
数据网格(Data Mesh)是近来受到广泛重视的一种新型架构范式。每家数据和平台提供商都说明了怎样使用自己的平台来构建最好的数据网格。数据网格的故事包括像亚马逊云科技这样的云计算提供商,像 Databricks 和 Snowflake 这样的数据分析提供商,以及像 Confluent 这样的事件流解决方案。本文详细讨论了这一原理,并探索了为何没有一种技术最适合构建数据网格。本文列举的例子表明,为何像 Apache Kafka 这样的开放和可扩展的分布式实时平台一般都是数据网格基础设施的核心,而其他数据平台则是为了解决业务问题而提供支持。
静态数据与动态数据
在我们开始数据网格的讨论之前,必须先弄清楚静态数据和动态数据之间的差异和关联性。
静态数据:数据被摄取并存储在一个存储系统中(数据库、数据仓库、数据湖)。为存储系统执行业务逻辑和查询。日常用例包括:使用业务智能工具的报告、机器学习中的模型训练,以及诸如洗牌、映射和 Reduce 等复杂的批处理分析。因为数据是静态的,所以处理对于实时用例来说太迟了。
动态数据:当将新的事件传送到平台上后,对这些数据进行了连续的处理和关联。实时执行业务逻辑和查询。常见的实时用例包括库存管理、订单处理、欺诈检测、预测性维护,和很多其他的用例。
实时数据优于慢速数据
在几乎任何行业的所有用例中,实时数据都优于慢速数据。所以,问问你自己或者你的业务团队,他们希望或者需要在下一个项目如何消费和处理数据。静态数据和动态数据是有取舍的。因此,这两个概念是相辅相成的。基于此,现代云计算的基础设施在其架构中同时应用了这两个概念。《使用 Kafka 的无服务器事件流与亚马逊云科技 Lakehouse 的结合》(Serverless Event Streaming with Kafka combined with the AWS Lakehouse)是一个很好的资源,可以了解更多的信息。
但是,尽管将批处理系统连接到实时神经系统是可能的,但反过来说,将实时消费者连接到批处理存储就不太可能了。关于 《Kappa 与 Lambda 架构》(Kappa vs. Lambda Architecture)文章的讨论,将会给我们带来更多的见解。
Kafka 是一种数据库。因此,对于静态数据,也可以使用。比如,如果要确保排序,那么历史事件的可重放性就是很多用例所必需的,也是有帮助的。但是,Kafka 的长期存储存在着一定的局限性,例如,它的查询功能受到了限制。所以,对于很多用例来说,事件流与其他存储系统是相互补充而非相互竞争的。
数据网格:一种架构范式
数据网格是一种实现模式(不同于微服务或域驱动设计),但应用于数据。ThoughtWorks 发明了这个词。你可以在网络上发现很多资源。Zhamak Dehghani 在 2021 年欧洲 Kafka 峰会上就“如何构建数据网格基础及其与事件流的关系”(How to build the Data Mesh Foundation and its Relation to Event Streaming) 做了精彩演讲。
域驱动 + 微服务 + 事件流
数据网格并非一种全新的范式。它产生了若干具有历史意义的影响:
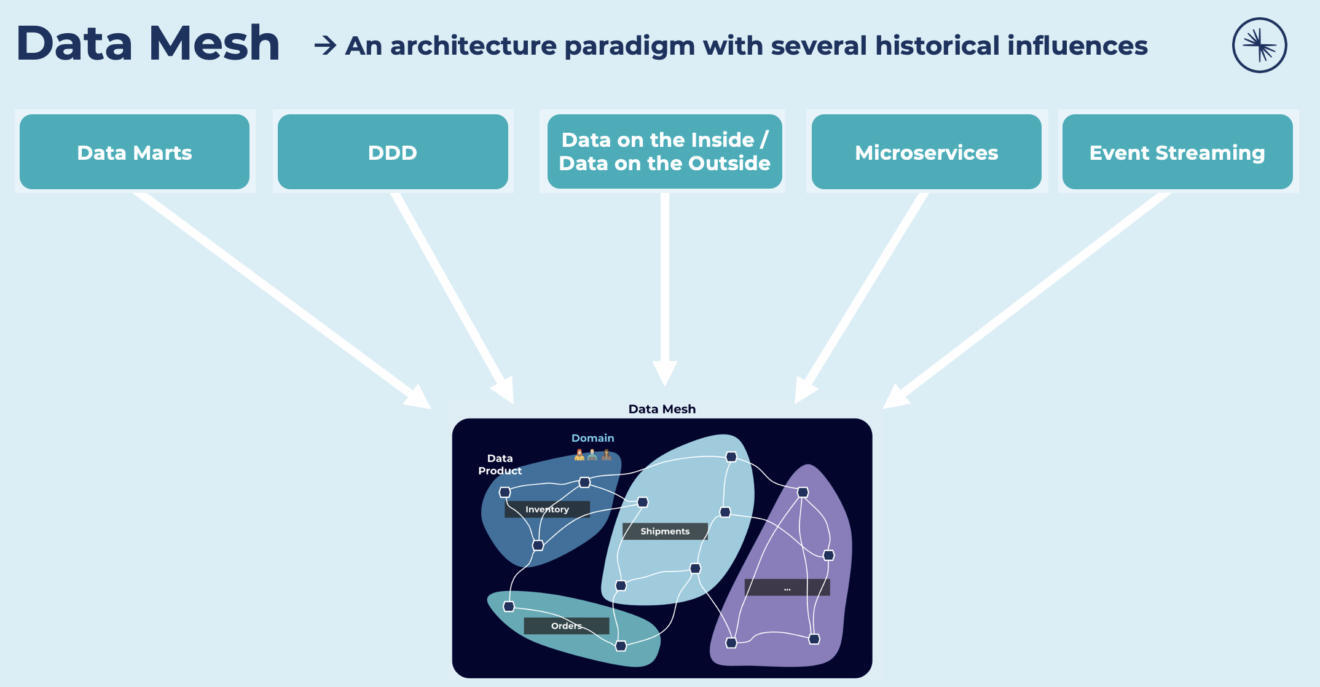
这种架构的范式能够大规模解锁分析数据,为整个组织的机器学习、分析或数据密集型应用等大量消费场景快速解锁了对数量不断增加的分布式域数据集的访问。数据网格解决了传统的集中式数据湖或数据平台架构的常见故障模式。
数据网格是一种逻辑视图,而非物理视图!
数据网格转变为借鉴现代分布式架构的范式:将域视为第一流的关注点,应用平台思维来创建一个自助式数据基础设施,将数据视为一种产品,并实施开放的标准化,从而实现具有互操作的分布式数据产品的生态系统。
下面是一个数据网格的例子:
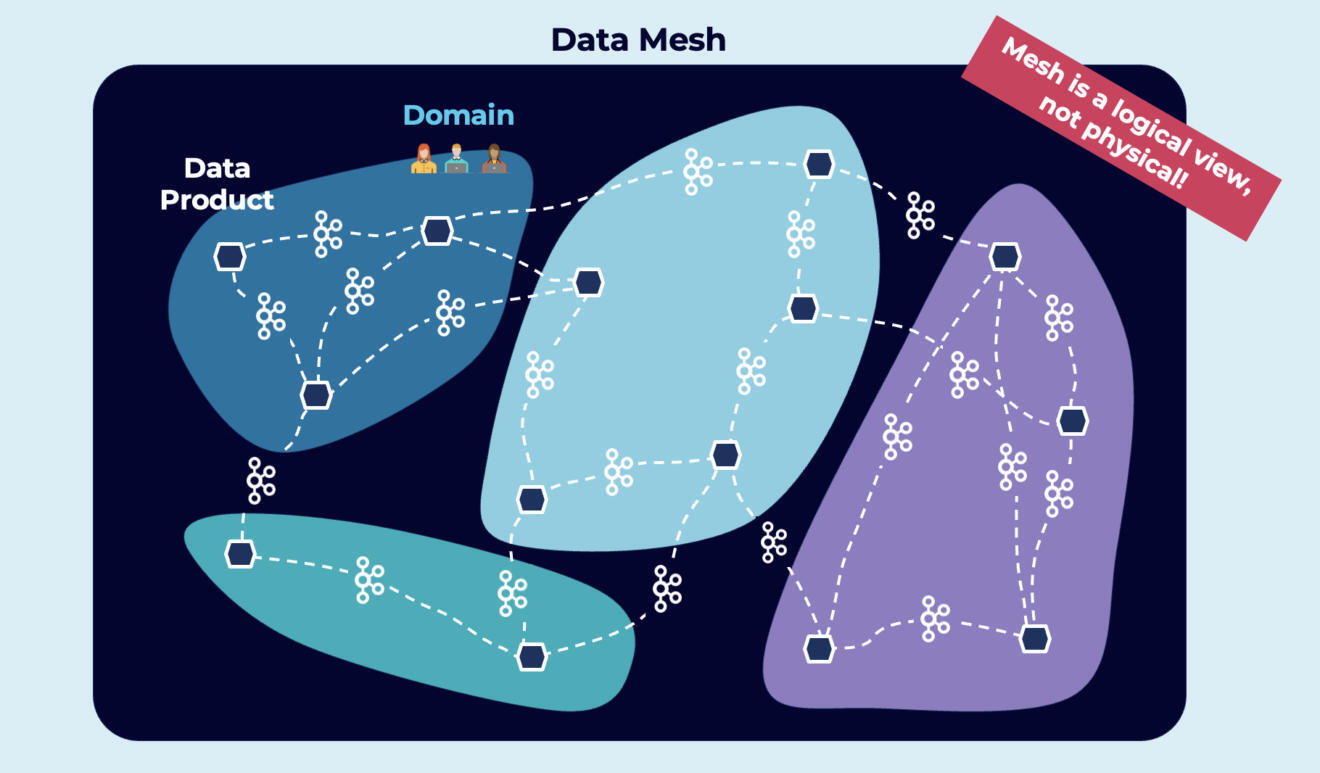
概括:数据网格结合了现有的范式,包括域驱动设计、数据集市、微服务和事件流。
数据即产品
但是,差异的一面集中在了产品思维(“数据的微服务”),即将数据作为一流的产品。数据产品是事件流与“动态数据”的完美结合,从而构建出创新的、全新的实时用例。
具有事件流的数据网格
为什么事件流很适合数据网格?
流是实时的,所以一旦有新的信息,你可以立即在整个网格中传播数据。流还具有持久性和可重放性,因此它们可以让你用一个基础设施同时捕获实时和历史数据。由于它们是不可改变的,因此它们是一种很好的记录来源,可以帮助治理。
在大部分创新用例中,动态数据是关键。正如之前所讨论的,在几乎所有的情况下,实时数据都优于慢速数据。因此,数据网格架构的核心是一个事件流平台,这是合理的。它提供了真正的解耦、可扩展的实时数据处理,以及跨边缘、数据中心和多云的高可靠性操作。
Kafka 流 API:移动数据的事实标准
Kafka API 是事件流的事实标准。我不再对此进行重复的讨论。在我们进入“Kafka + 数据网格”内容之前,这里有一些参考资料:
《为什么 Kafka 会像 Amazon S3 一样成为标准 API?》(Why Kafka became a Standard API like Amazon S3)
《事件流和 Kafka 供应商的比较,如 Red Hat、Cloudera、Confluent、Amazon MSK 的比较》(Comparison of event streaming and Kafka vendors like Red Hat, Cloudera, Confluent, Amazon MSK)
《Apache Kafka 与 Apache Pulsar》(Apache Kafka versus Apache Pulsar)
Kafka 支持的数据网格
我强烈推荐大家观看 Ben Stopford 和 Michael Noll 关于《Apache Kafka 和数据网格》(Apache Kafka and the Data Mesh)的演讲。本文的几张截图也是来自那个演讲。为我的两位同事点赞!演讲探讨了数据网格的关键概念以及它们与事件流的关系:
域驱动的去中心化
数据作为一种自助式服务的产品
一流的数据平台
联合治理
下面让我们看看,Kafka 的事件流如何融入数据网架构,以及其他解决方案,如数据库或数据湖如何与之互补。
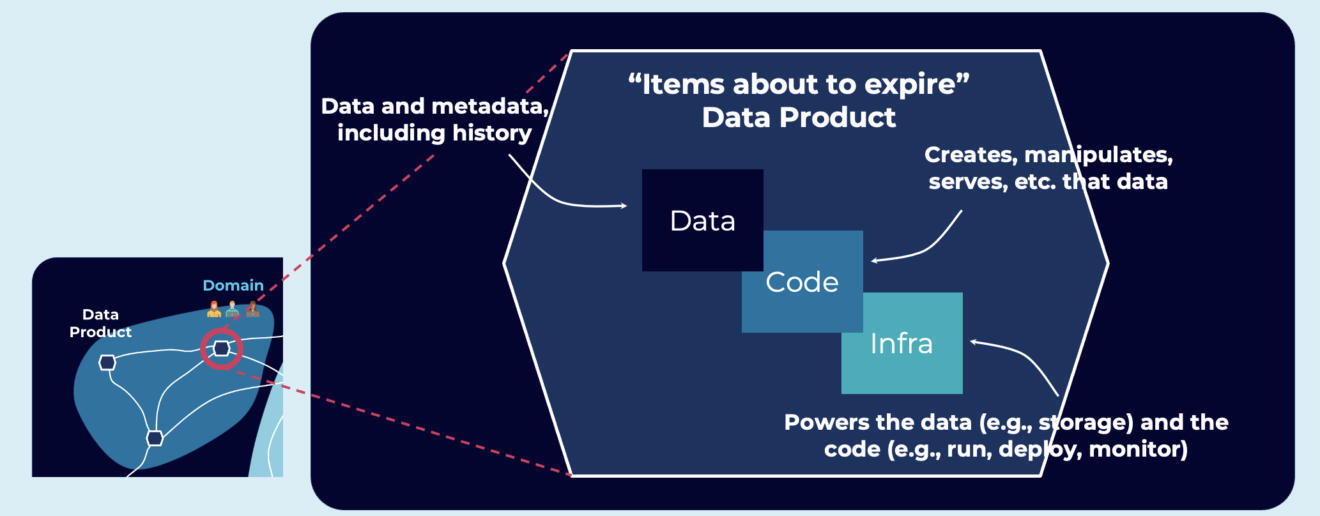
数据产品,一种“数据世界的微服务”:
数据网格中的一个节点,位于域内。
在网格中产生并可能消费高质量的数据。
封装了其功能所需的所有元素,即数据和代码加基础设施。
数据网格不只是一种技术!
数据网格基础设施的核心必须是实时、解耦、可靠和可扩展的。Kafka 是一个现代的云原生企业集成平台(今天也经常被称为 iPaaS)。因此,Kafka 为数据网格的基础提供了一切功能。
但是,并非所有的组件都可以或者应当以 Kafka 为基础。为问题选择合适的工具。在接下来的几节中,我们将探索 Kafka 原生技术以及其他的解决方案在数据网格中的应用。
利用 Kafka Stream 和 ksqlDB 在数据产品中进行流处理
将来自一个或多个数据源的信息,基于事件的数据产品实时地聚合并将其关联起来。无状态和有状态的流处理是通过 Kafka 原生工具(如 Kafka Streams 或 ksqlDB)实现的:
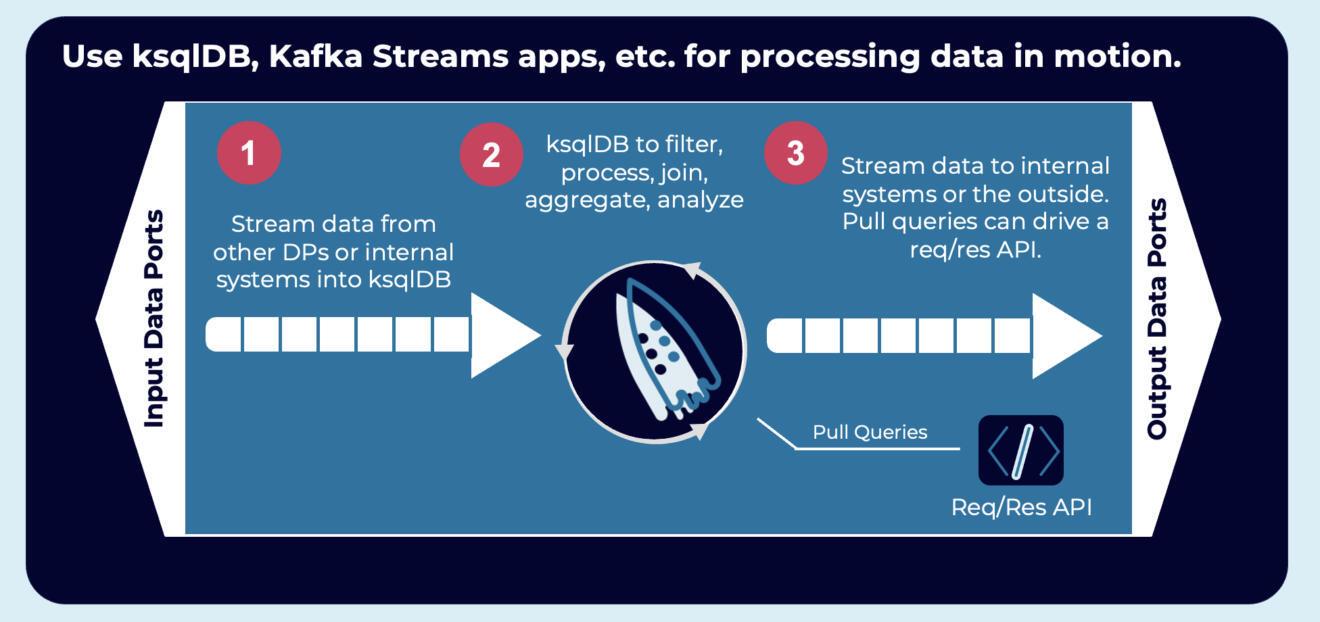
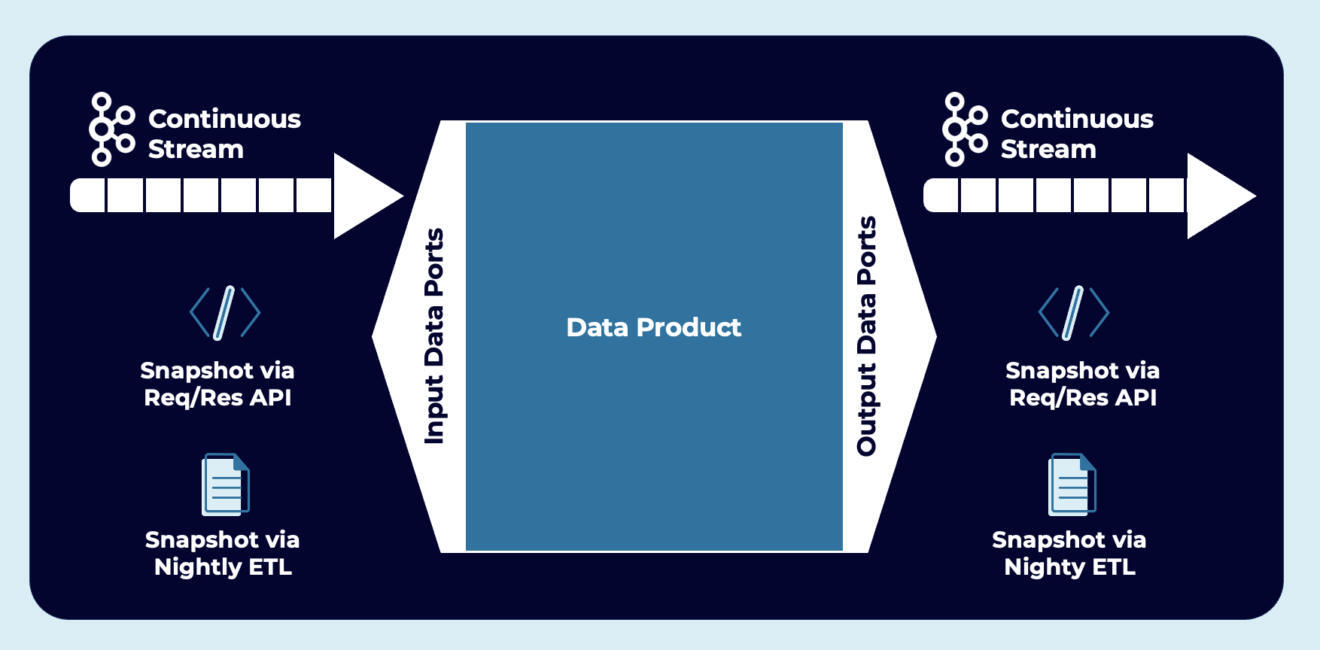
数据产品中的各种协议和通信范式:HTTP、gRPC、MQTT 等
很明显,并非所有的应用都仅将事件流用作技术和通信范式。上图显示了一个消费者应用,它还可以使用 HTTP 或 gRPC 这样的请求/响应技术进行拉取查询。相比之下,另一个应用则用任何编程语言(如 Java、Scala、C、C++、Python、Go 等)的原生 Kafka 消费者持续消费流式推送查询。
数据产品往往包括一些互补的技术。例如,如果你构建了一个车联网基础设施,那么你很有可能会利用 MQTT 进行“最后一公里”的整合,将数据摄入 Kafka,然后再通过事件流来进行处理。《Kafka + MQTT 博客系列》(Kafka + MQTT Blog Series)是关于如何利用互补性技术来构建数据产品的一个典型实例。
数据产品内的各种解决方案:事件流、数据仓库、数据湖等
微服务架构的美妙之处在于,每个应用都可以选择合适的技术。一个应用程序可以包含数据库、分析工具其他补充性组件,也有可能不包括。数据产品的输入和输出数据端口应该与选定的解决方案无关:

Kafka Connect 是正确的 Kafka 原生技术,可以将其他技术和通信范式与事件流平台连接起来。评估你是否需要另一个集成中间件(如 ETL 或 ESB),或者 Kafka 基础设施是否是数据网内的数据产品更好的企业集成平台(iPaaS)。
全球流数据交换
数据网格的概念与全球部署有关,而不只是局限于某一项目或区域。多个 Kafka 集群是常态,而非例外。很久以前,我就写过《客户将 Kafka 的事件流用于全球架构》(Event Streaming with Kafka in global architectures) 的文章。
目前有多种架构可以将 Kafka 部署到不同的数据中心和不同的云上。某些用例要求较低的延迟,将某些 Kafka 的实例部署到边缘或者 5G 区域。其他的用例,包括在全球各地、国家和大陆之间进行数据复制,用于灾难恢复、聚合或分析用例。
下面是一个例子,跨越亚马逊云科技、Azure、GCP 或阿里巴巴等多个云计算提供商和内部/边缘站点的流式数据网格:
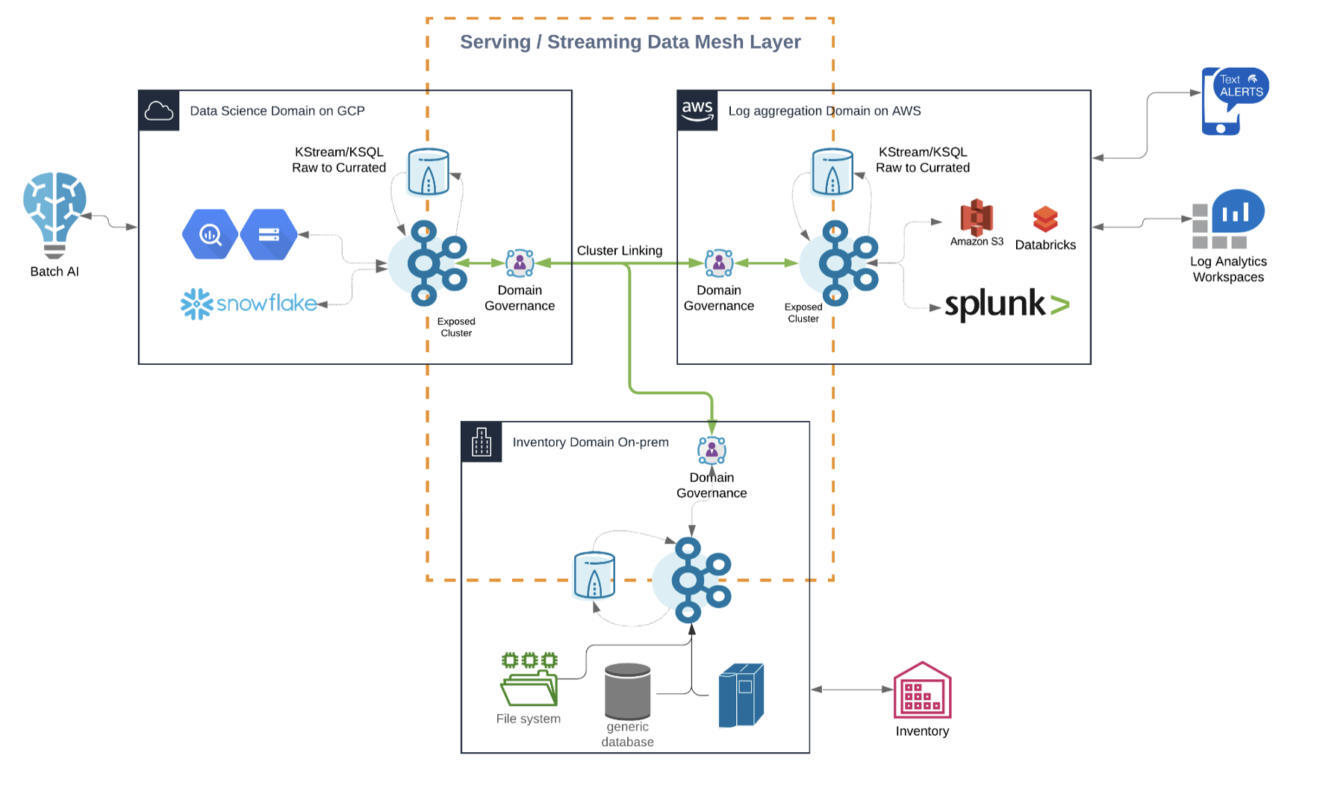
这个例子显示了上述章节中所讨论的数据网格的所有特性:
跨域和基础设施的分布式实时基础设施
云内和云间的域之间的真正解耦
几种通信范式,包括数据流、RPC 和批处理
与传统和云原生技术的数据集成
在能增加价值的地方进行连续的流处理,并在一些分析汇总中进行批处理
实例:汽车行业跨域的流数据交换
以下是汽车行业的一个实例,显示了在不同的公司中,独立的利益相关者是怎样利用公司内部的流数据进行交换的:
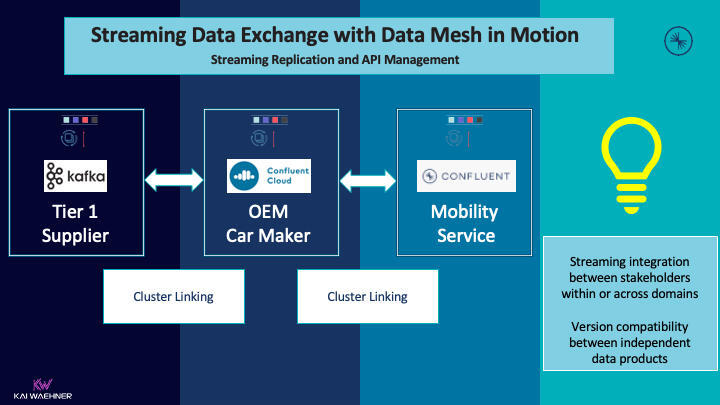
创新永远不会止于自己的边界。流复制适用于所有实时性优于慢速数据的用例(对大多数场景有效)。举几个例子:
从供应商到 OEM 到中间商到售后的端到端供应链优化
跨国追踪溯源
第三方附加服务与自身数字产品的整合
嵌入和组合外部服务的开放 API,以建立一个新产品。
我可以继续列举下去。许多数据产品都需要通过第三方进行大规模的实时访问。在这种情况下,有些 API 网关或 API 管理工具就会发挥作用。
一个 由 Kafka 支持的流数据交换的现实世界的实例是移动服务 Here Technologies。他们公开了 Kafka API,可以直接从其映射服务中获取流数据(作为他们的 HTTP API 的一个替代选择):

但是,即便所有的合作伙伴都在自己的架构中使用 Kafka,那么直接向外界公开 Kafka API 并不一定总是正确的。Kafka 生态系统的某些技术能力(例如访问控制或连接到成千上万的设备),以及缺失的业务功能(如货币化或报告),使得事件流基础设施之上的 API 层在许多实际部署中发挥作用。
用于第三方集成和流 API 管理的开放 API
API 网关和 API 管理工具有很多种类,包括开源框架、商业产品和 SaaS 云产品。功能包括技术路由、访问控制、货币化和报告。
然而,大多数人仍然以 RPC 的方式实现开放 API 的概念。我猜 95% 以上的人还在使用 HTTP(S) 来使 API 能够被其他利益相关者(例如其他业务部门或外部各方)访问。如果数据需要实时地大规模处理,那么 RPC 在流数据网格架构中就没有什么意义了。
事件流和 API 管理之间仍然存在阻抗不匹配的问题。但是,现在情况有所好转。像 AsyncAPI 这样的规范,自称是“定义异步 API 的行业标准”,还有类似的方法为数据流世界带来了开放 API。我那篇名为《Kafka 与 MuleSoft、Kong 或 Apigee 等工具的 API 管理》(Kafka versus API Management with tools like MuleSoft, Kong, or Apigee)的论文,如果你愿意对此进行更深入的探讨,那么它依然是非常正确的。IBM API Connect 是最早通过 Async API 集成 Kafka 的厂商之一。
从 RPC 到流 API 的演变,一个很好的例子就是机器学习领域。《用 Kafka 原生模型部署流式机器学习》(Streaming Machine Learning with Kafka-native Model Deployment)探讨了 Seldon 等模型服务器如何在 HTTP 和 gRPC 请求—响应通信之外用原生 Kafka API 增强他们的产品:
使用 Kafka 的流式数据网格之旅
范式的转变是很大的。数据网格不是免费午餐。对于微服务架构、领域驱动设计、事件流和其他现代设计原则,过去和现在都是如此。
与 Confluent 的事件流成熟度模型相类似,我们的团队描述了部署流式数据网格的历程:
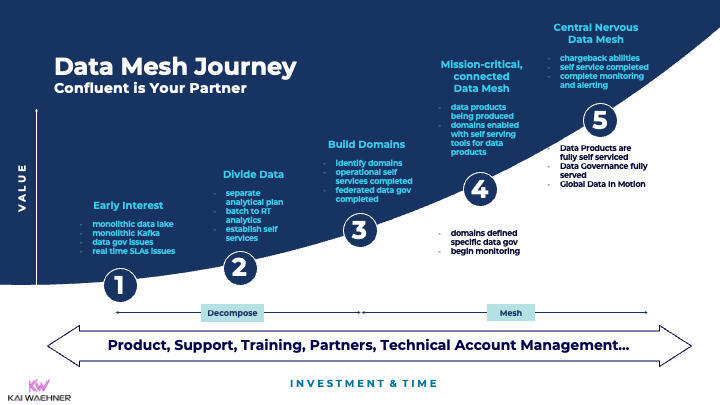
这些努力在大多数情况下可能需要几年时间。这一转型不仅涉及技术层面,也涉及组织和业务流程的调整。我认为大部分公司都还处在起步阶段。告诉我你在这个旅途中发生了什么!
流数据交换作为数据网格的基础
数据网格是一种实施模式,而非特定的技术。然而,大多数现代企业架构需要一个分散的流数据基础设施,以便在独立的、真正解耦的域中构建有价值的创新数据产品。因此,Kafka 作为事件流的事实上的标准,在许多数据网格架构中起着重要的作用。
很多数据网格架构跨越了不同地区,甚至是大陆的许多域。部署在边缘、内部和多云上运行。这种集成连接到许多解决方案,具有不同通信范式的技术。
基于开箱即用的云原生事件流基础设施,可以构建一个现代化的数据网格。没有一个数据网格会使用单一的技术或者厂商。从你最喜欢的数据产品提供商(如亚马逊云科技、Snowflake、Databricks、Confluent 等)的鼓舞人心的帖子中学习,从而成功地定义并构建你的自定义数据网格。数据网格是一段旅程,并非一场大爆炸。
作者介绍:
Kai Wähner,在 Confluent 担任技术布道师。他的主要专业领域是大数据分析、机器学习/深度学习、消息传递、集成、微服务、物联网、流处理和区块链等领域。他经常在国际会议上发言,如 JavaOne、O'Reilly 软件架构或 ApacheCon,为专业期刊撰写文章,并在他的博客(www.kai-waehner.de/blog)上分享他对新技术的经验。
原文链接:
https://dzone.com/articles/streaming-data-exchange-with-kafka-and-a-data-mesh




