
引言
“贝壳找房在做的就是推动居住服务这个传统行业进行深度的互联网化,在这个过程中数据是非常重要的支撑。”
——张如松,贝壳找房数据平台高级工程师
近日,Apache Kylin 5 周年在线庆典顺利结束,来自贝壳找房的张如松老师为大家介绍了 Apache Kylin 在在贝壳找房指标体系的应用,包含 Kylin 升级历程以及对 Kylin 4.0 版本的展望。
以下是张如松老师的现场分享实录。
Apache Kylin 在贝壳找房的发展历程
贝壳找房是以技术驱动的品质居住服务平台,聚合和赋能全行业的优质服务者,打造开放的品质居住服务生态,致力于为 3 亿家庭提供包括二手房、新房、租赁、装修和社区服务等全方位的居住服务,涉及到了居住服务的方方面面。
贝壳找房有 4+ 年的 Kylin 使用经验。从 2016 年下半年开始,当时有一个 Hive + MySQL 的平台,内部代号是地动仪,用来解决业务线的多维分析需求。
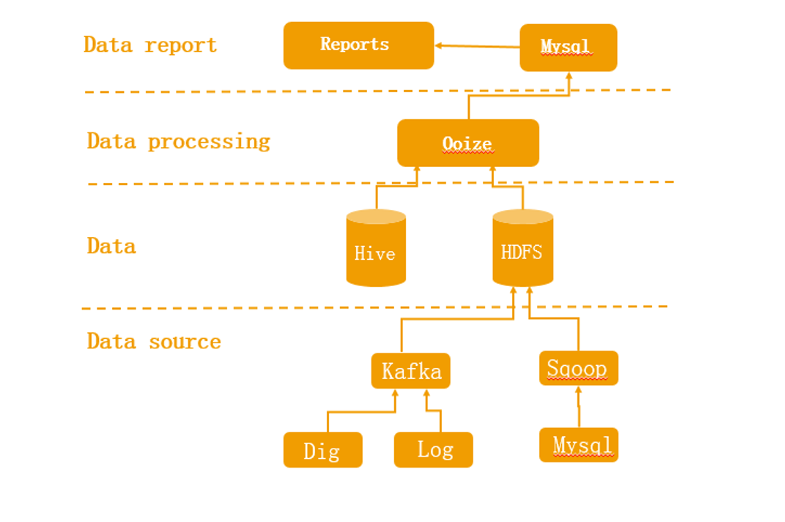
Kylin 在贝壳找房中的架构体系
上图展现了平台数据的流转过程,负责数仓的同学会将数据进行初步的预聚合,再通过关系数据库来提供查询。 但是随着数据量的快速增长,查询响应的时间变得越来越长,底层数据库的运维压力也越来越大。 为了解决这些问题,同时为了支撑公司的指标体系建设,需要一个既能够支持大规模数据计算,也可以对查询作出快速响应的引擎。
经过调研,从可支持海量数据计算、亚秒级查询响应、支持标准 SQL、以及可维护性,涉及的技术栈以及社区活跃度上,Kylin 都符合作为数据引擎来支撑企业指标体系建设的要求。
2017 年 3 月,Kylin 1.6 版本上线
随着指标平台的上线,Kylin 开始对外提供服务。
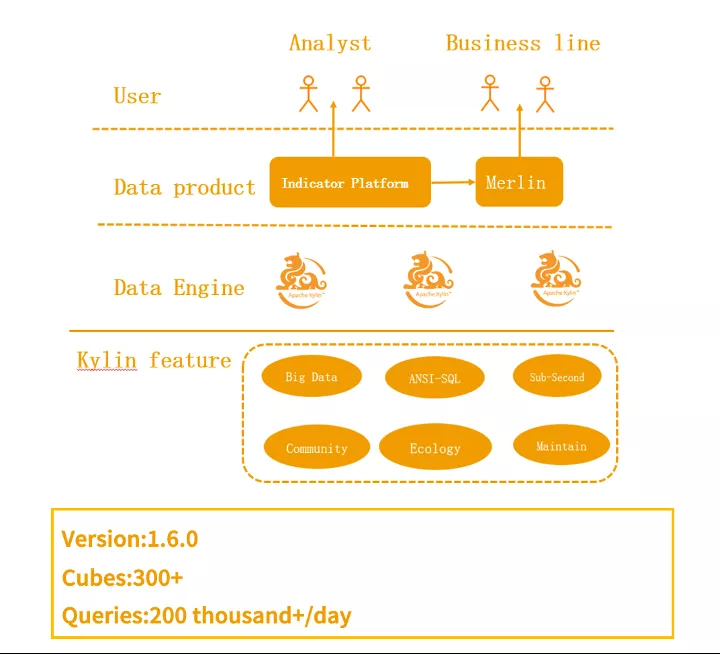
2017 年底,贝壳已经累计创建了 300 + Cube,每天有 20 多万的查询量
2018 年初,随着指标在各业务线的推广,有越来越多的数据产品开始接入 Kylin
例如像 Merlin、Turing 等数据产品,这些产品从 PC 端到手机端覆盖的范围非常广泛,涉及到公司组织架构的各个层级,都有相应的数据需求。同时为了保障重点数据的产出和查询,我们又部署了一套集群来给重点业务使用。
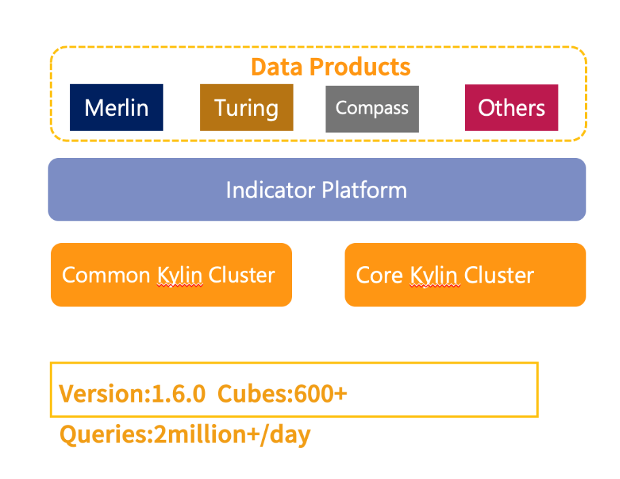
2018 年底,贝壳一共有 2 套集群,累计创建了 600+ Cube,每天的查询量达到了 200 万。
2019 年初,我们 Kylin Team 定下了两个 KPI,在机制方面要保障重点数据在每天上午 9 点之前产出,在查询上要达成 3 秒钟内响应占比 99.7%,将 Kylin 升级到 3.1 版本,主要来做实时多维分析的应用。
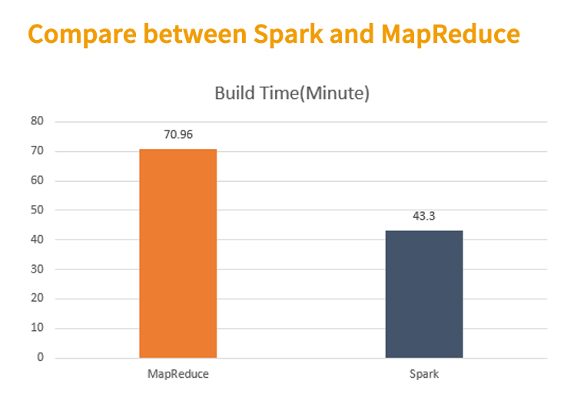
为了达成这两个目标,在计算方面我们把集群从 1.6.0 升级到 2.5.2,引入了 Spark 组件,将重点 Cube 构建的方式从 MR 改为了 Spark。
上图是调优前后的对比,重点 Cube 的平均构建时间从 70 分钟降到了 43 分钟,近 40% 左右的提升;在查询方面也通过一系列的优化,在 12 月就达成了 3 秒内占比 99.7% 的目标。
下图是当时每天的统计数据,到 19 年底贝壳还是两套集群,版本是 2.5.2,累计 700+ Cubes,每天的查询量超过了 1000 万。
2020 年初,Kylin 升级到 3.1.0,引入了 Flink 组件。
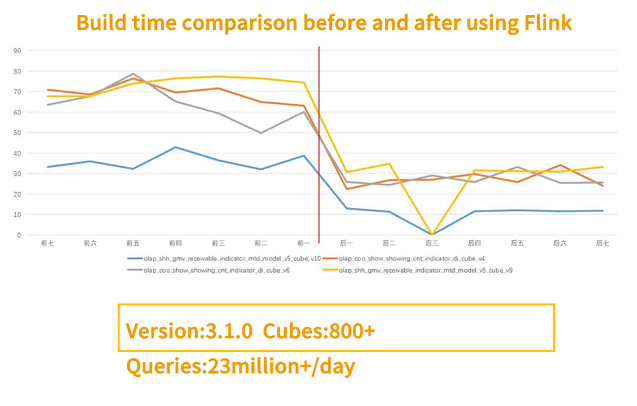
下图是公司的一级指标使用 Flink 组件前后花费时间的对比,可以看到提升比较明显,截止到 2020 年底,贝壳有两个 3.1 的集群,累计 800+ Cubes,每天的查询量最高超过了 2300 万。
使用 Flink 前后的构建时长对比

总的来说,这几年贝壳找房围绕 Kylin 主要在做平台化的建设。
下图右边最下面是 Kylin 集群,我们把集群的节点分成了 3 种角色,一台 Master 节点,负责接受提交的构建任务和提供元数据查询服务。Master 节点既不参与查询也不参与构建。有多台构建器(Job 节点)和查询机器(Query 节点)提供服务,这是在集群节点上的划分。集群本身是不对外开放的,通过上层平台提供服务。在平台侧主要是围绕 API、任务、查询、元数据做了一些工作。我们封装了 Kylin 的 API,对创建的 Cube 的流程进行了简化,同时对接了公司的权限体系来对模型进行权限控制。
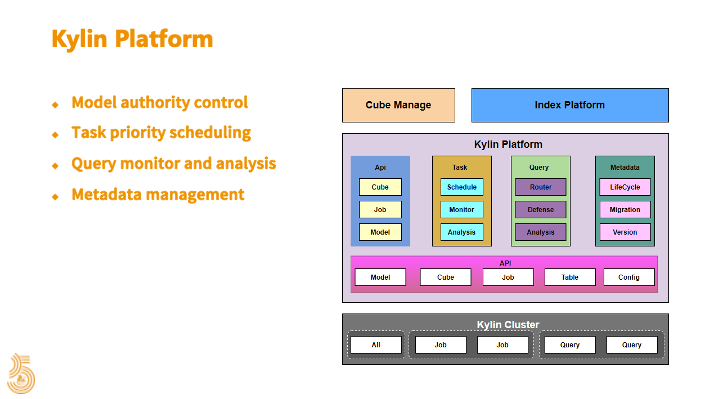
在任务管理上,由平台控制任务的提交,包括任务的优先级,任务的运行数,还有对任务状态的监控和异常数据的报警等。在查询上,包括对 Cube 所在集群的路由,以及对查询的实时监控和分析。在元数据管理上,我们对 Cube 进行了生命周期管理,当符合规则的时候,会启动 Cube 下线的流程。元数据管理还包括对 Cube 在不同集群之间的迁移和集群的版本控制、配置管理等等。
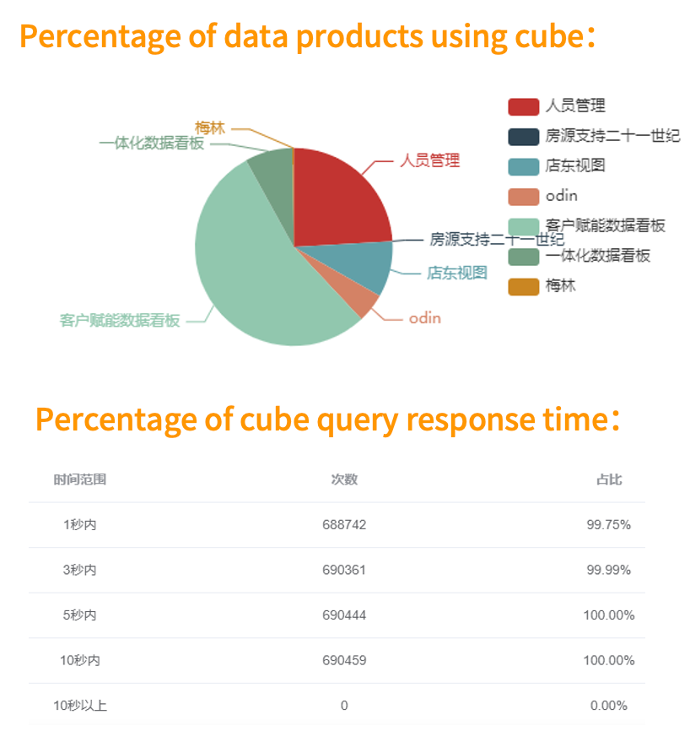
下图展示的是平台里非常有意思的一个功能,叫做 Cube 查询分析,每个小时都会分析一次 Kylin 的查询日志,统计出这些 Cube 被查询了多少次,有哪些产品使用 Cube 的数据,上面这个图就是一个 Cube 被不同产品查询次数的占比,可以看到这个 Cube 有 7 个产品在用,下面这个图是 Cube 的响应时间在不同范围内的查询次数和占比,可以看到这个 Cube 被查询了 69 万次,3 秒内占比达到了 99.99%。
我们会解析 Cube 查询解析的每一条 SQL,拿到 SQL 用到的维度组合以及对应的响应时间,下图包括三个方面内容:
Cube 被使用最多的维度组合排行
Cube 查询慢的组合排行
最近 30 天都没有用到过的维度

通过这些数据可以让 Kylin 的用户更好的了解数据的使用情况,也可以根据这些信息做一些针对性的优化,比如在构建和查询方面。
Kylin 在贝壳能高效的运用离不开内部同学的贡献。下图是这几年贝壳找房的同学贡献到社区的一些记录,先后有 4 位同学向 Kylin 贡献代码,涉及任务调度、Web 页面、构建和查询的优化等等多个方面,覆盖了从 1.6 到 3.1 的各个版本。

贝壳找房开发人员对 Kylin 的贡献
Kylin 在贝壳找房指标体系建设过程中的作用
贝壳找房是在 2016 年下半年开始规划指标体系的建设,为了明确指标的定义,统计数据的口径,提高数据的共享性和安全性,同时规划了指标平台来承载指标体系的建设,并且使用 Kylin 来作为指标体系的数据引擎,来提供数据服务。
下图是以 Kylin 为基础的指标平台的架构,通过对数仓数据的建模计算,提供给指标平台使用,指标平台以 API 的方式对外提供服务,API 的基础是指标,业务方定义的 API 可以包含一个或多个指标。
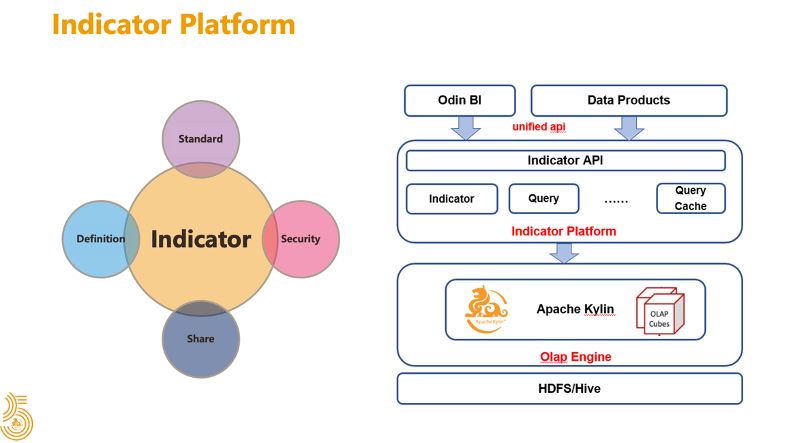
下面是基于 Kylin 的指标计算和使用的流程,首先数仓的同学会根据业务过程进行建模,从源数据有一个 ETL 的过程,最后会在 OLAP 层产生一张事实表,接着会在 Kylin 上关联维表创建模型和 Cube,创建完 Cube 后会自动在调度系统生成一个依赖事实表和维表的任务,接着会在指标平台定义指标,配置一下计算方式,支持的维度等信息,创建完指标之后就可以在 API 配置使用,调度系统会根据任务依赖来触发 Cube 的构建,数据构建完之后各种数据产品就可以通过 API 来使用这些数据,这是基于 Kylin 的指标创建和使用的流程。
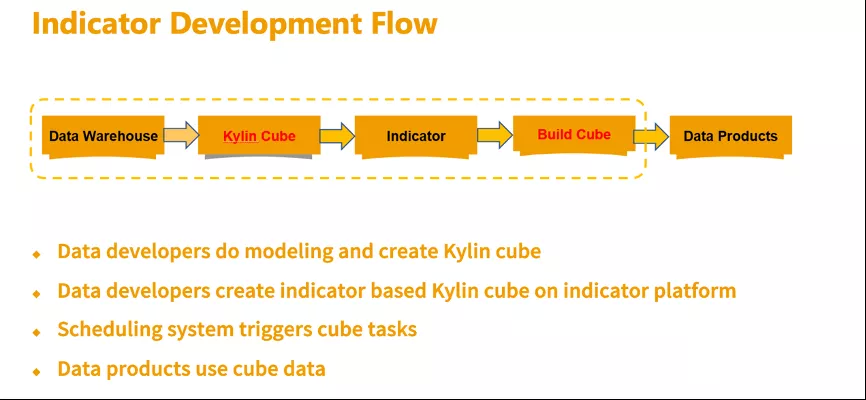
接下来为大家介绍两个指标的例子,两种不同的计算方式,一个是 SUM 类型,一个是 COUNT DISTINCT 类型的精确去重。
在贝壳找房指标体系里面,精确去重是非常强的需求,尤其是一些涉及到业绩类的指标,比如经纪人的带看量,精确去重也是 Kylin 的优势之一。
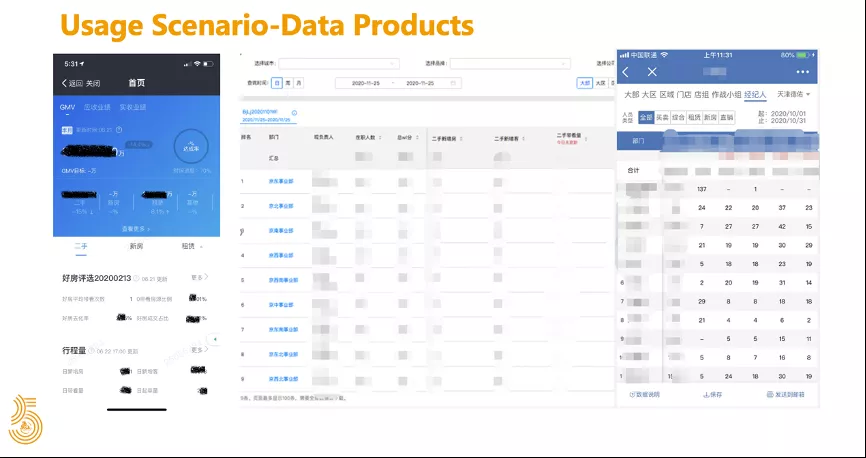
上图左右两边是手机端的产品,中间是 PC 端的报表产品,这几款产品都是通过固定的维度组合来获取相应的指标数据,只需要筛选不同的过滤条件就可以快速获取报表。
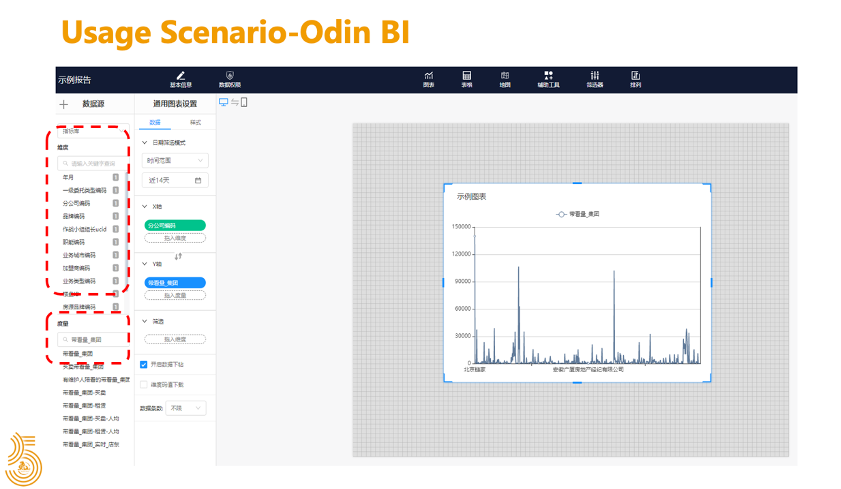
另外一种场景就是可以随意进行维度组合的自助分析场景,做一些探索性的尝试,下图是我们公司自研的 Odin 可视化平台,图左侧两个红框分别是维度和指标,用户可以随意选择他想要的维度和需要的指标,配置筛选条件,右侧的图是根据用户的选择,实时查询 Kylin 生成的图表,当他确定要使用这些维度和指标之后,就可以把当前的配置保存成固定的报表
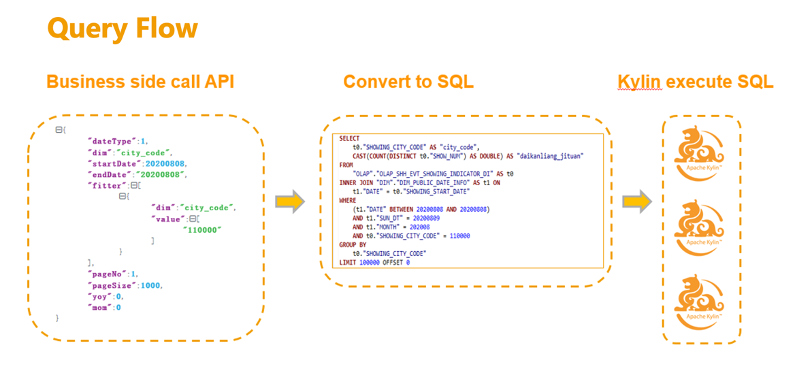
不管是固定报表还是自助分析,底层的查询流程是一样的,下图左侧框是业务方发起指标调用的形式,里面的字段是他需要的维度,同时要指定时间范围和过滤条件,发起一次 API 的调用,中间的框是指标平台,接受 API 的请求,将 API 的参数转化为标准 SQL,然后提交给 Kylin 集群执行查询,查询完了之后会将查询结果返回给指标平台,指标平台将数据封装成固定的格式返回给业务方。这就是贝壳找房各种数据产品使用 Kylin 的底层查询流程。
下图展示了目前 Kylin 在贝壳找房的一个使用情况,因为对接了公司的指标体系,所以 Kylin 的使用覆盖了所有的业务线, 为超过 30 多个数据产品提供查询服务,支撑了 10000+ 指标的计算需求,每天的查询量最高超过 2300 万,我们承诺的查询响应时间是 3 秒内占比是 99.7%,目前来说 Kylin 都能很好的完成这些目标。

对 Kylin 未来发展的展望
对 Kylin 的展望主要是针对 Kylin 4.0,贝壳在 9 月份的时候也做了一次简单的测试,总体来说非常期待 4.0 GA 版本的发布。希望在建模的流程上能够更简化更灵活,比如支持 Schema 的动态更新。在当前的情况下,只要涉及到 Cube 的改动就比较繁琐,希望 Kylin 4.0 能改变这种情况。
关于 Local segment cache,4.0 里面生成的文件是存储在集群上,每次查询都需要实时去读取集群上的文件,同时对集群的资源和性能依赖比较大,可以考虑一下引入为 HDFS 提速的组件,比如 Alluxio,可以将 Segment 的文件缓存到本地来提升查询性能。
关于多租户,希望在查询层面做到对多租户的支持,来避免不同业务之间互相的影响,因为贝壳现在的业务方还是比较多,互相影响的情况也会发生。
关于 Kubernetes,现在的机器数和实例数也比较多,运维的成本比较高,后续会尝试把 Kylin 部署到 Kubernetes 来降低维护成本。
作者介绍:
张如松,贝壳找房数据平台高级工程师,负责 OLAP 引擎的开发和维护以及运维指标体系的建设。
本文转载自公众号 apachekylin(ID:ApacheKylin)。
原文链接:




