
文 | 王洲,王强强
1. 背景
口语环节正在语言类教育课程中获得更多重视,一对一的师生交流和指导是提高口语水平最有效的方式,但该方式很难满足数量众多的口语学习者需求。得益于计算机技术和语音评测技术的突飞猛进,计算机辅助语言学习(Computer Assisted Language Learning)技术应运而生,各种基于人工智能技术的口语评测方案相继落地。包括朗读,背诵,复述,自由表达等多种方式,它为学生提供了额外的学习机会和充足的学习材料,能够辅助或者替代教师指导学生进行更有针对性的发音练习,指出学生的发音错误,提供有效的诊断反馈信息,并评估学生的整体发音水平,从而切实提高学生的口语学习效率和口语水平。
2. 语音评测技术简介
2.1 评价指标
发音评测维度包括发音的准确率,流畅度,完整度,韵律,语调等
准确度:体现用户的发音水平。
流利度:体现用户朗读流畅程度,和语速、停顿次数相关。
完整度:体现用户发音正确的单词占比。
单词得分:句子中每个单词的得分。
句子得分:段落中每个句子的得分。
总分:评测整体得分,综合上面分数获得,准确度对总分影响最大。
口语好坏的评价是主观的,人工专家根据自身的专业知识及经验,在各个维度按照优、良、中、差、劣等级进行打分,不同的专家会得出不同的结果。评价机器口语评测系统是否靠谱,一般采用相关系数(Pearson correlation coefficient),一致性(kappa coefficient)等指标来衡量打分系统的性能。与专家打分越接近,系统越靠谱。但有多靠谱,需要有参照物,通常会用平均的人与人之间的相关性来作为参照,目前的人机相关性、一致性已经超过了人与人之间的平均相关性,一致性。语音评测技术已被普遍使用在中英文的口语评测和定级中。
2.2 技术框架
语音评测目前的主流方案是基于隐马尔科夫-深度神经网络(Hidden Markov Model,HMM,Deep Neural Networks, DNN)模型获得语音后验概率,与评测文本强制对齐(force alignment)后,使用 GOP(Goodness of Pronunciation)方法进行打分,流程如下图所示。

1) 声学特征提取:语音信号在一帧(frame)观察窗口内平稳,将切分后的时域片段信号转换到频域,获得 MFCC(13 维或 40 维),Fbank(80 维)等特征,一帧是语音序列的最小单元。在 GMM(Gaussian Mixture Model)模型中,使用 MFCC 特征,是因为 GMM 的协方差估计使用了对角矩阵,输入特征需要保证每一帧的元素之间相互独立。DNN 模型中,特征可以是 MFCC 或 Fbank 特征;
2) HMM-GMM 无监督聚类:该过程用来获取帧标签(Frame-wise label)进行后面的 DNN 训练。HMM 对语音的时序约束、依赖进行建模,GMM 属于生成模型,对 HMM 的观察概率(属于各个音素的概率)进行建模。语音的标注通常是单词序列,每一帧对应哪个音素提前是不知道的。GMM 通过相似度聚类,同一个音素的相邻各帧归为同一类,获得音素的 duration、边界信息。目前语音信号中对齐算法主流依旧是 HMM-GMM,其它算法 ctc,attention 对齐都有各自的问题,ctc 的尖峰,attention 的时序无约束问题。
3) DNN 判别学习: GMM 聚类效果尚可,但 GMM 对音素建模能力有限,无法准确的表征语音内部复杂的结构。通过 DNN 取代了 GMM 来进行 HMM 观察概率的输出,可以大大提高准确率。DNN 模型的最后一层使用 softmax 进行软分类,交叉熵 loss 进行训练,DNN 的输出称为后验概率 (phonetic posteriorgrams,PPG)。
用一个例子来说明 DNN 的输出,假设有 5 帧语音特征, 发音内容为“er_3 d uo_0”, 取[sil,er_3,d,uo_0,uo_3]PPG 如下:
在 t=0 第一帧,er_3 的概率 0.921272 最大。
4) 评测文本构建 hmm 解码图,约束文本时序关系:

对于上面的评测文本“er_3 d uo_0”, 我们要评价每个音素的发音正确性,也要保证时序性,如果用户读的是“d uo_0 er_3”每个音都对,但时序是错误的,为了约束这种时序关系,我们定义了如上的 HMM 结构。状态 0 到 1,1 到 2,2 到 3, er_3,d,uo_0 每个音至少发生一次,状态 1,2,3 上面每个都有自旋,表示该音素可以重复发生。
5) Viterbi 解码获得强制对齐结果
首先我们将 PPG,表示成状态转移图,如下图所示,有六个状态,状态之间的弧表示各个音素及音素的后验概率,0 粗线圆圈代表开始状态,5 双圆圈代表结束状态。如果音素个数为 C,帧数为 T,则弧路径个数为
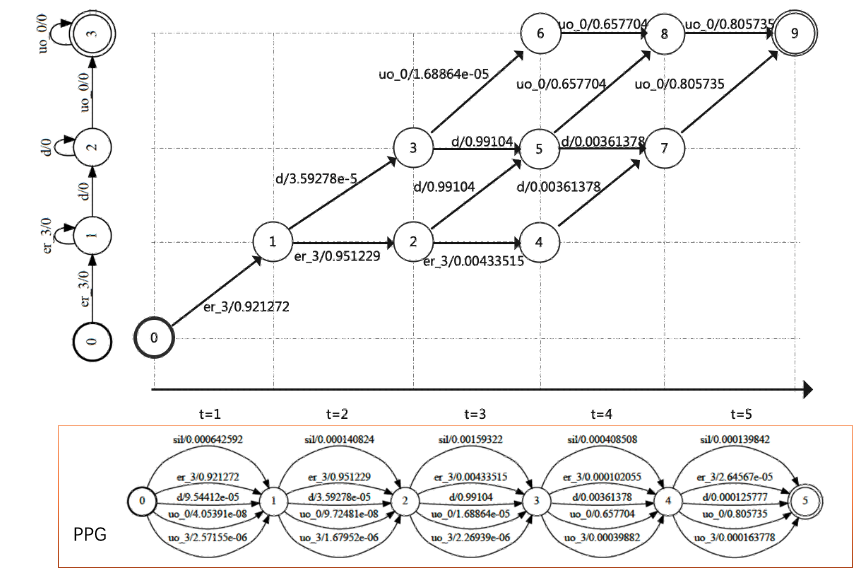
DNN 的后验概率转移图,通过评测文本 HMM 解码图的约束,在条路径中,只剩下构成“er_3 d uo_0”的路径及相应的 score。使用 Viterbi 算法我们可以高效获得 score 最大路径。上图中 Viterbi 最优路径[er_3, er3, d, uo_0, uo_0] ,也就是强制对齐结果。
6) GOP 准确度打分,Averaged Frame-level Posteriors[1]:
是 DNN 模型 softmax 的输出,是 t 时刻语音帧,是 force alignment 后 t 时刻的对齐音素。是音素的开始和结尾。
GOP(er_3)=(0.92+0.95)/2
GOP(d) = 0.99
GOP(duo_0)=(0.65+0.80)/2
7) 整体打分
获得音素的准确度打分,离最终的单词,句子,整体打分还有距离。评测任务最后都会接一个打分模型,使用音素的 GOP 分数,流利度等特征拟合到专家分数。2021 年腾讯提出一种将声学模型中的深层特征[2],而不是 GOP 特征传递到打分模块中,该模块基于注意力(attention)机制,考虑句子中不同粒度之间的关系,获得了更优的整体评分。
作业帮目前基于特征提取工程,收集了包括 GOP 分数,元辅音,词性,声调,发音时长,流利度等多维度信息,通过神经网络模型强拟合能力,预测单词,句子的分数结果,整体打分效果跟人工打分取得了较高的一致性。
3. DNN 声学模型的改进
3.1 conformer 模型
Conformer 是 Google 在 2020 年提出的语音识别模型,基于 Transformer 改进而来,主要的改进点在于 Transformer 在提取长序列依赖的时候更有效,而卷积则擅长提取局部特征,因此将卷积应用于 Transformer 的 Encoder 层。Conformer 的 Encoder 模型由多个 encoder_layer 叠加而成,每个 encoder_layer 由 feed-forward ,multi-head self-attention,convolution,feed-forward 组成。
在流式评测任务中,随着用户的朗读,需要实时快速的返回评测结果,直接使用 conformer 模型进行流式评测,会遇到以下问题:
1) 由于 attention 机制,每一帧数据需要看到全部数据做 weight 计算,随着语音时长的增加,计算复杂度和内存储存开销会越来越大;

2) 为了提高帧的识别准确率,每帧会向前看几帧数据,随着 encoder_layer 的增加,向前看数据量就会累加,这会造成很大的延迟;
3.2 基于块(chunk)的 mask 流式解决方案[3]
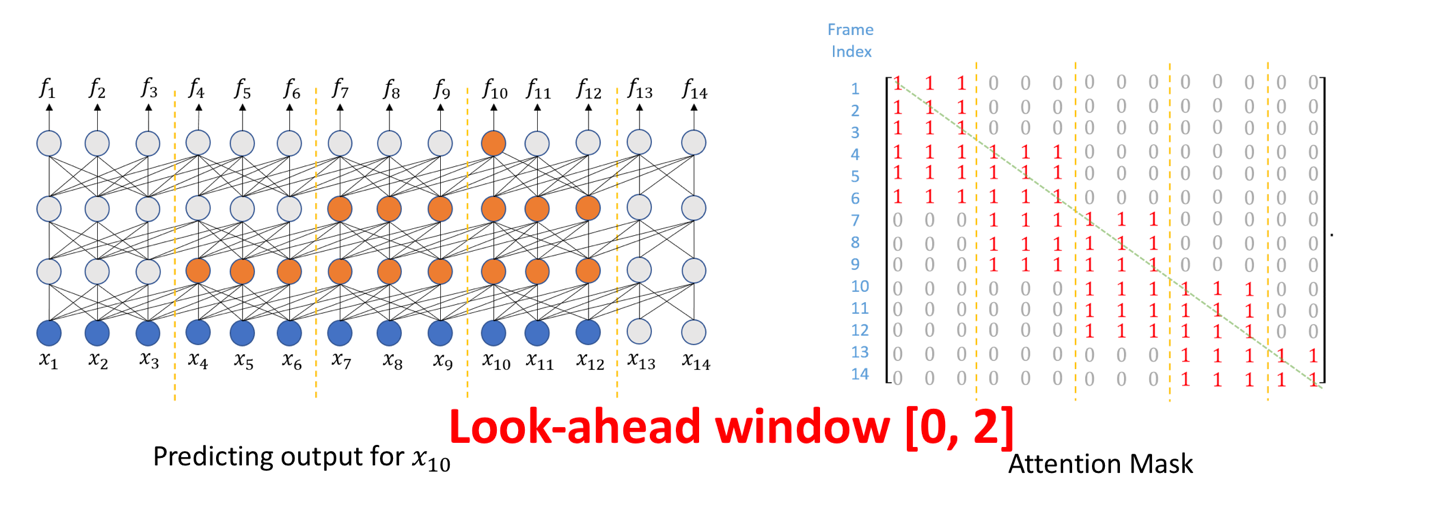
如上图所示,相邻三帧为一个 chunk,通过 mask 掉一些数据,attention 作用在当前 chunk 和前一个 chunk 中,当前 chunk 中的每一帧对右边的视野依赖最多两帧,平均时延为一帧时长,在每个 encoder_layer 层,对历史数据的依赖最多五帧。通过 mask 机制牺牲掉一些 attention 带来的收益,换取流式低延迟作为妥协。
conformer 中的卷积模块也使用了因果卷积,避免右边视野的累积。通过以上的改进,conformer 胜任了流式评测任务,时延在 300ms 左右。
4. 古文背诵应用中的特殊处理

如上图所示,学生在手机应用中选择古文进行背诵,屏幕上就会实时显示背诵情况,正确染成黑色,有发音错误,染成红色。背诵后给出整体的评分报告,以此帮助学生检查和进行背诵练习。
多分支评测:古文背诵中,评测文本一般为一首诗,或古文的一段,包含了多句话。评测文本的解码图需要以句子为单位,支持句子的重复读(家长领读,小孩跟读),跳读(可以往前跳,也可以往后跳读)

为了关注句子级别的构图关系,上图做了简化,将音素改为字,去掉字的跳读,重复读等弧。0 为开始状态,1 是结束状态,到达结束状态可以继续回到开始状态,开始下一句的背诵,每句背诵前面会有一个句子标识“$0”,“$1”等,通过该标识,我们可以知道当前用户读到了那一句,方便染色。
上面的构图方式在一些诗句背诵中遇到问题,当诗句中存在重复诗句,或开头相似的句子。当回到开始状态 0 时,由于每条路径都是等概率的。会出现如下的现象:
在 t+1 时刻读完了第二句,应该开始第三句“$3 鱼”的染色,但由于等概率,及顺序问题,仍然会走 $2 路径,当 t+5 时刻读到“东”,路径会突然跳转到“$3 鱼戏莲叶东”。用户的体验就是,读完第二句一直不染色,读到“东”,立马第三句整句染色,影响体验。
解决方案:如下图所示,每一句读完添加到下一句的弧,例如状态 7 到 8 添加空边,第一句读完可以走第二句路径,或者回到起始状态,但添加惩罚(比如 0.5)。这样就可以保证古文多句的顺序读,但又保留了足够的自由度,允许重复读,跳读。
5. 评测引擎本地化
评测服务在部署阶段遇到了如下问题:
1) 课堂场景应用评测技术会带来超高并发,直播课场景,老师下发题目后学生几乎是同一时刻做答,并发量瞬间达到几万,要保证用户在短时间内尽快拿到打分结果,不能通过消息队列异步处理,只能提前为每个连接准备资源,需要大量的服务器资源支撑。
2) 网络传输有一定的时延,对于需要做实时染色的评测服务,会感觉到染色时延,体验较差。
3) 语音评测需要建立长链接,用户的网络有波动,但是语音评测服务要实时返回结果,无法缓存,会造成一定程度的评测失败。
为了解决这些问题,我们考虑开发本地评测方案,相比云端,本地评测具备以下优势:低延迟:节省了网络请求的延迟,优化了用户体验。安全性:更好的保护用户隐私数据。更稳定:消除了网络波动对服务的影响。节约云端资源:根据不同的本地算力,与云端推理结合,从而降低对云端算力的压力。
作业帮语音评测技术经过数轮迭代,在保证效果的前提下,conformer 模型通过裁剪以及量化等处理,压缩到 10M 以内,极大降低了端的算力要求。
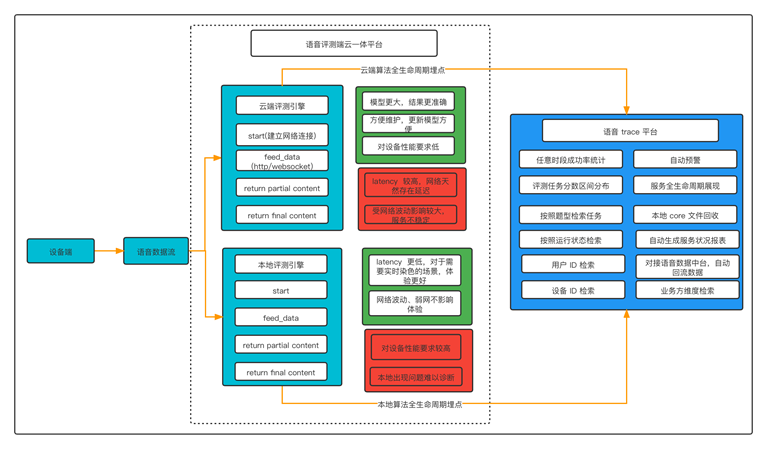
作业帮用户体量比较大,部分用户使用的手机配置较低,难以进行端上计算,为了给所有用户带来好的体验,我们采用了端云一体解决方案,如下图所示。为了结合“端”和“云”的优势,在评测时,服务判断端上算力,对于较高算力的设备,评测是在“端”上完成;对于较低算力的设备,评测是在“云”上完成。在“端”的解决方案中,能提供 PC、手机、平板电脑、学习笔等多类型的硬件设备;跨平台支持 iOS,安卓、Windows、鸿蒙、Linux 等操作系统。
使用端云一体方案后,延时从原来的 200ms 降低到 50ms 以内,用户体验明显提升。同时释放了大量服务端资源,服务端资源占用降低为原有的 20%。
6.技术总结展望
语音评测技术和语音识别任务非常类似,近些年都获得了快速发展,语音识别中各种端到端算法不仅简化了训练流程,同时降低了整体错误率。评测技术也从原来的 HMM-GMM 升级到 HMM-DNN,准确率大幅提升。
但在语音评测中 GMM 依旧是非常核心,必不可少的算法模块,通过 GMM 良好的聚类能力,音素的边界信息被提取出来。但能否通过神经网络直接获得对齐信息,大家有在各种尝试,interspeech2021 会议论中 Teytaut 通过 ctc 与 Auto-Encoder 的结合获得了优于 GMM 的对齐效果[4],ICASSP2022 会议论文中字节跳动提出了基于双向注意力神经网络强制对齐(Forced Alignment)模型 NeuFA[5]。生成模型 Auto-Encoder,Variational Auto-Encoder,以及 attention 机制都有不错的对齐潜力,语音评测技术如果能借鉴这些方法实现完全的端到端训练,准确度有机会进一步提高。
Reference:
[1] A New DNN-based High Quality Pronunciation Evaluation for
Computer-Aided Language Learning (CALL)
[2] Deep feature transfer learning for automatic pronunciation assessment
[3] Developing Real-time Streaming Transformer Transducer for Speech Recognition on Large-scale Dataset
[4] Phoneme-to-audio alignment with recurrent neural networks for speaking and singing voice
[5] NeuFA: Neural Network Based End-to-End Forced Alignment with Bidirectional Attention Mechanism
作者介绍
作业帮语音技术团队成立于 2018 年,积累了语音识别、语音评测、语音合成、声音克隆、声纹识别、语音降噪等技术。提供整套语音技术解决方案,支撑整个公司的语音技术需求。
王强强 作业帮语音技术团队负责人。 负责语音相关算法研究和落地,主导了语音识别、评测、合成等算法在作业帮的落地实践, 为公司提供整套语音技术解决方案。
王洲 作业帮语音算法工程师, 在语音识别、语音评测、话者分离领域有丰富的落地经验,开发的算法模块支撑了智能质检、趣味古诗等多项业务。




