C++ AMP、CUDA 和 OpenCL,选择哪个?
在《遇见C++ AMP:在GPU 上做并行计算》发布之后,我曾被多次问及为何选择C++ AMP,以及它与 CUDA 、 OpenCL 等相比有何优势,看来有必要在进入正题之前就这个问题发表一下看法了。
在众多可以影响决策的因素之中,平台种类的支持和 GPU 种类的支持是两个非常重要的因素,它们联合起来足以直接否决某些选择。如果我们把这两个因素看作两个维度,可以把平面分成四个象限,C++ AMP、CUDA 和 OpenCL 分别位于第二象限、第四象限和第一象限,如图 1 所示。如果你想通吃所有平台和所有 GPU,OpenCL 是目前唯一的选择,当然,你也需要为此承担相当的复杂性。CUDA 是一个有趣的选择,紧贴最新的硬件技术、数量可观的行业应用和类库支持使之成为一个无法忽视的选择,但是,它只能用于NVIDIA 的GPU 极大地限制了它在商业应用上的采用,我想你不会为了运行我的应用特意把显卡换成NVIDIA 的。C++ AMP 的情况刚好相反,它适用于各种支持DirectX 11 的GPU,但只能在Windows 上运行。
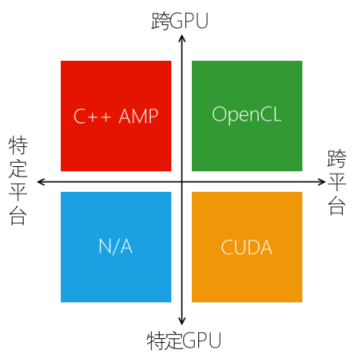
图 1
这些技术都有自己的特点和位置,你应该根据项目的具体情况选择合适的解决方案。如果你正在从事的工作需要进行大量计算,你想尽可能利用硬件特性对算法进行优化,而你的机器刚好有一块NVIDIA 的显卡,并且你不需要在其他机器上重复执行这些计算,那么CUDA 将是你的不二之选。尽管 NVIDIA 已经开源 CUDA 编译器,并且欢迎其他厂商通过 CUDA 编译器 SDK 添加新的语言 / 处理器,但 AMD 不太可能会为它提供在 AMD 的 GPU 上运行的扩展,毕竟它也有自己的基于 OpenCL 的 AMD APP 技术。如果你正在从事 Windows 应用程序的开发工作,熟悉 C++ 和 Visual Studio,并且希望借助 GPU 进一步提升应用程序的性能,那么 C++ AMP 将是你的不二之选。尽管微软已经开放C++ AMP 规范, Intel 的 Dillon Sharlet 也通过 Shevlin Park 项目验证了在 Clang/LLVM 上使用 OpenCL 实现 C++ AMP 是可行的,但这不是一个产品级别的商用编译器,Intel 也没有宣布任何发布计划。如果你确实需要同时兼容 Windows、Mac OS X 和 Linux 等多个操作系统,并且需要同时支持 NVIDIA 和 AMD 的 GPU,那么 OpenCL 将是你的不二之选。
GPU 线程的执行
在《遇见C++ AMP:在GPU 上做并行计算》里,我们通过extent 对象告诉parallel_for_each 函数创建多少个GPU 线程,那么,这些GPU 线程又是如何组织、分配和执行的呢?
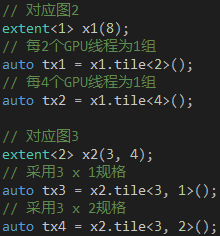
首先,我们创建的GPU 线程会被分组,分组的规格并不固定,但必须满足两个条件:对应的维度必须能被整除,分组的大小不能超过1024。假设我们的GPU 线程是一维的,共8 个,如图2 所示,则可以选择每2 个GPU 线程为1 组或者每4 个GPU 线程为1 组,但不能选择每3 个GPU 线程为1 组,因为剩下的2 个GPU 线程不足1 组。
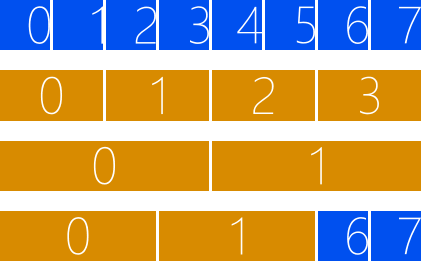
图 2
假设我们创建的GPU 线程是二维的,3 x 4,共12 个,如图3 所示,则可以选择3 x 1 或者3 x 2 作为分组的规格,但不能选择2 x 2 作为分组的规格,因为剩下的4 个GPU 线程虽然满足分组的大小,但不满足分组的形状。每个分组必须完全相同,包括大小和形状。
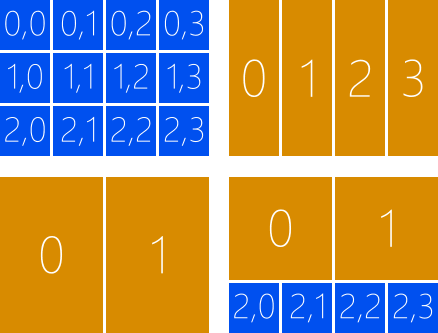
图 3
为了便于解释,我们的GPU 线程只有寥寥数个,但真实案例的GPU 线程往往是几十万甚至几百万个,这个时候,分组的规格会有大量选择,我们必须仔细判断它们是否满足条件。假设我们的GPU 线程是640 x 480,那么16 x 48、32 x 16 和32 x 32 都可以选择,它们分别产生40 x 10、20 x 30 和20 x 15 个分组,但32 x 48 不能选择,因为它的大小已经超过1024 了。
接着,这些分组会被分配到GPU 的流多处理器(streaming multiprocessor),每个流多处理器根据资源的使用情况可能分得一组或多组GPU 线程。在执行的过程中,同一组的GPU 线程可以同步,不同组的GPU 线程无法同步。你可能会觉得这种有限同步的做法会极大地限制GPU 的作为,但正因为组与组之间是相互独立的,GPU 才能随意决定这些分组的执行顺序。这有什么好处呢?假设低端的GPU 每次只能同时执行2 个分组,那么执行8 个分组需要4 个执行周期,假设高端的GPU 每次可以同时执行4 个分组,执行8 个分组只需2 个执行周期,如图4 所示,这意味着我们写出来的程序具备可伸缩性,能够自动适应GPU 的计算资源。
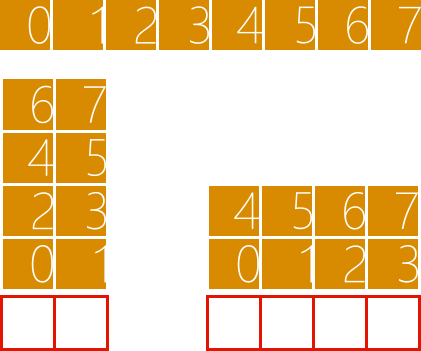
图 4
说了这么多,是时候看看代码了。parallel_for_each 函数有两种模式,一种是简单模式,我们通过extent 对象告诉它创建多少GPU 线程,C++ AMP 负责对GPU 线程进行分组,另一种是分组模式,我们通过 tiled_extent 对象告诉它创建多少 GPU 线程以及如何进行分组。创建 tiled_extent 对象非常简单,只需在现有的 extent 对象上调用 tile 方法,并告知分组的规格就行了,如代码 1 所示。值得提醒的是,分组的规格是通过模板参数告诉 tile 方法的,这意味着分组的规格必须在编译时确定下来,C++ AMP 目前无法做到运行时动态分组。
代码 1
既然 C++ AMP 不支持运行时动态分组,肯定会为简单模式预先定义一些分组的规格,那么 C++ AMP 又是如何确保它们能被整除?假设我们创建的 GPU 线程是一维的,共 10000 个,C++ AMP 会选择每 256 个 GPU 线程为 1 组,把前面 9984 个 GPU 线程分成 39 个分组,然后补充 240 个 GPU 线程和剩下的 16 个 GPU 线程凑够 1 组,执行的时候会通过边界测试确保只有前 10000 个 GPU 线程执行我们的代码。对于二维和三维的情况,C++ AMP 也会采取这种补充 GPU 线程的策略,只是分组的规格不同,必要时还会重新排列 GPU 线程,以便分组能够顺利完成。需要说明的是,简单模式背后采取的策略属于实现细节,在这里提及是为了满足部分读者的好奇心,你的算法不该对它有所依赖。
共享内存的访问
既然简单模式可以自动分组,为何还要大费周章使用分组模式?为了回答这个问题,我们先要了解一下 GPU 的内存模型。在 Kernel 里,我们可以访问全局内存、共享内存和寄存器,如图 5 所示。当我们通过 array_view 对象把数据从主机内存复制到显卡内存时,这些数据会被保存在全局内存,直到应用程序退出,所有 GPU 线程都能访问全局内存,不过访问速度很慢,大概需要 1000 个 GPU时钟周期,大量的GPU 线程反复执行这种高延迟的操作将会导致GPU 计算资源的闲置,从而降低整体的计算性能。

图 5
为了避免反复从全局内存访问相同的数据,我们可以把这些数据缓存到寄存器或者共享内存,因为它们集成在GPU 芯片里,所以访问速度很快。当我们在Kernel 里声明一个基本类型的变量时,它的数据会被保存在寄存器,直到GPU 线程执行完毕,每个GPU 线程只能访问自己的寄存器,寄存器的容量非常小,不过访问速度非常快,只需1 个GPU 时钟周期。当我们在Kernel 里通过 tile_static 关键字声明一个变量时,它的数据会被保存在共享内存(也叫 tile_static 内存),直到分组里的所有 GPU 线程都执行完毕,同一组的 GPU 线程都能访问相同的共享内存,共享内存的容量很小,不过访问速度很快,大概需要 10 个 GPU 时钟周期。tile_static 关键字只能在分组模式里使用,因此,如果我们想使用共享内存,就必须使用分组模式。
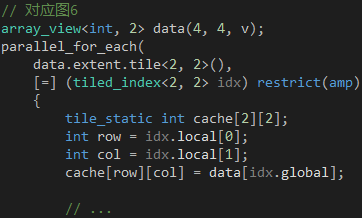
如果数据只在单个 GPU 线程里反复使用,可以考虑把数据缓存到寄存器。如果数据会在多个 GPU 线程里反复使用,可以考虑把数据缓存到共享内存。共享内存的缓存策略是对全局内存的数据进行分组,然后把这些分组从全局内存复制到共享内存。假设我们需要缓存 4 x 4 的数据,可以选择 2 x 2 作为分组的规格把数据分成 4 组,如图 6 所示。以右上角的分组为例,我们需要 4 个 GPU 线程分别把这 4 个数据从全局内存复制到共享内存。复制的过程涉及两种不同的索引,一种是相对于所有数据的全局索引,用于从全局内存访问数据,另一种是相对于单个分组的本地索引,用于从共享内存访问数据,比如说,全局索引 (1, 2) 对应本地索引 (1, 0)。
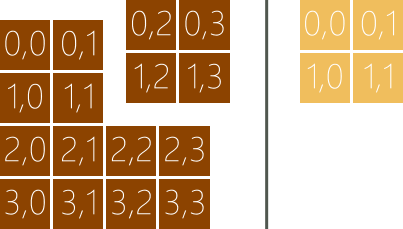
图 6
在分组模式里,我们可以通过 tiled_index 对象访问索引信息,它的 global 属性返回全局索引,local 属性返回本地索引,tile 属性返回分组索引,它是分组作为一个整体相对于其他分组的索引,tile_origin 属性返回分组原点的全局索引,它是分组里的 (0, 0) 位置上的元素的全局索引。还是以右上角的分组为例,(1, 2) 位置的 global 属性的值是 (1, 2),local 属性的值是 (1, 0),tile 属性的值是 (0, 1),tile_origin 属性的值是 (0, 2)。tiled_index 对象将会通过 Lambda 的参数传给我们,我们将会在 Kernel 里通过它的属性访问全局内存和共享内存。
说了这么多,是时候看看代码了。正如 extent 对象搭配 index 对象用于简单模式,tiled_extent 对象搭配 tiled_index 对象用于分组模式,使用的时候,两者的模板参数必须完全匹配,如代码 2 所示。parallel_for_each 函数将会创建 16 个 GPU 线程,每 4 个 GPU 线程为 1 组,同一组的 GPU 线程共享一个 2 x 2 的数组变量,每个元素由一个 GPU 线程负责复制,每个 GPU 线程通过 tiled_index 对象的 global 属性获知从全局内存的哪个位置读取数据,通过 local 属性获知向共享内存的哪个位置写入数据。
代码 2
因为缓存的数据会在多个 GPU 线程里使用,所以每个 GPU 线程必须等待其他 GPU 线程缓存完毕才能继续执行后面的代码,否则,一些 GPU 线程还没开始缓存数据,另一些 GPU 线程就开始使用数据了,这样计算出来的结果肯定是错的。为了避免这种情况的发生,我们需要在代码 2 后面加上一句 idx.barrier.wait(); ,加上之后的效果就像设了一道闸门,如图 7 所示,它把整个代码分成两个阶段,第一阶段缓存数据,第二阶段计算结果,缓存完毕的 GPU 线程会在闸门前面等待,当所有 GPU 线程都缓存完毕时,就会打开闸门让它们进入第二阶段。
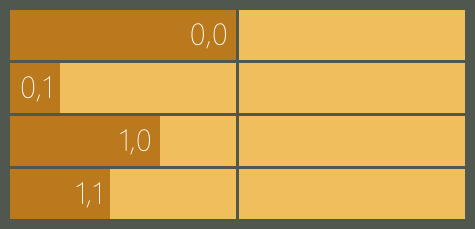
图 7
总的来说,使用分组模式是为了借助共享内存减少全局内存的访问,缓存的过程已经包含了一次全局内存的访问,因此,如果我们的算法只需访问全局内存一次,比如《遇见C++ AMP:在GPU 上做并行计算》的“并行计算矩阵之和”,那么缓存数据不会带来任何改善,反而增加了代码的复杂性。
并行计算矩阵之积
矩阵的乘法需要反复访问相同的元素,非常适合用来演示分组模式。接下来,我们将会分别使用简单模式和分组模式实现矩阵的乘法,然后通过对比了解这两种实现的区别。
设矩阵
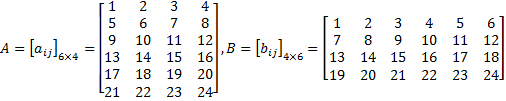
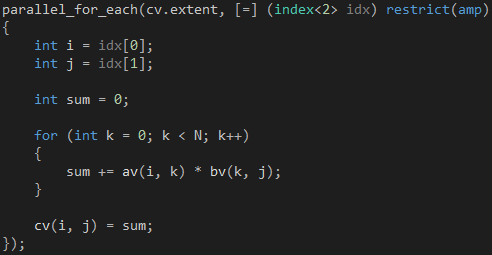
求AB。设C = AB,根据定义,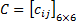 ,其中
,其中
 , 。你可以把这个公式想象成矩阵A 的第i 行和矩阵B 的第j 列两个数组对应位置的元素相乘,然后相加。
, 。你可以把这个公式想象成矩阵A 的第i 行和矩阵B 的第j 列两个数组对应位置的元素相乘,然后相加。
如何把这些数学描述翻译成代码呢?第一步,定义A、B 和C 三个矩阵,如代码3 所示, iota 函数可以在指定的起止位置之间填充连续的数字,正好满足这里的需求。
代码 3
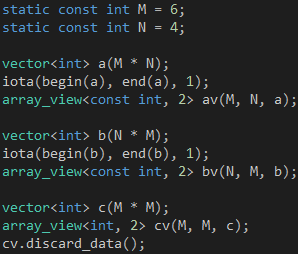
第二步,计算矩阵 C 的元素,如代码 4 所示,整个 Kernel 就是计算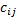 的求和公式, 因为每个元素的计算都是独立的,所以非常适合并行执行。
的求和公式, 因为每个元素的计算都是独立的,所以非常适合并行执行。
代码 4
在执行代码 4 的时候,parallel_for_each 函数将会创建 36 个 GPU 线程,每个 GPU 线程计算矩阵 C 的一个元素,因为这 36 个 GPU 线程会同时执行,所以计算矩阵 C 的时间就是计算一个元素的时间。这听起来已经很好,还能更好吗?仔细想想,计算需要访问矩阵 A 的第 i 行一次,那么,计算矩阵 C 的第 i 行将会访问矩阵 A 的第 i 行 M 次,M 是矩阵 C 的列数,在这里是 6;同理,计算矩阵 C 的第 j 列将会访问矩阵 B 的第 j 列 M 次,M 是矩阵 C 的行数,在这里也是 6。因为 A、B 和 C 三个矩阵的数据是保存在全局内存的,所以优化的关键就是减少全局内存的访问。
根据上一节的讨论,我们将会使用分组模式,并把需要反复访问的数据从全局内存缓存到共享内存,那么,使用分组模式会对性能带来多少改善,又对算法造成多少影响呢,这正是我们接下来需要探讨的。
第一步,选择 2 x 2 作为分块的规格对 A、B 两个矩阵进行分块处理
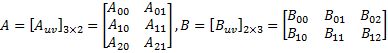
分块矩阵的乘法和普通矩阵的乘法是一样的,设 C = AB,根据定义,分块矩阵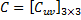 ,其中,
,其中,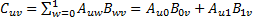
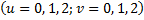 。
。
第二步,把parallel_for_each 函数改成分组模式,如代码5 所示。T 是子块的边长,W 是分块矩阵A 的列数,也是分块矩阵B 的行数。
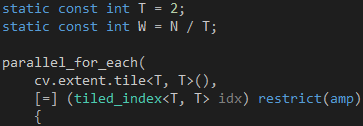
代码 5
第三步,分别缓存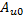 和
和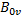 ,如代码6 所示。因为它们都是2 x 2 的矩阵,所以缓存它们的工作需要4 个GPU 线程协同完成。正确缓存的关键在于弄清每个GPU 线程负责全局内存和共享内存的哪些位置,共享内存的位置可以通过tiled_index 对象的local 属性获知,而全局内存的位置则需要换算一下,因为i 和j 是针对矩阵C 而不是矩阵A 和矩阵B 的。每个GPU 线程只是分别从矩阵A 和矩阵B 缓存一个元素,根据定义,从矩阵A 缓存的元素必定位于第i 行,而从矩阵B 缓存的元素必定位于第j 列。当我们缓存时,子块位于分块矩阵A 的左上角,tiled_index 对象的local 属性和global 属性指向相同的列,因此,目标元素位于矩阵A 的第h 列,当我们缓存
,如代码6 所示。因为它们都是2 x 2 的矩阵,所以缓存它们的工作需要4 个GPU 线程协同完成。正确缓存的关键在于弄清每个GPU 线程负责全局内存和共享内存的哪些位置,共享内存的位置可以通过tiled_index 对象的local 属性获知,而全局内存的位置则需要换算一下,因为i 和j 是针对矩阵C 而不是矩阵A 和矩阵B 的。每个GPU 线程只是分别从矩阵A 和矩阵B 缓存一个元素,根据定义,从矩阵A 缓存的元素必定位于第i 行,而从矩阵B 缓存的元素必定位于第j 列。当我们缓存时,子块位于分块矩阵A 的左上角,tiled_index 对象的local 属性和global 属性指向相同的列,因此,目标元素位于矩阵A 的第h 列,当我们缓存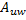 时,我们已经从左到右跨过了w 个子块,因此,目标元素位于矩阵A 的第h + w * T 列。同理,当我们缓存时,子块位于分块矩阵B 的左上角,目标元素位于矩阵B 的第g 行,当我们缓存
时,我们已经从左到右跨过了w 个子块,因此,目标元素位于矩阵A 的第h + w * T 列。同理,当我们缓存时,子块位于分块矩阵B 的左上角,目标元素位于矩阵B 的第g 行,当我们缓存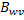 时,我们已经从上到下跨过了w 个子块,因此,目标元素位于矩阵B 的第g + w * T 行。4 个GPU 线程都缓存完毕就会进入第二阶段。
时,我们已经从上到下跨过了w 个子块,因此,目标元素位于矩阵B 的第g + w * T 行。4 个GPU 线程都缓存完毕就会进入第二阶段。
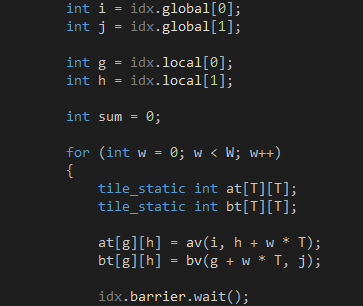
代码 6
第四步,计算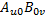 ,如代码7 所示。这是两个2 x 2 的普通矩阵相乘,需要4 个GPU 线程协同完成,每个GPU 线程计算结果矩阵的一个元素,然后加到变量sum 上。4 个GPU 线程都计算完毕就会重复第三、四步,缓存
,如代码7 所示。这是两个2 x 2 的普通矩阵相乘,需要4 个GPU 线程协同完成,每个GPU 线程计算结果矩阵的一个元素,然后加到变量sum 上。4 个GPU 线程都计算完毕就会重复第三、四步,缓存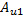 和
和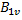 ,计算
,计算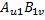 。如果还有其他子块,那么这个过程会一直重复下去。最终,每个GPU 线程汇总矩阵
。如果还有其他子块,那么这个过程会一直重复下去。最终,每个GPU 线程汇总矩阵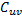 的一个元素。
的一个元素。
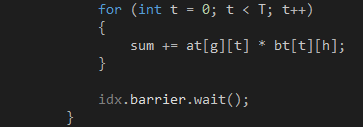
代码 7
最后一步,把汇总的结果保存到矩阵C,如代码8 所示。
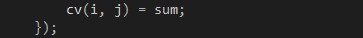
代码 8
至此,我相信你已经深刻地体会到分组模式的复杂性。CPU 拥有更强的控制部件和更大的缓存区域,可以预测和决定应该缓存哪些数据,而GPU 则把原本属于它们的空间留给更多的运算部件,把缓存的控制权交给程序员,这意味着缓存的逻辑将会渗透到业务的逻辑,从而增加了代码的复杂性。
那么,这样做是否值得?我们可以算一下,在代码4 里,av、bv 和cv 都是位于全局内存,每次访问都要1000 个GPU 时钟周期, 读取N 次av 和bv,写入一次cv,总共耗时2000 * N + 1000 个GPU 时钟周期,当N = 4 时,总共耗时9000 个GPU 时钟周期。在代码6、7、8 里,at 和bt 都是位于共享内存,每次访问只要10 个GPU 时钟周期,读取W 次av 和bv,写入W 次at 和bt,读取W * T 次at 和bt,写入一次cv,总共耗时 (2000 + 20 + 20 * T) * W + 1000,当N = 4,T = 2 时,W = 2,总共耗时5120 个GPU 时钟周期,约为简单模式的56.89%,性能的改善非常明显。如果我们增加矩阵和子块的大小,这个差距就会更加明显,令N = 1024,T = 16,则简单模式总共耗时2049000 个GPU 时钟周期,而分组模式总共耗时150760 个GPU 时钟周期,后者是前者的7.36%。
当然,这并不是简单模式和分组模式在性能上的精确差距,因为我们还没考虑访问寄存器和算术运算的耗时,但这些操作的耗时和访问全局内存的相比简直就是小巫见大巫,即使把它们考虑进去也不会对结果造成太大影响。
你可能会问的问题
1. 什么时候不能使用分组模式?
分组模式最高只能处理三维的数据结构,四维或者更高的数据结构必须使用简单模式,事实上,简单模式会把四维或者更高的数据结构换算成三维的。如果算法没有反复从全局内存访问相同的数据,那也不必使用分组模式。
2. 分组的限制有哪些?
分组的大小不能超过 1024,对应的维度必须能被整除,第一、二维度的大小不能超过 1024,第三维度的大小不能超过 64,分组的总数不能超过 65535。
3. 分组的大小越大越好吗?
不是的,我们使用分组模式主要是为了使用共享内存,一般情况下,分组的大小和它使用的共享内存成正比,每个流多处理器的共享内存是有限的,比如说, NVIDIA 的 GK110 GPU 的最大规格是 48K,每个流多处理器最多可以同时容纳 16 个分组,这意味着每个分组最多只能使用 3K,如果每个分组使用 4K,那么每个流多处理器最多只能同时容纳 12 个分组,这意味着流多处理器的计算能力没被最大限度使用。
4. 在设定分组的大小时需要考虑 Warp Size 吗?
在计算域允许的情况下尽可能考虑,NVIDIA 的 Warp Size 是 32,AMD 的 Wavefront Size 是 64,因此,分组的大小最好是64 的倍数。
感谢崔康对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




