计算机专家在问题求解时非常重视表达式简洁性的价值。Unix 的先驱者 Ken Thompson 曾经说过非常著名的一句话:“丢弃 1000 行代码的那一天是我最有成效的一天之一。”这对于任何一个需要持续支持和维护的软件项目来说,都是一个当之无愧的目标。早期的 Lisp 贡献者 Paul Graham 甚至将语言的简洁性等同为语言的能力。这种对能力的认识让可以编写紧凑、简介的代码成为许多现代软件项目选择语言的首要标准。
任何程序都可以通过重构,去除多余的代码或无用的占位符,如空格,变得更加简短,不过某些语言天生就善于表达,也就特别适合于简短程序的编写。认识到这一点之后,Perl 程序员普及了代码高尔夫竞赛;其目标是用尽可能短的代码量解决某一特定的问题或者实现某个指定的算法。APL 语言的设计理念是利用特殊的图形符号让程序员用很少量的代码就可以编写功能强大的程序。这类程序如果实现得当,可以很好地映射成标准的数学表达式。简洁的语言在快速创建小脚本时非常高效,特别是在目的不会被简洁所掩盖的简洁明确的问题域中。
相比于其他程序设计语言,Java 语言的冗长已经名声在外。其主要原因是由于程序开发社区中所形成的惯例,在完成任务时,很多情况下,要更大程度地考虑描述性和控制。例如,长期来看,长变量名会让大型代码库的可读性和可维护性更强。描述性的类名通常会映射为文件名,在向已有系统中增加新功能时,会显得很清晰。如果能够一直坚持下去,描述性名称可以极大简化用于表明应用中某一特定的功能的文本搜索。这些实践让Java 在大型复杂代码库的大规模实现中取得了极大的成功。
对于小型项目来说,简洁性则更受青睐,某些语言非常适于短脚本编写或者在命令提示符下的交互式探索编程。Java 作为通用性语言,则更适用于编写跨平台的工具。在这种情况下,“冗长Java”的使用并不一定能够带来额外的价值。虽然在变量命名等方面,代码风格可以改变,不过从历史情况来看,在一些基本的层面上,与其他语言相比,完成同样的任务,Java 语言仍需更多的字符。为了应对这些限制,Java 语言一直在不断地更新,以包含一些通常称为“语法糖”的功能。用这些习语可以实现更少的字符表示相同功能的目标。与其对应的更加冗长的配对物相比,这些习语更受程序开发社区的欢迎,通常会被社区作为通用用法快速地采用。
本文将着重介绍编写简洁Java 代码的最佳实践,特别是关于JDK8 中新增的功能。简而言之,Java 8 中 Lambda 表达式的引入让更加优雅的代码成为可能。这在用新的 Java Streaming API 处理集合时尤其明显。
冗长的 Java
Java 代码冗长之所以名声在外,一部分原因是由于其面向对象的实现风格。在许多语言中,只需要一行包含不超过 20 个字符的代码就可以实现经典的“Hello World”程序示例。而在 Java 中,除了需要类定义中所包含的 main 方法之外,在 main 方法中还需要包含一个方法调用,通过 System.out.println() 将字符串打印到终端。即使在使用最少的方法限定词、括号和分号,并且将所有空格全都删除的极限情况下,“Hello World”程序最少也需要 86 个字符。为了提高可读性,再加上空格和缩进,毋庸置疑,Java 版的“Hello World”程序给人的第一印象就是冗长。
Java 代码冗长一部分原因还应归咎于 Java 社区将描述性而非简洁性作为其标准。就这一点而言,选择与代码格式美学相关的不同标准是无关紧要的。此外,样板代码的方法和区段可以包含在整合到 API 中的方法中。无需牺牲准确性或清晰度,着眼于简洁性的程序代码重构可以大大简化冗余 Java 代码。
有些情况下,Java 代码冗长之所以名声在外是由于大量的老旧代码示例所带来的错觉。许多关于 Java 的书籍写于多年之前。由于在整个万维网最初兴起时,Java 便已经存在,许多 Java 的在线资源所提供的代码片段都源自于 Java 语言最早的版本。随着时间的推移,一些可见的问题和不足不断得到完善,Java 语言也日趋成熟,这也就导致即使十分准确并实施的当的案例,可能也未能有效利用后来的语言习语和 API。
Java 的设计目标包括面向对象、易于上手(在当时,这意味着使用 C++ 格式的语法),健壮、安全、可移植、多线程以及高性能。简洁并非其中之一。相比于用面向对象语法实现的任务,函数式语言所提供的替代方案要简洁的多。 Java 8 中新增的 Lambda 表达式改变了 Java 的表现形式,减少了执行许多通用任务所需的代码数量,为 Java 开启了函数式编程习语的大门。
函数式编程
函数式编程将函数作为程序开发人员的核心结构。开发人员可以以一种非常灵活的方式使用函数,例如将其作为参数传递。利用 Lambda 表达式的这种能力,Java 可以将函数作为方法的参数,或者将代码作为数据。Lambda 表达式可以看作是一个与任何特定的类都无关的匿名方法。这些理念有着非常丰富多彩并且引人入胜的数学基础。
函数式编程和 Lambda 表达式仍然是比较抽象、深奥的概念。对于开发人员来说,主要关注如何解决实际生产中的任务,对于跟踪最新的计算趋势可能并不感兴趣。随着 Lambda 表达式在 Java 中的引入,对于开发人员来说对这些新特性的了解至少需要能够达到可以读懂其他开发人员所编写代码的程度。这些新特性还能带来实际的好处——可以影响并发系统的设计,使其拥有更优的性能。而本文所关心的是如何利用这些机制编写简洁而又清晰的代码。
之所以能够用 Lambda 表达式生成简洁的代码,有如下几个原因。局部变量的使用量减少,因此声明和赋值的代码也随之减少。循环被方法调用所替代,从而将三行以上的代码缩减为一行。本来在嵌套循环和条件语句中的代码现在可以放置于一个单独的方法中。实现连贯接口,可以将方法以类似于Unix 管道的方式链接在一起。以函数式的风格编写代码的净效应并不只限于可读性。此类代码可以避免状态维护并且不会产生副作用。这种代码还能够产生易于并行化,提高处理效率的额外收益。
Lambda**** 表达式
与 Lambda 表达式相关的语法比较简单直白,不过又有别于 Java 之前版本的习语。一个 Lambda 表达式由三部分组成,参数列表、箭头和主体。参数列表可以包含也可以不包含括号。此外还新增了由双冒号组成的相关操作符,可以进一步缩减某些特定的 Lambda 表达式所需的代码量。这又称为方法引用。
线程创建
在这个示例中,将会创建并运行一个线程。Lambda 表达式出现在赋值操作符的右侧,指定了一个空的参数列表,以及当线程运行时写到标准输出的简单的消息输出。
Runnable r1 = () -> System.out.print("Hi!");
r1.run()
参数列表
箭头
主体
()
->
System.out.print(“Hi!”);
处理集合
Lambda 表达式的出现会被开发人员注意到的首要位置之一就是与集合 API 相关。假设我们需要将一个字符串列表根据长度排序。
java.util.List<String> l;
l= java.util.Arrays.asList(new String[]{"aaa", "b", "cccc", "DD"});
可以创建一个 Lambda 表达式实现此功能。
java.util.Collections.sort(l, (s1, s2) ->
new Integer(s1.length()).
compareTo(s2.length())
这个示例中包含两个传递给 Lambda 表达式体的参数,以比较这两个参数的长度。
参数列表
箭头
主体
(s1, s2)
->
new Integer(s1.length()).
compareTo(s2.length()));
除此之外还有许多替代方案,在无需使用标准的“for”或“while”循环的前提下,就可以操作列表中的各个元素。通过向集合的“forEach”方法传入 Lambda 表达式也可以完成用于比较的语义。这种情况下,只有一个参数传入,也就无需使用括号。
l.forEach(e -> System.out.println(e));
Argument List
Arrow
Body
e
->
System.out.println(e)
这个特殊的示例还可以通过使用方法引用将包含类和静态方法分开的方式进一步减少代码量。每个元素都会按顺序传入 println 方法。
l.forEach(System.out::println)
java.util.stream 是在 Java 8 中新引入的包,以函数式程序开发人员所熟悉的语法处理集合。在包的摘要中对包中的内容解释如下:“为流元素的函数式操作提供支持的类,如对集合的 map-reduce 转换。”
下方的类图提供了对该包的一个概览,着重介绍了接下来的示例中将要用到的功能。包结构中列示了大量的 Builder 类。这些类与连贯接口一样,可以将方法链接成为管道式的操作集。
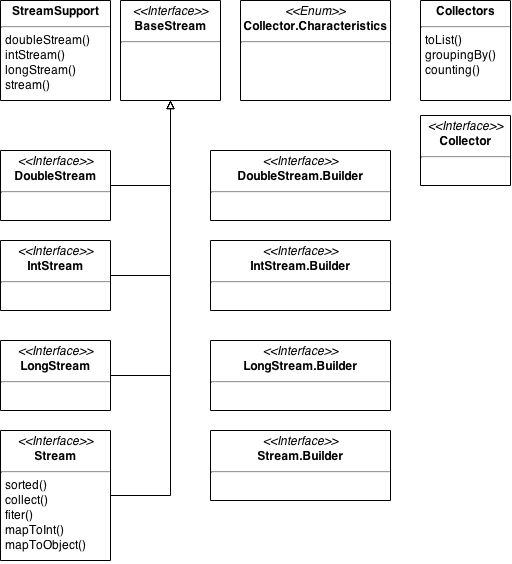
字符串解析和集合处理虽然简单,在真实世界中仍有许多实际应用场景。在进行自然语言处理(NLP)时,需要将句子分割为单独的词。生物信息学将DNA 和RNA 表示为有字母组成的碱基,如C,G,A,T 或U。在每个问题领域中,字符串对象会被分解,然后针对其各个组成部分进行操作、过滤、计数以及排序等操作。因此,尽管示例中所包含的用例十分简单,其理念仍适用于各类有实际意义的任务。
下方的示例代码解析了一个包含一个句子的字符串对象,并统计单词的数量和感兴趣的字母。包括空白行在内,整个代码清单的行数不超过70 行。
1. import java.util.*;
2.
3. import static java.util.Arrays.asList;
4. import static java.util.function.Function.identity;
5. import static java.util.stream.Collectors.*;
6.
7. public class Main {
8.
9. public static void p(String s) {
10. System.out.println(s.replaceAll("[\\]\\[]", ""));
11. }
12.
13. private static List<string> uniq(List<string> letters) {
14. return new ArrayList<string>(new HashSet<string>(letters));
15. }
16.
17. private static List<string> sort(List<string> letters) {
18. return letters.stream().sorted().collect(toList());
19. }
20.
21. private static <t> Map<string long=""> uniqueCount(List<string> letters) {
22. return letters.<string>stream().
23. collect(groupingBy(identity(), counting()));
24. }
25.
26. private static String getWordsLongerThan(int length, List<string> words) {
27. return String.join(" | ", words
28. .stream().filter(w -> w.length() > length)
29. .collect(toList())
30. );
31. }
32.
33. private static String getWordLengthsLongerThan(int length, List<string> words)
34. {
35. return String.join(" | ", words
36. .stream().filter(w -> w.length() > length)
37. .mapToInt(String::length)
38. .mapToObj(n -> String.format("%" + n + "s", n))
39. .collect(toList()));
40. }
41.
42. public static void main(String[] args) {
43.
44. String s = "The quick brown fox jumped over the lazy dog.";
45. String sentence = s.toLowerCase().replaceAll("[^a-z ]", "");
46.
47. List<string> words = asList(sentence.split(" "));
48. List<string> letters = asList(sentence.split(""));
49.
50. p("Sentence : " + sentence);
51. p("Words : " + words.size());
52. p("Letters : " + letters.size());
53.
54. p("\nLetters : " + letters);
55. p("Sorted : " + sort(letters));
56. p("Unique : " + uniq(letters));
57.
58. Map<string long=""> m = uniqueCount(letters);
59. p("\nCounts");
60.
61. p("letters");
62. p(m.keySet().toString().replace(",", ""));
63. p(m.values().toString().replace(",", ""));
64.
65. p("\nwords");
66. p(getWordsLongerThan(3, words));
67. p(getWordLengthsLongerThan(3, words));
68. }
69. }
</string>,></string></string></string></string></string></string></string>,></t></string></string></string></string></string></string>
示例程序执行输出:
Sentence : the quick brown fox jumped over the lazy dog
Words : 9
Letters : 44
Letters : t, h, e, , q, u, i, c, k, , b, r, o, w, n, , f, o, x, , j, u, m, p, e, d, , o, v, e, r, , t, h, e, , l, a, z, y, , d, o, g
Sorted : , , , , , , , , a, b, c, d, d, e, e, e, e, f, g, h, h, i, j, k, l, m, n, o, o, o, o, p, q, r, r, t, t, u, u, v, w, x, y, z
Unique : , a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, t, u, v, w, x, y, z
Counts
letters
a b c d e f g h i j k l m n o p q r t u v w x y z
8 1 1 1 2 4 1 1 2 1 1 1 1 1 1 4 1 1 2 2 2 1 1 1 1 1
words
quick | brown | jumped | over | lazy
5 | 5 | 6 | 4 | 4
上述代码已经经过了多重精简。其中一些方式并非在各个版本的 Java 中都可行,而且有些方式可能并不符合公认的编码风格指南。思考一下在较早版本的 Java 中如何才能够获得相同的输出?首先,需要创建许多局部变量用于临时存储数据或作为索引。其次,需要通过许多条件语句和循环告知 Java 如何处理数据。新的函数式编程方式更加专注于需要什么数据,而并不关心与其相关的临时变量、嵌套循环、索引管理或条件语句的处理。
在某些情况下,采用早期版本中的标准 Java 语法以减少代码量是以牺牲清晰度为代价的。例如,示例代码第一行的标准 import 语句中的 Java 包引用了 java.util 下的所有类,而不是根据类名分别引用。对 System.out.println 的调用被替换为对一个名为 p 的方法的调用,这样在每次方法调用时都可以使用短名称(行 9-11)。由于可能违反某些 Java 的编码规范,这些改变富有争议,不过有着其他背景的程序开发人员查看这些代码时可能并不会有何问题。
另外一些情况下,则利用了从 JDK8 预览版才新增的功能特性。静态引用(行 3-5)可以减少内联所需引用的类的数量。而正则表达式(行 10,45)则可以用与函数式编程本身无关的方式,有效隐藏循环和条件语句。这些习语,特别是正则表达式的使用,经常会因为难以阅读和说明而受到质疑。如果运用得当,这些习语可以减少噪音的数量,并且能够限制开发人员需要阅读和说明的代码数量。
最后,示例代码利用了 JDK 8 中新增的 Streaming API。使用了 Streaming API 中大量的方法对列表进行过滤、分组和处理(行 17-40)。尽管在 IDE 中它们与内附类的关联关系很清晰,不过除非你已经很熟悉这些 API,否则这种关系并不是那么显而易见。下表展示了示例代码中所出现的每一次方法调用的来源。
方法
完整的方法名称引用
stream()
java.util.Collection.stream()
sorted()
java.util.stream.Stream.sorted()
collect()
java.util.stream.Stream.collect()
toList()
java.util.stream.Collectors.toList()
groupingBy()
java.util.stream.Collectors.groupingBy()
identity()
java.util.function.Function.identity()
counting()
java.util.stream.Collectors.counting()
filter()
java.util.stream.Stream.filter()
mapToInt()
java.util.stream.Stream.mapToInt()
mapToObject()
java.util.stream.Stream.mapToObject()
uniq()(行 13)和 sort()(行 17)方法体现了同名的 Unix 实用工具的功能。sort 引入了对流的第一次调用,首先对流进行排序,然后再将排序后的结果收集到列表中。UniqueCount()(行 21)与 uniq -c 类似,返回一个 map 对象,其中每个键是一个字符,每个值则是这个字符出现次数的统计。两个“getWords”方法(行 26 和行 33)用于过滤出比给定长度短的单词。getWordLengthsLongerThan() 方法调用了一些额外的方法,将结果格式化并转换成不可修改的 String 对象。
整段代码并未引入任何与 Lambda 表达式相关的新概念。之前所介绍的语法只适用于 Java Stream API 特定的使用场景。
总结
用更少的代码实现同样任务的理念与爱因斯坦的理念一致:“必须尽可能地简洁明了,但又不能简单地被简单。”Lambda 表达式和新的 Stream API 因其能够实现扩展性良好的简洁代码而备受关注。它们让程序开发人员可以恰当地将代码简化成最好的表现形式。
函数式编程习语的设计理念就是简短,而且仔细思考一下就会发现许多可以让 Java 代码更加精简的场景。新的语法虽然有点陌生但并非十分复杂。这些新的功能特性清晰地表明,作为一种语言,Java 已经远远超越其最初的目标。它正在用开放的态度接受其他程序设计语言中最出色的一些功能,并将它们整合到 Java 之中。
关于作者
在过去的 15 年中,Casimir Saternos 曾担任过软件开发人员、数据库管理员以及软件架构师。他最近编写并创建了一个R 程序设计语言的截屏视频。他曾经在Java 杂志和Oracle 技术网络上发表过多篇文章。他还是 O’Reilly Media 上 Client-Server Web Apps with JavaScript and Java 的作者。
查看英文原文: Concise Java




