
2019 年初,好大夫经历了几次严重的线上故障,面临了中间件和服务治理危机。很多故障都是因为业务系统中不规范的 SQL 以及慢接口造成的,严重的几次甚至雪崩到全站短暂不可用的程度,这种局面必须立即、彻底改变。于是,系统架构部痛定思痛,发起了“DOA"(Dead or Alive)工程,首先治理基础设施,提升中间件的稳定性和高可用。之后紧接着又发起了服务风险治理项目,识别慢接口,不规范的 SQL,依赖不合理等服务风险。
在大家砥砺前行的完成这两个大项目之后,全站的稳定性得到了大幅度提升。经过了这两年多的沉淀,现在我来汇报一下在做服务风险治理过程的相关经验心得,希望能带给大家一起启发。
说到风险,我先想到了认知意识,每个人对风险认知其实是不一样的,大概可以分为一下四类:
我意识到我已经知道了;
我意识到我不知道;
我意识不到我知道;
我意识不到我不知道。
在日常工作中,我们收集了不少开发工程师的反馈,给我印象最深的就是“我意识不到我不知道”。SRE 小组探索服务风险治理已经快两年了,迎来了新版本的迭代。借此机会,想和大家深入聊一下服务风险治理,拓宽彼此认知的边界。
这次分享主要分三个部分:
探险:首先梳理下开发工程师遇到的已知和未知的风险,介绍一下服务风险治理的相关概念名词;
冒险:介绍下我们如何识别、量化、追踪服务风险,如何整合到平台里的;
历险:现场工作坊,实战分析服务风险任务。
探险
不知道大家有没这样的疑问:
夺命线 p99 到底是个啥,p50,p75,p95 这一家子暗藏什么玄机?
我的服务接口平均响应耗时 30ms,是不是很健康,为何在蜘蛛抓取的时候,受伤的总是我呢?
常说的高层服务、低层服务、上下游服务、循环依赖、双向依赖、慢接口、慢 SQL 等等基本概念说的是什么?
到底有哪些因素影响服务的健康度?
衡量服务健康度的指标有哪些,是如何筛选的呢?
服务健康度是大吞吐量服务应该感兴趣的事吧,我的服务 QPM 才几十需要关心啥?
定时任务,异步消费者里面的慢接口不影响用户,不算风险吧?
DB 抖动造成的波动会不会生成风险任务?
我只关心自己的服务健康度,将聚合接口逻辑扔给前端可以吗?
...
且看我们是如何处理这些疑问的。
服务风险治理最终目标是为了服务健康,服务的健康体系是个复杂系统,影响因素很多,但我们需要抓住现阶段最大的风险。经过反复的对比,选择从延迟风险入手,也是为了达到公司预期“全站秒开”的大目标。借助 MDD(Metrics-Driven Development)指导思想,确定 SLI,设定 SLO。并围绕 SLO 去识别风险,解决风险。故此选择 SLI:接口延迟-p99。并设定了 SLO:后端服务 p99<100ms,前端服务 p99<600ms。
延迟
曾经有人问为啥不用平均耗时呢,选择 p99 是为啥,这里再解释一下。
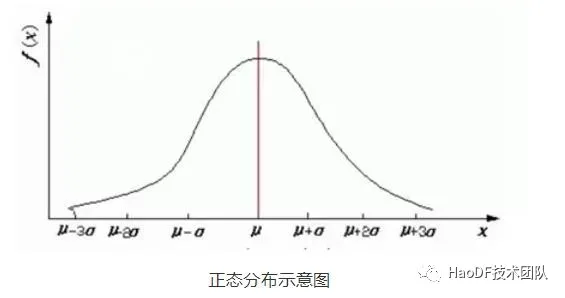
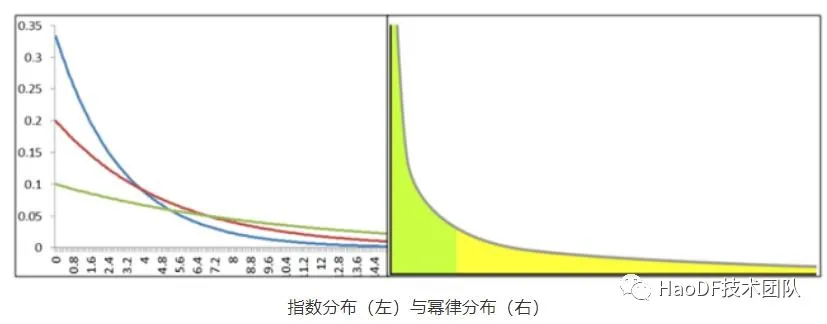
现实生活中普遍存在两种分布,正太分布 和 幂律分布。典型的两个例子:中国成年男性的身高符合正太分布,程序员的收入却符合幂律分布。那什么样的数据具备这样的特性呢?
一般如果有极值界限的,大多会符合正太分布,比如人的身高,体重,不可能无限大和无限小。
有人会说人的财富也有上限呀,为啥不是正太分布?由于财富聚集头部和尾部差距拉的过大,财富会在一连串聚集后,越来越分化,从而演化成了幂律分布。这么说可能有些人还是不太理解,有研究表明幂律分布一般由于连锁效应产生的,详细可以参考《失效的科学》。
这两种分布都具备长尾效应,取平均值就不能很好的反映模型特征。
服务延迟就是符合正太分布满足长尾效应,故此我们取 p99 作为 SLI。在服务延迟中,如果 p50,p75,p95,p99 无限接近,服务越稳定,p99 值越小服务具备了更高的抗压性,也就是弹性更强。p99 是个神奇的指标,我们以后会经常遇到。
好,关于为何选择 p99,应该大家都清楚了吧。接下来我们就围绕降低 p99 去挖掘服务存在的风险点。
寻找风险
哪些因素会影响接口延迟呢?
探寻很久,我们终于抓住了尾巴:依赖
监控服务依赖的延迟,就能顺藤摸瓜,从而解决了一大部分的高延迟服务风险。为什么这么说呢?
由于现在是微服务的架构,服务与服务之间,服务与中间件之间,服务与第三方接口之间,都可能隐藏风险点。监控好这些依赖的延迟,好把脉,服务风险治理就算成功一半了。
且看如何把脉。
第一大忌:服务之间依赖不合理
首先我们得了解几个基本概念:服务层级,高层、低层、上下游
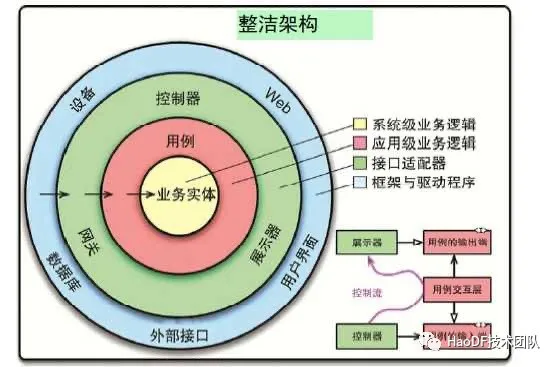
服务分层这部分分级模型我们参照《架构整洁之道》,大家可以看到越靠里同心圆,层级越高。
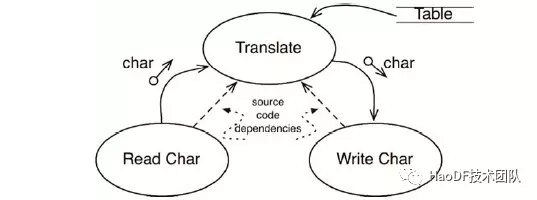
这是一个组件依赖模块示意图,其中 Translate 组件层级最高,同样我们服务也符合这种模型。
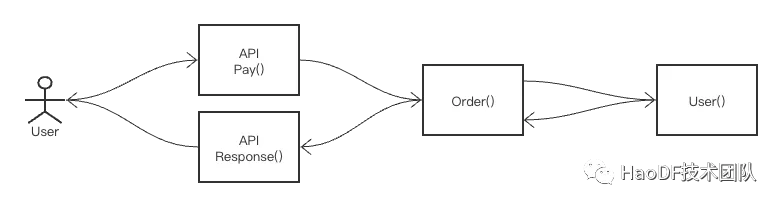
所谓高层、低层,我们这么界定,离用户侧越近层级越低,离用户侧越远层级越高。换个说法,离输入输出端越近层级越低。
上下游服务,符合数据流返回方向,从上游到下游,从高层到低层。
低层依赖高层,下游依赖上游,避免不合理的依赖成为风险点,如双向依赖,环形依赖等。
那依赖不合理为啥会影响延迟呢?
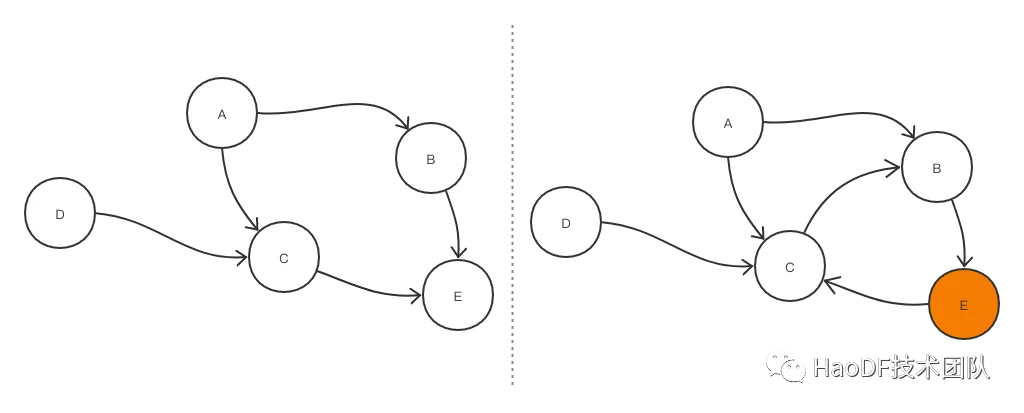
如果存在环形依赖 B->E->C->B,E 抖动会造成 C 负载高,从而可能造成 B 负载高,又会反过来作用 E。这时候排查定位问题会非常困难,三个服务都在告警,整个链路都在超时,恢复起来会非常麻烦。我们处理好合理的依赖,避免这样的情况产生,不要让已知风险成为定时炸弹。
由于网络开销成本较高,另外一个风险就是循环依赖。由于我们走的 http 协议,网络成本比较高,如果一次请求 50ms,循环 10 次就是 500ms。从而变成了大杀器。服务拆分并不是越细越好,做好服务边界的界定,减少不必要的服务间依赖。做好服务间依赖监控,就得依赖链路分析了。有机会我们再细聊这部分的实现。
第二大忌:中间件 100%可用
很多开发工程师对中间件的认知停留黑盒层面,要么盲目地认为中间件 100%高可用,要么认为中间件异常和我无关。然而中间件使用是否合理,是否存在风险点,一直是被大家忽视的一个问题。再加上中间件细节被框架屏蔽了,很多时候更是很难觉察到风险。这里先抛开中间件选型是否合理的问题,假设依赖的中间件都是合理的,我们来分析一下中间件延迟问题。
中间件一般分建连和执行两个阶段,由于框架的异构性,有的实现了连接池的长连接,有的是短连接。网络连接也是一种资源类型,也属于消耗品。延迟高会造成排队,更有可能造成雪崩事件。当然中间件应该要考虑如何防止雪崩有过载防护机制。那作为服务方是不是什么事都干不了呢?
我们要警惕这种思想,至少我们应该关注高延迟的事件,现在我们数据库和 redis 都是按服务维度隔离。延迟会直接反馈到用户请求的链路上。建连超过 1s 可能是资源不够用,吃不住这么大的流量。如果是执行慢,大部分需要考虑是不是姿势不太对,这里面主要是可能存在慢 SQL。
我们针对不同的事件也提炼出了一些风险任务。
首先是建连耗时及重试次数,这部分对短连接的场景下尤为重要,频繁建连会带来巨大的开销。我们选取 connection 耗时作为指标。
然后就是慢 SQL 风险任务,我们选取了执行时长作为指标,执行时长超过 1s 的需要重点关注。
其次我们大部分业务场景是基于 Mysql,如果有在大分页,或者查询结果集过大,或者有 like 语句,或者没有 where 条件等,极有可能造成服务内存泄漏和执行过慢的问题。
还有缓存依赖,锁依赖问题。大部分业务使用 Redis 做片段缓存和共享锁,获取锁超时异常,缓存被穿透等,可能会造成数据库被拖死,我们需要关注命中率和 Redis 交互的延迟。
另外 RabbitMQ 消费者,Prefetch count 预取数,如果消息过大,一次取的过多,都可能造成 OOM。php 框架与 RabbitMQ 心跳时间 60s,这块就需要 php 消费者耗时不能超过两个心跳周期,也就是 120s。
这块涉及的细节比较多,今天就不展开了,总之,服务不能太依赖中间件的 100%高可用,需要考虑失败的可能及一些技巧。拓宽自己的认知边界,以正确的姿势更好地使用中间件。
第三大忌:第三方服务的锅,我背不动
再讲一下第三方依赖吧,这块也是我在日常处理问题中比较常见的类型。一说第三方问题就各种抱怨,不是我的锅。业务需求不可避免要与第三方交互,基于 SDK 或 Http 等。常见的有用户请求同步等待短网址生成,调第三方语音转文字服务,调用腾讯 api,调用短信、电话运营商服务,调用 ios/友盟 sdk 推送等等。遇到最多的就是业务反馈 mq 消费者夯住了不再工作了,脚本执行超过 2 天了,用户请求大量 499 了等等。
大部分是过度信赖第三方,或者没有意识到第三方的问题,或者写代码的时候只考虑功能,未兼容异常情况。最常见的做法是需要做超时配置,如果是线程池或者长连接的模式,就需要做心跳保活机制了。提升第三方依赖高可用另外一个手段就是冗余备份,支持灾备切换。这部分只要意识到,做好几个关键指标的监控如延迟和成功率,基本上都能避免。
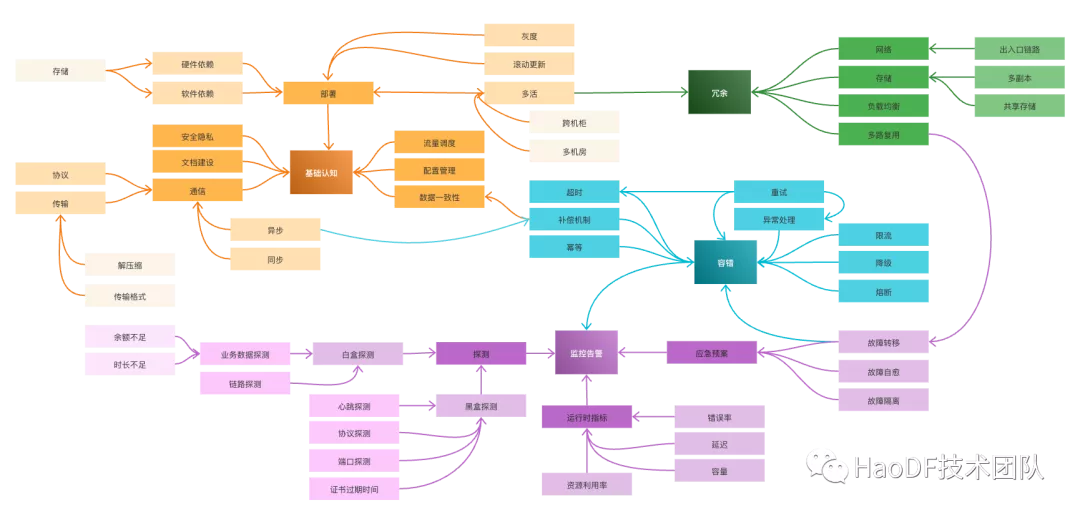
处理好这些依赖风险点,服务的整体稳定性就提高了,关于服务高可用其他的点可以参考下面这张图,这块有时间我们再细聊。
冒险
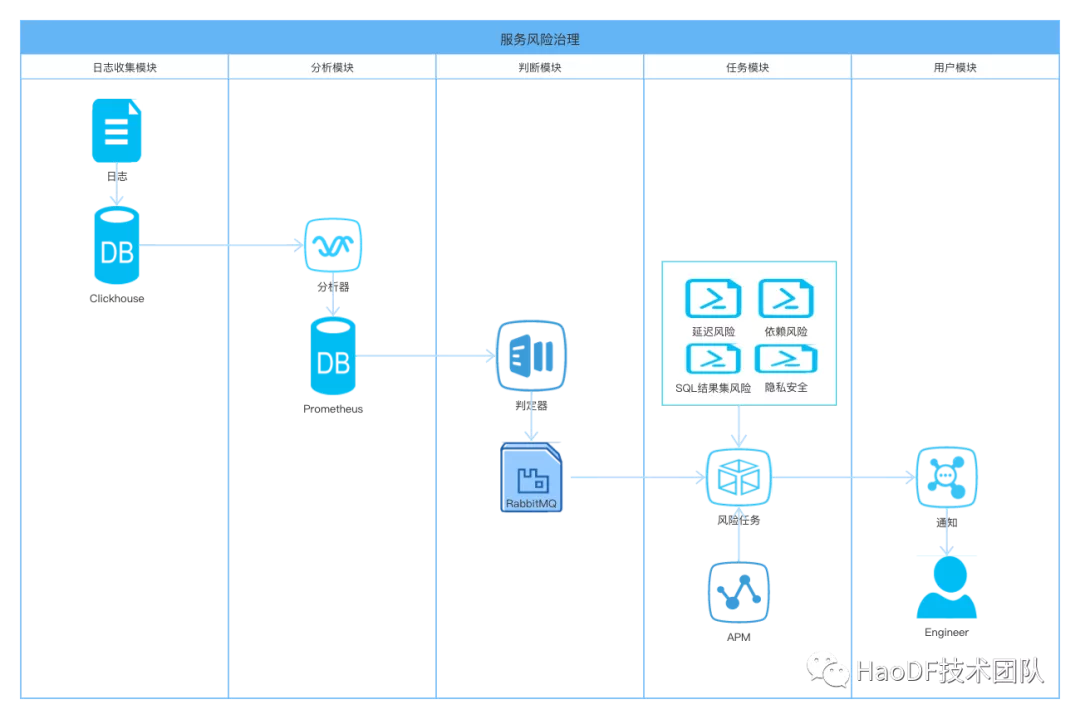
前面讲了我们是如何分析依赖提炼出风险任务,大家也有了服务风险意识。接下来分享一下我们是如何锤炼服务风险治理平台的。平台整体是基于链路日志分析,整合风险通知,整合 DBA 慢 SQL 优化建议,整合数据可视化画像。
下面简单聊一下平台设计中遇到的一些问题。
如何保障收益最大化?
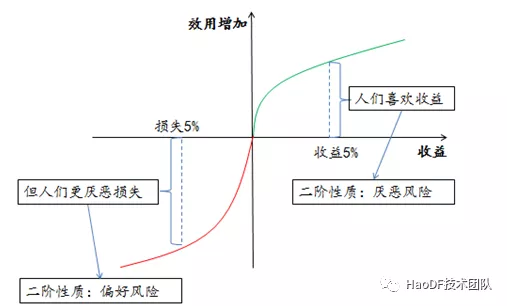
我们先来看一个模型,由于每个人对风险的好恶容忍度是不一样的。有的开发工程师会说 p99 才 200ms 左右,很健康呀。因此我们需要给定衡量的标准。
还有些开发工程师会考虑优化后的收益,有些任务优化成本低但收益不高,有些优化成本高但收益也大。因此需要评定风险任务的等级,让开发工程师关注质量而不是数量,以便抓住收益最大化。结合我们的现状,现阶段服务接口延迟风险是我们最大的痛点。
如何准确地识别服务延迟风险?为了识别延迟风险,制定收益最大化 SLO,我们做了很多实验,并参考业内其他公司的经验,我们结合 p99,慢接口 qpm 设定了标准。最终达到后端服务 p99 小于 100ms,前端服务 p99 小于 600ms。
sum(appslow_count>y) by(appname,method) and sum(appslow_p99>x) by (appname,method)如何让开发工程师抓住重点?我们有了 SLO,识别出延迟风险后,我们会根据耗时,访问量给任务打上不同的优先级。并且平台支持开发工程师分阶段制定优化计划,方便任务追踪。针对依赖的上游服务慢导致自己慢的,可以给对方送臭鸡蛋,催促对方优化。每个 Q 会统计臭鸡蛋最多的服务,邀请开发共赏。所以优先优化高风险和收到臭鸡蛋多的接口。
如何优化延迟风险任务?延迟风险具备相似的特性,有的存在循环调用,有的存在慢 SQL,有的存在依赖不合理等。基于不同的特征我们给风险任务打上不同的标签,针对每种标签给出相应的优化建议。如存在循环调用,就会给出具体的几组详情,配合 APM 链路分析,直达案发现场。如存在慢 SQL,打通 DBA SQL 优化引擎,给出优化建议。
如何实现数据可视化?风险任务优化周期一般比较长,服务的健康度需也要拉大时间维度去查看。不同的角色关注的维度也不太一样,不同的场景关注的维度也不一样。也就是平台需要具备 OLAP 数据库查询的能力,支持上卷,下钻按不同维度聚合数据并可视化展示。
按事业部维度:
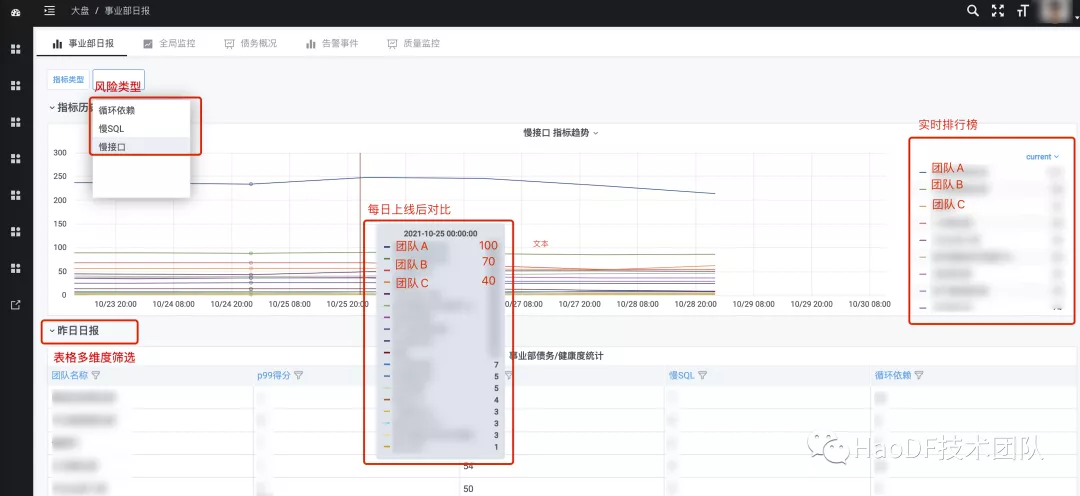
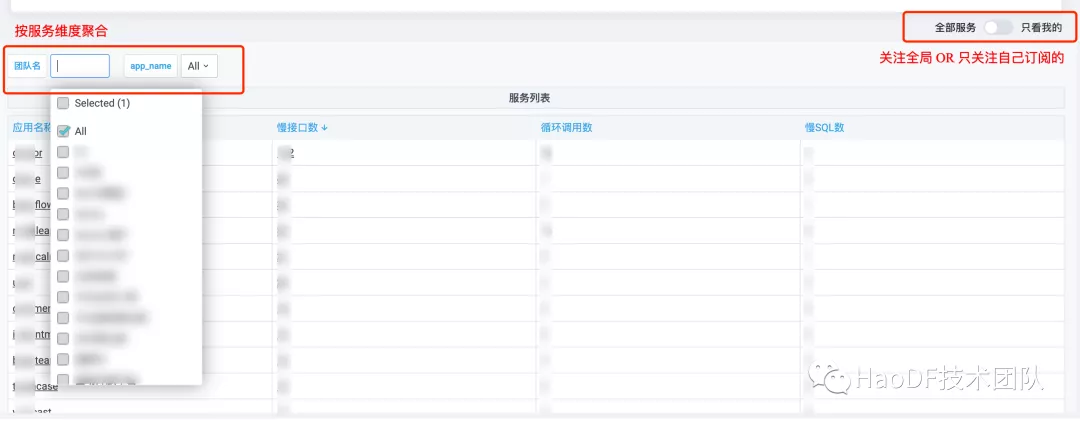
按服务维度:
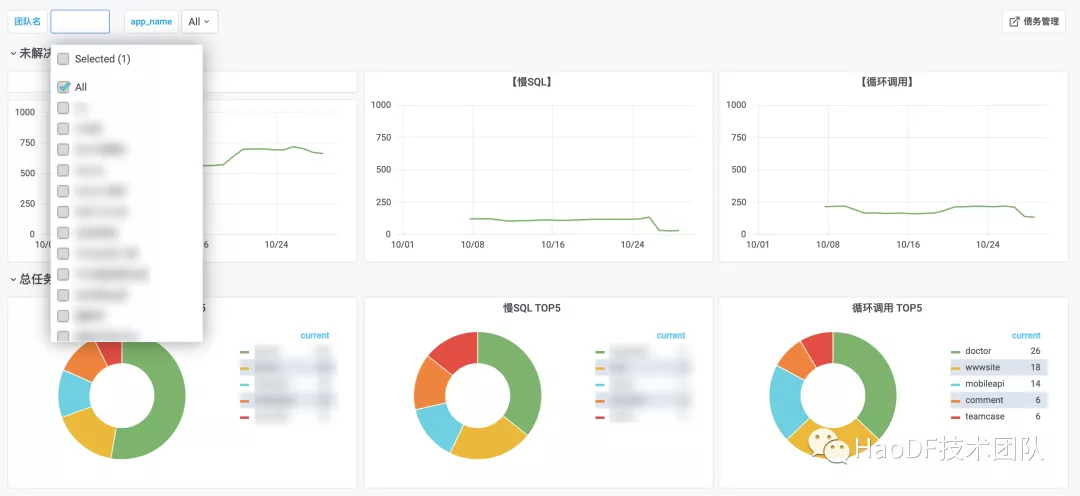
债务占比趋势:
历险
最后我们来实战体验一下服务风险治理平台是如何工作的。
任务列表:
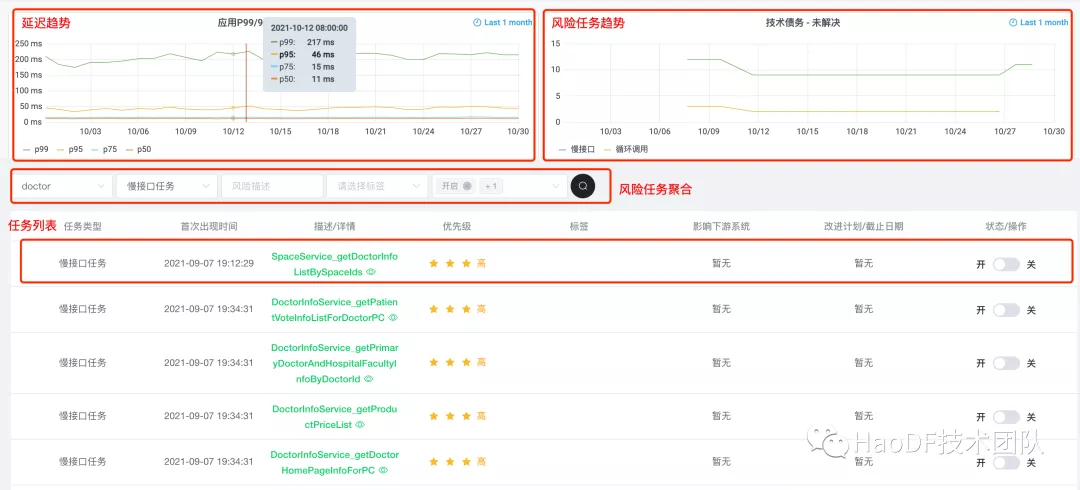
首先我们能直观的看到服务的延迟线,p50,p75,p95,p99,四条线越聚拢服务越稳定。这块有个设计技巧,需要按时间稀疏,支持查看全年趋势。30 分钟内支持按秒实时聚合查询,这块我们采用直接查询 Clickhouse 中存储的原始日志。然后每分钟打点转换成 metrics,然后存储到 GraphiteMergeTree 引擎数据库中。GraphiteMergeTree 支持稀疏策略,7d 内按 1h 的平均值进行稀疏,7d 以上按 1d 平均值进行稀疏。
任务列表支持不同维度,不同标签的聚合检索。默认按优先级排序,方便开发工程师抓住收益高的风险任务,同时高亮计划快过期任务。
任务详情:
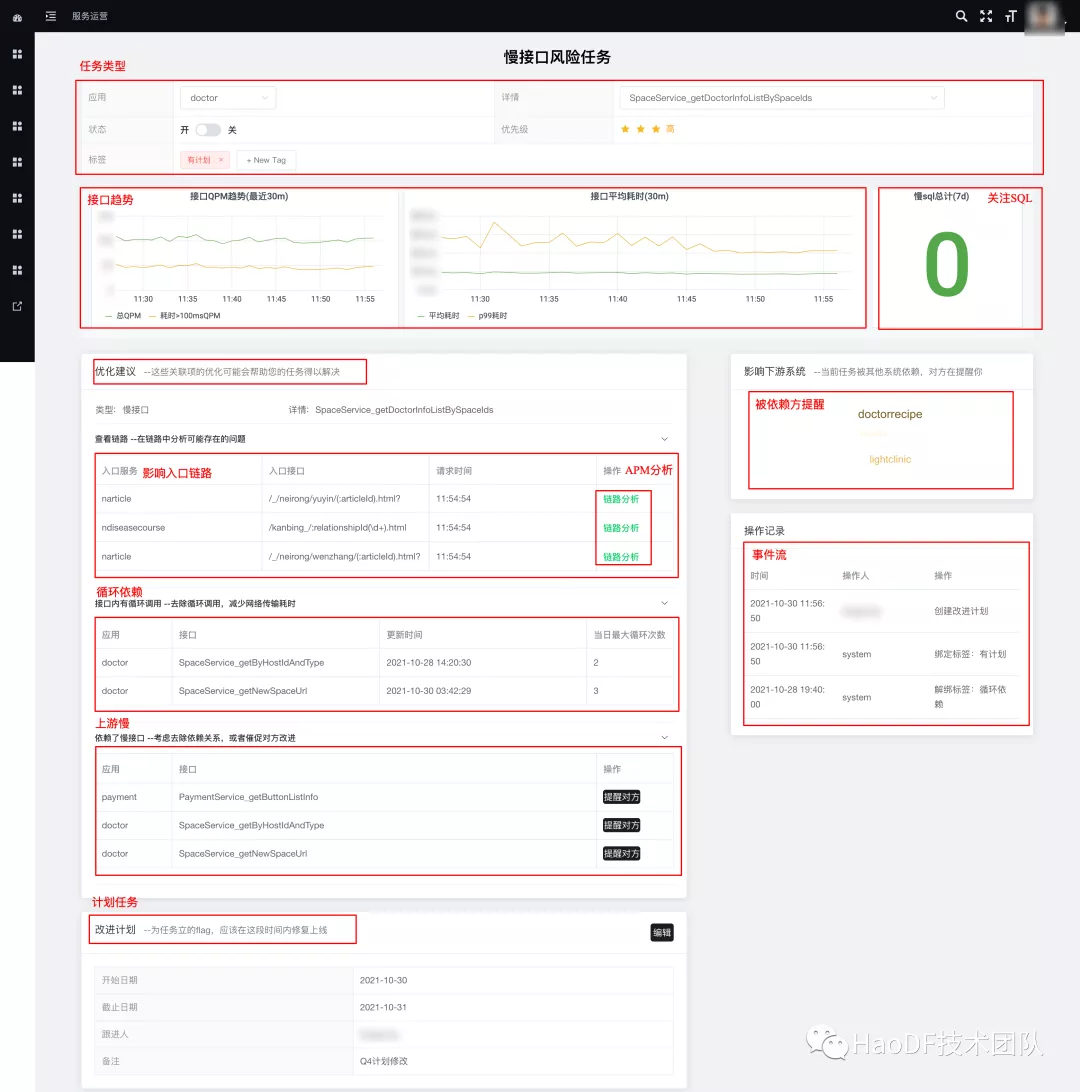
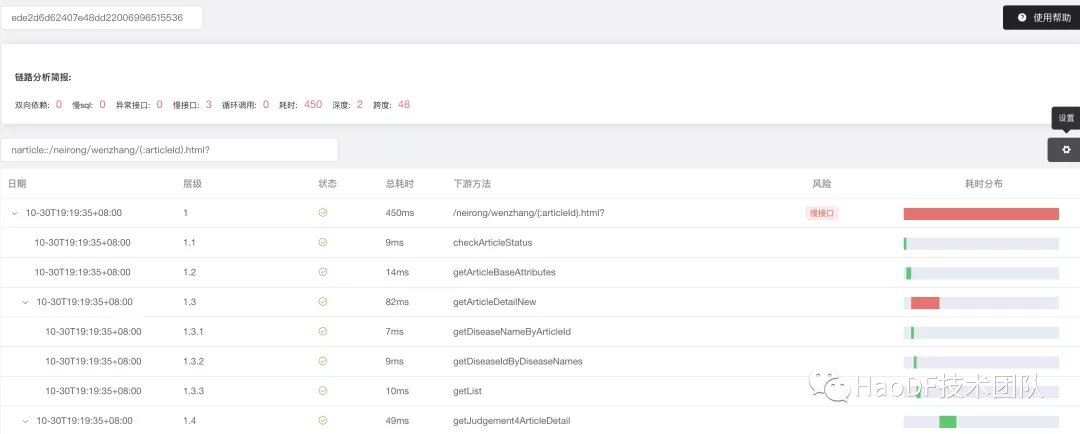
我们给出接口的详细画像,如果慢 SQL 会高亮提醒。给出相关的优化建议,结合 APM 链路入口,定位到案发现场。
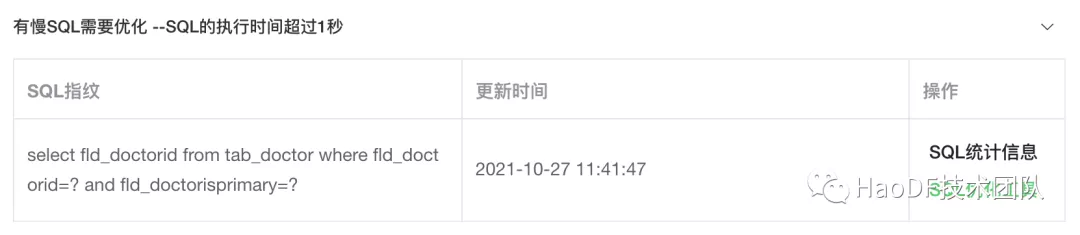
针对慢 SQL,我们提取 SQL 指纹,与 DBA SQL 优化分析引擎对接,给出优化建议。
具体实战工作涉及的细节比较多,需要从系统、中间件、代码甚至需求层面综合考虑,本次就先不展开了,后续还会单独讲,感兴趣的同学可以关注一下。
总之,优化风险任务是个长期工程,我们需要制定计划,给予提醒,方便开发工程师提前将这些工作纳入自己的 OKR 来落地。平台也会提供优化工作总结报表,推出周报、季度报告等,直接发送给相关事业部的业务和技术负责人。
小结
本次分享主要基于 MDD 指导思想,以指标为导向,深入分析服务风险模型,讲解了服务风险治理的一般模式,降低服务延迟,规避风险。一步步带领大家探索如何将未知的未知风险,转换成已知的未知风险,最终转换成已知的已知风险。希望对大家的日常工作有所帮助,也欢迎大家一起交流学习。
作者简介:
方勇:好大夫基础架构部高级工程师,专注于 SRE,微服务、中间件的稳定性和可用性建设,整体负责好大夫服务治理云平台的设计和搭建。




