
信息流业务背景介绍
信息流业务基本上伴随着互联网的诞生一起同步发展,不断为互联网用户提供信息来源,从而促进了门户网站的快速发展,比如腾讯网、搜狐、新浪等。
早期大部分的门户网站都是按照专题频道等划分,通过专业的人工编辑来维护信息的更新,所有人在同一时刻看到的门户新闻都是一样的。
而随着信息的爆炸,互联网上源源不断生产出海量内容,通过人工的方式已经很难去维护和更新。除此之外,随着互联网的用户爆发性的增长,每个用户对信息的喜好亦有所不同,这就导致了千人一面的门户网站难以满足用户的需求。
推荐系统在这个场景下得到了快速的发展,每个人在打开 App 或者网页时,看到的都是和自身兴趣相关的内容,从而实现了千人千面,提升了信息的分发效率。
信息流内容理解业务架构
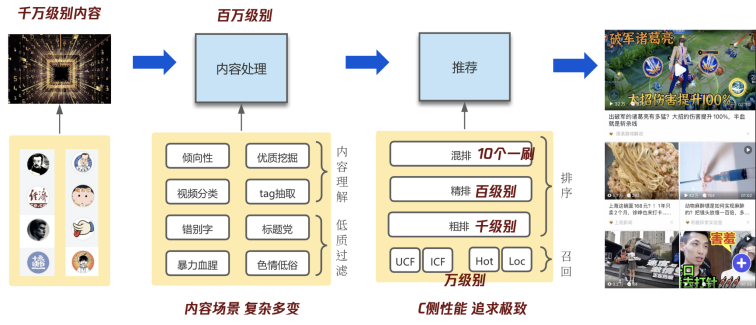
图文 / 视频内容会通过发布平台进入到我们的内容处理系统打上标记,并送到推荐系统,并最终展现到用户面前。
每天会有千万级别甚至亿级别的内容新增,而这些内容鱼龙混杂,有很多是优质的,但也有很多低质内容,比如色情、低俗等。这些如果都依赖人工编辑审核,无疑成本是巨大的,尤其是色情、安全相关,是一个产品的生死线,直接可能导致一个产品下架。
业界大部分的信息流产品都是通过机审和人审相互配合,即通过内容理解,将相关的低质内容进行过滤,只有机器无法判断的内容才会送到人审,从而大大节约人工审核成本。除此之外,我们还需要对内容进行深度理解,比如对内容进行分类,打上各类的标签以及一些 embedding 的特征,帮助推荐系统可以更精准的把内容推荐给用户。
这就像汽车的生产流水线一样,在一个原始汽车支架不断增加音箱、座椅、屏幕、雷达等,质检通过后,才可以最终出厂给消费者。

(图:上观新闻)
内容处理链路中,每一个模型能力最终会落地为一个微服务,而整个处理流依赖于一个调度系统,调度系统会根据各个模型能力的依赖特征关系,进行 DAG 图的调度。
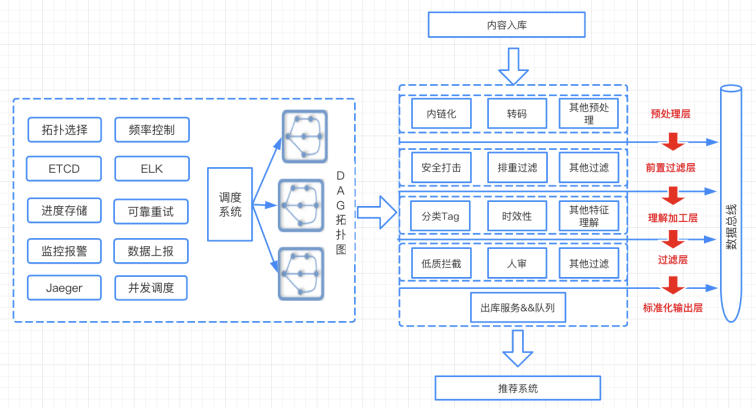
外部会源源不断的灌入这一条流水线,并将处理完推送到推荐系统中。目前我们的信息流业务中,各类模型服务近千个,生成出图文内容特征 2k+,视频内容特征也有近 2k 个字段,提供给机审、人审、推荐、运营系统等各个环节使用。
AI 全流程能力建设
针对于这一套复杂的流水线,无论是开发成本,还是运维成本以及模型服务带来的机器成本都是巨大的,因此我们的目标聚焦在以下三点:
如何提升算法模型的服务性能
如何提升算法模型的推理性能
如何提升算法工程效能
如何提升算法模型的服务性能
借着 AI 大潮,Python 荣登 TIOBE 的 2022 的年度编程语言。
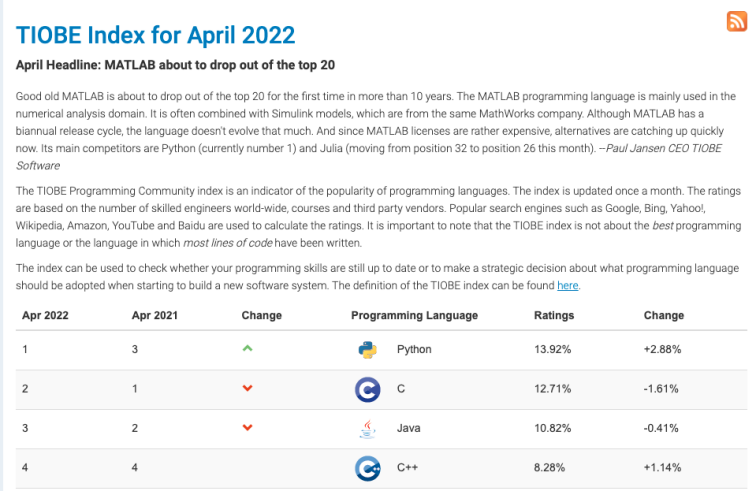
Python 因为拥有非常完善的算法库,使我们可以很方便就将一个算法模型落地为一个线上服务,从而快速验证模型效果,所以早期的算法服务基本上都是通过 Python 实现的。Python 如果作为纯后台的服务,性能毫无疑问会低于 C++、Go 等,但是如果我们将 Python 逻辑翻译成 C++ 等其他语言,会使得开发成本变的很高。在内容理解的场景下,并没有太多的网络 IO 耗时,大部分都是模型的处理耗时,同时对于服务的 QPS 要求也没那么高。所以综合考虑开发效率和服务性能,Python 在这个场景下还是非常适用的。
Python 框架服务性能优化
最早算法同学大部分都采用开源框架进行模型的服务化,比如 Flask、Django、Tornado 等。但这些框架存在很多问题:
开源框架和公司的监控体系、发布体系都很难融合,配套设施不全;
服务器进程模式落后,大部分都是同步阻塞,不支持 Reactor 模型,服务性能比较低;
在多核场景下,由于全局 GIL 锁的存在,所以 Python 很难充分发挥多核优势,导致机器资源的浪费;
服务化成本高,算法同学需要关注大量的工程相关知识,增加人力成本。
无法实现模型的 batch 批处理能力
笔者之前也是 PHP 的开源项目 Swoole 的核心开发者,在 PHP 语言中同样存在类似的问题,服务开发效率很高但服务性能很差。而 Swoole 最主要就是通过核心网络 IO 库以及先进的进程模型,解决了服务的性能问题,使得开发者可以专注于上层业务逻辑的开发,从而解决了开发效率和服务性能的冲突。
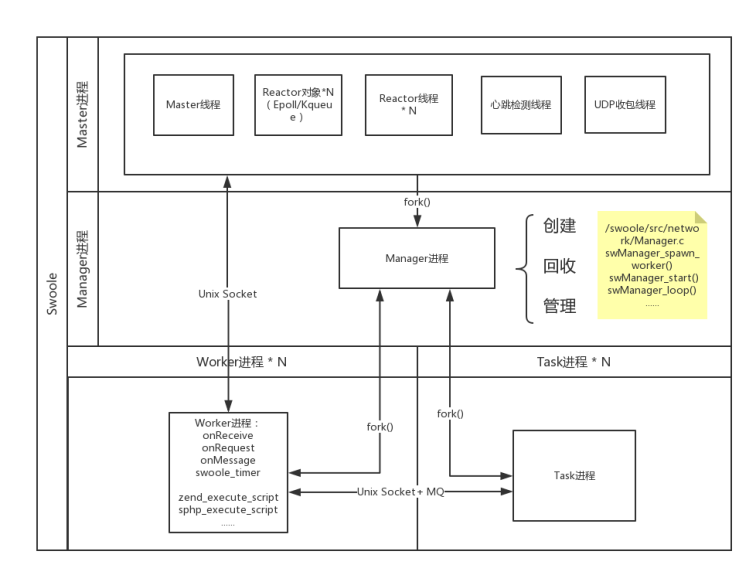
(图:Swoole 官网 https://www.swoole.com/)
我们调研了业界中对于 Python 性能的常见优化办法:
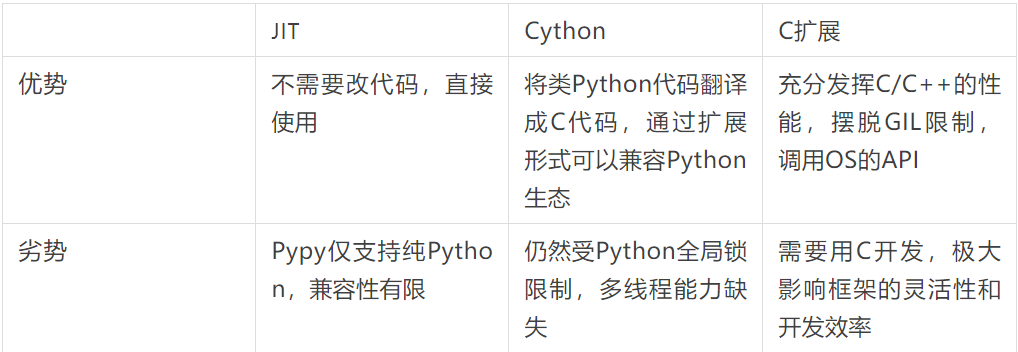
但是上述中没有任何一种方案是银弹,可以完美解决所有问题,因此我们决定学习 Swoole 优秀的设计模式,并结合公司统一的 RPC 协议以及微服务治理,对 Python 框架进行重构,组合使用各类优化手段。
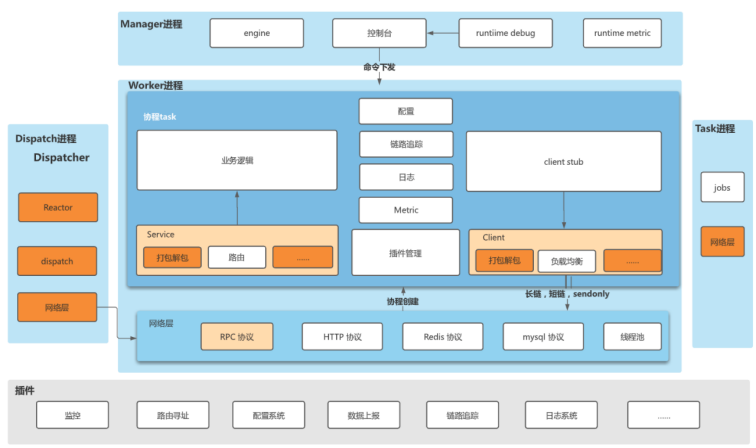
如上图所示,我们同样将 Python 服务设计为多进程的模式:
其中 Dispatch 进程主要负责监听端口,维护客户端的链接、处理协议、收发数据等,并将连接套接字转到 Reactor 线程处理。
Worker 进程主要用于接收 Dispatch 进程发射的请求包,并且创建对应的协程进行业务的处理。用户的业务逻辑也都会在 Worker 进程中执行。
Task 进程用来接收 Worker 投递的任务,并且可以在这个进程中实现各类跨进程的连接池,比如 MySQL 的连接池等。
Manager 进程负责创建和回收 worker 和 task 进程,对进程状态进行监控和管理。
Swoole 官网上有一个很通俗的解释:
假设 Server 就是一个工厂,那 Reactor 就是销售,接受客户订单。而 Worker 就是工人,当销售接到订单后,Worker 去工作生产出客户要的东西。而 TaskWorker 可以理解为行政人员,可以帮助 Worker 干些杂事,让 Worker 专心工作。
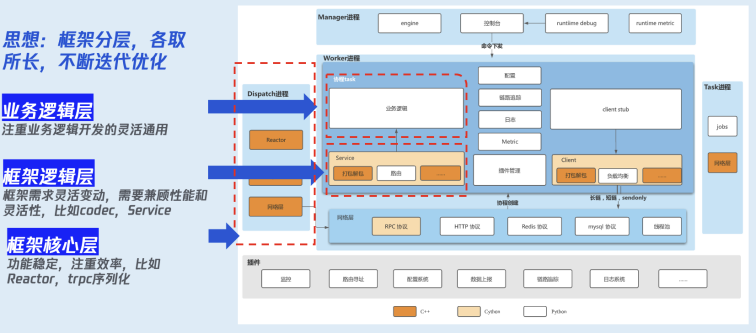
除了进程模式之外,我们还根据不同的开发场景和应用场景对框架进行分层:
框架核心层:其功能是比较稳定的,对性能要求比较高,比如 Reactor、协议的解析等,我们通过 C++ 进行开发。
框架的逻辑层:框架需求灵活变动,需要兼顾性能和灵活性,比如编解码等,我们一般通过 Cython 进行开发。
业务逻辑层:注重业务逻辑开发的灵活通用,这一块是直接面对用户的,因此这一块全部是通过 Python 进行开发。用户的开发逻辑也都在这一层。
通过上述重构,整个服务相对于 grpc-Python 有了接近 10 倍的提升,P99 耗时也大幅下降。
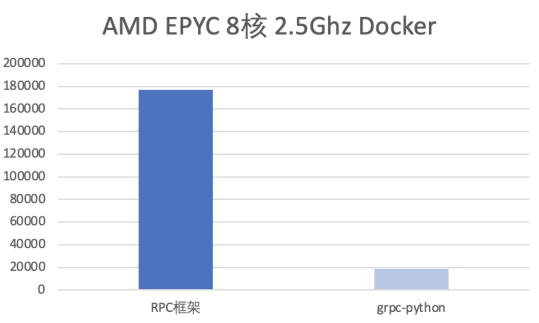
Python 框架算法场景优化
在不断优化 RPC 框架的性能同时,我们同时也针对算法服务的应用场景进行了一些优化:
1、支持模型自定义初始化时机
PyTorch 推理过程中会使用多线程来对算子之间并行化,同时在算子内部也会使用 openMP 等并行库来进行加速。
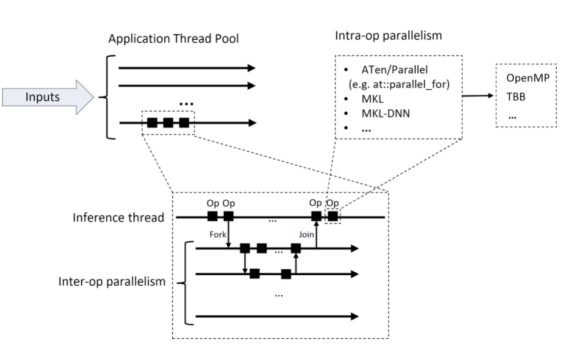
(图:pytorch.org)
但是因为 fork 的时候只可以继承当前线程,而 trpc-Python 是一个多进程的架构,因此模型只能在 worker 初始化的时候进行加载。
我们的框架支持插件灵活的在不同的时机进行初始化。比如日志类的组件可以在 onMasterStart 进行初始化,而模型加载可以在 onWokerStart 的时候进行初始化,从而解决模型加载的问题。

此外,我们发现同样的模型,在 4 核实体机和虚拟机性能服务差异很大。定位后发现这是因为在 docker 上,torch 默认设置的线程数为母机核数的一半,比如 72 核就会设置 36 个线程,而 docker 只分配了 4 个核,从而导致线程竞争,服务性能大幅下降。
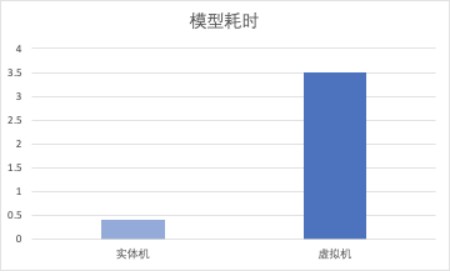
(云上 4 核机器:0.4s,tke 机器:3.5s)
参考 GoLang 的库,我们开发了 automaxproc 库,自动设置在云上实际可以使用的核数,解决了线程竞争的问题。
2、大模型 /GPU 的模型推理的场景
通过插件注册机制解决了模型加载的问题,但是在大模型和 GPU 的场景下还会存在新的问题。
因为 GIL 锁的问题,所以在一个进程内,预处理和推理是串行的,只能依靠多开进程来提升性能;
如果一个模型特别大,或者依赖 GPU,多进程占用的内存和显存会和进程数成正比;
无法实现模型的批处理能力,继而导致 GPU 的利用率不高。
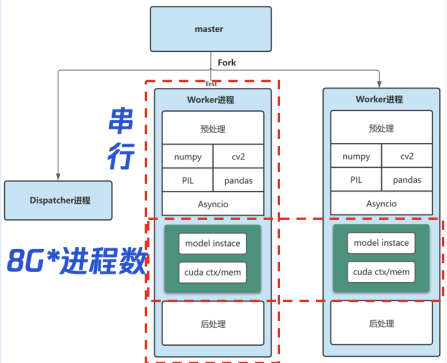
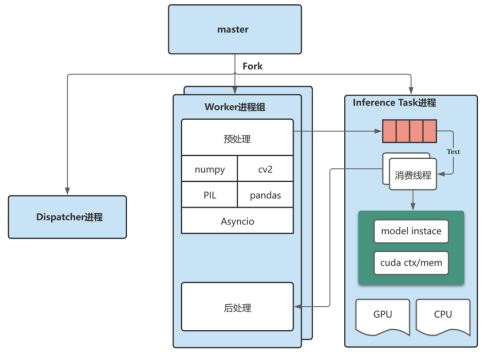
所以我们抽离 inference 进程,仅在 task 进程里加载一次,从而显著减少内存 / 显存消耗,而将预处理逻辑比如 Numpy、CV2、文件下载等操作,放在 worker 进程,利用 worker 的多进程,可以提升处理性能。
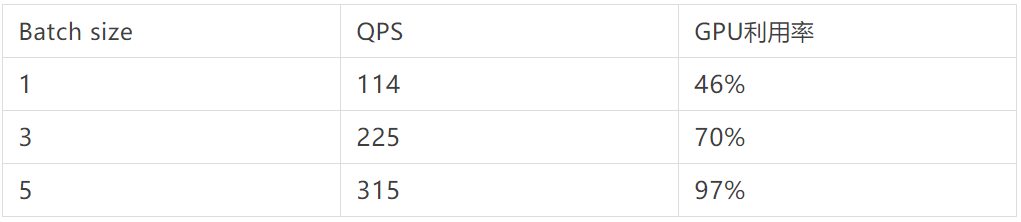
在实际业务中,T4 单卡上部署的 pytorch-bert-classsfication 模型,在 seq_len=64 的情况下,对于不同 Batch size 进行压测,可以看到适当的增大 Batch size,可以有效的提升服务的 QPS,提升 GPU 利用率。当然 Batch size 也并不是越大越好,当 GPU 计算资源已经被重复利用后,增大 Batch size 反而会使得请求的时延大幅增加。
通过对这一套 RPC 框架的开发以及对各个环节性能的逐步优化,目前这套方案已经可以兼容算法同学快速开发的要求,同时亦可以保证足够高的性能,在腾讯内部很多算法团队都得到广泛使用。
如何提升算法模型的推理性能
一个信息流依赖的内容理解服务很多,大部分的模型原型都是算法同学提供,其更多关注于模型的效果,尤其是 CV 类的模型对资源耗费也很巨大,导致整个运营成本急剧扩展。除此之外,不断增加的模型,直接带来了整个链路的耗时提升。内容推送的实时性对于信息流产品至关重要。所以我们开始尝试对模型推理速度进行优化,以提升性能、降低推理耗时。
业界常见的推理加速方案调研
业界有各种各样的推理加速的方案,有些方案也会和硬件厂商进行深度绑定,不同模型有不同的加速效果,之前大部分都是工程同学手工再转,评测后选择最优的方案,但这样会带来大量的学习成本和测试成本。
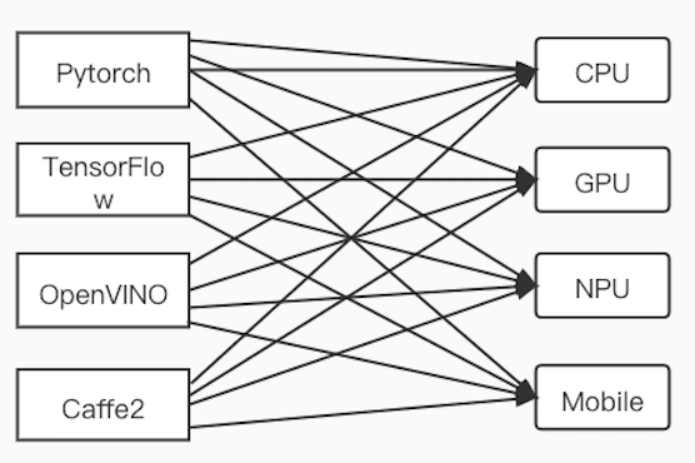
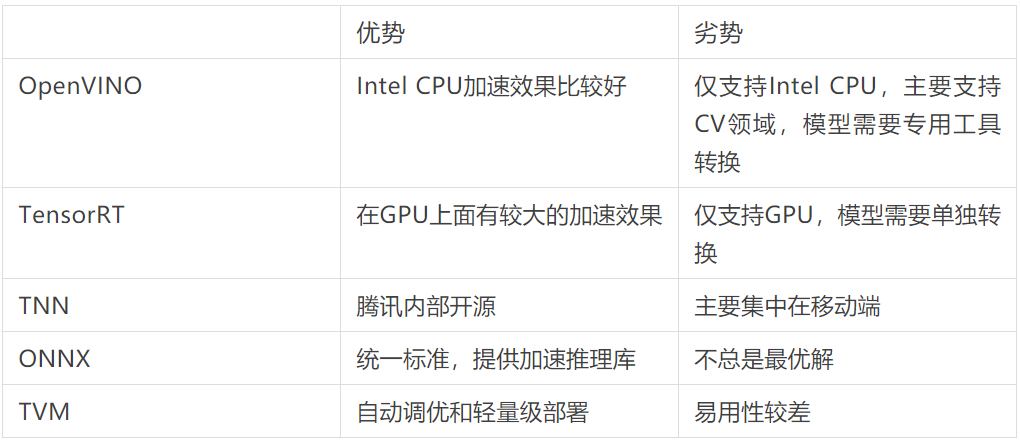
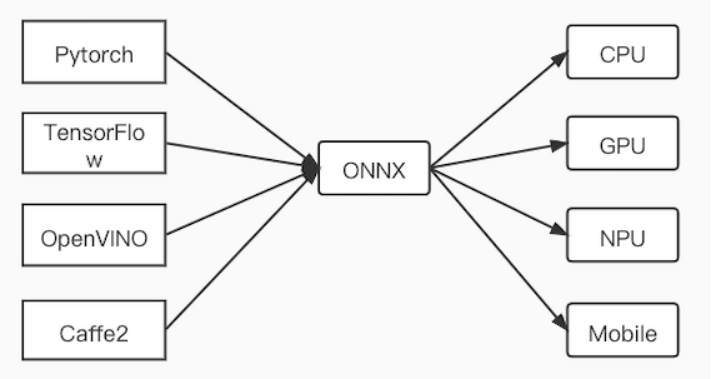
调研中发现,ONNX 作为一个统一标准的开源格式,可以作为统一的中间结果,然后跑在各个推理引擎上。
如果把相应的模型统一转换为 ONNX,我们就可以在这个标准的格式上进行不断迭代和优化,更好地聚焦我们的工作,降低学习和开发成本。
另外,因为不同的硬件优化的效果不一样,同样也需要一个流程来自动评测模型转换的结果以及性能,从而选择性价比最高的一套方案。
因此我们开发了一个评测组件,用户输入自己的模型,我们会优先转为 ONNX 格式,然后评测在 GPU 和 CPU 上面的性能效果,并对转换之后的模型结果进行进度比较,最终选择最优方案。对于转换失败的场景下,我们会回滚到原始模型上,保证降级机制。
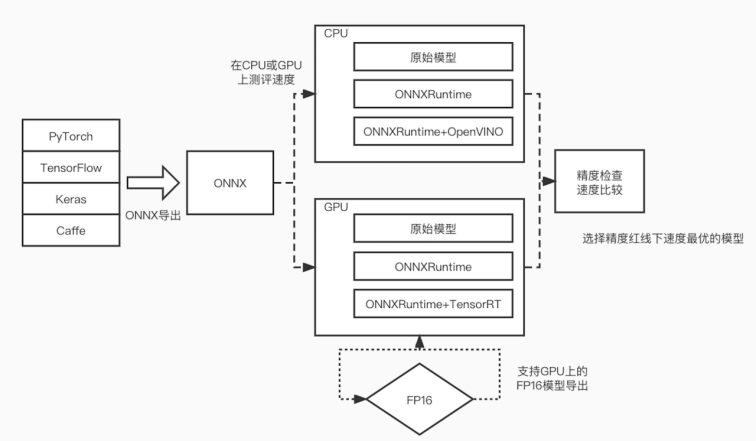
在我们的业务上,针对于常见的一些模型,通过这个评测组件可以快速输出评测结果(2~10 倍的性能提升),帮助我们更好的决策,大大提升了效率,节约我们的开发工作量。
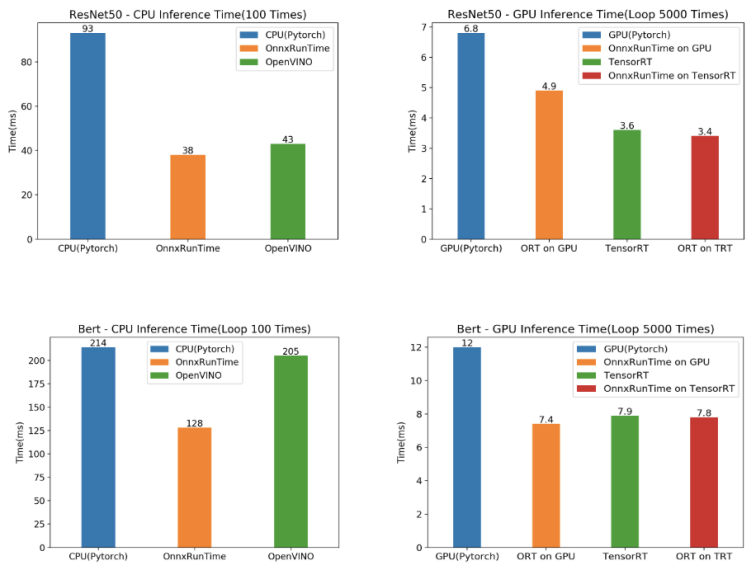
模型自身的优化
通过采用各类推理引擎,可以对已经训练好的模型,在前向推理的场景进行优化。但这意味着这类优化是存在上限的,那么我们是否可以像测试左移一样,做到优化左移,即从模型自身着手,进行优化。
业界常见的对模型优化主要包括了剪枝、蒸馏、量化以及 AutoML 等。
模型剪枝
在我们的神经网络中,其实有大量的神经元以及权重等都是冗余的,其对最终的结果影响并不大。把这些节点去掉后,一方面可以压缩模型的大小,另外一方面也可以加速我们的推理速度。
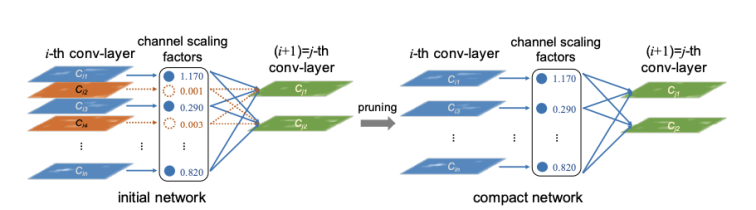
(图:Learning Efficient Convolutional Networks through Network Slimming)
剪枝主要包括了两大类:
非结构化稀疏化剪枝
优点:高稀疏率下 finetune 可以恢复模型精度,适合 Benchmark 网络
缺点:对硬件不友好,需要 finetune,生态体验不好
结构化稀疏化剪枝
优点:对硬件友好,不需要特别的定制
缺点:模型精度下降较多,需要 finetune,生态体验不好
对使用 google 提出的 BigTransfer(BiT)结构的业务模型进行结构化剪枝加速实践,如下表所示,可以看到剪枝 40% 后,模型减小 43%,推理 FPS 提升 20%。

模型蒸馏
Hinton 最早提出了知识蒸馏的概念,其大概的原理是将原始模型作为教师模型,设计一个更小的模型作为学生模型,通过一些训练策略使学生模型尽可能与教师模型的表现一致,从而起到压缩原模型大小、提高模型推理速度的效果。
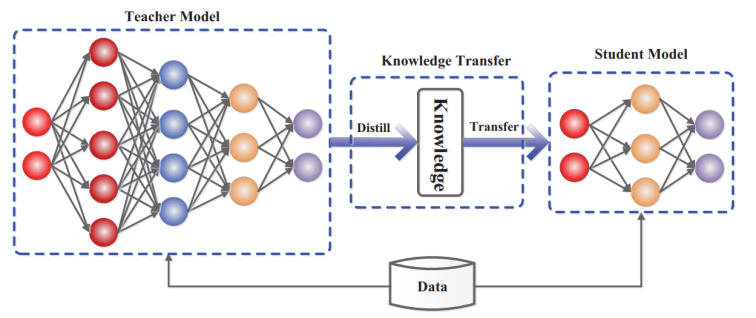
(图:https://arxiv.org/pdf/2006.05525.pdf)
基于我们预训练 Bert 模型蒸馏出来的标题夸张识别模型,对蒸馏前后进行压测比较(单个 8 核 CPU/16G 内存节点),可以看到模型减少了 60%+,而 QPS 提升了近 5 倍。

量化
最近几年,业界很多公司如 Google、英伟达、Facebook、华为等公司结合量化计算硬件和模型量化技术在商用场景上来获得推理加速、内存占用减少、降低功耗的收益。特别是对内存、计算资源较少的端上设备,量化技术发挥了极大的作用。下表列举了当前主流的几大产品框架。

量化是指将信号的连续取值近似为有限多个离散值的过程。可理解成一种信息压缩的方法。在计算机系统上考虑这个概念,一般用“低比特”来表示,如下图所示。
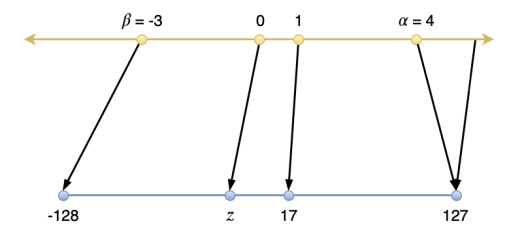
(图:https://arxiv.org/pdf/2004.09602.pdf)
基于量化的原理,通常有 PTQ(post training quantization) 和 QAT(quantization aware training) 两种量化策略:
PTQ:是指训练后对模型的参数进行量化,包括对 weight 权重和 input 的量化,通过少量样本进行 calibration 校准获得损失最少的量化系数。
QAT:是在训练时进行模拟量化,通过大量训练样本监督学习来调整模型参数和量化系数,尽可能减少与原始 fp32 模型的精度损失,在模型收敛于目标精度后,将训练得到的量化系数用于量化推理计算上。
根据量化 bit 来看,目前业界商用较多有 fp16、int8、混合精度等量化方式,学术界则有更低 bit 的量化尝试,如 4bit、2bit,甚至是 1bit。
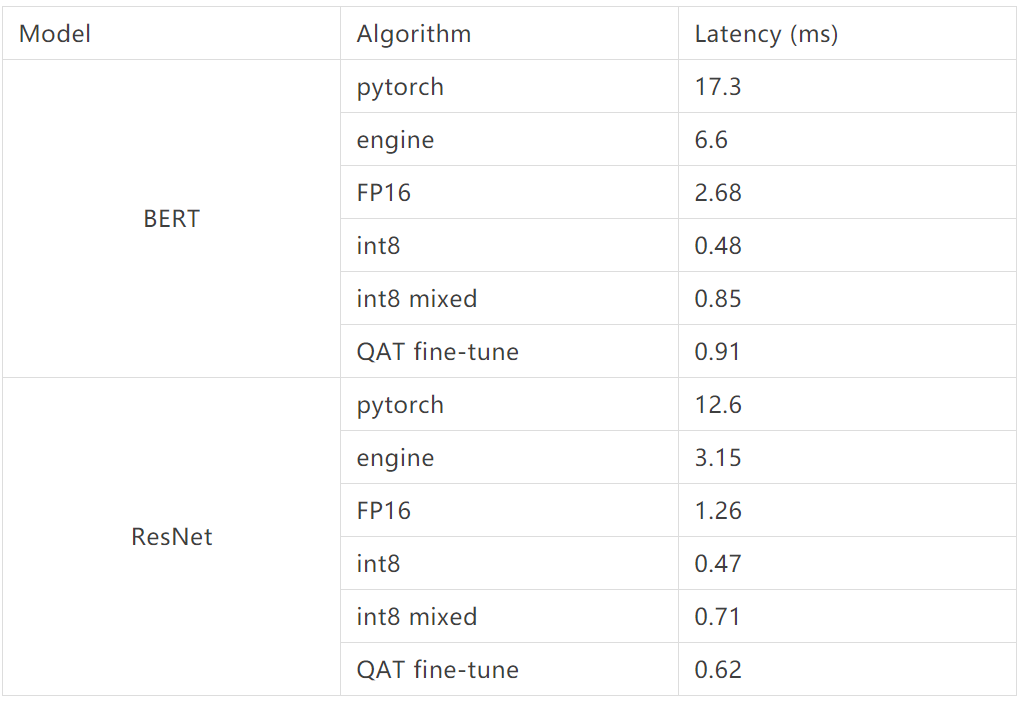
基于量化技术,我们在 NVIDIA Tesla T4 卡使用 TensorRT 进行了量化加速实践,可以看到相对 fp32,在 Bert 模型上 INT8 混合精度在精度基本无损下获得了 7 倍的推理加速收益,在 Resnet 模型上获得了 4 倍的推理加速收益。
加速 SDK
目前在 CV 和 NLP 的场景里面我们使用了大量的预训练模型作为我们的基准,所以针对于常见的模型结构我们建立了对应的任务模板,将之前积累下来的优化能力进行沉淀到我们的加速 SDK 中。
比如当算法同学完成模型的训练后,会通过我们预先设定的任务模板,对训练出来的模型进行蒸馏、量化,以及模型格式的转换,对于转换中不支持的算子我们搭建对应的算子库进行替换,当发现精度不够时,会回滚到相应的原始模型状态,从而提升整体的开发效率以及最终模型落地的性能。

当然,我们遇到一些新的模块结构,会发现我们当前的 SDK 是无法满足各个场景的需求,这个时候还是需要算法工程的同学对整个模型进行性能分析,继而不断的总结沉淀到我们的 SDK 中。
如何提升算法工程效能
通过对服务的性能提升和模型性能的提升,我们已经能够开发一个性能比较高的服务。
目前算法同学训练完模型之后,会交付一个模型给到算法工程同学,算法工程同学修改模型后再加载到我们的 RPC 框架中。但整个信息流中处理的服务模块非常多,迭代也很快,这就使得:
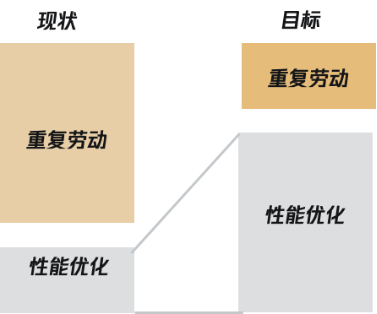
算法同学:算法策略依赖工程发布,迭代效率低,工程知识比较薄弱
工程同学:开发算法服务理解成本高,重复劳动多
因此我们希望能够逐步优化整个开发流程,并且使得原来之前交付一个算法模型变成交付一个算法服务,如此一来:
算法同学:可以专注于模型结构的设计,并且快速迭代
工程同学:深度挖掘模型性能,不断优化流程效率,扩展技术边界。
所以我们首先将整个工程服务进行模板化,屏蔽底层的 RPC 的逻辑,抽象算法工程的通用逻辑,固定模型加载、版本管理、推理接口,通过脚手架自动生成,同时支持插入模型的前后预处理以及模型的拓扑。

这样的话,算法同学提供模型 + 前后预处理,就可以一键部署大部分的算法模型。
一个完整的算法开发过程中,包括了样本的标注、模型的训练、模型效果的评估、模型性能的优化、模型的上线以及线上数据的反馈。之前我们只解决了服务的问题,而其他问题的解决还需要和公司的训练,发布等平台进行打通。
目前我们为常见的基于多模态的视频分类任务建立了一套完整的流程:
用户在界面上操作,上传业务数据集,进行模型训练
对于采用的预训练模型,通过蒸馏和量化进行模型加速,并进行速度和精度评测
对模型进行转换以及评测,选择最优部署方案
生成对应的部署代码,发布平台拉起镜像,下发模型
RPC 框架加载模型,对外提供服务
线上服务的数据上报落表,并进行巡检,将结果作为数据集提供到模型训练

通过这么一套流程,我们实现了从数据生产、模型训练、模型优化、模型上线、数据反馈的完整闭环,从而大大提升了整体的开发效率。
小结
作为工程团队,我们的目标就是不断提升服务性能和开发效率,通过不断的边界左移,从模型框架的性能逐步拓展到模型自身的性能,并最终打造了 AI 全流程的能力。
后续我们也会持续集成 triton 等业界各类新的能力,也欢迎其他团队多多交流沟通。
最后感谢团队负责人 seta、chale 的支持,这项工作也汇聚了 maple、bowen、alvin、robert、shawn、alex、deven、jianxun、trey 等小伙伴很多的心血。
作者介绍
袁易之(微信号:madwolf),QQ 小世界内容理解算法工程负责人,曾负责腾讯看点内容中心能力建设,对信息流业务中内容处理领域有一定的经验。在司内司外积极拥抱开源,和公司内部多个平台共建,也曾是司外 PHP 开源项目 Swoole 的核心开发者,致力于开发效率和服务性能的提升。




