
当你面对一个由几百上千个服务高度耦合而成的大型系统,各式各样的问题便会不约而至,而且绝对是一个不小的挑战。熵增原理告诉我们——任何系统都需要治理,本文分享严选在多年的服务治理实践中的一些思考、一些心得。
服务需要治理吗?
当然需要,你 100%会碰上各种需求,各种问题。
古代的农民耕种最关心的问题是气候变化、按时播种、按量灌溉,而如今的现代化规模化种植时代,农民(和粮食集团)还需要去关注一系列其它问题,譬如多作物立体种植、经济效应最大化、环保合规和生态破坏等等。只要生产方式和生产规模不是一成不变,那早晚都会有新的问题诞生。
计算机应用亦然。当服务技术架构还是单体服务(monolithic)的年代我们需要解决问题 A、问题 B 和问题 C,到了 MVC 架构/RPC 架构/SOA 架构盛行的时代可能会引入问题 D、E、F,当业务规模持续扩张促使架构演进到微服务(microservice)阶段,此时你会发现,可能老问题 A、B、D、F 消失不见了,但 C 和 E 依然存在,同时还引入了好几个新问题 G、H、I、J 和 K。
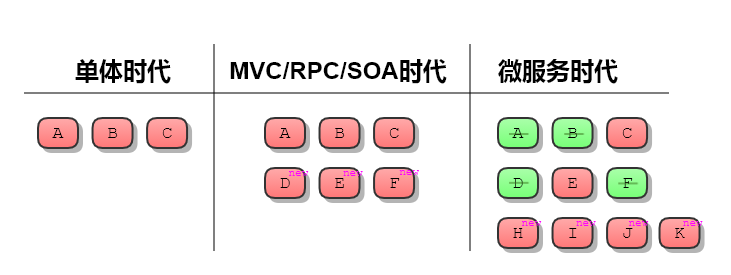
存在问题或可能出现问题,因此才需要治理。
IBM 在 2006 年对服务治理的要点做过总结,“问题”可以归纳为以下 10 个方面:
服务定义 Service definition:关注服务的范围、接口和边界
服务生命周期 Service deployment life cycle:从规划到下线整个生命周期各个阶段
服务版本治理 Service versioning:强调兼容性,新需求催生新版本,但迭代不能中断用户体验
服务迁移 Service migration:启用和退役
服务注册中心 Service registries:依赖关系
服务消息模型 Service message model:规范数据模型
服务监控 Service monitoring:异常发现、排障定位与恢复,强调 SLA
服务所有权 Service ownership:企业组织,用户角色,对齐服务与业务关系
服务测试 Service testing:充分测试和验证,覆盖,重复
服务安全 Service security:圈定保护范围,控制数据获取渠道并强化
在严选的实践中,我们发现服务元数据管理(配置中心或叫 CMDB)、注册与发现、流量管理、容量管理、资源调度、可观测性、故障定位、安全控制、平台抽象化等方面是解决问题的重中之重。同时,要重视规范流程先行、交付效率 &交付质量和治理平台易用性。其实,这里面每一个方面都很庞大和复杂,值得深入钻研,它们都属于服务治理的范畴,整个服务治理就是“企业为了确保事情顺利完成而实施的过程”(SOA governance —— Anne Thomas Manes)。

如果你的系统规模很小,只有十几个服务,那治理成本是很低的,任何粗放式、人工式手段通常都能被接受。然而,当你面对一个由几百上千个服务高度耦合而成的大型系统,各式各样的问题便会不约而至,而且绝对是一个不小的挑战。熵增原理告诉我们——任何系统都需要治理,假如我们选择无视这些问题,则可能导致一些更加不可接受的问题,譬如维护成本剧增、规范腐化、MTTR 增加、SLA 下降、系统失控等等。
一句话,服务治理,势在必行,宜早不宜迟。
服务如何治理?
参考答案:拥抱 DevOps。
DevOps 是服务治理的好伙伴。DevOps 落地让团队获得 CMDB、CI/CD、CloudNative、ServiceMesh、Monitor 等多重利器,为服务治理提供各种工具,是不可或缺的治理能力层。
严选 DevOps 工具链的持续建设让产技部门在效能、性能、稳定性等方面尝到了越来越多的甜头,随着基建越来越完善,服务治理状况也得到极大改善。正所谓内功外功要兼修,在这个过程中,我们发现服务治理很需要一个统一的易用的门户平台,否则开发、测试和运维都要去接触很多概念术语和底层系统,面临着巨大学习成本和上手门槛(效能↓),以及不小的出错几率(风险↑)。
于是,一个严选服务治理门户便水到渠成地诞生了,项目代号是服务鸟巢 Service Nest,内部日常简称为 SNest。前面提到服务治理要解决 10 个方面的问题,这些问题在背后会由不同的系统在提供解决方案(如 CMDB、Consul、Istio、KVM、K8S 等),这些通通可以视为能力层,而 SNest 最大的使命就是包装全部能力层并统一暴露出来,作为服务治理的整合平台和用户端门户系统。
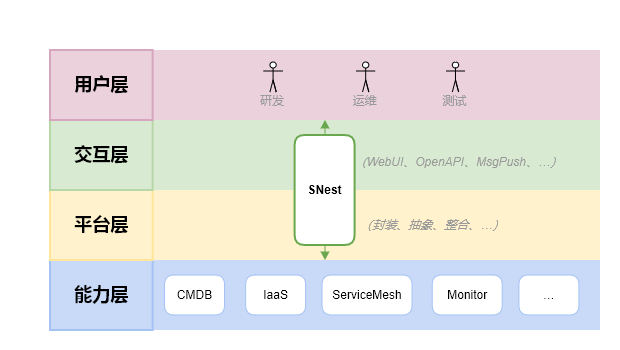
下面举几个例子。
服务元数据管理
服务类型、所属产品、不同环境的实例信息(IP、端口)、JVM 配置、Tomcat 参数、操作系统特殊需求、服务的负责人/研发人员/测试人员列表等等,这些都可以视为服务的元数据,它们非常重要。
以前:散落在各地(开发和运维手上各自维护一部分,可能记录在一些内部零散系统或者 wiki、甚至靠脑子记忆),有变更靠人工交流、手动执行,系统之间也无打通关联。可想而知,沟通成本巨大,而且,时间久了就意味着文档老化和数据变脏。
现状 &规划:基础配置项(Configuration Item,CI)维护在严选 CMDB,服务级别的配置项(也是 CI)则维护在严选 SNest,核心配置的修改由流程控制(严选工单),配置变更后触发通知(严选事件消息中心),再结合 SNest 提供的丰富 OpenAPI,使得严选全服务的元数据得以平台化(入口收敛,规范落地于此)、流程化(变更审批和事件推送)、自动化(工单自动执行)和数据打通(系统间联动,通传通识)。对将来来说,拥有完善的服务元数据对单元化和服务定义(Application Definition)等进阶项目都有极大帮助。

服务容量与资源调度
服务实例必须运行在一定资源之上,服务 A 可能需要 4 台 8core/16G mem/150G HDD 规格的虚拟机,服务 B 可能需要 10 台 Dell R740 物理机,服务 A 希望不要与服务 BCD 共处同一台物理宿主机(这 4 个服务容易存在资源抢占,严选内部常称之为互斥),服务 E 希望优先被调度到能提供 SRIOV 高性能网络的机器(云计算建德机房,特殊网卡+内核参数)上运行。与此同时,严选当前正处于上云过程中,云内和云外两地机房的 IaaS 资源层实现是不同的,云外机房跑的是物理机和 KVM 虚拟机,而云内机房跑的是云计算轻舟提供的 K8S 容器。
以前:仅提供少数几个规格备选,粒度粗,存在浪费(服务通常会偏大选择,主机利用率低),支持最简单的调度算法。主机利用率抓得不严,容量趋势预估多为人工,规格选择也是依靠申请人经验。
现状 &规划:SNest 提供多种丰富的细粒度规格,以及规格智能推荐、规格/副本数环境限制等策略,并且支持用户表达资源调度倾向性:云外使用 WebKvm 新算法和新表达式,云内则借助 K8s Lable/NodeSelector/Toleration 等对象来组合亲和性表达式。借助主机利用率统计和资源密集型定性,可以支持错峰调度,错开资源密集型调度,进一步提高整体利用率和降本。

服务注册发现与流量调配
服务注册发现与流量调配,这是 ServiceMesh 关键落脚点,包括一个服务在各个环境有哪些实例,运行在何处(IP:Port),处于什么状态(健康检测),希望受理多少流量(流控频控),是否需要劫持流量做一些校验甚至篡改等等。严选的 ServiceMesh 架构一直在演进,云外机房使用的解决方案是 Consul+Consul-Nginx,而云内机房则使用 K8S+Istio 云原生定制增强方案。
以前:服务注册走工单人工执行,日常可使用一个老旧平台去维护实例状态,用户直接打 Consul weight 标签来控制每个实例的流量(此时需人工核算每个实例的 weight 值,容易算错),严选上云初期服务要切一部分流量进去云内很麻烦,必须找运维人工修改 Consul 配置和网关配置。
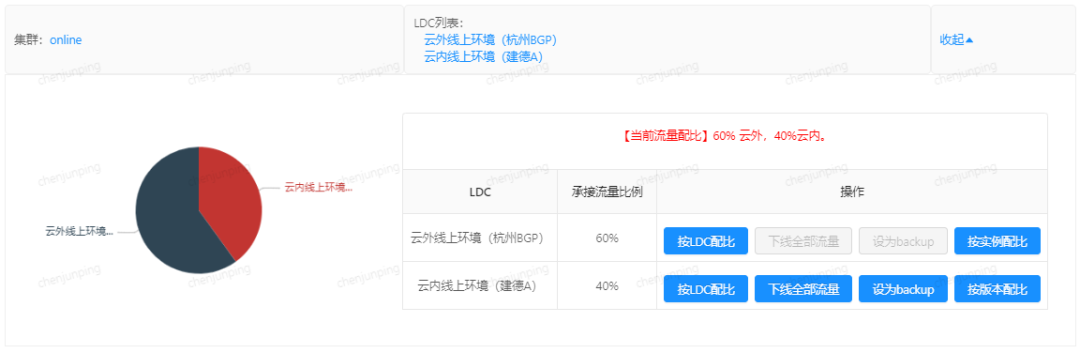
现状 &规划:SNest 抽象掉两地机房底层不同的 ServiceMesh 解决方案并统一封装成接口,再以一个的简单易用的交互界面暴露出来,开发/测试/运维可以无需关心 Consul/Consul-Nginx/k8s svc/ingress/egress/Istio RR,DR 等专业术语有什么特性、什么时候用、什么时候不要用、有什么易踩的坑。用户在申请资源时 SNest 会自动完成服务注册(无论云内云外),日常管控时可以傻瓜式一键调配流量(控制各个机房分别受理多少比例的流量,或者每个实例受理多少)。由于 Istio 能力很强大(它劫持了全部进 &出调用),那么实现限流熔断、黑白名单、故障注入等也都是轻而易举,对应用无侵入。
严选的治理心得
严选的服务治理方兴未艾,诸多规划点都处于持续建设的状态,尽管距离终点还有很长一段路,但多年的实践经验还是给了我们一些思考、一些心得。
能力层要夯实
万丈高楼起于垒土,积基树本;
无论是 CMDB 层、MetaData 层、IaaS 层、ServiceMesh 层、Monitor 层等,它们都是服务治理必须依赖的基础能力,务必规划先行,规范先行,能力先行。这些能力层缺一不可,而且无一不重要,怎么样做好都不过分。
平台层要统一
能力层位于底层,而且可能是异构的(不同数据中心有不同的实现方案),服务治理必须封装一个平台层:把底层抽象掉,为上层管控提供接口;
平台层可以实现收口,同时落地规范。今后能力层有进化,规范有调整,只需要迭代平台层即可;
也可以让能力和规范都聚集起来,不再散落,不再失控。
交互层要友好
关键词是“友好”二字;
服务治理解决方案在面向用户(研发/测试/运维等技术人员)时一定要提供足够友好的交互门户,包括但不限于页面 UI、工单流、消息通知机制等等;
越友好,越全面,越直观,越精细,越智能,这样的门户不仅可以提高生产效率,还能降低上手门槛和出错概率。
演进要果敢
业务在发展,会提出更多新需求和新问题;
社区在演进,会提供更多新工具和新创意;
银弹是不存在的,当你察觉到治理现状对新需求和新问题已经显得捉襟见肘、无能为力时,你就应该果断启动新方案的研发和试点。业务那边不用太担心,当前版本还在继续跑着,只需无感式地迭代你的“能力层/平台层/交互层”并适时推出新版本即可。至于老系统和老版本,该退役的就勿过于留念。从 1 到 1.1 也是创新。
小结
服务治理要解决十大类问题,还是那句话,每一类问题单拎出来都是一个大型课题,都需要充分实践,而且没有一成不变的最佳实践。本文是严选在服务治理历程上的一些心得总结,权当抛砖引玉,望大家不吝勘正,发表评论和文章分享自己的经验。
路漫漫其修远兮,吾将上下而求索。
作者简介
书技, 网易严选运维 SRE 负责人,专注系统容量与稳定、DevOps 效能、服务治理、线上质量等体系的搭建和发展。
头图:Unsplash
原文:在路上:严选服务治理实践
来源:严选技术产品团队 - 微信公众号 [ID:YanxuanTechProd]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




