
在机器学习不断发展并改变其所涉及的各个行业之后,它才开始向审计世界提供信息。身为数据科学家和前 CPA 审计员,我能理解为什么会这样。实质上,审计是一个关注细节和研究任何例外的领域,而机器学习通常寻求宽泛的推理模式。审计关注的是历史事件的分析,而机器学习解决方案倾向于预测未来事件。最终,大多数审计人员缺乏在工作中熟练运用机器学习所需的教育或编程技能。接下来,我将展示我们如何使用机器学习解决 Uber 的特定审计问题,以及如何扩展我们的方法和架构,以解决大型审计行业中的其他数据问题。
现金中介(也称“代理”)是指公司要求作为公司和其他供应商之间的代理人的第三方供应商。为什么公司需要这样的中介机构?因为你的企业可能在某些国家经营,而在这些国家,你所需要的产品和服务的一些当地供应商无法通过你的 P2P 流程和系统来运作。举例来说,假设你想购买一批鲜花,但是花店不能通过公司的应付账款系统来处理。一个已经成立的代理(其实是入驻公司的 P2P)将用现金帮助你从花店购买这批鲜花。代理随后会把这些费用项目加入到下一张账单中(作为他们自己的服务),公司则会给代理报销。
这个例子很简单,也是良性的。尽管这些代理的使用本身并不违法,但这种交易如果无节制扩散,容易带来一些风险。例如,你如何知道花店可以合法销售?怎样知道鲜花的实际价格?代理向公司收取的费用是否正确?花店和代理之间有利益相关吗?你是利用代理的身份来避开与花店经营者的利益冲突,还是掩盖回扣、贿赂,或者这类费用是不被允许的?
对于 Uber 来说,过去这些代理都是由全球各地的本地团队人工雇佣的,并且他们并不清楚发生了什么。由于我们已对这类案件进行了几次欺诈调查,我们知道有这样的代理存在。但是,仍然存在一些问题:我们到底有多少个供应商被作为代理使用?这些代理用于什么样的情况?而从地域上来看,这些代理被用在哪里,处理了多少?由于没有确定这些代理的系统先例,因此我们最初寻找这些代理的方法是询问当地团队并建立一个启发式方法。我们随后将理解过程转换为 SQL。但是,事实证明,这种方法非常有限。我们认为,代理和非代理之间的关系更为复杂,尤其是在涉及潜在特征数量方面。创建一个逻辑门,其数目应等于 SQL 中每个特征的唯一组合的数目,或者从数学角度讲,$\sum\limits_{i=1}^{n} \frac{n !}{(n-i) ! i !}$(其中 n 是我们的支出管理平台中可用的特征数量),都是不可行的,所以我们假定机器学习能够帮助解决这个问题。
再者,我们只有一小部分标签数据样本(来自当地团队的确认代理)。对于数据源,我们使用一个表格获取数据,并将其输入到支出管理平台,以获得交易类型、描述、金额、货币等特征。
重申一下,我们只有一小部分标签数据样本(来自本地团队的确认代理)。至于数据源方面,我们使用了在支出管理平台中摄取数据的表格来获取数据和特征,如交易类型、描述、金额、货币等。
接受挑战
数据可用性
其中一个主要的障碍是我们没有大量的标签和可用数据。根据我们最初对当地团队的调查,我们在 477 个供应商中,有 47 个被标记为代理。从数据科学家的角度来看,这些样本并不足以训练任何模型。为增加组中的记录数量,我们将数据集从供应商扩大到采购订单。有关如何进行此工作的信息,请参阅模型设计部分。
数据标签
标签主要集中在事实上是代理的供应商上。反过来说,我们无法确认消极标签是否正确。审计人员知道,除了为了确认而增加的工作外,积极确认(当有人明确告诉你某事是否正确时)要好于消极确认(当有人被要求只在某事看起来不正确时才回复)。要解决这一问题,我们应该在每次评估中,将召回分数作为一个指标,基于你面临的业务问题,你可能需要优先考虑其他指标。
研究之旅
降维
在对我们分类的特征(例如货币和部门)进行虚拟编码(或者独热编码)之后,我们最终得到了近 300 个特征。在这里我们可以考虑降维问题,降维通常可以提高训练速度,提高模型性能,或者两者兼而有之。
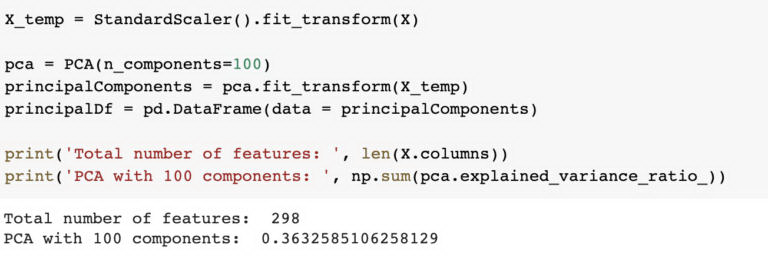
采用主成分分析(Principal Component Analysis,PCA)的方法对 100 个成分进行了分析,仅有 36% 的方差对结果进行了解释。由于三分之一的数据给我们的解释方差只有三分之一多一点,看来我们需要使用所有的特征来捕捉整个画面,因此我们通过模型来推出所有可用的特征。
实验
模型 v1 的设计与结果
在第一次迭代中,我们使用了 K- 最近邻(KNN)。这些特征包括美元金额和四种高风险交易类型的存在。在采购订单级别的预测中,$K∈{1,3,5,7,9}$的准确率约为 92%。在供应商级别的预测中,达到的最高准确率为 88%。作为一种最小特征的简单化模型,它的表现似乎不错。但是,请记住,这一比例是 1:10 左右,数据非常不平衡。因此,考虑到 91% 的基线空准确率(Null accuracy ),我们无法说出这个模型的作用。空准确率指的是,模型每次都只是简单地预测大多数类。因此,在我们 1:10 的不平衡数据集中,如果模型只预测 0,那么它就会准确地预测$\dfrac{10}{11}$次,即 91%。
经验教训:在评估模型性能时,确保评估模型基于基线。在我们的案例中,我们使用的是空准确率。
模型 v2 的设计与结果
在第二次迭代中,我们仅在采购订单级别上使用随机森林分类器。这样做的目的主要是为了训练一个快速模型,让我们了解特征的重要性,以及对这些特征进行分类是否有意义。
通过 4 倍的交叉验证,我们也观察到平均准确率为 95.9%。将其分解后,我们最终得到准确率为 95.8%,召回率为 97.5%。尽管这一结果看起来很有希望,但我们必须谨慎对待评估结果。首先,我们假定所有被标记的供应商的交易都是积极标签的交易。无论如何,我们必须抑制这一因素。另外,我们需要的是对供应商的预测,而非对交易的预测。同时,我们也必须在模型中注入供应商级别的特征。
经过对预测更深入的研究,这个随机森林模型的初步结果出现了一些问题。举例来说,当我们查看一家预测的供应商的所有交易时,我们无法从逻辑上说这个预测具有类似于代理的属性。
经验教训:尽管预测结果有可能高于基线,但也必须回顾由模型生成的预测数据。同时,牢记我们的目标,我们希望预测的是单一的供应商,而非交易。
最终的架构设计
针对标签和可用数据的不足,我们设计了一个双模型架构。
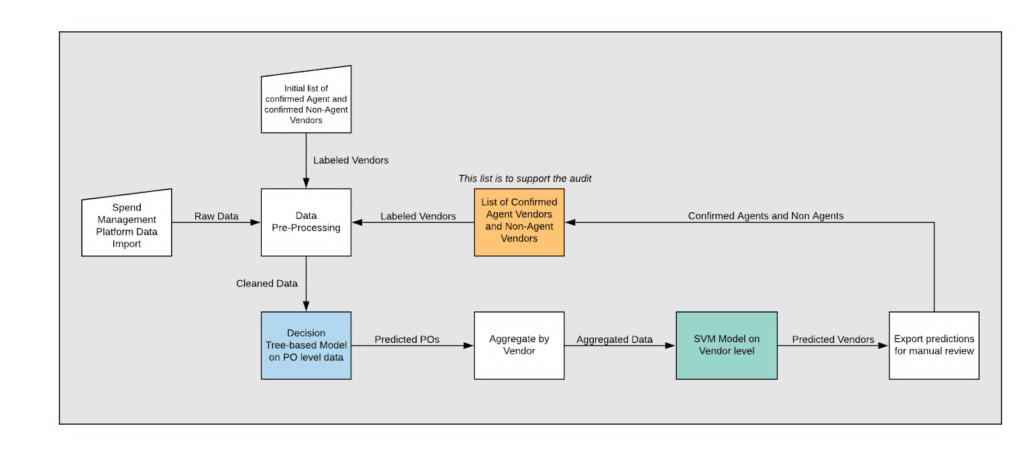
我们建立了一种基于交易级数据和供应商级数据的特征的最终架构。只有使用双模型架构才能做到这一点,其中一个模型依赖于前一个模型的预测。
首先,我们建立了一个基于树的模型,无论是随机森林还是梯度提升决策树。在部署之前对梯度提升决策树和随机森林模型进行了调整。第一个模型将会尝试根据交易级数据进行预测,比如货币、部门、金额和描述。如果这些交易看起来有问题,我们就把这种预测称为第一级预测。当我们调整第一个模型的时候,我们优化了召回分数,因为我们希望最小化假阴性。
仅采用单一模型体系结构,逻辑和技术都会有缺陷。第一,我们的目的是预测代理,而非交易。单独的模型将试图预测交易,而非代理。另外,有些特征不能用交易级数据进行编码,比如每个供应商的商品种类的数量。所以,在进行了第一级预测后,下一步是根据厂商汇总结果。在此过程中,我们选择统计供应商进行交易的唯一实体数量(例如, Uber 和 Uber BV 是不同的实体),统计每个供应商唯一交易类型数量,并取每个供应商预测交易的平均值。举例来说,如果一家供应商有 10 个交易,其中 8 个交易是由第一个模型预测的(未作标签),那么该供应商在汇总中得分 0.80。
最后,支持向量机(Support Vector Machine,SVM)模型将利用这些特征进行最终的预测。通过对支持向量机模型的调整,将不平衡数据考虑在内,优化了平衡准确率得分。
为什么没有使用朴素贝叶斯?因为我们不知道先验概率是多少。请记住,我们的标签数据只是一批手工挑选的供应商。我们不知道他们是占所有供应商或交易的 5%、10%,还是 50%。因此,我们没有任何理由去使用朴素贝叶斯。
模型性能
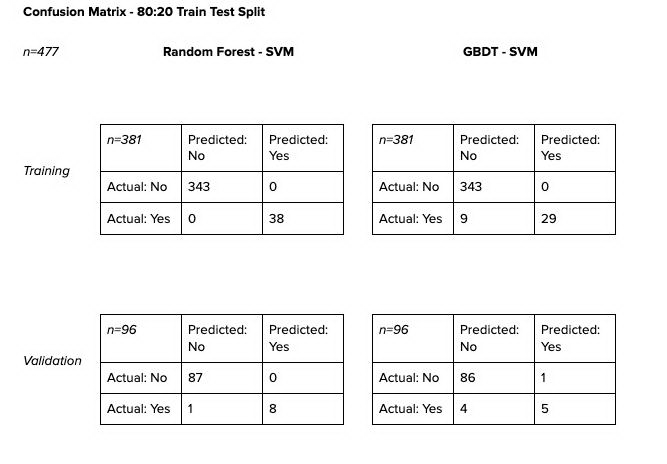
上面的表格是厂商数据在“二八开”时的训练和验证得分。由于阳性标签的数量非常少,所以拆分时对数据进行了分层。
以下是模型与整个数据集拟合后的混淆矩阵,供参考。
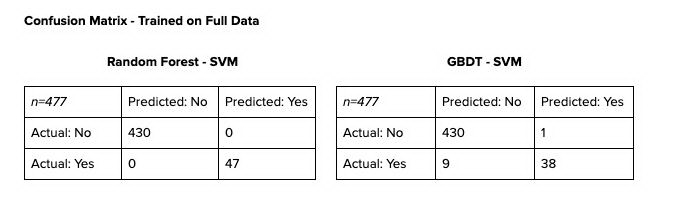
混淆矩阵显示了有希望的结果。但是,对于如此小的样本,我们在评估结果时必须非常谨慎。尽管随机森林 - 支持向量机在同类产品中的表现明显优于梯度提升型决策树 - 支持向量机,但我们不能很快地完全否定梯度提升决策树 - 支持向量机。
以下是验证分数及其 95% 的置信区间。虽然在每个统计量的点估值之间存在显著差异,但是实际上,两个模型之间的置信区间有相当大的重叠。将模型应用到实际生产中,所得到的输入越多,置信区间越窄,点估计就越更准确。
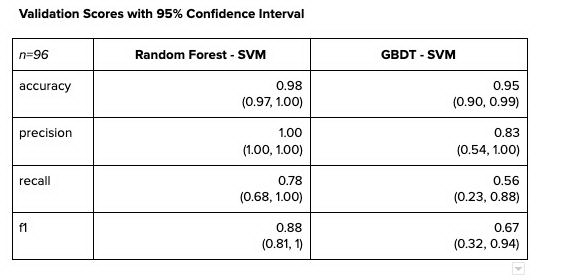
若要评估单模型架构和双模型架构的结果,最好的方法就是将交易级别的预测结果按厂商进行汇总。对于基准测试来说,如果某一供应商有一个积极的预测,那么我们假定该供应商是预测的代理。这个方法似乎有些极端,但实际上,如果我们只对交易进行预测,我们就将利用预测结果调查可疑的供应商。
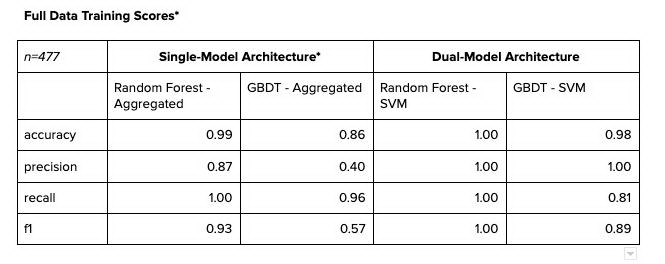
结论
在评估哪种模型最好的时候,我们将以上表 3 中所示的验证分数作为基准,根据这些分数做出判断。考虑到这些结果,我们部署了随机森林 - 支持向量机架构作为最终的架构,这不仅是因为它的性能,也因为它的训练和超参数调优的速度非常快。随机森林算法可以在几分钟内执行 RandomSearchCV,而梯度提升决策树需要超过 6 个小时的调优。当然,随机森林可能已经过拟合,但是,鉴于目前的数据规模,很难进行评估。然而,在获得新数据时,我们需要保持并重新调整模型,并相应地进行重新评估。在此过程中,根据模型预测,选取少数厂商,用更有力的证据来支持审计,并对当前问题进行量化。
借助这一项目,我们可以更加自信地为管理层提供全面的信息,回答诸如每个国家有多少代理、交易数量、所付现金总额、过去三年的演变情况,以及使用情况等问题。这样,我们就可以了解到管理层之前没有意识到的问题,同事也为我们提供了关于如何让合适的领导者参与解决业务风险方面的重要洞察力。本文提出的方法还可用于其他审计,值得进一步研究。
作者介绍:
Jesse He,数据科学家,Uber 内部审计公司数据科学团队的创始成员。在 Uber,致力于推动内部审计的边界,热衷于学习和应用创造性的机器学习解决方案来解决就问题。在普渡大学获得了 MIS。会计和金融专业的学士学位,其间还学习了航空工程、航空航天管理,并获得了商业飞行员执照。
原文链接:




