
专题介绍
2009 年,Spark 诞生于加州大学伯克利分校的 AMP 实验室(the Algorithms, Machines and People lab),并于 2010 年开源。2013 年,Spark 捐献给阿帕奇软件基金会(Apache Software Foundation),并于 2014 年成为 Apache 顶级项目。
如今,十年光景已过,Spark 成为了大大小小企业与研究机构的常用工具之一,依旧深受不少开发人员的喜爱。如果你是初入江湖且希望了解、学习 Spark 的“小虾米”,那么 InfoQ 与 FreeWheel 技术专家吴磊合作的专题系列文章——《深入浅出 Spark:原理详解与开发实践》一定适合你!
本文系专题系列第四篇。
首先感谢各位看官在百忙之中来听我说书,真是太给面子啦!在前文书《Spark调度系统之权力的游戏》中咱们提到 SparkContext 的初始化就像是打开了潘多拉的盒子,宛如三十六天罡临凡、七十二地煞降世,稳坐聚义厅头三把交椅的是 Spark 调度系统的三位大佬。三位大佬通力配合最终将任务(代码)分发到 Executor,Executor 则将分布式任务封装为 TaskRunner 并交由线程池执行。
笼统地说,任务执行的过程通常是将数据从一种形态转换为另一种形态,对于计算成本较高的数据形态,Spark 通过缓存机制来保证作业的顺利完成,今天咱们就来说说 Spark 的存储系统,看看 Spark 存储系统如何为任务的执行提供基础保障。
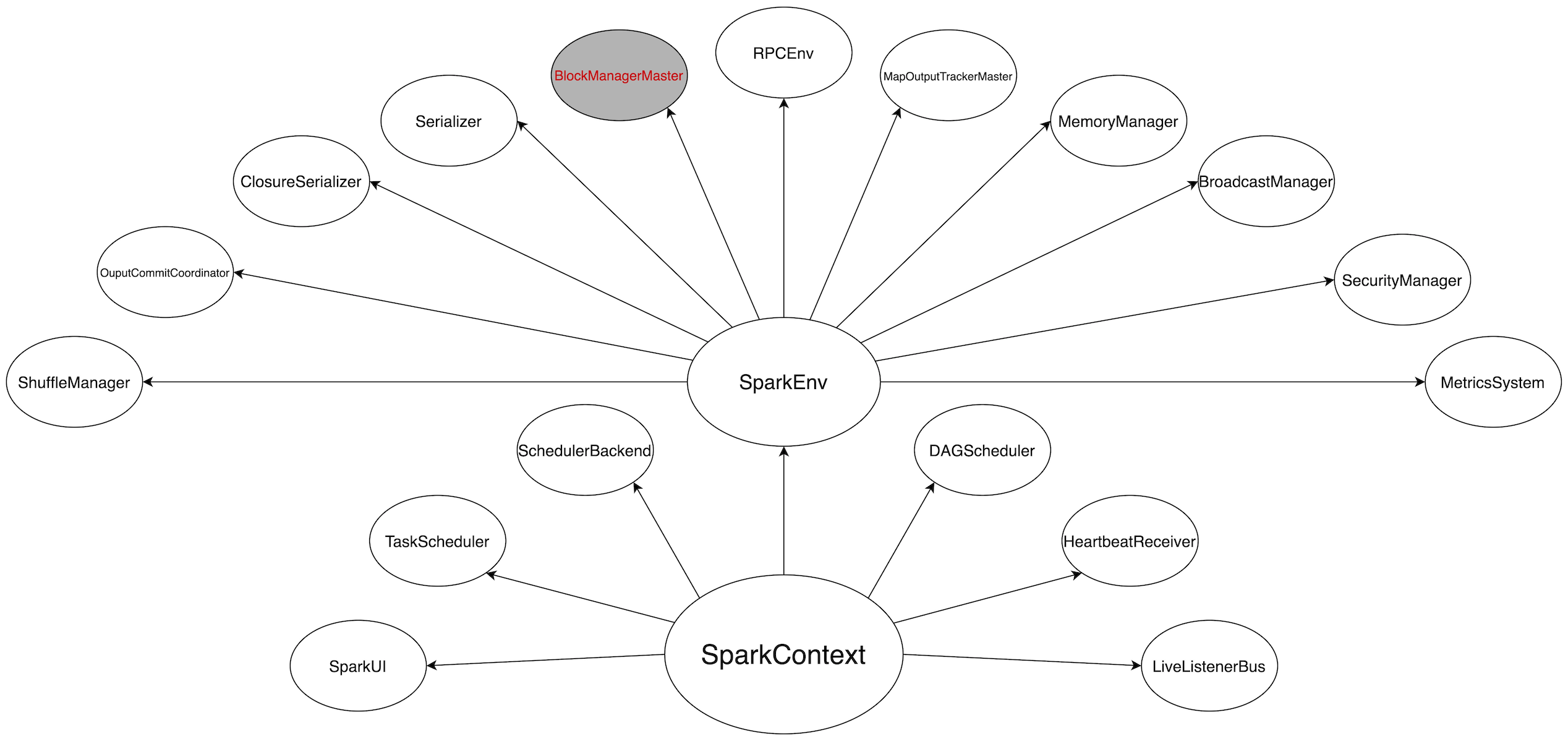
SparkContext 初始化
任何一个存储系统要解决的关键问题无非是数据的存与取、收与发,不过,在去探讨 Spark 存储系统如何工作之前,咱们先来搞清楚 Spark 存储系统中“存”的主要是什么内容?总的来说,Spark 存储系统用于存储 3 个方面的数据:
RDD 缓存
Shuffle 中间结果
广播变量
在咱们这套书《深入浅出Spark:原理详解与开发实践》中,这 3 个概念还是头一次出现。RDD 缓存指的是将 DAG 中某些计算成本较高且访问频率较高的数据形态以缓存的形式物化到内存或磁盘的过程。对于血统较长的 DAG 来说,RDD 缓存一来可以通过截断 DAG 从而降低失败重试的开销,二来通过缓存在内存或磁盘中的数据来从整体上提升作业的端到端执行性能。
Shuffle 的概念咱们在第二篇《深入浅出Spark(二):DAG》有简单的提及,不得不说,Shuffle 是个超级大的话题,作为绝大多数 Spark 应用的性能瓶颈担当,咱们在后文书还会细说 Spark 如何搞定 Shuffle。如果非要用一两句话来提炼,那么 Shuffle 的过程应该是:
Map 阶段:Shuffle writer 按照 Shuffle 分区规则将本节点数据以分片(Splits)的形式写入本地磁盘(或内存)
Reduce 阶段:Shuffle reader 按照 Shuffle 分区规则从各个节点下载属于本节点的数据分片并根据需要进行聚合计算
Map 阶段产生的数据分片,还有另外一个名字,聪明的您一定猜到了 —— 没错!就是“Shuffle 中间结果”。通常来说,这些中间结果默认都是存储在磁盘上的,不过要是您不差钱、内存随便用,想把这些中间结果怼到内存里去从而提升 I/O 效率,也是有办法的,这是后话,咱们回头再说。
最后说说广播变量,广播变量的设计初衷是为了解决 Spark 调度系统中任务调度的开销问题。在前文书咱们提到,Task 分发到 Executor 后,Executor 中的线程池会并发地执行多个 Task。对于如下这段代码:
val dict = List(“spark”, “scala”)val words = sparkContext.textFile(“~/words.csv”)val keywords = words.filter(word => dict.contains(word))keywords.map((_, 1)).reduceByKey(_ + _).collect只有第一行定义 dict 列表的代码是在 Driver 端执行,其余 3 行代码都在 Executor 端运行。需要特别注意的是,在第三行代码中,每个分发到 Executor 的 Task 都会消费第一行定义的 dict 列表,在没有广播变量机制的情况下,每个分发的 Task 都会携带一份这个列表的拷贝,对于一个线程池大小为 20 的 Executor 来说,这意味着在任意时刻该 Executor 中都有 20 份同样的数据拷贝,毫无疑问,这种分发方式引入大量不必要的网络和存储开销。
明智的做法自然是把需要共同访问的数据与 Tasks 剥离开来,让所有 Tasks 以共享的方式访问同一份数据。广播变量就是在这样的背景下诞生的,我们来看看使用广播变量的前后对比,即可一目了然地理解广播变量机制如何帮助任务分发降低网络与存储开销。
广播变量机制生效前后的任务分发对比
在广播变量机制下,Driver 中的 dict 列表在每个 Executor 中仅分发、存储一次。具体来说,dict 列表以广播变量的形式分发并存储到 Executor 的 BlockManager 中,Executor 中的多个 Tasks 不再持有 dict 列表拷贝,在需要读取 dict 数据时,通过 BlockManager 中存储的广播变量进行访问。广播变量的收益显而易见,一则提升存储效率,二则大幅降低网络开销,那么,如果我们将思维发散出去,广播变量是不是也适合其他需要考虑存储效率和网络开销的场景呢?
介绍完 3 种存储对象,咱们再收回来说说 Spark 存储系统的基本构成。还记得斯巴克国际建筑集团公司的权力派系吗?驻扎在总公司的 BlockManagerMaster 作为空降派主要成员,随时向老大戴格汇报建筑材料明细,当然这里的建材指的不仅仅是原始建筑材料如钢筋、水泥、砂石料,还可以是任意加工过的半成品如楼板、承重墙面等等。BlockManagerMaster 所掌握的一手信息均来自分公司的下属 —— BlockManager。本篇要讲述的,就是布劳克(BlockManager)和他的小弟们之间的故事。
Spark 分布式系统新老派系构成 —— 新老派系的故事请参考《Spark调度系统之权力的游戏》
存储建材的仓库
无论是原材料还是中间加工的半成品,这些形形色色的数据形态都需要有个地方“存”才行,Spark 存储系统提供了两种存储实现,分别是内存存储 MemoryStore 和磁盘存储 DiskStore。从名字我们就能看出来,MemoryStore 用于存储内存中的数据块,而 DiskStore 则用来存储磁盘中的数据块。
更形象地,在斯巴克建筑集团的分公司,MemoryStore 相当于是建筑工地上的临时储物仓库,无论是往里存物料还是往外取建材都很方便,不过缺点是临时仓库空间有限,能装的东西少;DiskStore 则不同,DiskStore 是能够容纳所有建材的专用仓储基地,这里地大物博,空间大、各种建材应有尽有,不过缺点是距离工地太远,来回往返运输建材比较麻烦,得需要多辆专用的大型货车才能及时地供应建筑工地的作业需要。
说完“在哪儿”(Where)存,咱们再来说说不同的数据形态以怎样的形式存储于 MemoryStore 和 DiskStore。
Spark 支持两种数据存储形式,即对象值和字节数组,且两者之间可以相互转化。将对象值压缩为字节数组的过程,称为序列化;相反,将字节数组还原为对象值,称之为反序列化。序列化的字节数组就像是从宜家家具超市购买的待组装板材(外加组装说明书),而对象值则是将板材拆包、并根据说明书组装而成的各种桌椅板凳。对象值的优点是“拿来即用”、所见即所得,缺点是所需的存储空间大、占地儿。相比之下,序列化的字节数组的空间利用率要高得多,不过要是急用桌椅板凳的话,还得根据说明书现装,略麻烦。
由此可见,二者的关系是一种博弈,所谓的“以空间换时间”和“以时间换空间”,具体的取舍还要看使用场景,想省地儿,您就用字节数组,想以最快的速度访问对象,对象值的存储方式还是来的更直接一些。不过像这种选择的烦恼只存在于 MemoryStore 之中,DiskStore 只能存序列化后的字节数组 —— 这里咱们多说两嘴,凡是需要走网络或落盘的数据,都是需要序列化的。
仓库类比之 MemoryStore 与 DiskStore
得益于临时储物仓库(MemoryStore)和专用仓储基地(DiskStore),斯巴克的各个分公司暂时解决了东西存在哪儿的问题,不过,光有仓库也不行啊,总得要有人打理、管理这些仓库,不然来拉取建材的人连想要的东西具体放在哪个货架都不清楚,总不能每次来都从头到尾把仓库逛个遍吧。
说到分公司的组织架构,建材部的部门经理布劳克(BlockManager)对与建材和库管有关的所有事项负责,比如建材编号、建材存储、建材拉取、建材运输、建材状态维护、仓库管理、仓库维护等等。
不过,作为部门经理,受限于时间和精力有限,布劳克自然不能事必躬亲,更何况他还要对自己的老板(总公司的 BlockManagerMaster)负责 —— 随时汇报分公司建材与仓储的信息与状态。好在布劳克还有一众小弟们来帮他打理各种具体事务,仅库存管理就有两个小弟来分别负责工地的临时储物仓库和专用仓储基地,他们分别是:BlockInfoManager 和 DiskBlockManager。
先说 DiskBlockManager,DiskBlockManager 的主要职责是记录逻辑数据块 Block 与磁盘文件系统中物理文件的对应关系。每个 Block 都对应一个磁盘文件,同理,每个磁盘文件都有一个与之对应的 Block ID,这就好比仓库中的每一件货物都有唯一的 ID 标识,显而易见,DiskBlockManager 就是专用仓储基地 DiskStore 的“库管”。
对于仓库的管理,DiskBlockManager 首先根据用户配置如 spark.local.dir 创建出用于存储文件的根目录,这一步相当于是在仓库中把所需的货架都提前准备好;然后,根据存储内容(如 RDD 缓存或 Shuffle 中间结果)的不同,创建不同前缀的文件:RDD 缓存为‘rdd_’,Shuffle 中间结果为‘shuffle_’,广播变量是‘broadcast_’,在创建文件的过程中,DiskBlockManager 同时维护 Block 与文件之间的对应关系;最后,当不同类型的任务根据 Block ID 尝试获取、访问这些数据块时,DiskBlockManager 根据对应关系查找与该 Block ID 对应的物理文件地址。
相较于 DiskBlockManager,MemoryStore“库管”BlockInfoManager 就显得没那么“称职”,对于 MemoryStore 中存储的数据,BlockInfoManager 的职责仅包含如下各项:记录数据块大小、维护加持在 Block 上的读锁与写锁、维护任务的读写权限状态。简言之,BlockInfoManager 主要用于保持 MemoryStore 中数据状态的一致性,而不是用于维护逻辑块与物理存储的对应关系。那么问题来了,想要拉取 MemoryStore 中“货物”的卡车司机怎么知道货物存储在哪个货架呢?
建材的存与取
要回答这个问题,咱们还要说回 MemoryStore,前文书咱们说到 MemoryStore 可以存储两种形式的数据,即对象值和字节数组,对于这两种数据形式,MemoryStore 统一采用 MemoryEntry 抽象来进行封装。
MemoryEntry 实现为 Scala Trait,主要成员为数据块大小和数据类型,它的两个实现类 DeserializedMemoryEntry 和 SerializedMemoryEntry 分别用于封装对象值和字节数组,其中 DeserializedMemoryEntry 利用 Array[T]来存储对象值序列,而 SerializedMemoryEntry 利用 ByteBuffer 来存储序列化后的字节序列。
MemoryStore 通过一种高效的数据结构来统一数据块的存储与访问:LinkedHashMap[BlockId, MemoryEntry],即 Key 为 BlockId、Value 是 MemoryEntry 的映射。显然,一个 Block 对应一个 MemoryEntry,MemoryEntry 既可以是 DeserializedMemoryEntry、也可以是 SerializedMemoryEntry。有了这个 LinkedHashMap,通过 BlockId 即可方便地定位 MemoryEntry,从而实现数据块的快速存取。
MemoryStore 中的数据存储流程
先来看数据存储的流程,也即将 RDD 中数据分片(Partitions/Blocks)的 Iterator 物化为数据存储的过程。
逻辑上,RDD 数据分片(也即 Partition)与 Block 是一一对应的,不过需要指出的是,Partition 的编号规则与 Block 的编号规则不见得保持一致。MemoryStore 提供了 putIteratorAsValues 和 putIteratorAsBytes 来将 RDD 数据分片对应的迭代器分别物化为对象值序列和字节序列,具体流程如上图所示。
值得注意的是,在将数据封装为 MemoryEntry 之前,MemoryStore 先利用 ValuesHolder 对 Iterator 进行展开(Unroll),展开的过程实际上就是物化的过程,数据实实在在地存储到 ValuesHolder 封装的数据结构(Vector 或 OutputStream)中,这些物化的数据在之后封装为 MemoryEntry 的过程中,仅仅(通过 toArray、toByteBuffer 等操作)在数据类型上做了转换,并没有带来额外的内存消耗,Spark 源码中将这个过程称之为:从 Unroll memory 到 Storage memory 的“Transfer(转移)”。
理顺了数据存储的流程,数据的读取和访问则一目了然。MemoryStore 提供 getValues 和 getBytes 方法,根据 BlockId 分别访问对象值与字节序列,如下图所示。两种方法首先通过 BlockId 获取到对应的 DeserializedMemoryEntry 或 SerializedMemoryEntry,然后在通过访问各自封装的 Array[T]和 ByteBuffer 来读取数据内容。
MemoryStore 中的数据访问
说到 MemoryStore 中数据的存与取,有几个重要的角色不得不提,他们分别是:
BlockInfoManager:前文书已有交代,其主要职责是通过锁机制来保证多任务并发情况下数据访问的一致性。
SerializerMananger:顾名思义,自然是负责 MemoryStore 中数据的序列化与反序列化。
MemoryManager:Spark 内存管理器,这可是斯巴克国际建筑集团分公司举足轻重的一位大佬,我们在下一篇《Spark 内存管理》中会有更详细的交代。
如果非要用一句话概括,MemoryManager 的主要职能是维持不同内存区域(Storage memory, Shuffle memory, Runtime memory 等)之间的平衡、以及维持多任务并发下不同线程之间内存消耗的平衡。
BlockEvictionHandler:这个角色比较有意思,他负责把 MemoryStore 中的数据块“驱逐”出内存 —— 通常情况下都会把这些被驱逐的 Block“撵”到 DiskStore 中去,也即把内存中物化的数据转移到磁盘存储中。一个典型的场景是当 RDD 缓存采用 MEMORY_AND_DISK 模式且内存不足以容纳整个 RDD 数据集时,根据 LRU 原则,访问频次较低且访问时间较为久远的 Block 就会被 BlockEvictionHandler“下放”到 DiskStore 中去。
DiskStore 中数据的存与取
说来说去又说回了 DiskStore,DiskStore 中的数据存取相对直截了当一些,有 DiskBlockManager 这个“管家”协助维护 Block 与磁盘文件的对应关系,DiskStore 并不需要过多的抽象来封装读写逻辑。实际上,在数据存取的闭环中,DiskStore 仅在数据访问的过程中利用 BlockData 抽象来封装将磁盘文件内容转换为字节数组的操作。
BlockData 的两个实现类 DiskBlockData 和 EncryptedBlockData 都是通过 open 函数获取 Java NIO 的 FileChannel,然后再通过 toByteBuffer 函数利用 FileChannel 将文件内容转换为字节数组。如上图所示,在数据访问过程(步骤 4 至 7)中,getBytes 首先根据 BlockId 从 DiskBlockManager 获取对应磁盘文件,然后将 FileChannel 封装为 BlockData,最后通过 BlockData 的 toByteBuffer 方法得到所需的字节数组。数据写入的过程(步骤 1 至 3)则更简单,首先根据 BlockId 从 DiskBlockManager 获取文件地址,然后再通过 FileChannel 将 ByteBuffer 内容落地到磁盘文件。
建材的运输与物流
到目前为止,数据的存与取都是发生在本地的,也即数据存储与拉取的请求和处理都是发生在同一个计算节点。前文书咱们说到,Spark 存储系统主要服务于三类任务:
RDD Caching
Shuffle
广播
要完成这些任务,仅有本地化的数据存取是不够的,Spark 存储系统还需要提供跨节点存取数据的能力。具体来说,为了提高可用性和稳定性,RDD Caching 往往会在 MemoryStore 和 DiskStore 中缓存多份 RDD 副本,节点间的副本拷贝与上传需要跨节点传输的能力。Shuffle 任务在 Shuffle write 阶段会将对应于多个 Reducer 的数据分片写入到本地磁盘,这些数据分片称为 Shuffle 中间文件,Shuffle read 阶段 Reducer 通过网络访问所有节点从而读取所有属于自己的数据分片,这个过程自然需要网络 I/O 的支持。那么问题来了,如何提供这些能力从而支持跨节点数据存取的功能呢?
在本篇的开始,咱们说到 SparkContext 在初始化的过程中会创建一系列的对象来分别服务于众多的 Spark 子系统 —— 如调度系统、存储系统、内存管理、Shuffle 管理、RPC 系统等,我们暂且把这些对象称之为“上下文对象”。BlockManager 作为 Spark 存储系统的入口,以组合的设计模式持有多个“上下文对象”的引用,封装了与数据存取有关的所有抽象。BlockManager 的组合对象星罗云布,到目前为止我们接触过的有:
MemoryStore、DiskStore、BlockInfoManager、DiskBlockManager —— 本地数据存取
MemoryManager —— 维护不同内存区域之间的平衡
SerializerManager —— 序列化管理器
除此之外,还有 MapOutputTracker、ShuffleManager、BlockTransferService 等等。MapOutputTracker 咱们在上一篇《Spark 调度系统之权力的游戏》略有提及;Shuffle 是个大话题,ShuffleManager 我们留到之后《Spark Shuffle 管理》再讲;本章节的主角是 BlockTransferService —— 回答刚刚的问题,Spark 存储系统正是仰仗 BlockTransferService 来提供跨节点的数据存取。
Spark 存储系统对于不同类型任务的支持
BlockTransferService 抽象主要提供两种方法来支持不同类型的计算任务,即如上图所示的 fetchBlockSync 方法和 uploadBlockSync 方法。
BlockTransferService,顾名思义,既然是 Service,自然就绕不开 Server/Client 的概念。fetchBlockSync 方法和 uploadBlockSync 方法都属于客户端方法,用于向服务端提交“下载数据块”和“上传数据块”的请求。
说到这里,各位看官不禁要问:BlockTransferService 就是个抽象而已,而且仅仅提供了两个数据收发的接口,它依托什么来构建服务端和客户端呢?
要说清楚客户端与服务端,咱们就需要深入到 BlockTransferService 接口的唯一实现类 NettyBlockTransferService 中去一探究竟。Netty 是基于 NIO(Nonblocking I/O,非阻塞 I/O)的网络通信框架,非阻塞 I/O 赋予 Netty 天然的高并发特性,Netty 提供 Channel 抽象对 JDK 原生的 SocketChannel 进行了封装和增强从而使得开发者可以更加高效地进行网络开发。NettyBlockTransferService 正是站在 Netty 的“肩膀”上在初始化阶段同时创建客户端工厂和服务端。
NettyBlockTransferService 创建建客户端与服务端
如上图所示,NettyBlockTransferService 在初始化过程中分别通过 createServer 和 createClientFactory 来创建服务端和客户端,二者的创建过程极其类似 —— 先实例化 Netty Bootstrap、然后绑定 Channel 和异步处理线程 NioEventLoop、最后绑定地址与端口/连接服务器来启动服务/发起请求。
通过客户端,BlockManager 即可通过 fetchBlockSync 方法和 uploadBlockSync 方法向其他计算节点发起数据块下载/上传请求;相应地,每个 BlockManager 通过服务端来响应其他节点发来的数据传输请求。这么看来,对于斯巴克国际建筑集团公司来说,BlockTransferService 相当于是集团为分公司(Executor)配备的物流服务,专门负责不同分公司之间建材的物流与分发。
到此为止,Spark 存储系统的全貌已初露端倪,尽管相关环节细节还有待深入,不过从功能和功用的角度来说,Spark 存储系统作为底层基础设施,我们基本上弄清了它如何为其他数据服务(如 RDD 缓存、Shuffle)提供基础保障。这些数据服务在 Spark 分布式计算中扮演着至关重要的角色,运用得当,他们可以帮助应用程序大幅提升执行性能,不过,反之亦然。在接下来的篇章里,我们将一一对其展开、渐进式地解锁性能调优的技能,敬请期待。
Postscript
本篇是《Spark分布式计算科普专栏》的第四篇,笔者学浅才疏、疏漏难免。如果您有任何疑问,或是觉得文章中的描述有所遗漏或不妥,欢迎在评论区留言、讨论。掌握一门技术,书本中的知识往往只占两成,三成靠讨论,五成靠实践。更多的讨论能激发更多的观点、视角与洞察,也只有这样,对于一门技术的认知与理解才能更深入、牢固。
在本篇博文中,先从功用的角度介绍了 Spark 存储系统服务的主要对象(RDD 缓存、Shuffle、广播);紧接着从“建材仓储”MemoryStore 和 DiskStore 入手,说明了数据在 BlockManager 中的存储形式和存储方式;然后通过 MemoryEntry 和 DiskBlockManager 来讲述数据在内存和磁盘中的存取过程;最后以 BlockTransferService 收尾,NettyBlockTransferService 以服务端与客户端的形式为跨节点数据传输提供基础服务。
出于科普的初衷,本篇隐去了 Spark 存储系统中的一些分支和细节,如与 ExternalShuffleService(提供高可用的 Shuffle 服务)有关的存储功能、为支持异步数据拷贝与上传而提供的 newCachedThreadPool 线程池,等等。
从下一篇开始,咱们将以性能调优为导向分析、探讨 Spark 分布式系统的关键环节,而不只是单纯地进行原理的讲解。作为一款内存计算引擎,内存的探索与利用自然尤为重要,毕竟不知 MemoryManager 如何以统一的方式打理内存,且听下回分解。
作者简介
吴磊,Spark Summit China 2017 讲师、World AI Conference 2020 讲师,曾任职于 IBM、联想研究院、新浪微博,具备丰富的数据库、数据仓库、大数据开发与调优经验,主导基于海量数据的大规模机器学习框架的设计与实现。现担任 Comcast Freewheel 机器学习团队负责人,负责计算广告业务中机器学习应用的实践、落地与推广。热爱技术分享,热衷于从生活的视角解读技术,曾于《IBM developerWorks》和《程序员》杂志发表多篇技术文章,并在极客时间发表了两个专栏《零基础入门Spark》和《Spark 性能调优实战》,内容深入浅出、风趣幽默。




