
由于在训练过程中使用的数据集的多样性,我们可以为来自不同领域的文本获得足够的文本生成。GPT-2 的参数和数据是其前代 GPT 的 10 倍。而 GPT-3 又是 GPT-2 的 10 倍。那么问题来了,应该选择那个 Transformer 呢?
我应该选哪个 Transformer:GPT-2 还是 GPT-3
生成式预训练 Transformer(GPT)是 OpenAI 开发在自然语言处理(NLP)领域的创新之举。这些模型被认为是同类模型中最先进的,甚至在坏人手中也可能是很危险的。它是一种无监督的生成模型,也就是说,它接收句子等输入信息,并尝试生成一个适当的响应,而用于其训练的数据是不带标签的。
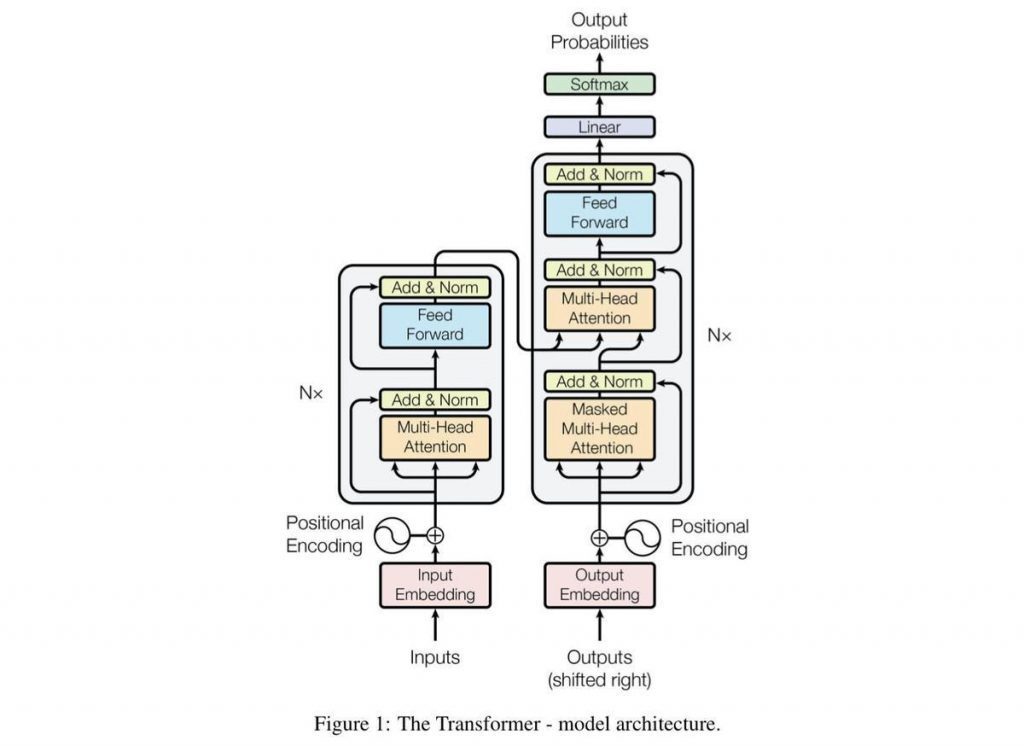
GPT-2 是什么?

GPT-2 是 OpenAI 在 2019 年 2 月创建的一种基于 Transformer 的无监督深度学习语言模型,其目的只有一个,就是预测句子中的下一个单词。GPT-2 是“Generative Pretrained Transformer 2”的缩写。该模型是开源的,在超过 15 亿个参数上进行训练,以便为给定句子生成下一个文本序列。
由于在训练过程中所用数据集的多样性,我们能够获取足够的来自不同领域的文本生成。而 GPT-2 的参数和数据是其前代 GPT 的 10 倍。
语言任务,如阅读、摘要和翻译,可以通过 GPT-2 学习原始文本,而不需要使用特定领域的训练数据。
自然语言处理的一些局限性
当处理自然语言生成时,必须考虑到某些局限性。它是一个非常活跃的研究领域,但它还处于起步阶段,还不能克服它的局限性。限制条件包括重复的文本,对技术性和专业性很强的主题的误解,以及对上下文短语的误解。
语言和语言学是一个复杂而庞大的领域,通常需要人们经过多年的训练和接触,不仅包括理解词语的含义,而且还包括上下文如何构成句子、如何给出答案以及使用恰当的俚语。它还可以为不同的领域创建自定义和可扩展的模型。OpenAI 提供的一个例子就是使用 Amazon Reviews 数据集来训练 GPT-2,并教授模型如何根据星级和类别等为条件编写评论。
GPT-3 是什么?

简而言之,GPT-3 就是“生成式预训练 Transformer”,它是 GPT-2 的第 3 个发行版,也是一个升级版。第 3 版将 GPT 模型提升到了一个全新的高度,因为它的训练参数达到了 1750 亿个(这是前代 GPT-2 的 10 倍以上)。
GPT-3 是在一个名为“Common Crawl”的开源数据集上进行训练的,还有来自 OpenAI 的其他文本,如维基百科(Wikipedia)条目。
GPT-3 的创建是为了比 GPT-2 更强大,因为它能够处理更多的特定主题。GPT-2 在接受音乐和讲故事等专业领域的任务时表现不佳,这是众所周知的。现在,GPT-3 可以更进一步地完成诸如答题、写论文、文本摘要、语言翻译和生成计算机代码等任务。它能够生成计算机代码,本身就已经是一个重大的壮举了。你可以在这里查看一些 GPT-3 的例子。
长期以来,很多程序员都在担心被人工智能所取代,而现在看来,这一担心正在成为现实。随着 Deepfake 视频的普及,由人工智能驱动的语音和文字也开始模仿人类。不久,当你打电话或在网上交流时(例如聊天应用),可能很难判断你是在和真人交谈还是与人工智能交谈。
GPT-3 可称为序列文本预测模型
虽然它仍然是一种语言预测模型,但更精确的描述可能是一种序列文本预测模型。GPT-3 的算法结构已被认为是同类模型中最先进的,因为它使用了大量的预训练数据。
GPT-3 通过语义学的方法理解语言的含义,并尝试输出一个有意义的句子给用户,从而在接受输入后生成句子。因为不使用标签化的数据,模型就不会知道什么是对的,什么是错的,这是一种无监督学习。
因为这些模型可以自动完成许多基于语言的任务,所以当用户使用聊天机器人与公司进行通信时,它们就变得越来越知名和流行。GPT-3 目前处于私有 beta 测试阶段,这意味着如果用户想要使用这个模型,他们必须登录到等待列表中。它作为通过云访问的 API 提供。现在看来,这些模型只适用于那些拥有 GPT 模型资源的个人 / 企业。
当我们给出 “I want to go output to play so I went to the____”的句子时,可以看到这种模式在发挥作用的一个例子。在这个例子中,一个好的响应可以是诸如 park 或 playground 之类的,而不是诸如 car wash 之类的。
因此,在提示文本的条件下,park 或 playground 的概率高于 car wash 的概率。当模型被训练时,它被输入数百万个样本文本选项,并将其转换为数字向量表示。这是一种数据压缩的形式,模型用它把文本转换成有效的句子。压缩和解压的过程可以提高模型计算词的条件概率的准确性。它开启了一个充满可能性的全新世界,但也有其局限性。
GPT-2 和 GPT-3 的一些局限性
尽管生成式预训练 Transformer 在人工智能竞赛中是一个伟大的里程碑,但是它没有能力处理复杂和冗长的语言形式。举例来说,如果你想像一个句子或一段包含文学、金融或医学等专业领域的词汇,如果事先没有进行足够的训练,模型就不能做出恰当的反应。
鉴于计算资源和功耗的巨大需求,在当前情况下,这并非一种可行的大众解决方案。数十亿的参数需要大量计算资源才能运行和训练。
那又是一个黑盒模式。在一个业务环境中,用户最需要的是理解下面的过程。目前 GPT-3 仍不能向公众开放,因为只有少数人可以独占。潜在的使用者必须登记他们的兴趣,并等待邀请,这样才能亲自测试模型。这么做是为了防止滥用如此强大的模型。一种可以复制人类语言模式的算法,对于整个社会来说有很多道德意义。
GPT-3 优于 GPT-2
由于 GPT-3 更强的性能和明显更多的参数,它包含了更多的主题文本,显然比它的前代要好。这一模型非常先进,即便存在局限性, OpenAI 仍然决定保持其安全性,并仅发布给提交推理使用这一模式的选定个人。最后,他们可能会考虑将其作为 API 发布,这样就可以控制请求,并最小化对模型的滥用。
另外需要注意的是:微软在 2020 年 9 月宣布了 GPT-3 的“独家”使用许可;其他人仍然可以使用公共 API 来接收输出,但只有微软自己拥有源代码的控制权。由于这个原因,EleutherAI一直在研究它自己的基于 Transformer 的语言模型,这种模型是根据 GPT 架构松散地设计的。他们的目标之一是使用自己的 GPT-Neo 来复制一个 GPT-3 规模的模型,并将其免费开源给公众。你可以在这里查看 GitHub repo 上的 GPT-Neo 进展。
人工智能在对语言生成领域造成致命一击之前,还有很长的路要走,因为这些模型还不能完善人类语言的细微差别。需要学习处理的任务的精确度和类型仍比当前的能力要高。但是,新的 GPT 模型的快速发展,使得下一个重大突破可能就在眼前。
作者介绍:
Kevin Vu,管理 Exxact Corp 博客,并与许多有才华的写手合作,他们都撰写深度学习的不同方面。
原文链接:
https://www.exxactcorp.com/blog/Deep-Learning/gpt2-vs-gpt3-the-openai-showdown




