
三年前,Reddit 的基础设施工程师团队大部分时间都在忙于救火。本文谈的就是他们如何通过开发一个平台抽象来简化运维并重新掌控局面的故事。
Reddit 于 2022 年 3 月 13 日瘫痪的事件是一个粗暴的警示,提醒这家公司需要以新的方式管理它的基础设施。
臭名昭著的“Pi Day”全站中断事件持续了刚好 314 分钟。事件源于从 Kubernetes 1.23 到 1.24 的集群范围升级操作,该升级导致了一些微妙的不可预测行为,迫使基础设施团队进行回滚,这本身就是一项高风险行动。
即使在那时,公司工程师也知道运维方式需要改变了。
这个广受欢迎的社交新闻论坛彼时正在扩展其服务器堆栈,使服务器跨多个可用区以提高可靠性,最终目标是在全球范围内提供服务。其他一些围绕广告投放和机器学习的项目也面临着各自的挑战。此外,公司高管正在为 IPO 做准备。
Reddit 基础设施团队的高级软件工程师 Karan Thukral 那时指出,该公司需要一个新的平台抽象。随着公司的发展,他们需要新的平台抽象来继续高效运维。
Thukral 与 Reddit 软件工程师 Harvey Xia 在最近的 KubeCon+CloudNativeCon 北美会议上发表了演讲,介绍了他们的基础设施团队如何创建新的平台抽象,从而提前做好计划,摆脱被动的救火模式。
“从技术上讲,我们做到了用更少的人手来解决更具挑战性的问题,”Thukral 说。“由于我们在过去几年中投入了大量资源,我们得以有更多的专门工程时间来主动解决问题,而不是被动地救火。”
神秘的命名空间
2022 年,该公司运行着 20 个 Kubernetes 驱动的生产集群。基础设施团队有 92 名工程师,比公司部署的 706 名应用工程师少得多。他们的大部分工作都是帮助应用工程师。
一个问题是命名空间的创建。在 Reddit 中,每个在 Kubernetes 上运行的应用程序都需要一个命名空间,可以通过 Helm 图表或 Kustomize 清单指定。应用程序开发人员并不是编写这些规范的专家。
这导致了大量剪切和粘贴操作。结果错误悄然而至,而审阅者并不总能发现这些错误。这块的审查流程为应用审查过程增加了额外的 24 小时。
Thukral 说,由于时区差异,可能需要将近一周的时间才能获得命名空间。而且,糟糕的配置设置仍然渗透到了整个持续集成流程中,这可能会导致停机故障。
Reddit 对命名空间的管理并不一致。 Thukral 表示:“我们无法推断命名空间的来源,无法推断它是否正在使用。”因此公司制定了一条不销毁任何命名空间的规则,因为工程师无法判断命名空间是否仍在某个地方使用。
并且所有过时的命名空间(随着公司将其单体应用程序迁移到微服务中,这样的命名空间很多)仍然占用着 Kubernetes 资源。
手工集群和受困扰的基础设施
与此同时,基础设施团队也面临着自己的挑战,Xia 说道。
工程师需要 30 多个小时才能启动一个集群,其中包括 100 多个步骤,诸如配置网络、配置硬件或选择云供应商、安装控制平面以及添加可观察性和自动扩展工具等等。
此外,正如 Pi Day 所警示的那样,集群的就地升级是不稳定的,而且根本没有退役集群的流程。仍在运行的集群的配置逐渐偏移,越来越特别,还没有文档记录这些变化。
Xia 说,退役一个集群相当于“进行成本高昂的考古搜索,以找到必须退役的所有基础设施”。
“这是一个自我强化的低效率循环”——Reddit 的 Harvey Xia
那时,该组织没有很好的方法来管理整个集群。 Xia 表示,有时,基础设施会偏离指定配置太远,以至于被称为“闹鬼”。
“任何工程师都很难自信地推断出集群应该如何运行,或者正在如何运行,这使得所有生命周期操作都极其危险。”Xia 说道。
因此,基础设施团队的时间主要用来保持一切内容的运行和修复中断。
Xia 表示,这种“被动、救火的心态”使得“想象、规划或构建更可持续的未来”变得非常困难。
Reddit 选择 K8s 控制器而不是 IaC 的原因
一个抽象会将用户的关注点与底层实现分开来,从而隐藏复杂性。根据 Xia 的定义,平台是开发人员可以在其基础上构建的可组合工具生态系统。它以公司开发人员的最佳实践为依据。
Reddit 决定通过一组由 Kubernetes 控制流程支持的声明性 API 来实现一个平台。它的接口被定义为自定义资源。期望的状态是规范,观察到的状态通过当前状态来报告。
自定义资源会启动 Kubernetes 控制器,后者将活动状态转变为期望状态来实现其 API。
工程师最初考虑使用基础设施即代码工具,但后来改用基于 Kubernetes 控制器的工具。
使用标准 IaC 很难表示任意业务逻辑,这是构建 Reddit 基础设施的主要要求。
“我无法建模我要的工作流,在工作流中我需要从证书颁发机构提供 TLS 证书,将其卸载到 Amazon 证书管理器,并将其附加到负载均衡器上,”Xia 说。标准 IaC 平台也不是动态的。你不能依赖 IaC 来续订过期的证书。

相比之下,Kubernetes 控制器将确保当前状态始终处于所需状态下,或至少一直朝着所需的状态移动。这将包括所有生命周期操作。
大脑和负载集群
如今,Reddit 基础设施工程师花在集群管理上的时间更少了。他们有一组 API,可以通过“单一管理平台”管理多个集群。
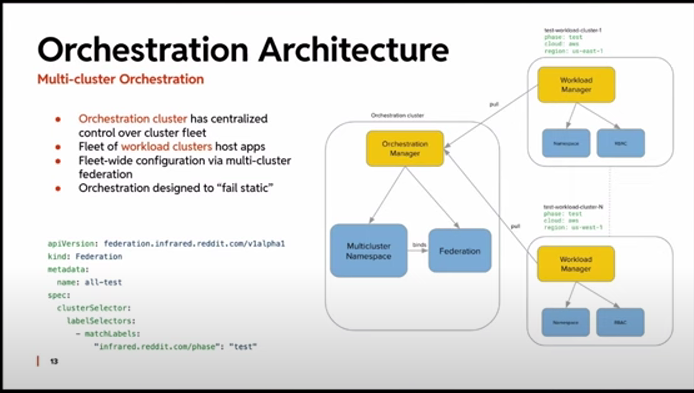
该公司有两种类型的集群。一种是控制集群,可以被认为是运维的大脑。它为其他易于替换的“负载”集群生成配置。
“我们开始将这些集群视为牛,而不是宠物,”Thukral 说。
这样,集群有了明确定义的属性,所有适用的配置更新都会自动流入该集群。可以执行多集群运维操作。
每个负载集群都有自己的自定义资源,并带有属性标签,例如其运维阶段(测试、生产或准备)、地理位置和支持的云供应商。这为多集群 API 控制奠定了基础。一个联合控制器通过 K8s 标签选择器管理集群。
集群定位是动态的。如果启动了新的测试集群,它会自动加入测试命名空间。
“这为我们的工程师节省了大量时间,”Xia 说。
这种方法有一些潜在的缺点。首先,编排集群是单点故障。但系统的设计使得 worker 集群即使无法更新也能继续运行和自我修复。限制可以启动的集群类型也会限制可以构建的集群种类,从而使它们整体上更易管理。
FluxCD 用于将源配置与集群同步。Crossplane 用于将 Kubernetes API 桥接到云供应商资源。Cluster API 提供用于管理 Kubernetes 控制平面的 API。
这些资源或基础原语都由 Reddit 自己的自定义资源来中介,允许公司在需要时交换各种实现。
命名空间的创建也为开发人员带来了便利。现在,Reddit 应用程序开发人员无需学习 Helm 或 Kustomize,只需创建一个名为 Reddit 命名空间的自定义资源,并将其定位到一组集群即可。对于用户来说,基于角色的访问控制(RBAC)简化为两个选项:operator 或 reader 状态。
没有致命弱点
为了帮助基础设施工程师更轻松地创建控制器和 operator,Reddit 构建了 Achilles SDK,它建立在 Kubernetes 控制器运行时之上。
Thukral 表示,该 SDK 将整个协调循环表示为一个有限状态机。目前,这由单个函数处理,这可能会变得相当笨重。Thukral 表示,使用 Achilles 构建集群所需的步骤比在 Terraform 下组装相同集群所需的少得多。
Achilles 自动跟踪所有子资源和状态条件。
“我们希望让我们的基础设施工程师能够专注于构建业务逻辑,而不必成为 Kubernetes 专家,”Thukral 说。
结果
Reddit 仍在构建新的基础设施,不过该公司已经看到了很多成果,工程师们引以为傲。
该平台的可扩展性更强了:不再需要为命名空间的编写和管理而头疼。安全性和应用程序栈的简单性也得到了提升。
建立新集群的周转时间现在约为两个小时。升级可以在一小时内完成。多亏了 Achilles,可以在不到两周的时间内创建和测试控制器,“这对我们来说是一个巨大的成功,”Thukral 说。
该公司今年年初在生产中部署了 4 个 Kubernetes 控制器,截至 KubeCon,该公司已拥有 12 个。这些控制器管理基础设施的各个方面,包括 Kubernetes Ingress 栈、AWS 网络、Redis、Cassandra、HashiCorp Vault 和 Kubernetes 本身。
“对平台抽象的投资已获得了回报,”Xia 说。“自助服务界面已经取代了我们以前大部分的白手套流程。我们许多繁重的内部工作流程已被自动化所取代。”
在本次演讲中,Xia 还提供了有关何时自动化工作流程的一些提示。第一步:一切都必须是可编程的。
他说,该平台让工程师们能够专注于那些“我们希望投入主要时间解决的重大问题”。
演讲视频:https://youtu.be/ruto5Sak-jI
原文链接:https://thenewstack.io/reddit-no-longer-haunted-by-drifting-kubernetes-configurations/




