor,否则在调用 ONNX 模型时,对模型输出的索引将会出错。(如下面的代码不修改,输出 output 对应索引位置的值,不是 r_conformer_cnn_cache,⽽是 r_conformer_cnn_cache[0])
r_conformer_cnn_cache.append(new_cnn_cache)改为
r_conformer_cnn_cache = torch.cat((r_conformer_cnn_cache, new_cnn_cache.unsqueeze(0)), 0)另外需要注意的是,通过 tracing 来追踪模型的 opts,如果模型传入的 tensor 没有被使用,导出的模型就会认为不会输入该参数,若输入该参数会导致报错。最后,ONNX 不支持 tensor 转 bool 变量操作,训练的 python 脚本中大量的 assert 将无法使用,不过具体使用时这个可以不用考虑。
四、具体实现
说完了困难和解决方案,具体实现就非常简单了。首先 U2 模型是分为三个大块,encoder、CTC 以及 decoder,我们需要分别对三个块进行导出,最简单的 CTC 不必多说,decoder 由于不涉及到 cache,也较为简单,不过为了方便 decoder 的输出能直接被使用,我们在导出 decoder 时去掉了不需要的输出,并且将输出的值进行 softmax 变换
if self.onnx_mode:return torch.nn.functional.log_softmax(x, dim=-1)else:return x, olens对 encoder,按照第二部分将动态切片部分和 cache 的 dummy 进行处理后,按照如下操作将 encoder 的 forward 函数替换为 forward_chunk 即可进行导出。
model.eval()encoder = model.encoderencoder.set_onnx_mode(True)encoder.forward = encoder.forward_chunkbatch_size = 1audio_len = 131x = torch.randn(batch_size, audio_len, 80, requires_grad=False)i1 = torch.randn(batch_size, 1, 256, requires_grad=False)i2 = torch.randn(12, batch_size, 1, 256, requires_grad=False)i3 = torch.randn(12, batch_size, 256, 14, requires_grad=False)onnx_path = os.path.join(args.output_onnx_file, 'encoder.onnx')torch.onnx.export(encoder,(x, i1, i2, i3),onnx_path,export_params=True,opset_version=12,do_constant_folding=True,input_names=['input', 'i1', 'i2', 'i3'],output_names=['output', 'o1', 'o2', 'o3'],dynamic_axes={'input': [1], 'i1':[1], 'i2':[2],'output': [1], 'o1':[1], 'o2':[2]},verbose=True)onnx_model = onnx.load(onnx_path)onnx.checker.check_model(onnx_model)print("encoder onnx_model check pass!")# compare ONNX Runtime and PyTorch resultsencoder.set_onnx_mode(False)y, o1, o2, o3 = encoder(x, None, None, i3)ort_session = onnxruntime.InferenceSession(onnx_path)ort_inputs = {ort_session.get_inputs()[0].name: to_numpy(x),ort_session.get_inputs()[1].name: to_numpy(i1),ort_session.get_inputs()[2].name: to_numpy(i2),ort_session.get_inputs()[3].name: to_numpy(i3)}ort_outs = ort_session.run(None, ort_inputs)np.testing.assert_allclose(to_numpy(y), ort_outs[0][:, 1:, :], rtol=1e-05, atol=1e-05)np.testing.assert_allclose(to_numpy(o1), ort_outs[1][:, 1:, :], rtol=1e-05, atol=1e-05)np.testing.assert_allclose(to_numpy(o2), ort_outs[2][:, :, 1:, :], rtol=1e-05, atol=1e-05)np.testing.assert_allclose(to_numpy(o3), ort_outs[3], rtol=1e-05, atol=1e-05)print("Exported encoder model has been tested with ONNXRuntime, and the result looks good!")导出模型后,WeNet 的 runtime 也需要根据导出的模型进行修改,最主要是对 dummy 的张量的处理,如原本的 TorchAsrDecoder 中,初始化的 subsampling_cache_、elayers_output_cache_、conformer_cnn_cache_应按照对应大小设置为全为 0 的张量(其他数字也可以,反正不会参与运算),对应的,offset_初始值应该设置为 1,每次 Reset 的时候也应重新设置为上述值。其他方面按照 onnxruntime 给定的 API 以及 demo 就可以顺利完成后续集成的工作。
五、ONNX 效果实测
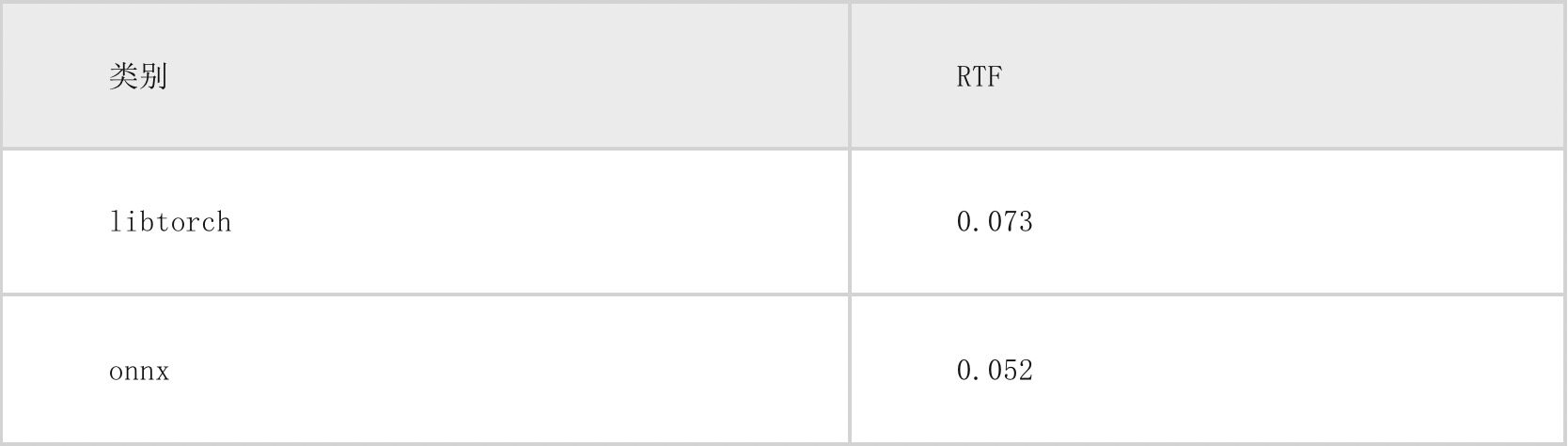
目前我们测试的结果是 onnxruntime 运行速度要相对 libtorch 提升 20%~30%左右,而且 ONNX 的解码器完成之后,也能依葫芦画瓢比较顺利的完成集成 MNN 的工作,便于后续可能的本地化加速需求,在 centos 服务器上,onnxruntime、libtorch 实时率对比见下表(2000 条音频测试结果)。
六、题外话:WeNet 训练相关调参经验分享
WeNet 自发布以来以其易用性以及模型优秀的落地效果获取了大量关注,从去年起我们就一直在跟 WeNet 的相关工作,同时也在 WeNet 的基础上做了大量相关实验,有一些相关经验可以和大家分享一下,需要说明的是,下述经验只在我们场景下的数据集得到了验证,不代表适应所有应用场景。
首先,对于数据,Spec Aug 数据增强部分,我们将 num_t_mask * max_t = 2 * 50 改为 4 * 25,对最终效果有能观察到的正向影响,猜想是短小而密集的 mask 更贴近白噪声效果;feature_dither 在训练和推理时都设为 true,效果也会更好。
其次关于模型训练的速度,为了最大化 GPU 的使用效率,可以在 GPU memory 足够的情况下尽可能把 batch 设的大一些。一般来说我们都会把数据按长度进行排序后,再分为不同的 batch 进行训练,因此可能存在的数据长度不均衡的情况,会导致静态 batch 大小往往受限于最长音频所在的批次,只能取较小值。为了避免这种情况可以采用 espnet 的经验,将 batch 设为动态的,每当音频长度增长到某些瓶颈就减小 batch 值,另外也可以直接在 WeNet 训练时,将 batch_type 设置为 dynamic,使用 data bucket 的方式限制每个 batch 音频的总长度,而不是每个 batch 的音频条数。
最后,对于模型大小,在我们的场景下(中文识别),线性层 units 个数从 2048 调整为 1024 对最终结果影响较小,可以为了更快地训练、识别速度进行适当调整。
七、关于作业帮
作业帮教育科技(北京)有限公司成立于 2015 年,一直致力于用科技手段助力教育普惠,运用人工智能、大数据等前沿技术,为全国中小学生提供更高效的学习解决方案。公司旗下有作业帮 APP、作业帮直播课、作业帮口算、喵喵机等多款教育科技产品。作业帮用户遍布全国各地,其中 70%以上来自于三线及以下城市。




