
背景
随着大数据、互联网技术的发展,数据量爆发式增长。Apache Kafka通过架构创新和生态完善,具备高吞吐、低延迟和横向扩展能力,完美匹配了大数据的各种需求,成为消息、事件流领域的事实标准。
随着云计算的普及,近几年云原生成为最热门的技术趋势。云原生意味着云计算原生,面向云计算的特点来重新设计软件,释放云计算的红利。对于业务应用而言,云原生意味着摒弃传统的运维开发框架,通过微服务、容器化、DevOps 和持续交付,实现应用敏捷开发、弹性伸缩、自动化部署。对于基础软件而言,则是充分和云计算的基础设施层结合,重新设计,进一步提升关键技术指标。如这几年讨论得比较多的存算分离技术,存储计算一体的架构逐渐被云原生存储(存储托管化)+ 存储计算分离的云原生架构取代。在存算分离架构中,状态存储不再依赖于本地磁盘,摆脱了本地存储规格的限制,这使得计算资源与存储资源可以灵活配比,支持快速的扩缩容。同时状态下移到存储层,降低了基础软件的运维复杂度,提升运维效率。
云原生发展到今天,已经全面往 Serverless 的方向演进。因此我们希望能基于最新的云计算技术,对 Apache Kafka 存储引擎进行深度重构,使其能够实现真正的弹性 Serverless 架构形态。在云原生 Serverless 架构的基础上建设 Kafka 云服务,为客户提供按需弹性、按量计费的 Serverless 产品体验,把降本增效红利真正释放到客户侧。
设计
目标
Kafka 等消息队列是典型的存算不分离架构,基于本地文件系统和本地盘自建,这种架构主要有以下几个问题:
单盘热点吞吐能力和容量受限;
存算比例绑定,不能灵活调整适配,容易导致资源利用率低;
节点有状态,导致扩缩容涉及数据迁移,但迁移速度受到原始节点负载、数据量和磁盘吞吐等因素影响,一般 TB 级数据需要小时级迁移时长。因此整体风险高,运维压力大。
Kafka 社区的二级存储是典型的共享冷数据架构。由于对象存储无法匹配本地盘的低延时和高吞吐,仍然需要本地盘存储热数据和 S3、OSS 等对象存储来存储冷数据。这种架构主要有以下几个问题:
本地存储不能保证数据可靠,仍然需要多副本协议保证本地热数据不丢不错,而各计算节点之间同步副本会消耗网络带宽资源;
需要实现本地存储文件和二级存储文件逻辑映射机制,增加系统复杂度。
我们期望架构可以共享所有数据,且实现计算无状态化、计算容器化和存储托管化,从而充分发挥弹性和调度优势。故我们需要高性能分布式存储系统,提供对标本地盘的低延迟和高吞吐能力,同时支持冷热分层以提高存储性价比。
盘古是阿里云自研的高性能分布式文件系统,解决了超大规模下数据不丢不错和高可用的难题,兼顾更加稳定可靠的存储能力、更大的容量和更高的性能等优点,广泛部署在全球数十个大型数据中心,服务阿里云上数百万的客户,覆盖互联网、政企、金融、制造等全行业。盘古是阿里云关键的创新技术之一,满足数字经济对海量存储、快速存储和稳定存储的需求,并入选世界互联网领先科技成果。阿里云盘古 DFS 是构建在阿里云盘古分布式文件系统之上的存储产品,会在云上提供大数据文件存储服务,满足云上客户的高性能存储需求。
Kafka 是面向日志或流的架构,且本身也是 Append Only 语义,这些特点和盘古模型非常贴合。基于调研和性能验证,最终我们选择基于阿里云的盘古 DFS 分布式文件存储产品实现 Kafka 云原生化,通过把 Kafka 的存储全卸载到云原生存储,将实现公共云基础设施级的资源并池,也就是存储池化,我们将具备无限存储空间,同时也解决社区版 Kafka 饱受诟病的数据倾斜问题。横向对比业界某些消息系统的存算分离架构,其存储并非是使用池化的云存储资源,依然要自己运维分布式存储系统,自己预先承担存储成本,因此其不是真正的按量付费。
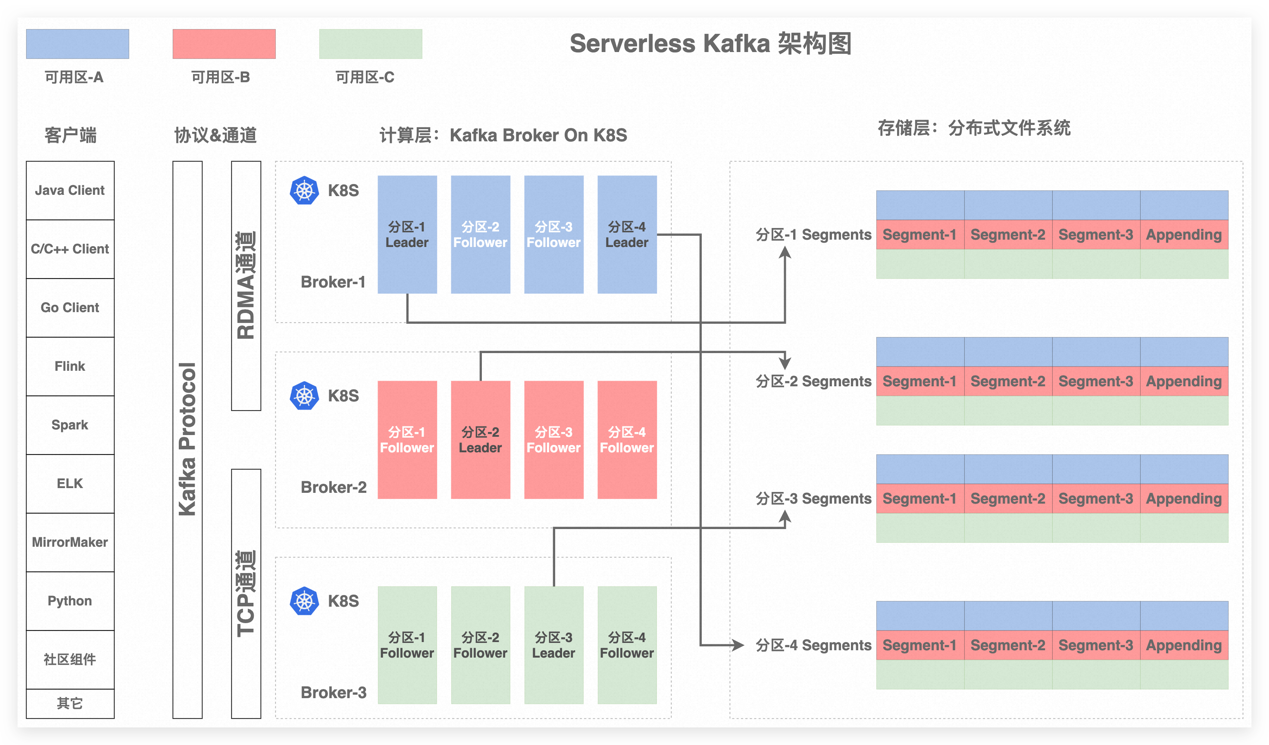
图 1 Serverless Kafka 架构图
数据高可靠
盘古 DFS 使用多副本以及 EC 等策略来保证数据极高的可靠性,不要求磁盘本身高可用,因此完全可以采用廉价的磁盘来实现数据的安全存储。将数据打散到不同的 rack 上,当某一台廉价的服务器发生故障时,仍然能够快速地恢复出数据的副本以保证数据安全,这种可靠性保证为有把握对上层承诺数据不丢失提供了稳固的基石,使得 Kafka 更加可靠,数据更加安全。盘古 DFS 支持跨数据中心的容灾策略,百微秒级平均延迟、毫秒级长尾延迟以及单存储节点打满 200Gbps 网络的 IOPS 处理能力,同时数据可靠性达到 12 个 9,可用性高达 5 个 9。
服务高可用
开源 Kafka 基于 ISR 机制实现服务高可用,ISR(in-sync replica)为某个分区维护的一组同步集合,处于 ISR 集合中的副本意味着 follower 副本与 leader 副本保持同步状态,只有处于 ISR 集合中的副本才有资格被选举为 leader。一条 Kafka 消息,只有被 ISR 中的副本都接收到,才被视为“已同步”状态,节点故障或者网络断连等会触发 ISR 选举,选出新 leader 并对外提供服务。ISR 机制复杂度高,问题调查难度大。存算分离后各计算节点无状态且共享存储,再配合我们设计的一套轻量级的故障切换机制,大大降低系统复杂度的同时还提升了可运维性。
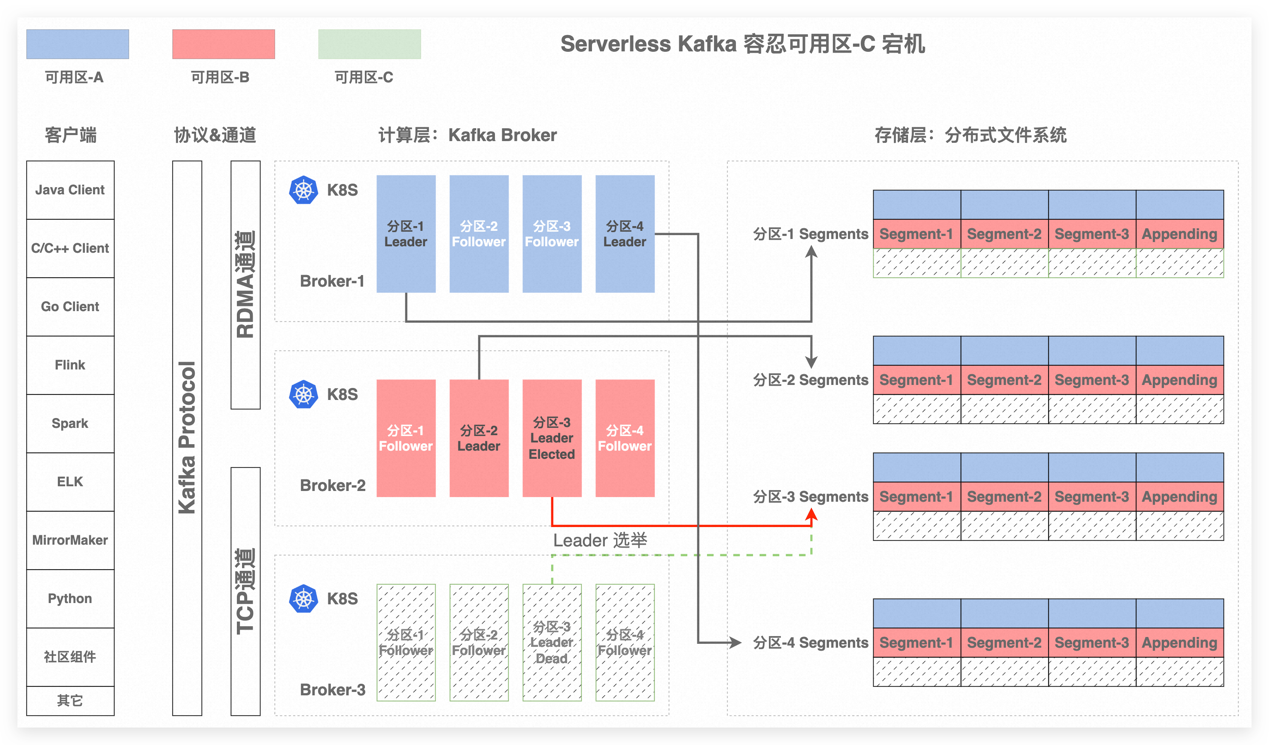
图 2 示例 可用区-C 宕机不影响可用性
降低成本
计算成本。由于数据直接写入高可靠的盘古 DFS,计算层无流量复制,极大的降低了计算节点的 CPU 和网络带宽消耗,相同成本下拥有更高吞吐上限。Kafka 也在适配倚天 ARM 架构,通过软硬件协同进行全栈的深度优化,释放巨大技术红利,降低计算成本。
存储成本。依赖盘古 DFS 实现高可靠的数据存储,盘古 DFS 通过纠删码、冷热分层、基于 CIPU 软硬件协同优化等技术实现存储成本的降低,这种技术红利也会持续降低 Kafka 的存储成本。针对“把 Kafka 作为长期存储”的场景,可以极大的降低存储成本。
降低延迟
网络延迟。我们可能会质疑分布式文件系统性能不及本地文件系统,在上一代分布式文件系统中,这是一个比较明显的问题,但是随着用户态协议栈、高性能 RDMA 网络、NVMe SSD 和新型软硬融合存储技术的持续发展,分布式文件存储进入微秒延迟时代。
计算延迟。针对平均延迟,计算层无复制流量可以充分降低网络吞吐以避免拥塞。针对长尾延迟,开源 Redpanda 用 c++重写 kafka 避免 gc 延迟,它带来的挑战是如何做到 100%兼容开源 Kafka 并能保持很高的迭代效率。我们使用主流编程语言领域最顶尖的内存管理技术,即新一代分代无暂停 GC(generational pauseless GC),仅设置堆大小和并发线程数就使得 GC 停顿时间小于 2ms,大大降低了系统长尾延时。
存储延迟。通过 2-3 异步写、Backup 读、精细 QoS 控制和慢盘规避等技术保障了性能的稳定性,极大减少了性能的抖动,为客户提供了高质量可预期的平滑服务保障。
弹性伸缩
阿里云容器服务通过硬件结构体系、操作系统、分布式调度配合,实现了面向 SLO 的资源精细化管理和弹性调度:VPA,弹性,超卖等调度技术,提升了资源弹性能力和资源的利用率。节点资源自动弹性结合调度能力提供了丰富的资源弹性能力:块资源弹性,resource limit 阈值弹性,定时弹性等。通过调度和节点弹性技术大幅度提升了容器部署密度和部署效率。
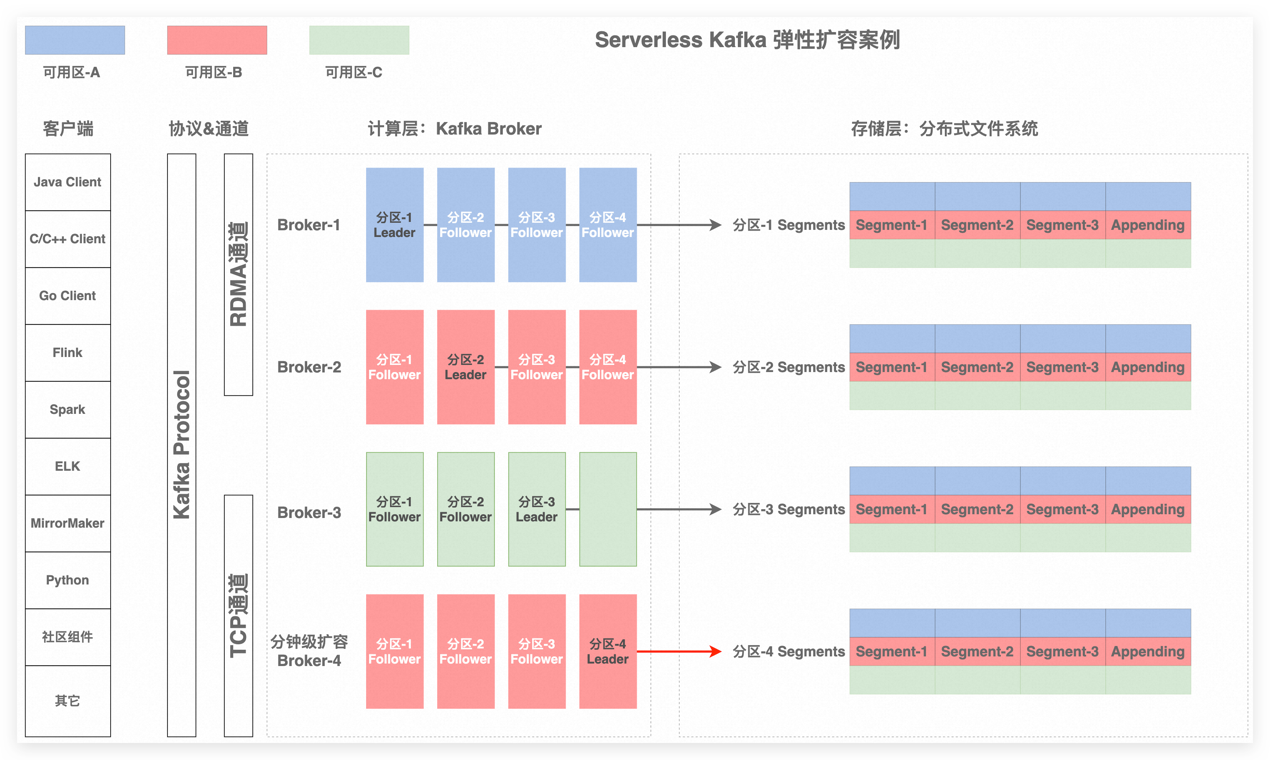
图 3 弹性扩容 Broker-4
支持 RDMA 网络访问加速
传统的 TCP/IP 一直是业界主流的网络通信协议,众多应用都是基于 TCP/IP 构建的,但随着数据中心相关的业务蓬勃发展,应用对于网络的性能需求(如高并发、低延迟、高吞吐)越来越高。在 Kafka 中网络传输是一个关键的性能瓶颈,传统的 TCP/IP 协议会对网络传输带来一定的开销和延迟,尤其是在高并发、低延迟、高吞吐的数据传输场景下,TCP 协议的开销和延迟会更加明显。
从图 4 上半部分可以看出在传统 TCP/IP 网络协议栈的通信过程中,存在若干次的数据拷贝过程,甚至在部分场景下,数据拷贝的 CPU 开销占比可达 50%以上。而且对于一次通信的过程,发送端和接收端均需要经历上述的数据拷贝过程。随着云计算时代对数据中心算力的需求逐渐提高,TCP/IP 协议栈逐渐遇到瓶颈,不再能够满足数据中心对于网络的性能需求。
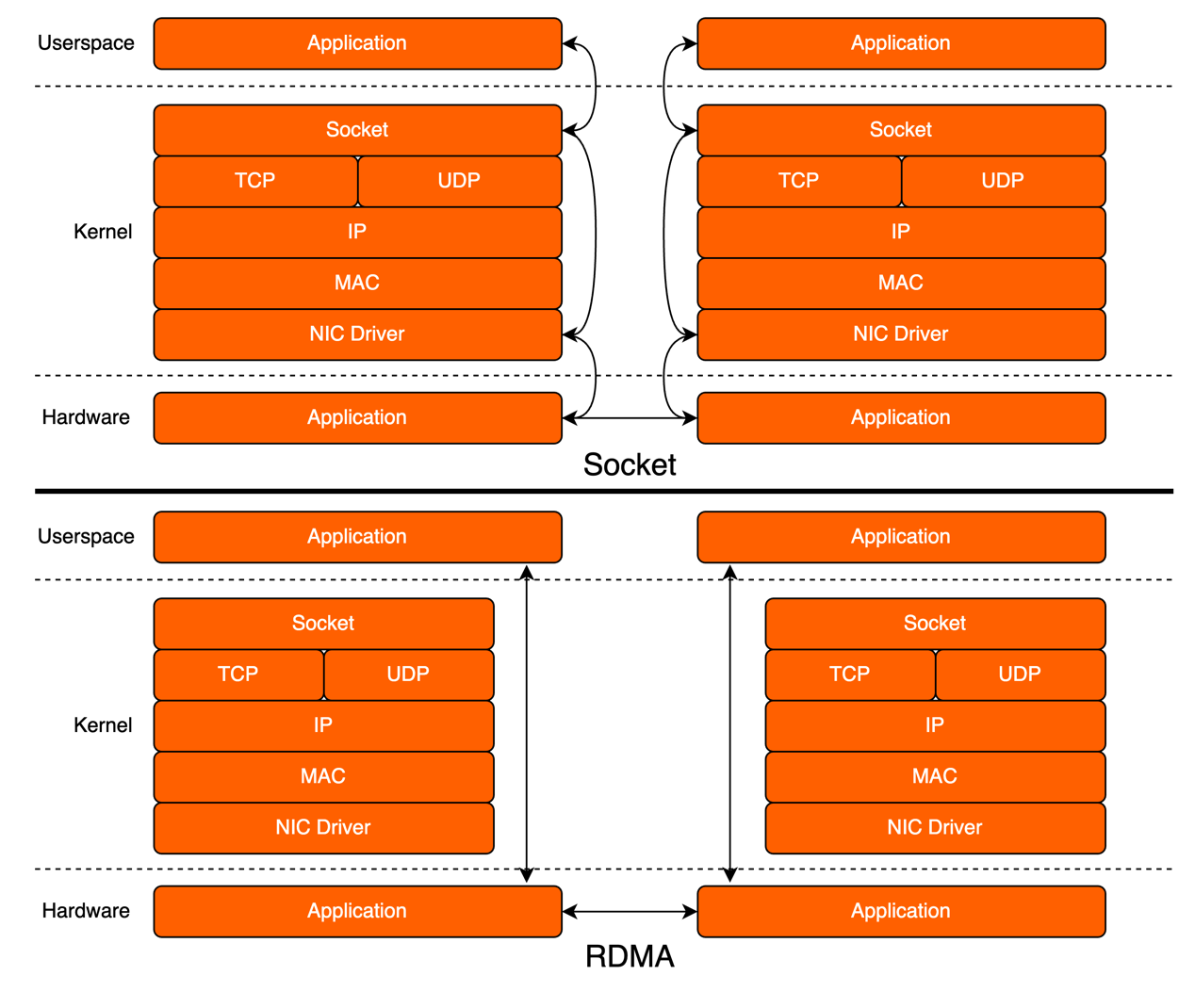
图 4 传统 TCP/IP 协议栈与 RDMA 协议栈
为了解决 TCP/IP 遇到的性能问题,一种高性能网络通信技术——RDMA(Remote Direct Memory Access)逐渐成为云计算时代的秘密武器,并逐渐在数据中心的业务中被广泛应用。简单来说,RDMA 是一种基于硬件加速的网络传输技术,可以实现无 CPU 参与的数据传输,从而提高传输效率和性能。从图 4 下半部分可以看出 RDMA 技术通过在网络适配器和内存之间建立直接的数据传输通道,绕过了操作系统内核和 CPU 的介入,直接在内存中进行数据传输。另外 RDMA 在远端节点 CPU 不参与通信的情况下对内存进行读写,以实现 CPU 卸载,再配合零拷贝技术,使得 RDMA 具有低延迟、高吞吐和低 CPU 开销的特点。
我们希望借助 RDMA 打造云产品差异化竞争力同时具备可扩展性。最终需要解决以下问题:实现真正的零拷贝通信,避免中间缓冲;RDMA 和 TCP 数据路径在 Kafka 中共存而不妨碍其可用性和性能;共享内存避免直接分配大块内存;使用 RDMA FAA 加速偏移请求的提交。
实现
整体架构
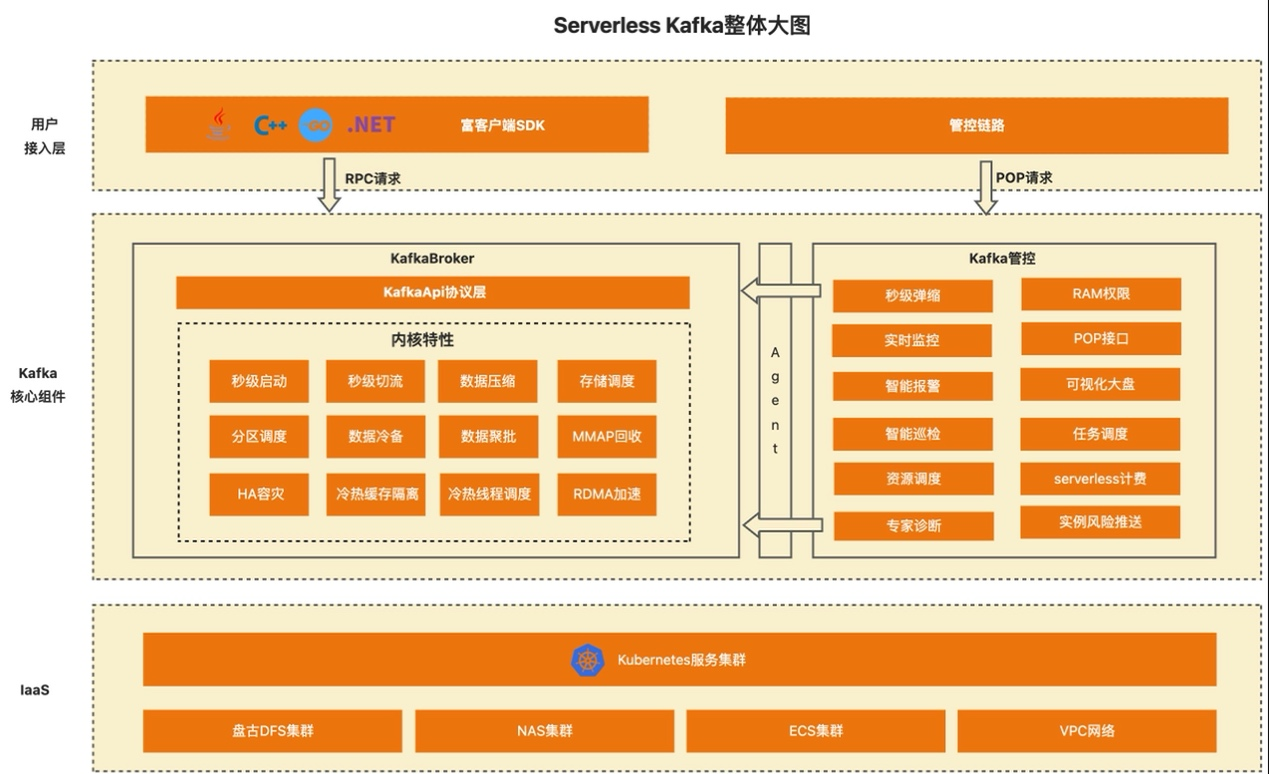
图 5 Serverless Kafka 整体大图
核心存储
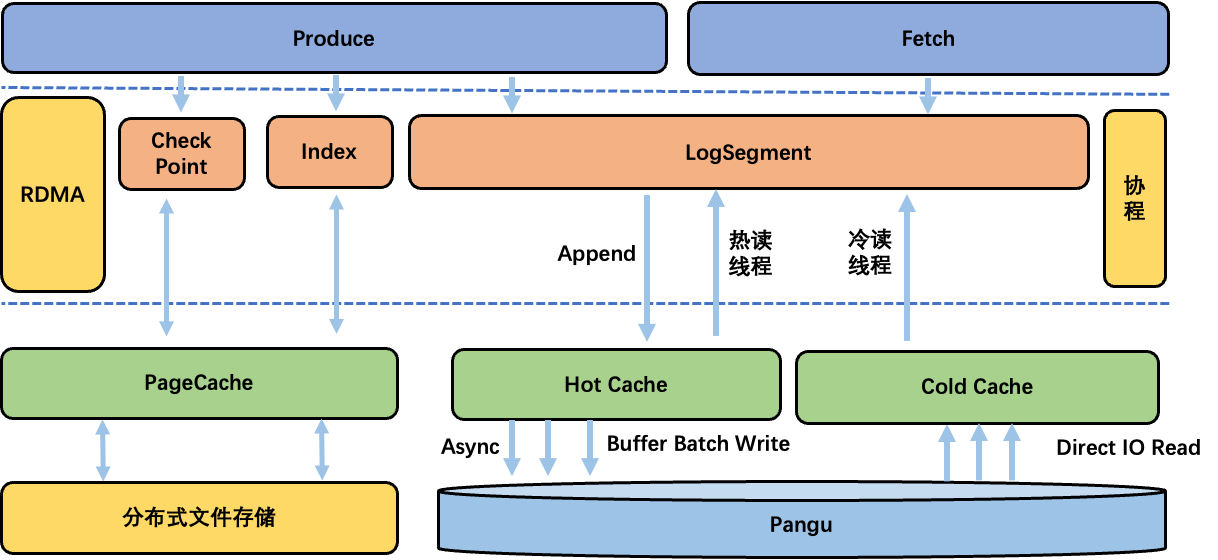
图 6 单机存储
Apache Kafka 生产者发送的消息首先写入 PageCache,操作系统异步持久化到存储介质,通过在 broker 层面实现副本机制保证数据可靠性。云原生 Kafka 采用盘古 DFS 作为存储底座,消息数据(CheckPoint 和 index 文件依然写入分布式文件系统)写入盘古 DFS 便可保证可靠性。然而也面临新挑战:盘古 DFS 与本地文件系统有本质区别,无法直接利用操作系统的 PageCache 机制,如果数据直接写穿盘古 DFS,可能导致写延迟增加和吞吐量下降。
为解决这一问题,我们基于堆外内存实现了用户态 HotCache。生产者发送的消息首先写入 HotCache,持久化到盘古 DFS 便可保证数据可靠性,然后响应生产者发送成功。针对数据持久化到盘古 DFS 的过程,我们进行了以下优化:首先在 HotCache 中批量聚合数据,然后用时间、空间和频率等多种策略触发持久化至盘古 DFS,减少网络抖动毛刺同时更快地推进 HighWaterMarker,使消费者及时读取消息,降低端到端延迟;针对大 IO 的业务场景,我们采用了 I/O 切片处理方式,支持更大并发操作同时提升吞吐上限。
Apache Kafka 在 Catch-up Reads 或 Streaming 场景下可能出现大量冷读,这些数据往往不在 PageCache 中,需要从磁盘读取并加载到 PageCache,当冷读较多时 PageCache 竞争激烈,频繁的换入换出导致缓存污染,严重影响写入性能。此外,Apache Kafka 处理生产和消费请求的同一线程池可能会受到冷读阻塞的影响,导致所有请求无法及时处理出现故障。因此,冷读会严重影响数据的写入和 Tailing Reads。为缓解此问题,我们通过自研"冷热数据隔离"的堆外缓存、冷热线程(协程)分离和预加载等策略进行优化。
高可用
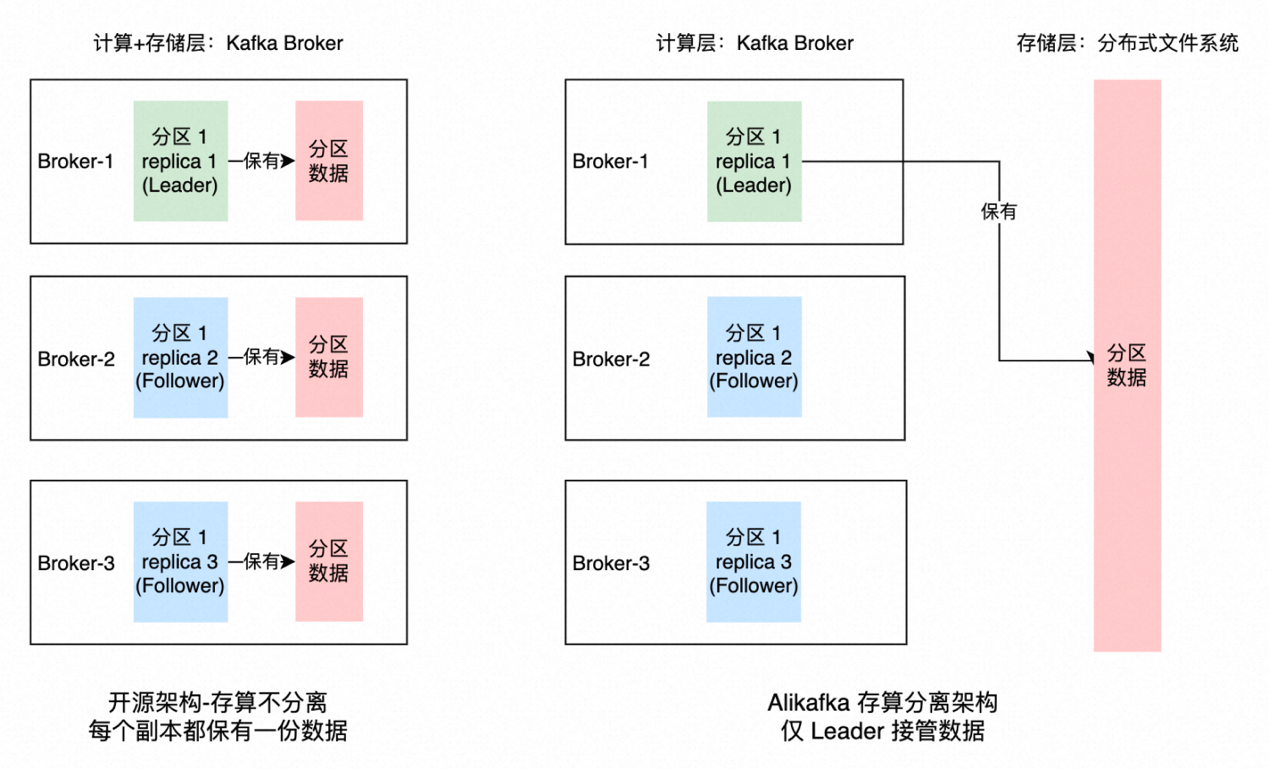
图 7 Serverless Kafka 高可用
存算分离架构下,计算层不再需要 ISR 这样重量级的副本复制协议,因此我们设计了一种更加轻量的 HA 方案优化了元数据管理机制、降低了系统复杂度。Follower Replica 仅作为计算资源的热备存在,只保有少量必要的元数据,并仅需要处理少量的元数据变化请求,进一步提高计算层的处理效率。这种架构下,新节点能够快速接管数据并提供服务,为弹性的极致体验打下了基础。
我们基于存算分离实现的 HA 的新方案,相比于开源拥有如下优势:
使用分布式锁解决了主从切换可能带来的双写问题(阻止旧进程对已打开文件继续写入;阻止旧进程新建文件,打开新文件继续写入)确保了 HA 过程的正确性,同时经过一系列的细节设计保证了 HA 过程的高效率;
更加轻量化和安全的设计,开源的 ISR 方案是一种较为重量级的副本复制协议,给运维和安全都带来了挑战。在 HA 新方案下,我们优化了元数据管理的层次和复杂度,设计了 HA 事件标记机制,提供高安全性的同时,极大降低了运维的成本;
面向极致弹性的设计,开源的 ISR 方案在节点扩容时通过 Reassignment 进行数据和流量的再平衡,这个过程需要等待新副本追赶上 leader 的数据才能提供服务,往往需要相当长的时间。在 HA 新模型下,我们的计算与数据是解耦的,扩容时新副本可以秒级接管数据并提供服务,为用户带来了更加极致,安全的弹性体验。
性能
我们使用OpenMessaging Benchmark Framework 对阿里云云原生 Kafka 和 Apache Kafka 3.3 进行对比。我们首先对比了在一定的延迟下,达到同样吞吐两者所需的成本;随后对比了聚批发送与碎片化发送下各自的吞吐延迟。
成本对比
在一定的、可接受的延迟下达到同样的吞吐,对比云原生 Kafka 和 Apache Kafka 各自需要的资源与成本。测试采用单 Topic 100 分区进行测试,发送消息体大小为 1K,BatchSize 为 1M,acks 为 -1,linger.ms 为 1ms,吞吐为 1GB/s。开源用户自建常选择本地 SSD 机型搭建三节点以上集群,保证服务可用性和数据可靠性。考虑搭建吞吐达到 1GB/s 的集群,且本地 SSD 机型的 CPU、内存、带宽、存储容量为固定比例,我们选择阿里云本地 SSD 机型(8C 64G,基础带宽 6 Gbit/s,突发带宽为 15Gbit/s;本地 SSD 1788GB,读写宽带分别为 3GB/s 和 1.5GB/s)机型为例,计算用户自建三节点成本。尽量达到同样的 1GB/s,并且 TP999 延迟控制在 50ms 左右的场景下,两者的成本对比如下:
自建三节点 Apache Kafka 之间存在大量数据复制,ECS 带宽很容易达到瓶颈,在吞吐 1G/s 时,Apache Kafka 的 TP999 发送延迟开始快速恶化到 56ms,而云原生 Kafka 的 TP999 发送延迟仅有 45ms。同时云原生 Kafka 所使用的计算资源更少,只需 3 x 3C 的计算资源。成本上,Apache Kafka 所使用的三台 8C 64G,提供了 1GB/s 的吞吐和 1788G 的存储能力。而云原生 Kafka 所使用的集群为存储计算分离架构,我们将计算存储分开计算。云原生 Kafka 使用 3 x 3C 的计算资源和按量付费的盘古 DFS 存储资源,提供同样的 1GB/s 的吞吐和 1788G 的存储能力,相比自建 Apache Kafka 综合成本降低 75%。
吞吐延迟对比
我们限制计算资源为单台机器 4C16G,并搭建三节点集群对比云原生 Kafka 和 Apache Kafka 的吞吐、发送延迟(包括了消息到达 Broker 的时间、Commit 成功时间、Broker 返回生产确认到生产者的时间)和端到端延迟(包括了消息到达 Broker 的时间、Commit 成功时间、消息到达消费者的时间。消息在 Broker Commit 后,会优先 wakeUp 消费者线程。当数据包较小时,消息到达消费者的时间会比 Broker 返回生产确认到生产者的时间短,因此当流量较小时,会存在端到端延比发送延迟低的情况)。对比聚批发送与碎片化发送两种场景下的吞吐和延迟,两种场景下的生产者负载参数分别如下表:
聚批发送一般能够达到较高的吞吐,我们不断增加流量,对比不同吞吐下两者的 TP999 发送延迟与 TP999 端到端延迟。结果如下:
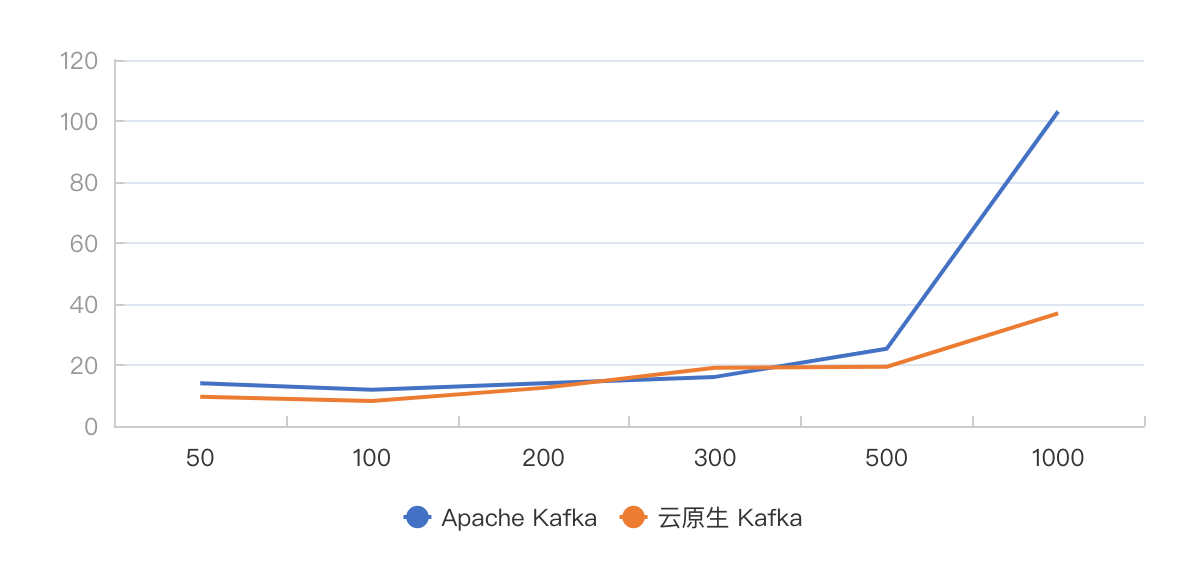
图 8 攒批发送,不同吞吐下 TP999 发送延迟对比
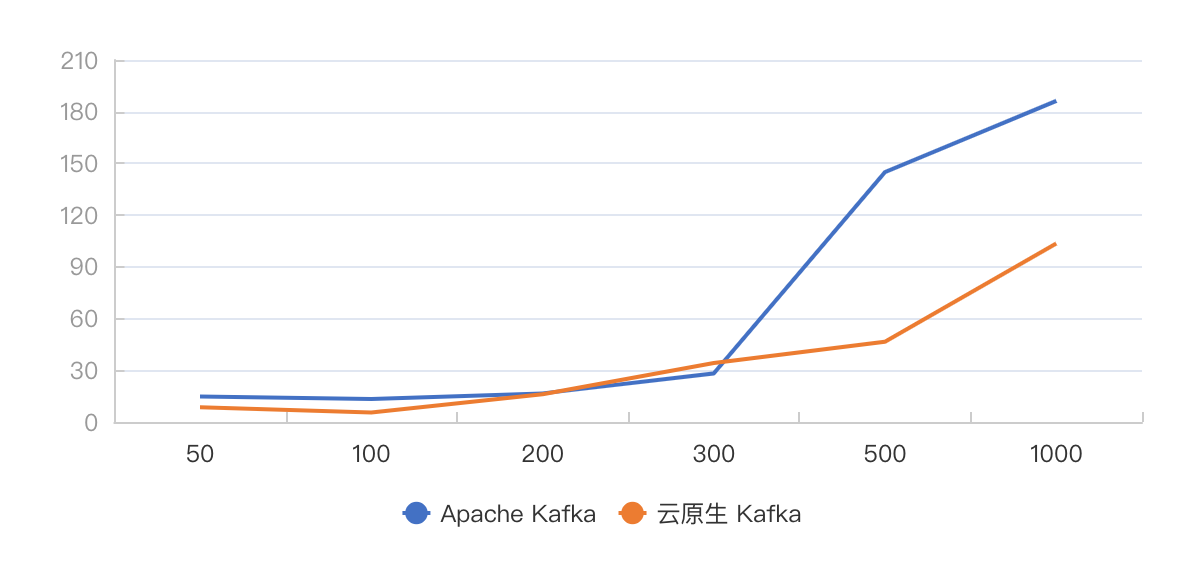
图 9 攒批发送,不同吞吐下 TP999 端到端延迟对比
从结果中可以看出,云原生 Kafka 在 TP999 的延迟表现整体要优与 Apache Kafka,并且随着吞吐的变大,这种优势越发明显。在吞吐达到 1000MB/s 时,Apache Kafka TP999 发送延迟达到了 103.1ms,TP999 端到端延迟达到了 180ms。而云原生 Kafka 在同样的吞吐下,相应的延迟分别只有 36.9ms 和 103.5ms。
碎片化发送也是 Kafka 常见的工作负载之一,和攒批发送一样,我们同样对比了不同吞吐对延迟的影响,同时我们还比较了 CPU 资源的消耗。对比结果如下:
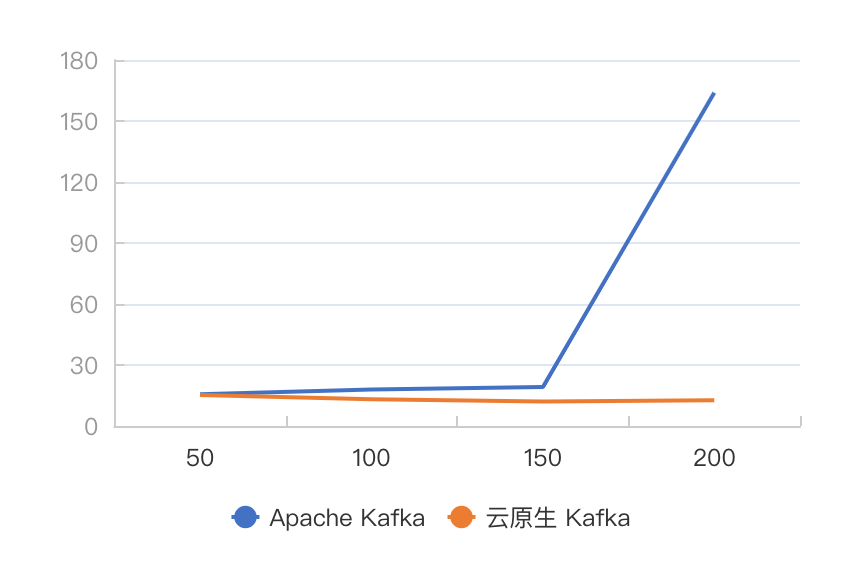
图 10 碎片化发送,不同吞吐下 TP999 发送延迟对比
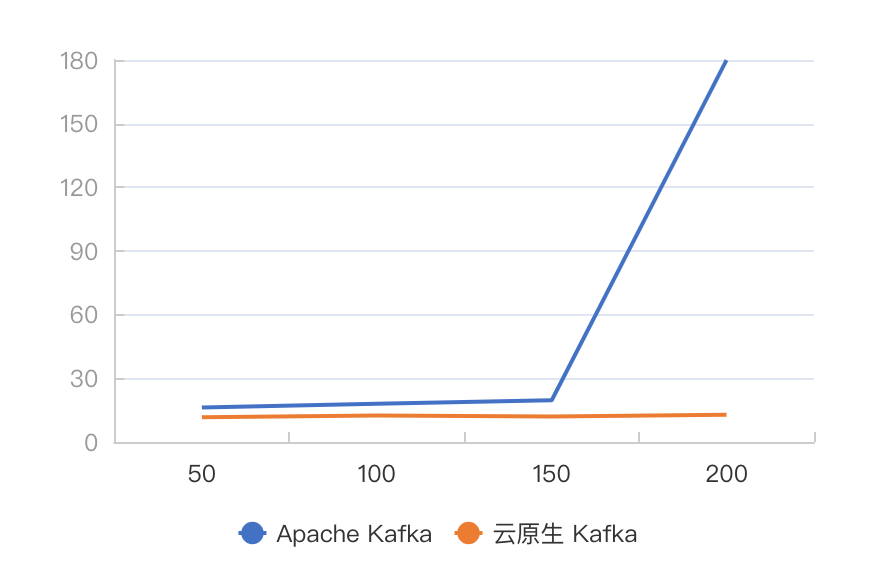
图 11 碎片化发送,不同吞吐下 TP999 端到端延迟对比
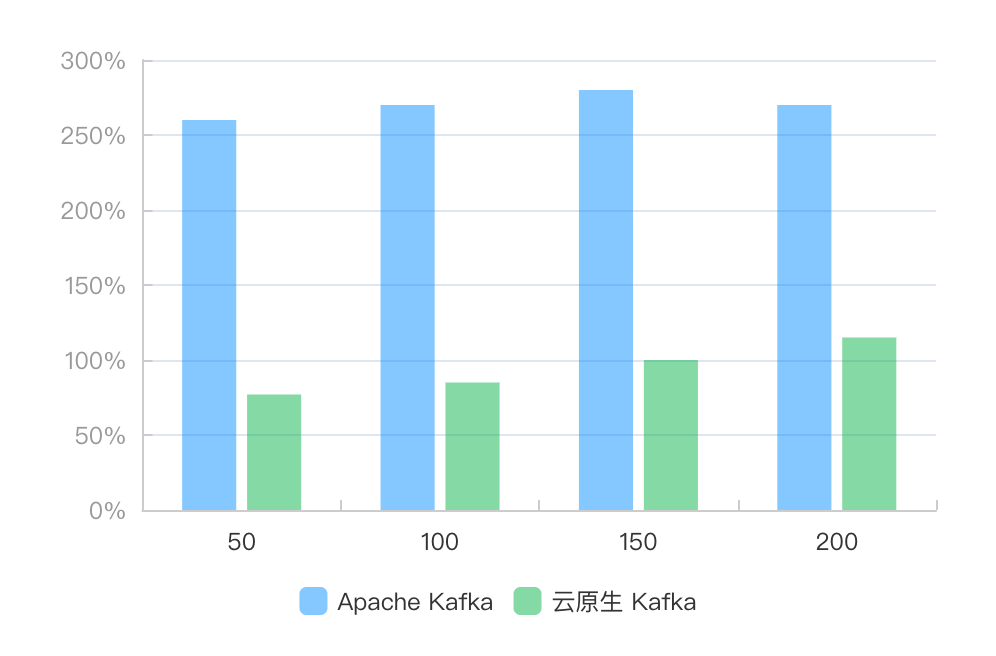
图 12 碎片化发送,不同吞吐下单节点平均 CPU 负载
从图中可以发现,在碎片化发送场景下,云原生 Kafka 同样整体优于 Apache Kafka。并且随着吞吐的增加,云原生 Kafka 的 TP999 发送延迟和 TP999 端到端延迟的优势越大。在吞吐达到 200M/s 时,Apache Kafka 的 TP999 延迟达到了 163.9ms,TP999 端到端延迟达到了 179.9ms,服务质量严重下降,因此我们停止继续增加流量。但此时的云原生 Kafka 的相应延迟只有 12.6ms 和 12.8ms,在可接受延迟下还远没有达到自身的吞吐上限。同时,我们对比 CPU 资源的消耗,云原生 Kafka 的平均单节点的 CPU 负载都远小于 Apache Kafka。
总结
可以看到,深度结合云原生技术的 Kafka Serverless 架构,在成本、延迟,弹性等多项核心技术指标上面都超越了社区版的 Kafka。未来我们将持续打磨稳定性,补齐产品功能和提升体验,核心技术指标也会持续优化,如以下几个方向:
吞吐:
操作系统参数调优。大页内存、64k memory page;
适配 JDK21 的 Loom 虚拟线程。减少上下文切换,提高并发处理能力;
探索一写多读,增加 RO 节点支撑更多的读流量。
延迟:
适配 RDMA 网络、TCP BBR 拥塞控制算法等降低端到端延迟;
JDK21 的 generational pauseless GC 优化长尾延迟;
基于本地盘的就近访问加速和故障场景快速恢复。
成本:
持续的软硬协同优化,适配倚天 ARM 架构,性价比全面超越 x86 实例;
适配新型存储介质,减少读写放大、增加磁盘寿命;
根据数据冷热度进行自动分层管理和存储。
作者简介:
林清山,阿里云消息产品线负责人
张美平,阿里云 Kafka 负责人
参考链接:
https://mp.weixin.qq.com/s/I0hHMOH5-nlfRCBNblg62Q
https://mp.weixin.qq.com/s/XWP_6o24o3vNWsd0ILEwEg
https://openmessaging.cloud/docs/benchmarks/




