
我们的前一篇文章探讨了最小可行架构(Minimum Viable Architecture,MVA)的概念。本文将通过一个聊天机器人与传统保险系统(如保单管理系统)和企业外部数据源(重建成本、房屋估价数据)交互的虚构示例,探讨如何应用 MVA 概念,并回答房主可能针对他们的保单和保障范围提出的问题。为了便于说明问题,我们将集中讨论与住宅重置成本有关的问题。
使用 MVA 方法实现一个聊天机器人
我们之所以选择了聊天机器人作为示例,是因为它有一个简单的用户界面,把与数据完整性、并发性、延迟和响应性相关的复杂问题隐藏掉了。聊天机器人是一种软件服务,它可以通过文本或文本到语音的方式提供在线聊天对话,从而替代真人。
它很适合被用在许多软件系统中,如保险公司使用的家庭保险系统。受火灾等自然灾害的影响,保险公司和保险公司的家庭保险专家经常会接到大量来自客户的电话和咨询电子邮件。受自然灾害影响的房主希望他们的问题能得到及时回答,但因为电话数量太多,中介不能及时回答房主的紧急问题。在正常时期,房主通常会有一些简单但不紧急的问题,他们想问这些问题,但又不想麻烦中介。聊天机器人可以提供更及时的信息,从而提高客户满意度,同时让代理腾出时间处理更复杂的任务。
初始 MVA:一个简单的基于菜单的聊天机器人
创建 MVA 的第一步是选择聊天机器人的工作方式,这足以实现最小可行产品(MVP)。在我们的例子中,MVP 仅具备能够实现我们为其设定的产品目标的最小功能。如果没有人想使用它,或者它不能满足客户的需求,我们就不会继续开发它。因此,我们打算向有限的用户群发布 MVP,采用了简单的基于菜单的界面,并假设因访问外部数据源收集数据可能产生的延迟是客户可以接受的。我们希望避免超出我们试图要解决的问题的需求——包括功能性需求和质量属性需求(QAR)。这将产生如下所示的初始设计。如果我们的 MVP 被证明是有价值的,我们将增加它的功能,并在随后的步骤中逐步构建它的架构。MVP 是产品开发战略的一个有用的组成部分,与原型不同,MVP 最终不会被“扔掉”。
我们可以用可重用的开源框架(如RASA)来实现一系列客户服务聊天机器人,从简单的基于菜单的机器人到使用自然语言理解(Natural Language Understanding,NLU)的高级机器人。借助这个框架,最初的 MVA 设计实现了基于菜单的单用途聊天机器人,它能够处理简单的咨询业务。这个简单的聊天机器人在智能手机、平板电脑、笔记本电脑或台式电脑上向用户提供一个简单的选择列表。其结构如下图所示:
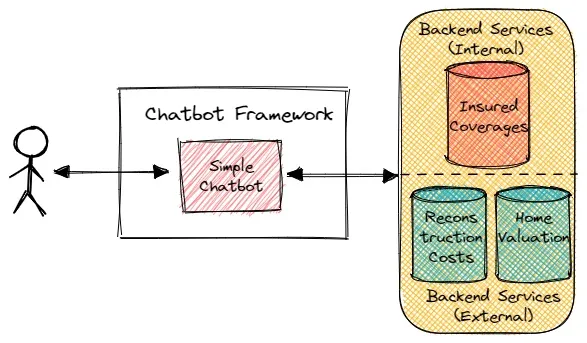
聊天机器人与以下这些后台服务发生交互:
投保范围:这项服务是保险公司的内部服务,提供了 API 访问,预计存在低至中等的延迟。
重建成本:这项服务在保险公司外部,提供了 API 访问,延迟是未知的。
房屋评估:这项服务也在保险公司外部,也提供了 API 访问,延迟也是未知的。
正如我们在前一篇文章中所描述的,在开始 MVA 时,我们针对解决方案做出了一系列基本的选择,并使用一个简单的检查清单来确保我们做出了合适的架构决策。我们的清单包括以下这些项:
安全性——我们需要考虑 MVP 的安全性需求。用户需要授权才能访问聊天机器人检索的信息,因此,聊天机器人应该捕获用户凭据并将这些凭据传递给后端服务进行验证。
监控——我们相信,每一个应用程序都应该提供基本的监控功能,用于监控性能并收集在初次发布期间可能遇到的潜在系统问题。
平台——我们已经决定 MVP 将托管在商业云平台上。
用户界面——我们认为,一个简单的基于菜单的界面对于 MVP 来说已经足够了,但可能需要根据最初用户的反馈进行调整。MVP UI 适用于智能手机、平板电脑、笔记本电脑和台式电脑。
延迟和响应性——虽然我们不担心延迟和响应性,因为 MVP 的部署面向的是一个小用户群,但如果 MVP 获得成功,我们需要扩大它的用户基础。届时,延迟和响应性可能成为潜在的问题。延迟指标将作为基本监控功能的一部分。
以下内容并不是目前应该关注的问题,但随着用户群和使用量大幅增长,以后可能需要关注。
并发性——目前不需要考虑,我们假设用户群不会变得太大。
吞吐量——目前不需要考虑,因为目前需要处理的数据量非常小。
可伸缩性——目前不需要考虑,但如果聊天机器人的用户基数显著扩大,这可能会成为一个问题。
持久性——目前不需要考虑,因为聊天机器人需要存储的数据很少。
你可以将这个清单视为你的应用程序的一个合理的入手点,当然,你可能需要根据你遇到的技术问题调整或扩展它。
在 MVP 交付之后,用户似乎对产品的性能相对满意,但他们表示,基于菜单的界面太过局限。即使是 MVP 中使用的简单菜单也相当繁琐,增加菜单选项只会让用户体验进一步恶化,特别是在智能手机和平板电脑上。他们希望能够使用自然语言与聊天机器人进行更自然的交谈。
实现自然语言接口
MVP 使用的开源聊天机器人框架也支持自然语言理解,因此,我们将继续使用它来为聊天机器人添加 NLU,将简单的聊天机器人变成机器学习(ML)应用程序。
切换成 NLU 接口会改变聊天机器人的架构,如下图所示。训练数据的离线数据摄取和数据准备是两个非常重要的步骤,此外,还需要模型部署和模型性能监控。对语言识别准确性以及吞吐量和延迟的监控尤为重要。商业用户会使用一些“行业术语”,随着时间的推移,聊天机器人会更好地理解这些术语。
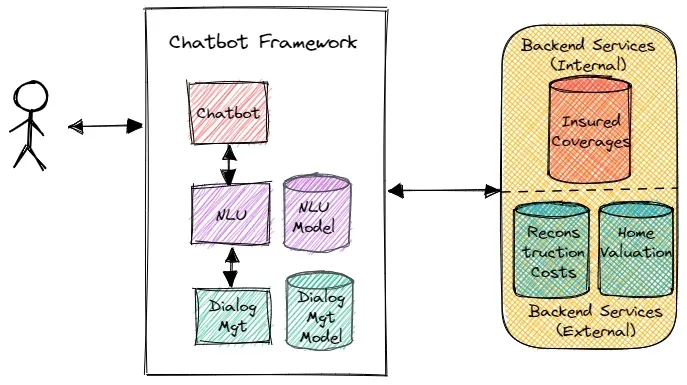
新架构包含了两个模型,它们需要在沙盒环境中进行训练,并部署到一组 IT 生成环境中。这两个模型可以看作是与用户提问有关的 NLU 模型,以及与聊天机器人的回答有关的对话管理模型。更具体地说,聊天机器人使用 NLU 模型来理解用户想要做什么,并使用管理模型来构建对话,让聊天机器人能够顺畅地回应问题。模型和它们所使用的数据都应该放在版本控制系统中。
处理后端服务的延迟
重建成本和房屋估价数据最初是由其他组织存储和维护的,保险公司可控的只有投保信息是。即使在使用量较低的情况下,当聊天机器人从两个外部数据服务收集必要的数据时,用户也可能会感受到延迟。我们应该在使用最初基于菜单的 UI 时对客户可接受延迟的假设进行测试。
如果因访问外部服务导致的延迟不受欢迎,就必须调整架构,在本地(或至少与投保数据位于相同的位置)缓存外部服务数据,并定期更新缓存数据。假设房屋估价和重建成本在短时间内不会发生太大变化,那么缓存这些数据似乎是一种合理的权衡。然而,我们也需要对这种假设进行测试,将延迟影响客户体验的成本与维护缓存一致性的成本进行对比,确定是否值得花费时间和精力在缓存上。此外,我们还应该经常复查 MVA 检查清单,确保在这个过程开始时所做的假设仍然有效,并且在 MVP 演变成为成熟产品的过程中,架构仍然是令人满意的。
结论
乍一看,聊天机器人似乎并不需要太多的架构考量,因为提供了大部分构建模块的框架比比皆是,开发应用程序似乎只需要训练一些 NLU 模型和集成一些现成的组件。但是,任何经历过构建聊天机器人的人都知道,正确使用聊天机器人应用程序并不容易,试错成本会极大地影响客户满意度。即使是像聊天机器人这样简单的应用程序也需要 MVP 和 MVA。
对于更复杂的应用,MVA 需要解决的问题将取决于 MVP 的目标。MVP 是从客户的角度来测试产品是否值得开发,而 MVA 则通常考虑的是向客户交付解决方案在技术和经济方面是否可行,并在其预期寿命内为解决方案提供支持。MVA 还必须超越 MVP,至少需要提供 MVP 成功之后解决问题的方案,以免成功的 MVP 导致组织无法承受长期的产品维持。
作者简介:
Kurt Bittner 拥有超过 30 年短周期交付软件的经验。他帮助过许多采用敏捷软件交付实践的组织,包括大型银行、保险、制造和零售企业,以及大型政府机构。他曾为大型软件交付企业工作,包括甲骨文、惠普、IBM 和微软,并曾是 Forrester Research 公司的技术行业分析师。他的重点领域是帮助组织建立强大、自组织、高性能的团队,为客户交付受欢迎的解决方案。他撰写了 4 本与软件开发相关的书,包括“The Nexus Framework for Scaling Scrum”。他现居科罗拉多州博尔德市,并担任 Scrum.org 的企业解决方案副总裁。
Pierre Pureur 是一位经验丰富的软件架构师,拥有丰富的创新和应用程序开发背景、广泛的金融服务行业经验、广泛的咨询经验和全面的技术基础设施知识。他曾担任一家大型金融服务公司的首席企业架构师,领导大型架构团队,管理大型并发应用程序开发项目,指导创新计划,以及制定战略和业务计划。他是“Continuous Architecture in Practice: Scalable Software Architecture in the Age of Agility and DevOps”(2021 出版)和“Continuous Architecture: Sustainable Architecture in an Agile and Cloud-Centric World”(2015 出版)的合著者,并发表了许多文章,以及在多个软件架构会议上发表相关演讲。
原文链接:
Minimum Viable Architecture in Practice: Creating a Home Insurance Chatbot




