
信息爆炸的时代,更需要我们拥有高效获得文档信息的能力。随着人工智能技术的快速发展,智能问答系统已逐渐成为提升这一能力的重要手段之一。2022 年以来,以 GPT-3 模型为代表的大规模语言模型能力的不断提升,为智能文档问答带来了新的机遇,前不久 GPT-4 模型的震撼发布更是再次颠覆人们的认知。
GPT 爆火后,人们往往聚焦于其巨大的模型和令人惊叹的自然语言生成能力,而少有人谈到如此具体的技术解析。
近日,亚马逊云科技联合 Jina AI 举办 Tech Talk 主题活动。Jina AI 联合创始人兼 CTO 王楠从论文到工程实践,深度分析了如何将 GPT 模型更加高效地运用于智能文档问答系统的方法。
现代文档问答系统的发展史
文档问答系统是指从大规模文档数据中查找到与用户问题相关答案的一套完整的系统。系统会接收文本输入的问题 Q,并在给定文档集合 D 的情况下,自动提取信息并生成对应的答案 A。文档问答系统和一般的问答系统是有明显区别的。问答系统通常是多轮对话系统,而文档问答系统更像是多轮对话的一个子问题,只考虑当前问题,并根据这个问题给定的文档集合进行回答。
问答系统的研究自上个世纪 60 年代就已经开始了,而直到 2017 年后,深度学习方法才逐渐成为问答系统的技术核心。2017 年斯坦福团队率先提出全新的基于深度学习的问答系统 DrQA。DrQA 被普遍认为是第一个在问答系统里使用深度学习模型的算法,它开辟了一个问答系统的新范式,被称为两阶段方法。
两阶段方法
两阶段方法将问答过程分为两个阶段。第一个阶段称为召回阶段,系统会根据用户的提问从文本库或知识库中检索相关的文本片段或知识点,利用传统的检索技术去召回可能的文档候选。第二个阶段称之为阅读理解阶段,会利用深度学习的机器阅读理解模型,从对应的候选文档里将答案抽取出来。
两个阶段分别用到不同的技术。在召回阶段,原始的论文里使用的是基于 TF-IDF 的方式去进行召回。TF-IDF 会评估问题的关键词,并通过静态计算的方式评估每一个 Term 的重要度,然后,根据每篇被召回的文档的 TF-IDF 得分进行排序,选取得分最高的前 K 篇文章,将其输入到第二阶段的机器阅读理解模型中。在论文中,一开始使用了 RNN 模型,思路是将问题转化为序列标注问题,即对于给定文档中出现的每个词,判断其是否应该出现在答案中,以及它在答案中是开头、中间还是结尾。
两阶段方法的优点在于准确率相对较高、效率高、不容易出错。但缺点也较为明显,因为它使用了传统的召回技术,一些语义近似的文档虽然与原文意思相近,但未完全出现在原文中,无法通过此方法召回。
端到端方法
在两阶段方法的基础上,端到端方法进行了召回阶段的提升。从模型上看,端到端方法依旧是分为召回和阅读理解两个阶段,区别在于,它使用了向量检索的方式来替代传统的检索技术用于召回。用向量去召回是指将所有文档通过一个映射函数映射到一个空间中,这个空间可以是二维的。同样地,当用户提出一个问题时,可以将这个问题映射到同样的二维空间中。在这个二维空间中,可以找到与问题语义相似的文档,因此可以将这些文档召回作为答案的候选项。与传统的关键词匹配不同,这种方式可以通过语义相似性来匹配文档,从而提高召回率。
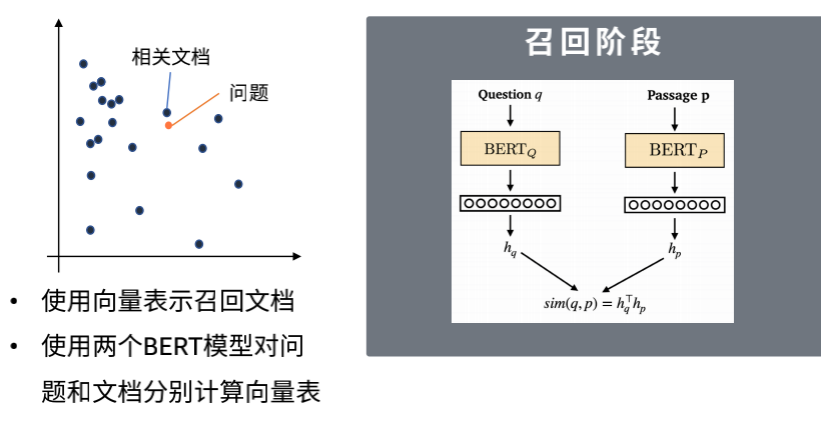
上图是召回阶段常用的模型。在召回阶段,我们通常使用的模型是 Meta AI 推出的 DPR 模型。该模型的实现方法是使用两个不同的 BERT 模型分别处理答案和文章,并计算它们对应的向量表示。在训练过程中,目标是尽可能地使相关的问题和答案在向量空间中处于相同的位置,而不相关的答案和文章则应该在向量空间中处于不同的位置。在向量空间中,我们通常使用余弦相似度来衡量相似性。使用这样的模型进行召回的优点不仅在于它可以扩大召回的范围,而且它还可以通过专门的模型针对具体的文档进行训练,从而提高召回的效果。因此,整个召回阶段成为一个可训练的过程。在阅读理解的部分,采取的仍然是抽取式的方式,把整个问题转换成一个序列标注的问题。只不过 BERT 模型的出现替代了 RNN 模型在该任务上的应用。
端到端方法还有一个改进的版本——RocketQA,其创新点在于 RocketQA 通过将答案和问题拼接在一起传递给第三个 BERT 模型,再计算相似度,来提高准确率。这种方法可以确保在提高召回率的情况下,准确率也能得到较好的效果,但最大的问题是需要针对语料进行微调,如果不进行微调,整个系统的效果并不理想。另外,和前面说的两阶段方法一样,在阅读理解的部分使用的是一个抽取式的模型,只能返回文章中已经有的答案,而不能去生成答案。这就导致如果问题是一般疑问句,它没办法直接回答是或者否。此外,这个模型也没有一个很好的拒绝回答问题的机制。
无召回方法
为了回答一般疑问句和解决拒绝回答的问题,第三类方法应运而生,即无召回的方法。这类方法的代表是 GPT 模型,它通过训练大规模的语言模型来记忆知识,不需要外部的存储机制来存储索引。GPT 模型的关键在于它可以生成答案,因此它可以回答一般疑问句和拒绝回答问题。GPT 模型使用了 Transformer 模型的 Decoder 部分来生成答案,它不会局限于输出输入中出现过的内容,这使得它的答案更加灵活。但是,由于 GPT 模型需要生成完整的答案,因此需要更大的模型。
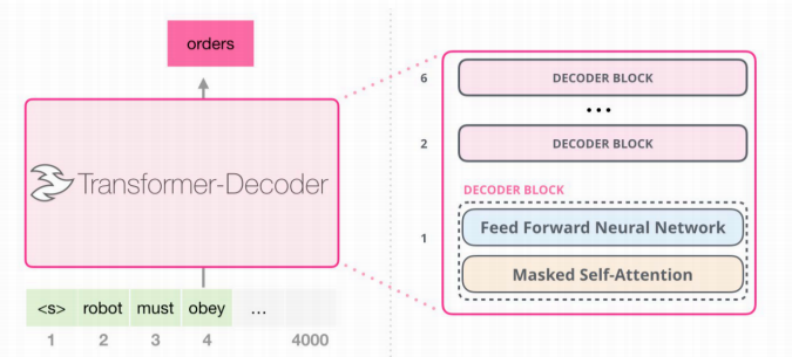
GPT 模型有多大呢?GPT-1 是 2018 年发布的,有 1.17 亿个参数,与 BERT 模型的参数大小差不多。而 GPT-3 具有 1750 亿个参数和 96 层 Transformer。GPT-4 的参数量没有公开披露,但据估计是 GPT-3 的大约 600 倍。
当模型变得更大时,通常需要更多地训练数据。在 GPT 发布之前,迁移学习的范式主要以像 BERT 这样的模型为代表。这种方法是先预训练一个模型,然后根据不同的下游任务设计不同的模型结构和目标函数,再进行微调。GPT 模型的思路非常新颖,它放弃了微调的方式。它假设所有任务的输入都是相同的,不管是什么任务,都可以使用同一个模型结构。这种方法的好处在于,一旦模型训练好了,我们就可以直接用它来处理各种各样的任务,而不需要进行微调。此外,这种方法还可以共享各种各样的任务语料,从而有效地扩展可用的语料范围。另外,无召回的方法采用 Reinforcement learning with human feedback(RLHF)和 Ru base reward model(RBRM)技术 ,很好的实现了拒绝回答问题,确保所生成的结果是有效且合理的。
简而言之,无召回方法的优势是非常明显的,唯一的不足是无召回方法中,基于 GPT 的方法存在 token 长度限制,输入长度不能过长,长度过长会增加开销。

从论文到实践,文档问答系统的挑战与技术实现
理论方法即便已足够完善,但在转化为具体实践的过程中仍会面临很大的挑战。Jina AI 作为一家开源软件公司,和其他开源公司面临着同样的困境。首先,使用端到端方法对每个模型进行微调会导致运营成本非常高,如果不进行微调,则准确率会相对较低。其次,使用 GPT 模型直接处理问题既开销高,又受到长度的限制。此外,大部分文档都已经有一个问答库,如何将其融入已有的系统中也是一大问题。
基于上述挑战,Jina AI 从算法设计和工程实践的角度提出了一系列解决方案。在算法方面,Jina AI 将前面提到的三种方法进行融合。具体来说,当问题输入后,首先使用意图识别来判断用户是否真的在询问问题。接着,分为两条路径解答问题:一条是针对问答库的,将用户的问题与问答库中的问题进行匹配;另一种则是采用传统的问答系统方法。
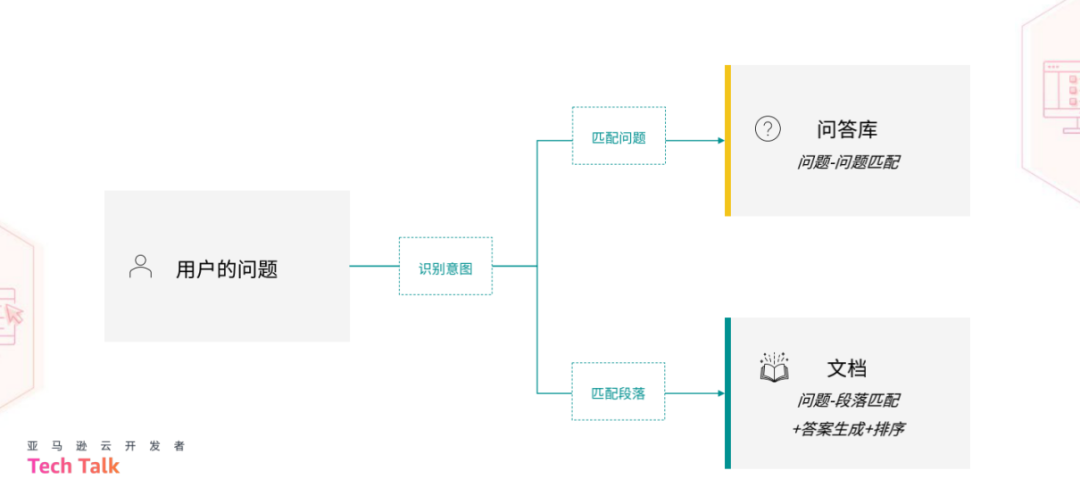
第一条路径本质上是一种问题匹配的方法,其出发点是用户的问题,通过在问答库中匹配与用户问题相对应的问题。DocsQA 使用了 Sentence Transformer 提供的 paraphrase-mpnet-base-v2 模型。将问答库中的所有问题转换为向量,同样地,用户的问题也被转换为向量,然后在向量空间中寻找相似的问题。如果找到了匹配的问题,则将相应的答案返回给用户。这条路径的最大优点是准确率非常高,缺点在于严重依赖于问答库。因此,这条路径非常适合处理高频出现的重复性问题。
第二条路径的本质是在整个文档中查找答案,然后使用 GPT-3 模型生成答案。这里有两种具体的实现方式。第一种是关键词检索,使用 TF-IDF 方法召回包含可能答案的候选文档。它的优点是准确率很高,但召回率可能有所不足。第二种是将问题和答案转换成向量,然后在语义空间中进行召回。这种方法使用了 Meta AI 提供的 DPR 模型,主要解决召回率不足的问题。这两种方式都不需要微调模型,避免了过高的成本。此外,Jina AI 还提供了一个名为 PromptPerfect 的自研工具,它可以优化 Prompt 背后的思路,获得更好的答案效果。
欢迎试用:promptperfect.jina.ai
由于 Jina AI 是一家开源软件公司,且问答系统并非主要业务,因此 Jina AI 的目标是尽可能快地上线整个项目,同时要以尽可能低的成本来维护。然而,DocsQA 的算法使用了三种不同的方式,并依赖于多个 AI 模型,而这些模型的使用频率并不高,如何保证系统的运行成本控制在一个合理的范围内呢?
基于 Amazon 服务的 DocsQA 工程方案
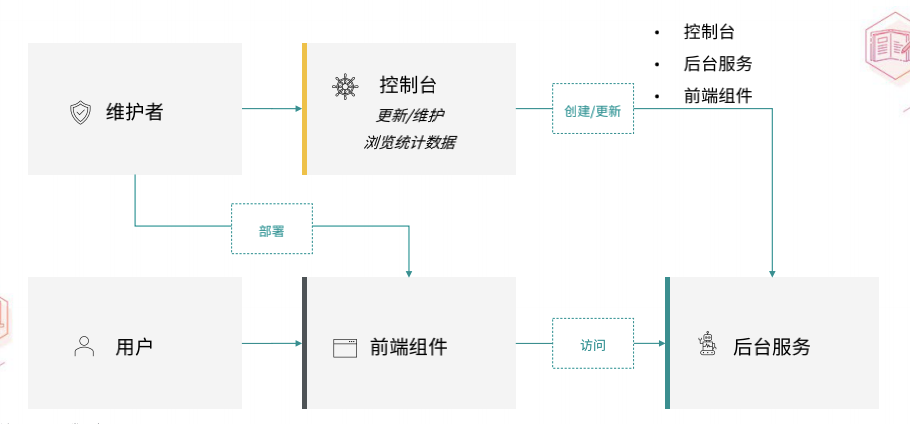
DocsQA 的系统架构分为三部分。第一部分是控制台,用于 DocsQA 的配置和更新,开发者可以在控制台上创建和更新问答系统。第二部分是前端组件,是一个交互式的前端插件,用于访问对应的后台服务,第三部分是后台服务,Jina AI 使用自己的 Jina 框架来搭建后台服务。
基于 Amazon API Gateway 的控制后台设计
控制台的功能相对简单。它允许用户创建自己的问答服务并填写一些基本信息。此外,我们提供了一个简单的监控后台,可以提供当前的统计数据。控制台的技术栈 Jina AI 采用了亚马逊云科技的 Serverless 框架,具体使用了 Amazon API Gateway 和 Amazon Lambda 来实现。由于创建、维护和更新整个文档问答系统的动作是非常低频的,因此 DocsQA 不需要一直在线的服务。通过 Amazon API Gateway,可以轻松地实现这一点。当开发者发起请求到达 Amazon API Gateway 时,Amazon API Gateway 会调用相应的 Lambda 函数。实际上,Amazon API Gateway 和 Lambda 函数之间的映射关系是通过 Serverless 原生的 API Gateway Event 来实现的。同时,DocsQA 还使用了 Lambda Proxy Integration 来完成整个 Serverless 构建。
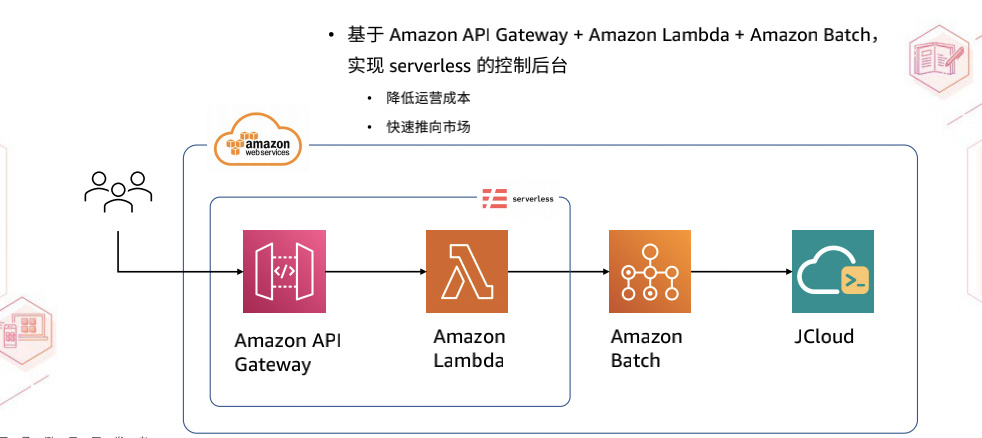
此外,由于创建索引需要耗费较长时间,不能让用户请求一直等待,以免超时。因此,可以在 Lambda 函数中触发相应的批处理作业,使用 Amazon Batch 模块。该模块会在云端启动一个容器,容器会完成相应的任务,任务完成后,容器会自动销毁。DocsQA 执行的任务是将用户要索引的文档拉取下来,然后将其以请求的形式发送到 JCloud 中。
这种方式不仅可以节省整个系统的运营成本,而且 Serverless 加上 Amazon API Gateway 和 Amazon Lambda 是一套非常快速的开发框架。这大大缩短了产品上市的时间,使产品能够快速推向市场。
在后台服务方面,当控制台收到用户的请求时,会触发后台服务。DocsQA 的后台服务是基于 Jina 框架搭建的,它是一套云原生的 MLOps 框架,旨在帮助开发者更高效、快速地开发各种多模态的应用。Jina 的核心是 Flow 的概念,即一个多模态的应用,由各种 Executor 构成。Executor 是 Flow 中的一个小模块,专门完成特定的任务。Flow 将这些 Executor 串联起来,构建了一个完整的系统。Jina 解决了网络传输、分布式部署等复杂性,能够帮助开发者更快地进行开发。
GitHub:github.com/jina-ai/jina
在 DocsQA 文档问答系统中,建立了两个 Flow,一个用于索引数据。当收到用户请求时,就会创建这样一个 Flow。另一个用于查询,其任务相对简单,即把刚才建立的 TF-IDF、问答,还有向量的索引都加载起来,同时把需要的深度学习模型也加载起来对外提供服务。值得一提的是,考虑到降低成本的需求,Jina 不同的问答服务可以共享同一个模型,这大大提高了模型的使用效率。
使用 Amazon Batch 实现低成本快速部署服务
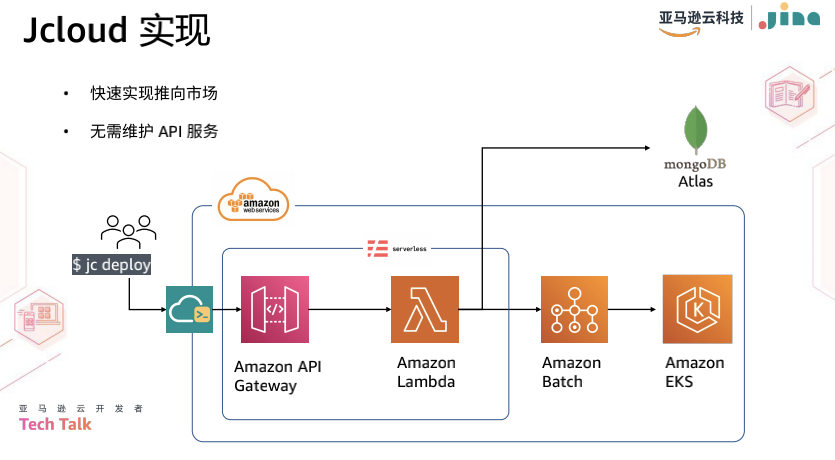
最后是真正的部署。JCloud 背后实际上是以 Kubernetes 的形式进行部署的。每个 Executor 都被封装成一个 Kubernetes Deployment,这样我们就可以保证每个 Executor 可以根据实际流量的情况单独进行缩放。此外,不同的 Deployment 可以放在同一个 node 上面,以节约成本。
JCloud 的实现逻辑如下图所示。JCloud 是一个 Python 包,安装后开发者可以直接使用 "JCloud deploy" 命令来运行对应的 Flow。该命令将向 API 发送一个请求。API 依然使用的是 Serverless 的方式,和控制台构建的方式类似,同样使用 Amazon API Gateway 和 Lambda Function 进行构建。一些比较重的任务会直接交给 batch job 处理,而轻的任务,如查询已部署的服务,则由 Lambda Function 自己处理。最后,服务将部署在 Amazon EKS 上。
DocsQA 系统的第三个组成部分是前端组件。它是一个前端的 UI 库,Jina AI 开源了所有的代码,王楠表示,感兴趣的话大家可以进行二次开发,也可以直接应用在工作中。
Jina AI Cloud:cloud.jina.ai
在分享的最后王楠总结,搭建文档问答系统的算法解决方案已经非常成熟,没有太多创新。然而,在工程实践中,需要考虑如何实现更好的线上效果,以解决问题。因此,可以将不同的算法进行融合。此外,在上线时,DocsQA 大量使用了 Amazon API Gateway、Amazon Lambda 以及 Amazon Batch,结合 Serverless 框架,使系统能够快速上线,以最低的成本运营,并减少推向市场的时间。
相关链接:
Tech Talk 完整视频:戳这里
亚马逊云开发者官网:https://dev.amazoncloud.cn/#
Jina 官网:https://jina.ai/
Jina Github:oss.jina.ai
全球社区:jina.ai/community/




