
Uber 将所有支付交易数据从 DynamoDB 和 Blob 存储 迁移到一个新的长期解决方案中,一个名为 LedgerStore 的专用数据存储。该公司正在寻找节省成本的方法,并在之前减少了 DynamoDB 的使用,只用它存储热数据(12 周内的数据)。此举大大节省了成本,并简化了存储架构。
Uber 于 2017 年构建了支付平台 Gulfstream,并使用 DynamoDB 进行存储。由于存储成本不断攀升,所以他们只用 DynamoDB 存储最近的数据(12 周),而把比较旧的数据存储在 TerraBlob 中,这是 Uber 内部创建的一种类似 S3 的服务。
与此同时,该公司开始研究一种专用的解决方案,用于存储需要数据完整性保证的金融交易。Uber 技术主管 Kaushik Devarajaiah 解释了创建定制数据存储的特有挑战:
LedgerStore 是 Uber 的一个不可变存储解决方案,提供可验证的数据完整性和正确性保证,可以确保交易的数据完整性。[…] 在 Uber,分类账是任何财务事件或数据移动的真相来源,因此,能够在各种访问模式中通过索引查找分类账至关重要,而索引数千亿的分类账记录需要数万亿的索引。
LedgerStore 支持强最终一致性索引。对于强一致性索引,该数据存储使用了两阶段提交。它首先在索引上保存索引意图(intent),然后保存记录。最后,如果记录写入成功,则异步提交意图或在失败的情况下回滚意图。如果意图写入失败,则整个插入操作就会失败,因为未实现一致性保证。在读取期间,任何意图未提交的写操作要么被异步提交(如果读取记录成功),要么被异步删除(如果读取记录失败)。LedgerStore 利用本地 Docstore 数据库(一个基于 MySQL 构建的分布式数据库)的物化视图来实现最终一致性索引。
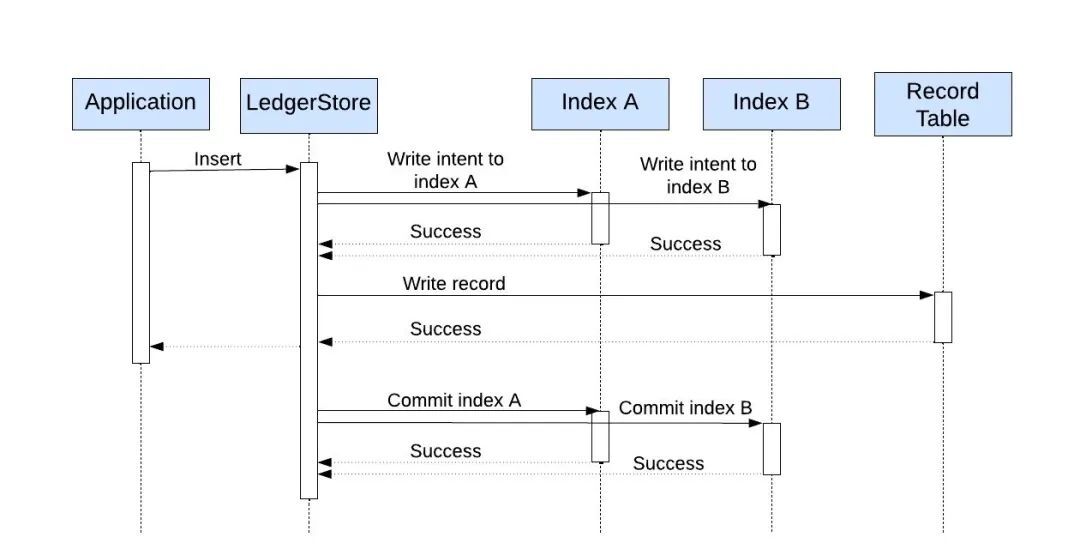
两段提交写入实现强一致性索引(图片来源:Uber 工程博客)
为了将旧的分类帐数据卸载到冷存储,LedgerStore 使用时间范围索引来支持时间查询。Uber 已不再使用 DynamoDB 和 Docstore 来存储时间范围索引。他们最初的解决方案使用了两个 DynamoDB 表,一个做了写优化,另一个做了读优化。这种设计是由 DynamoDB 的容量管理决定的,可以避免热分区和节流。新设计使用了 Docstore 数据库单表,并利用前缀扫描进行高效读取。
LedgerStore 支持索引生命周期管理,在索引定义更改时可以自动重新索引数据。该过程会创建一个新索引,回填旧索引中的数据,执行相关验证,切换索引,并删除旧索引。
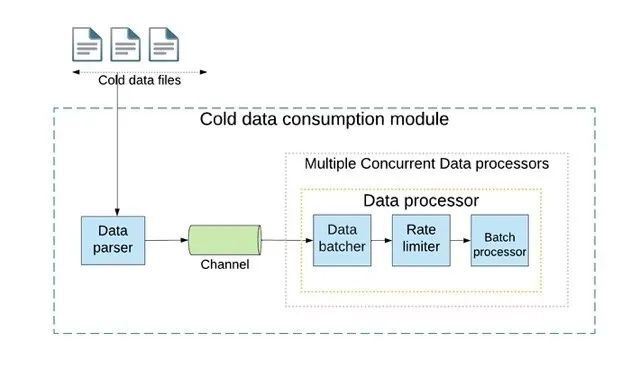
从冷存储回填索引(图片来源:Uber 工程博客)
在将 PB 级的金融交易数据迁移到 LedgerStore 时,该公司面遇到了一些特有的挑战。它使用影子和离线验证来确保迁移的正确性以及 LedgerStore 在生产环境中的性能和可扩展性。对于影子验证,Gulfstorm 将数据双重写入 DynamoDB 和 LedgerStore,并读取两个数据存储的数据进行比较。
此外,Uber 还实现了历史数据的离线验证,并在 Apache Spark 中运行增量回填作业。单是回填过程就遇到了非常严重的问题,因为该过程产生的负荷是平常生产负荷的十倍,整个过程需要三个月的时间。工程师们采取了多种措施来控制这个过程并缓解出现的任何问题,其中包括动态速率控制(根据平台处理的生产流量调整处理速率)以及紧急停止(在发生重大问题时快速停止这个过程)。
最后,团队在上线新解决方案时采取了比较保守的方法,实现了从 DynamoDB 获取数据的后备方案,以防在 LedgerStore 中找不到数据。整个迁移成功完成,并且在迁移期间和之后,公司没有经历任何停机或中断。迁移到 LedgerStore 为 Uber 节省了大量的成本,估计每年节省超过 600 万美元。
原文链接:
https://www.infoq.com/news/2024/05/uber-dynamodb-ledgerstore/




