
本文最初发布于优步工程网站,经授权由 InfoQ 中文站翻译并分享。
引言
2017 年我们推出了Horovod,这是一个开源框架,可将深度学习训练任务并行扩展到数百个 GPU 上。当时,优步的大多数深度学习用例都和自动驾驶汽车的研发有关,而在米开朗基罗平台上,绝大多数生产级机器学习模型都是基于XGBoost的树模型。
如今已经是 2021 年,深度学习领域出现了很多变化。对于表格数据问题,深度学习模型相对于基于树的模型的性能优势越来越大,并且越来越多的深度学习模型在从研究转移到生产级别。因此,我们不得不重新审视现有的深度学习平台,以适应不断增长的需求和新的要求:
自动缩放和容错
超参数搜索
统一计算基础架构
自动缩放和容错
我们之前的深度学习平台分配了一个固定大小的 Horovod 群集来训练单个模型。在本地运行时,用户经常会发现自己由于资源不足而无法开始大型训练作业。我们提供了在云数据中心进行训练的选项,但由于平台缺乏自动缩放能力,意味着只能在专用实例上运行作业,其成本通常是在可抢占或“竞价(spot)”实例上运行成本的 3-5 倍。
就算资源容量不成问题,容错能力也常常存在瓶颈。随着作业训练的 epoch 增多,动用的机器越来越多,失败的几率也会增加。密集的检查点可以帮助缓解这种情况,但是需要大量额外的定制平台工具链来提供支持。
Elastic Horovod
在 Horovod v0.20 中我们引入了Elastic Horovod。它提供了分布式训练的能力,可以在整个训练过程中动态地扩展 worker 的数量。只需在现有的 Horovod 训练脚本中添加几行代码,当运行作业的机器加入或退出时作业都可以继续训练,几乎不会中断。
从 API 的抽象级别来看,Elastic Horovod 解决了自动缩放训练过程的问题,但并没有对其操作化。我们将 Elastic Horovod 编写为适用于任何特定编排系统或云提供商的通用平台,这意味着以下组件要留作待实现的接口:
发现可以添加到训练作业(或应从训练作业中删除)的主机
当额外 worker 可用且作业可以利用它们时请求资源
我们一开始的假设是,我们要在每个主流云提供商(例如 AWS、Azure、GCP)或编排系统(例如 Kubernetes、Peloton)各自的组件中实现这些接口,以支持内部和开源用户。
结果我们发现,已经有一个开源解决方案可以解决多云分布式计算的问题了:它就是Ray。
Elastic Horovod on Ray
Ray 是一个用于并行和分布式编程的分布式执行引擎。Ray 由加州大学伯克利分校开发,最初的目的是使用一个简单的基于类/函数的 Python API 来扩展机器学习负载和实验。
自诞生以来,Ray 生态系统已发展为可用于在云上训练 ML 模型的一系列功能和工具组合,包括用于分布式超参数调优的Ray Tune、用于群集配置的Ray Cluster Launcher,和基于负载的自动缩放(load-based autoscaling)。现在,Ray 还集成了多种机器学习库,如 RLLib、XGBoost 和 PyTorch。
借助新的ElasticRayExecutor API,Horovod 能够利用 Ray 来简化底层主机的发现和编排工作。要使用 Ray 搭配 Horovod 来实现弹性训练,你首先需要启动一个包含多个节点(Ray 群集)的 Ray 运行时。
Ray 运行时/群集:Ray 程序能够利用一个底层的 Ray 运行时完成并行化和分发工作。可以在一个或多个节点上启动这个Ray运行时,从而形成一个 Ray 群集。
Ray 打包了一个轻量级群集启动器,该启动器可简化任何云(AWS、Azure、GCP 甚至是 Kubernetes 和 YARN 等群集管理器)上的群集配置。这个群集启动器根据给定的群集配置来配置群集,如以下示例所示:

要在 AWS 上启动一个 Ray 群集,你只需将以上配置另存为`cfg.yaml`,然后调用`rayupcfg.yaml`即可。在上面的示例中,请注意头节点是一个纯 CPU 节点,而 worker 是 GPU 可抢占实例。
此外,可以将 Ray 群集配置为“自动缩放”,这意味着 Ray 可以在不同的负载要求下透明地配置新节点。例如,如果一个 Ray 程序在应用程序运行中需要一个 GPU,则 Ray 可以配置一个便宜的 GPU 实例,在该实例上运行 Ray 任务或 actor,然后在完成后终止该实例。
你可以查看 Ray 文档中关于在 AWS/GCP 上创建一个自动缩放 Ray 程序的示例。
ElasticRayExecutor API:ElasticRayExecutor 可以利用自动缩放的 Ray 群集来简化主机的发现过程,并在适当情况下请求更多资源。要使用这个 API,需要定义一个训练函数,其中包括一个使用Horovod Elastic状态同步装饰器的更高级别的函数:

然后,你可以附加到这个底层 Ray 群集并执行训练函数:

在这个示例中,ElasticRayExecutor 将创建多个 GPU worker,每个 worker 都参与一个数据并行训练例程。Worker 的数量将由群集中 GPU worker 节点的数量自动确定——这意味着即使节点因为抢占而被随意移除了,训练也不会停止。
如你所见,Ray 与 Horovod 的集成产生了一个解决方案,其简化了在主流云提供商之间使用 Horovod 运行弹性训练作业的操作。
基准测试和实验
在考虑采用弹性训练技术时,对我们来说最大的未知数之一就是收敛性。具体来说,我们不确定在训练期间可以多久调整一次作业的规模,能调整到什么程度,我们是否需要在训练期间进行任何调整以消除在运行时增加和减少 worker 数量的影响?
为了衡量动态调整 worker 数量对模型收敛的影响,我们使用 AWS 的 8 个 v100 GPU(p3.2xlarge 实例),在 Cifar10 数据集上运行了三个训练 ResNet50 模型的作业,固定 90 个 epoch。我们换了 3 种实验配置,调整了上下增减 worker 的频率以及每次添加/删除 worker 的数量:
固定 8 个没有自动缩放的 GPU worker(8gpu_fixed)。
最初 8 个 GPU worker,每 60 秒增加或减少 1 个(8gpu_60_1)。
最初 8 个 GPU worker,每 180 秒增加或减少 3 个(8gpu_180_3)。
对于每次调整事件,如果 worker 数量已经达到最大值(8),我们都会减少数量;如果 worker 数量达到最小值(2),则我们都会增加数量。否则,我们会随机以相等的概率增加或减少 worker 的数量。
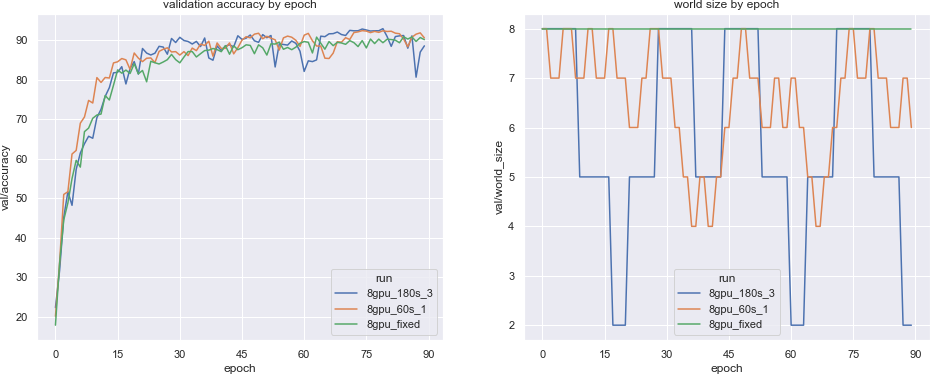
图 1:验证精度对 epoch 数的函数(左)和实验中每个 epoch 末尾对应的 worker 数(右)
如以上结果所示,我们观察到随着我们增加调整事件的幅度(通过一次添加/删除的主机数量来衡量)并按比例降低调整频率,各个 epoch 之间模型性能的总体差异增加了,相对于基线的整体模型泛化性能得到了实际改进。
弹性训练的另一个好处是,当调整事件的时机可以通过训练过程控制时,它甚至可以用来减少训练过程中的总体差异。如 Smith 等人在《不要降低学习速度,而是要增加batch大小》中所述,我们可以利用以下事实:增加 batch 大小会导致模拟退火效果,从而使模型训练从较早的探索阶段过渡到最终的利用阶段。
在实践中,与保持训练中 worker 数量不变的方法相比,通过增加 worker 数量来按比例扩大 batch 大小的这一过程让模型能够更快收敛,往往还有更高的泛化精度。
为了证明这种效果,我们进行了另一组实验:重复上面的训练过程,但有两个新配置:
固定 2 个 GPU worker(2gpu_fixed)
动态 worker 数量,每 30 个 epoch 加倍,从 2 开始,以 8 个 worker 结束(8gpu_exp)。
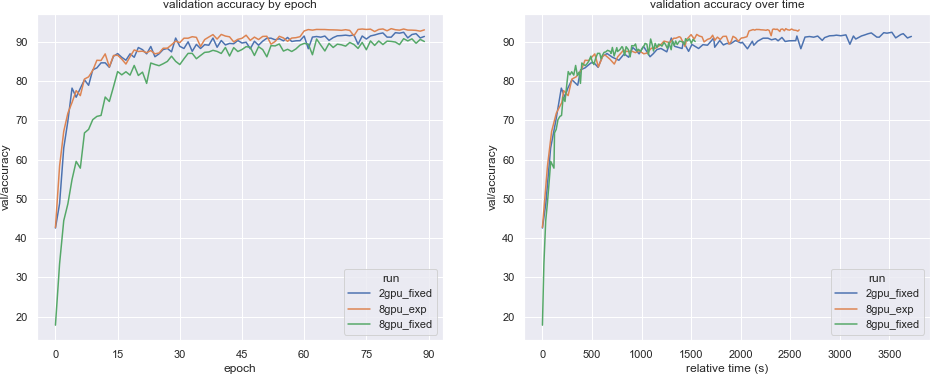
图 2:验证精度对 epoch 数的函数(左)和相对挂钟时间(从实验开始算起,以秒为单位)的函数(右)。
正如预期的那样,将 worker 数从 8 减少到 2 改善了整体模型的收敛。这引出了数据并行分布式训练中,当模型针对较小的 batch 大小做优化时存在的一个的常见陷阱。实践中,建议使用学习率预热/衰减、超参数搜索(见下文)和Adasum等技术来抵消这些影响。
上面展示的第三个实验说明了通过大量并行来实现良好收敛的另一种解决方案:随着时间的推移逐步扩展并行度。这种方法不仅获得了比 2 GPU 基线更少的总挂钟时间,而且还以更高的验证精度完成了这项工作!
正如 Smith 等人在上述论文中所解释的那样,其背后的原理是,训练过程将从最初的“探索”阶段过渡到最后的“利用”阶段,进而受益。增加并行度会增加 batch 大小,这有助于平滑训练示例之间的差异,从而减少训练后期的探索。
可以使用 Horovod on Ray 的 Callback API 将此功能添加到 Elastic Horovod on Ray 中:

这些回调还可以用来简化训练的其他一些部分,比如将消息从 worker 转发到驱动程序来简化日志记录和指标跟踪。
与超参数搜索结合使用时,这种方法可以提供最多的改善。与模拟退火对比(用于缩放 batch 大小)相似,许多现代超参数搜索算法也遵循“探索/利用”范式,该范式可与弹性训练结合使用,以实现最佳模型性能和最佳资源利用率。
超参数搜索
在开发深度学习模型的过程中,用户在进行大规模训练时经常需要重新调整超参数,因为许多超参数在较大规模上会表现出不同的行为。在自动缩放群集中进行训练时,这一点更加重要,因为要考虑其他一些可能会影响训练吞吐量、收敛性和成本的超参数,其中包括:
多长时间增加一次最大 worker 数/有效 batch 大小
多久提交一次共享 worker 状态,以在最短的时间内获得最多的 epoch
我们允许作业一次输入/删除多少 worker
使用 Horovod 大规模调整超参数通常会有些棘手。执行并行超参数搜索需要一个单独的更高级别的系统,以在可用资源上协调和调度多节点 Horovod 训练作业。米开朗基罗内部支持的AutoTune服务解决了编排长期运行的超参数搜索作业的一些基本挑战,但不支持基于群体的训练和提早停止策略,这些方法本应能让我们重新分配 GPU 资源以加速性能最佳的试验。
Ray 是基于对嵌套并行性的支持而构建的——这意味着它能够轻松处理“启动天然的分布式任务”的分布式程序。利用这一优势,我们开发了一个 Horovod+RayTune集成,以实现分布式训练的并行超参数调整。
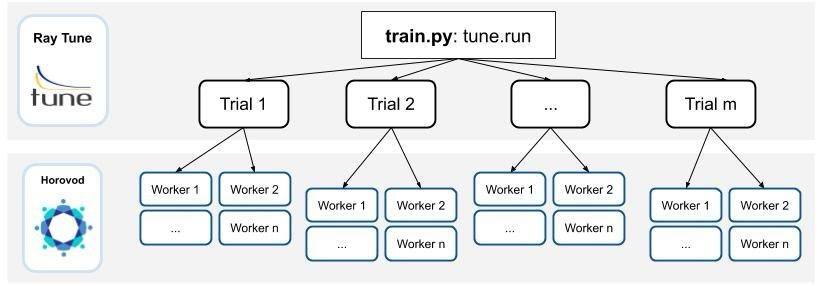
使用 Horovod+RayTune 进行带有嵌套超参数并行调整的分布式训练的示意图。
RayTune 是打包进 Ray 的流行超参数调整库。RayTune 包含一些最新的超参数搜索算法(例如基于群体的训练、贝叶斯优化和超频带),还支持故障处理,因此用户可以更好地利用模型性能与云成本之间的取舍来做超参数调整。
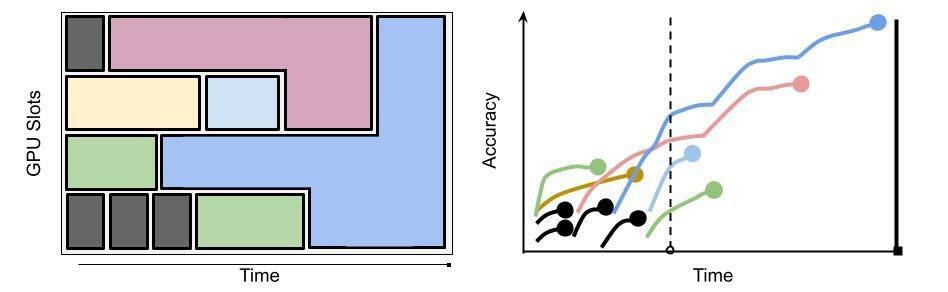
在时间限制下使用动态资源分配来改善模型训练性能的图形示意。像 HyperSched 这样的算法通过动态分配更多并行资源来逐渐将探索减少到零,从而更深入地利用更少的试验。
正如 Liaw 等人在《HyperSched:在最后期限前完成模型开发的动态资源重新分配》中所展示的那样,通过这种方式将超参数搜索与分布式训练相结合,可以让我们做到充分优化,在固定的时间内和计算资源内找到最佳模型。这对于像优步这样的组织来说特别有用,在该优步大多数训练都是在固定大小的本地 GPU 群集上进行的。
下一步:统一用于机器学习和深度学习的计算基础架构
我们将 Elastic Horovod with Ray 和 RayTune 集成的早期结果表明,Ray 这种将复杂的分布式计算系统脚本化为统一工作流程的方式,具有很好的灵活性和易用性。
除了我们先前讨论的挑战之外,机器学习平台通常还需要集成几种不同的技术,例如 SparkML、XGBoost、SKLearn 和 RLlib 等。这些技术运行在不同的计算平台上。例如在优步,ML 负载可以在通用的容器化计算基础设施(Peloton、Kubernetes)、Spark(YARN、Peloton)和 Ray(Peloton、Kubernetes)等平台上运行。结果,生产级 ML 管道经常被分解成许多不同的任务,并由诸如 Airflow 或 Kubeflow Pipelines 等管道编排器进行编排。这增加了平台的软件和运维复杂性。
过去,我们投资创建了很多定制系统来配置和运行深度学习工作流,但与 Horovod on Ray 相比它们存在许多缺点:
可扩展性:因为内部系统是为特定应用而非通用计算而设计的,所以要增加对 Elastic Horovod 之类框架的支持,需要对代码库进行重新配置,并自行实现 Ray 中提供的那种自动缩放器。
灵活性:为运行分布式深度学习而构建的系统无法轻松适应其他负载,例如数据处理(Dask、Modin)、超参数搜索(RayTune)或强化学习(RLlib)。
维护:与 Ray 这样的开源系统不同,我们的内部深度学习基础架构必须由专门的工程师团队维护,而他们的时间和精力可以用来解决更高级别的问题。
通过在 Ray 上整合更多的深度学习栈,我们可以进一步优化深度学习工作流程中的更多端到端过程。例如,当前我们在特征工程(ApacheSpark)和分布式训练(Horovod)之间存在清晰的界限。对于工作流的每个阶段,我们必须提供需要独立运行的单独计算基础架构,并将 Spark 流程的输出要素化到磁盘上,以便 Horovod 流程使用。当我们希望为工作流的不同阶段寻找替代框架时发现,这种架构不仅很难维护,而且替换起来同样困难。
能够切换不同的分布式框架是 Ray 的核心优势之一。由于 Ray 是通用的分布式计算平台,因此 Ray 的用户可以自由选择越来越多的分布式数据处理框架(包括 Spark),这些框架在 Ray 为深度学习工作流提供的相同资源上运行。这简化了我们的计算基础架构,因为 Spark 和 Horovod 负载之间不再存在上述的严格界限。实际上,根据数据量、计算强度和可用群集资源,针对不同的负载有不同的最优框架。此外,某些框架比其他框架更容易集成到现有项目中。
我们利用这些能力增强的一个项目案例是Ludwig,这是优步开发的开源深度学习 AutoML 框架。
过去,由于 Ludwig 依赖于 Pandas 框架进行数据处理,因此仅限于处理适合单台计算机内存的数据集。现在,在即将到来的 Ludwig 0.4 版本中,我们将在Dask on Ray上进行分布式大内存数据预处理,在 Horovod on Ray 上进行分布式训练,并用 RayTune 进行超参数优化。
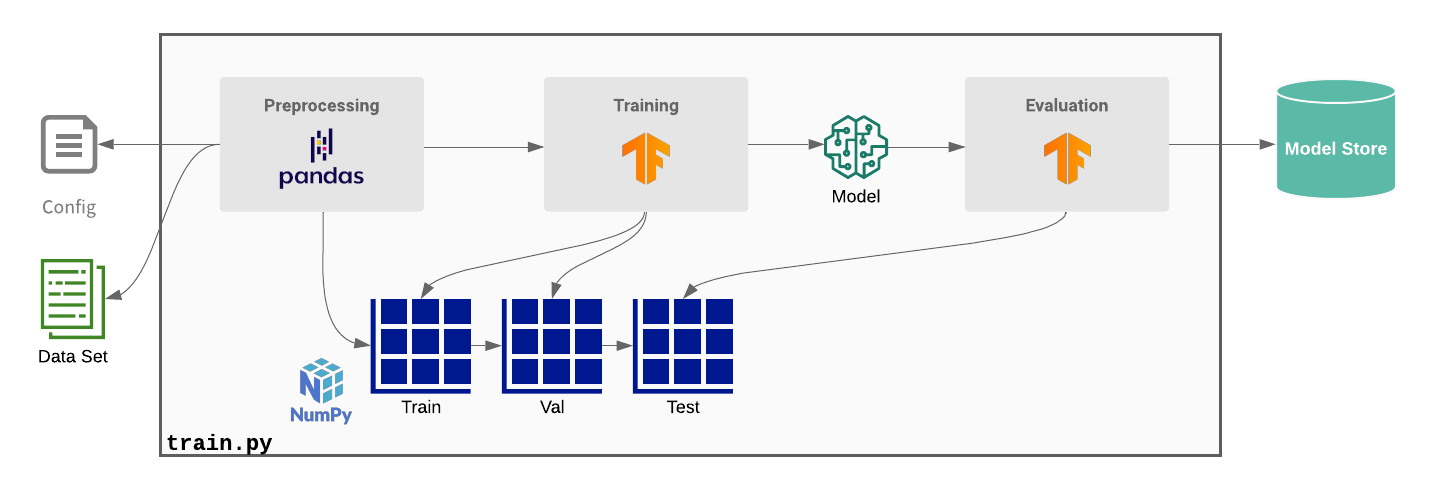
Ludwig 在本地模式下运行(v0.4 之前的版本):所有数据都需要容纳在一台计算机上的内存中。
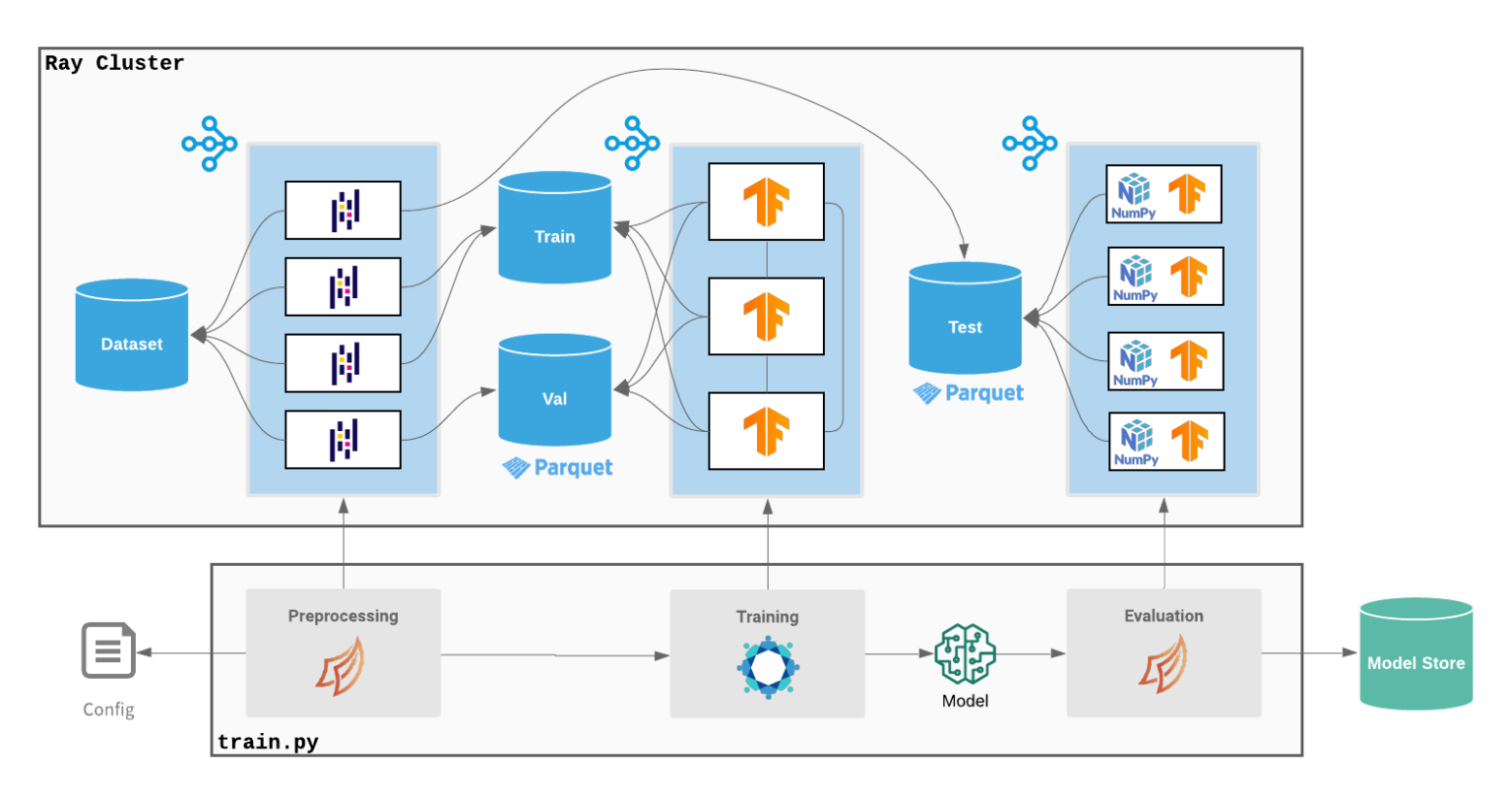
Ludwig 在 Ray 群集上运行(版本 v0.4):Ray 扩展了预处理和分布式训练任务,可以处理大型数据集,而无需在 Ludwig 中编写任何基础架构代码。
利用 Dask 可以扩展 Ludwig 现有的 Pandas 预处理,从而以最小的代码更改量实现大型数据集的处理;利用 Ray,我们可以将预处理、分布式训练和超参数搜索结合在一起,放进单个作业中运行的单个训练脚本。
对于 Ludwig 用户来说,这些功能不需要代码更改或其他基础设施配置更改,只需在命令行中添加“raySubmit”和“-backendray”即可:

我们相信,在优步和整个行业内,Ray 在为生产级机器学习生态系统带来行业亟需的通用基础架构和标准化方面将继续发挥越来越重要的作用。在接下来的几个月中,我们将分享更多关于将 Ray 的功能引入优步深度学习平台的相关工作。请查看Elastic Horovod on Ray,并随时提出任何问题、意见或建议。
致谢
我们想感谢以下人员的工作:
Richard Liaw 和 Anyscale 团队将 Horovod 与 Ray 集成在一起的努力,包括 Horovod in RayTune,以及他们对在优步集成 Ray 的持续支持。
Fardin Abdi 和 Qiyan Zhang 将 Elastic Horovod 与 Peloton 集成所做的工作。
来自 G-Research 的 Enrico Minack,他在 Elastic Horovod 上的工作及其与 Horovod on Spark 的集成工作。
Yi Wang,他在 ElasticDL 集成和 Elastic Horovod 基准测试方面的工作。
https://github.com/kuangliu/pytorch-cifar的作者提供了用于训练模型的 PyTorch 模型定义。
我们还要感谢所有 Horovod 贡献者,如果没有他们,这项工作是不可能完成的;感谢 Linux 基金会对 Horovod 项目的持续支持;以及 AWS 为我们的持续集成系统提供的支持。
作者介绍
Travis Addair 是优步 AI 的软件工程师,领导米开朗基罗 AI 平台的深度学习训练团队,领导 Horovod 开源项目,并主持 Linux 基金会内的技术指导委员会。
Xu Ning 是优步西雅图工程办公室的工程经理,目前领导优步米开朗基罗机器学习平台的多个开发团队。他之前曾领导优步的 Cherami 分布式任务队列、Hadoop 可观察性和数据安全团队。
Richard Liaw 是 Anyscale 的软件工程师,他目前领导基于 Ray 的分布式机器学习库的开发工作,是开源 Ray 项目的维护者之一,在读 UC Berkeley 的 PhD。




