
文章来源:英特尔
2024 年是至强的大年。
先于 6 月正式发布的至强®️ 6700E 系列开启了全新的、更为简洁命名方式:至强®️ 6 能效核。144 核的规格也意味着英特尔在最近几年当中首次在核心数量方面实现了领先。而且,这还并不是至强 6 的最强形态,毕竟大家都知道还有个 6900P 系列嘛。
9 月 26 日,至强 6 这个“最强形态”终于正式发布,主要规格非常震撼。即使面对今年内晚于自己发布的其他厂商同级别 CPU,至强®️ 6900P 的已有规格也战力十足。
最强至强能有多强?
英特尔代号 Birch Stream 的新一代服务器平台所采用的至强 6 处理器是分批次发布的。6 月发布的是代号 Sierra Forest 的能效核处理器 6700E 系列(E 后缀即 Efficiency Core,能效核的标记),目前发布的是代号 Granite Rapids 的性能核 6900P 系列。今年底和明年初还会陆续发布 6900E、6700P,以及 6500/6300 等。未来的 Intel 18A 制造工艺的处理器,如 Clearwater Forest,也会继续用于 Birch Stream 平台。
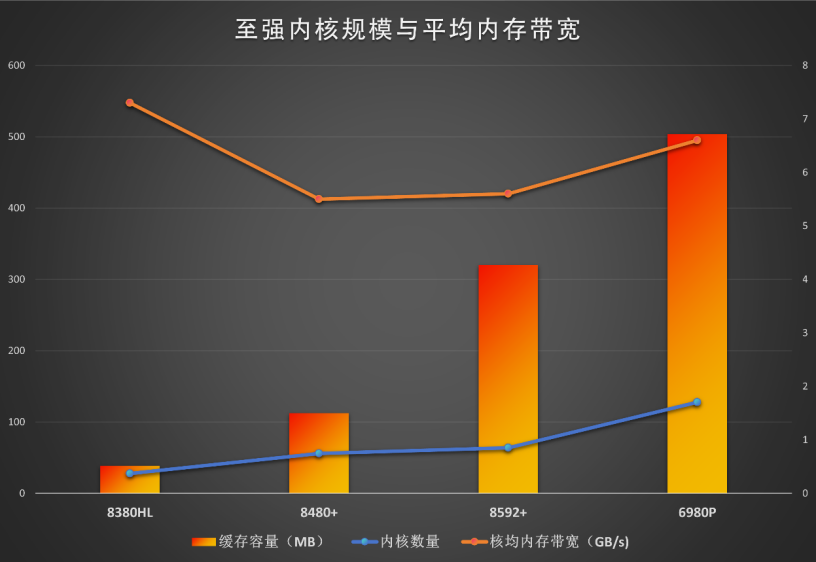
至强 6900P 是英特尔专为计算密集型工作负载设计的处理器,也是 Granite Rapids 的“完全体”。后缀的“P”意味其采用的是 Performance Core,即性能核,规模大、性能强;6900 的数字型号则说明其核心配置拉满——提供了 72 到 128 核的多种规格,TDP 有 400W 和 500W 两种,组合成已公开 5 种型号,显得比较简洁。当然,依照惯例,云厂商等大客户还会有若干定制型号的。单就内核数量而言,6900P 系列相对前两代“Rapids”产品线顶配的 56/60(Sapphire Rapids)或 64 核(Emerald Rapids)直接翻倍!如此巨大的迭代幅度非常罕见,也难怪英特尔要改命名方式了,由表及里都透着一个意思:厚积薄发、脱胎换骨!
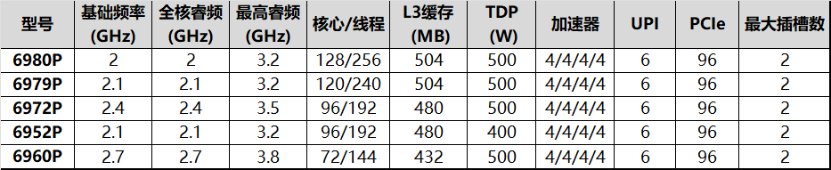
尤为值得一提的是:至强 6900P 也是业内首款性能核数量正式“破百”的产品,其他同级产品,不论是 x86 架构还是 Arm 架构都只达到了 96 核的水平。它们的性能核数量要追平英特尔,起码得等到下个季度。
随着内核规模增加,至强 6900P 的 L3 缓存达到了 504MB。为了配合倍增的核数和显著提升的算力,至强 6900 系列的存力也大为增强,内存带宽方面不仅支持 12 通道 DDR5 6400;并引入了新型内存 MR DIMM,把数据率大幅提升至 8800MT/s,基本内存带宽可以达到第五代至强可扩展处理器的 2.3 倍。另外,至强 6 还支持 CXL 2.0,尤其是包括 Type 3 设备(也就是 CXL 内存),可以进一步扩展内存容量和带宽。
至强 6900P 的 UPI2.0 链路也有很大改进,速率提升到 24GT/s,数量增加至 6 条,使得双路互联效率进一步提升。结合内核数量、内存带宽等方面的全面提升,至强 6900P 可以被视作高算力+高存力平台的最强机头,不论是科学计算,还是 AI 集群。根据已透露的测试,至强 6900P 平台的数据库、科学计算等关键应用负载的表现是上一代产品的 2.31 倍-2.5 倍,AI 应用性能是其 1.83 倍-2.4 倍不等。


至强 6 的扩展能力也有不小的提升。其中 6900 系列单插座不论是性能核还是能效核均可提供 96 通道 PCIe 5.0,双路即可提供 192 通道 PCIe 5.0。未来上市的 6700 系列单路型号可以提供 136 通道 PCIe 5.0,双/多路型号单插槽也可以提供 88 通道。相较而言,第四、五代至强可扩展处理器的 PCIe 5.0 通道数量为 80。CXL 支持能力方面,至强 6 6900、6700 系列都支持 64 通道 CXL 2.0。
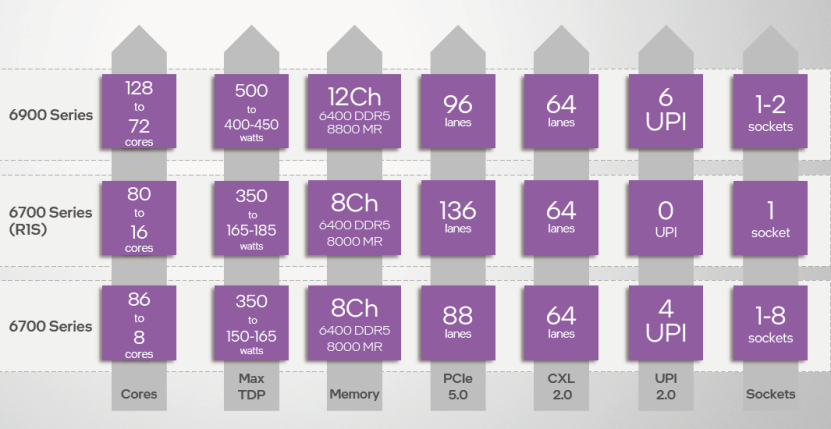
更多的内核、更多的内存通道、更多的 PCIe 通道需要更大规模的插座接口支持。 至强 6 带来了两种接口:LGA 4710 和 LGA 7529。至强 6900 系列使用面积较大的 LGA 7529 插座,提供最强大的内存带宽和扩展能力,是未来高性能、高密度服务器的基础。至强 6700 以及未来的 6500/6300 系列使用 LGA 4710,尺寸与第四、五代至强的 LGA 4677 相仿,内存、PCIe 的通道数相同或相近,有利于主流服务器内部布局习惯的延续性。
改进的 EUV:Intel 3
核心规模的飙升首先得益于至强产品线终于获得 EUV 光刻机的加持。在 2023 年发布的酷睿 Ultra 已经率先使用了引入 EUV 的 Intel 4 制造工艺。而 2024 年发布的至强 6 则使用了进一步改良的 Intel 3 制造工艺。
2021 年 7 月,英特尔 CEO 帕特·基尔辛格公布了“四年五个制程节点”(5N4Y)的工艺路线图。Intel 3 的量产时间节点位于 2023 年底,节奏基本符合计划。从基于 Intel 4 制造工艺的酷睿 Ultra 的市场表现看,EUV 的加持确实明显提升了英特尔处理器的竞争力。至强 6 所采用的 Intel 3 制造工艺相对 Intel 4 可以规划更多的金属层、拥有更多细分版本。
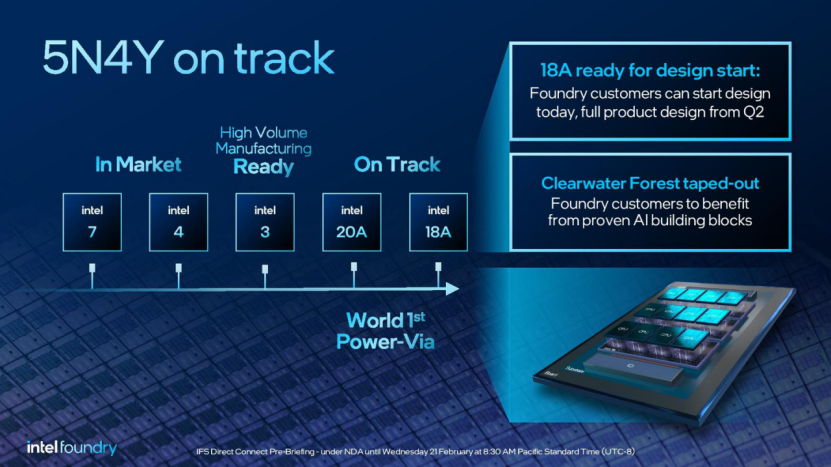
Intel 3 在更多的步骤中应用 EUV 光刻,可以提供更密集的设计库、更高的晶体管驱动电流。Intel 3 还有三种变体,包括 3-T、3-E 和 3-PT。Intel 3、3-T 是基本工艺,主要用于 CPU;3-E 是功能扩展;三者都支持 TSV;Intel 3 的这三种变体与 Intel 4 相比可以提升 18%的性能功耗比。而 3-PT 进一步增加混合键合的支持能力,带来了更高的性能并且易于使用。Intel 3 所有四种节点变体都支持 240 nm 高性能和 210 nm 高密度库,而 Intel 4 只支持 240 nm 高性能库。
对于性能取向,Intel 3 针对高性能运算进行优化,可以支持低电压(<0.65V)和高压(>1.3V)运行,且在各电压下的频率均高于 Intel 4。

微架构大迭代
至强 6900P 采用的性能核微架构代号 Redwood Cove。Redwood Cove 也是近年来英特尔最重要的微架构迭代,不但给服务器产品线带来了新名字,在消费类产品线同样开启了新的命名序列酷睿 Ultra。
我们先快速回顾一下 Redwood Cove 的上一代 Golden Cove/ Raptor Cove。Golden Cove 其实也是非常重要的迭代,在消费类开启了大小核时代(第 12 代酷睿处理器),在服务器上就是第四代至强可扩展处理器。Golden Cove 相对其前代的微架构大幅度提升了前端:
指令 TLB 翻倍,从 128 条增加到 256 条;
指令提取带宽从每周期 16 字节翻倍到 32 字节;
解码器从 4 路扩展到 6 路;
微操作缓存从 2304 条增加到 4096 条。
其他 L1 BTB、L2 BTB 等也有所提升。
Golden Cove 的后端当然也有提升,譬如重排序缓冲区、分支目标缓冲区也有大概 30%左右的提升,只是相对前端幅度不那么大。
Raptor Cove 的微架构与 Golden Cove 差异不大,表现在实际产品上主要是缓存的提升,如基于 Raptor Coved 的第 13 代酷睿(Raptor Lake)的每核心 L2 缓存从 12 代(Alder Lake)的 1.25MB 提升到 2MB;第五代至强可扩展处理器(Emerald Rapids)和第四代(Sapphire Rapids)每个核心的 L2 缓存都是 2MB,但前者每个网格的末级缓存(Last Level Cache,也可继续俗称为 L3 缓存)从后者的 1.875MB 猛增到 5MB。
Redwood Cove 相对 Golden Cove/ Raptor Cove 的最重要变化是:
指令缓存从 32KB 增加到了 16 路、64KB;
微操作队列从 144 个条目增加到 192 个条目;
指令执行延迟降低;
更智能的预取和改进的 BPU;
L2 缓存的带宽有所提升
AMX 增加 FP16 支持
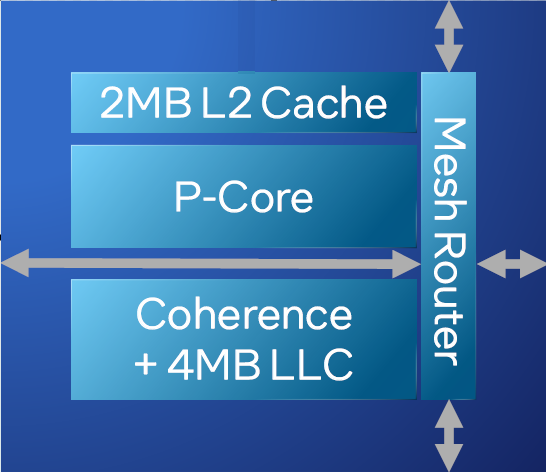
当然,Redwood Cove 还有一个重大的优势就是“命好”,也就是前面提到的 EUV 制造工艺。但即使有革命性的制造工艺加持,至强 6 性能核也没过分扩张每个内核的规模。就至强 6 性能核的内核而言,每个网格节点是一个 P 核,每个 P 核配置私有的 2MB L2 缓存,以及共享的 4MB 末级缓存。虽然平均到每个核的缓存容量并不比上一代至强(Emerald Rapids)多,但胜在总核数翻倍后。至强 6 性能核每个处理器可共享的末级缓存总容量依旧达到 504MB,远超第五代的 320MB 和第四代的 112.5MB。
在此也顺便提一下至强 6 能效核的微架构 Crestmont。这个微架构同样出现在了酷睿 Ultra 的能效核当中。Crestmont 是 2 或 4 个内核为一组共享 L2 缓存。在至强 6 能效核当中,每 2 或 4 个内核与 4MB 的 L2 缓存(在酷睿 Ultra 中则为 2MB)构成一个模块,这几个内核共享频率和电压域。这个模块对应的网格还拥有可整个处理器全部内核共享的 3MB 的末级缓存。换句话说,虽然至强 6 能效核的核数更多,但实际上网格规模比至强 6 性能核小。

能效核的指令缓存与性能核都是 64KB,但数据缓存分别是 32KB 和 48KB。前端的指令解码器宽度也有差异,分别为 6 和 8 宽。指令乱序执行引擎差异较大,能效核是 256 条而性能核是 512 条。能效核不支持性能核所支持的 AVX-512 和 AMX,这也可以明显减小矢量运算单元的晶体管占用,但代价是每周期的单精度浮点运算次数有了数量级的差异。但能效核也改进了 AVX2,增加了 VNNI 的 INT8 和 BF16/FP16 快速转换,这样在处理 AI 应用的时候表现也还有所改善。另外,其 256 位加密和 1024/2048 密钥也获得了能效核的支持,确保至强 6 平台的安全水平基本一致。

缓存规模、前端宽度以及矢量单元的差异,使得至强 6 性能核和能效核有不同的定位。早先发布的至强 6 能效核更适合微服务等运算强度相对较轻,可在高核心数量和规模扩展方面收益的任务,以追求更高的能效、更高的机架利用率。而现在发布的至强 6 性能核更适合大数据、建模仿真等计算密集型和人工智能任务,为高性能优化,单颗处理器的功耗直飚 500W——当然,跟同期发布的 Gaudi AI 加速器的新品或类似的加速器产品相比,能耗是应有的代价,有能力提升性能上限才是正经事。
内存性能大跃进
内存(DRAM)的数据存储依赖电容,这个特点使其微缩和提速的难度大于晶体管。因此内存并没有沾摩尔定律的光,带宽和密度的增长落后于 CPU、GPU 的发展。内存带宽滞后于 CPU 内核数量的增长导致一个长期问题:平均每个内核的内存带宽增长乏力,甚至出现倒退。譬如第三代至强可扩展处理器内核数 28,内存是八通道 DDR4 3200,理论上的内存总带宽为 205GB/s,平均每核 7.3GB/s;四代是 56 或 60 核,内存八通道 DDR5 4800,总带宽 307GB/s,平均每核 5.5GB/s;五代提升到 DDR5 5600,内核再增加到 64,平均带宽改进甚微。第四、五代至强可扩展处理器虽然引入了新一代的 DDR5 内存,但由于内核数量相对三代翻倍,内存带宽的增长幅度还是跟不上。同时期其他厂商的 CPU 核数在屡屡跃进的过程当中也存在同样的问题。为了弥补内存带宽增长较慢的问题,第四代至强可扩展处理器给部分用于科学计算的型号引入了 HBM,五代则大幅度增加了末级缓存的容量,并支持 CXL 2.0 内存扩展。
在至强 6900P 上,内存问题终于得到了比较好的解决。这涉及三个角度:
1、 大容量末级缓存。前面提到过,6900P 每个网格提供 4MB L3,总容量达到了 504MB,分别是四代的 4.5 倍、五代的 1.6 倍。而且,至强的全网格架构使得任意内核访问末级缓存的延迟相比其他厂商的一些产品有更优的表现,例如不需要跨计算单元而造成延迟剧增。这种架构效率更高的优势也是至强在核数曾落后的情况下还能打的有来有往的关键原因。
2、 DDR5 内存双管齐下提升带宽。至强 6900 系列支持 12 通道 DDR5 6400,总带宽可以达到 614GB/s,平均每核的带宽大致还有 5GB/s 的水平。6900P 还支持新型内存 MRDIMM,频率提升至 8800MT/s,总带宽达到了 845GB/s,平均每核 6.6GB/s,也明显超过了前两代产品,大幅度逆转了内核数量增加、平均内存带宽不升反降的问题。
MR(Multiplexed Rank)DIMM 打开了 DDR 内存性能提升的新方向。DRAM 通常由 1 到 2 个 Rank 组成,每个 Rank 的位宽为 64 位,如果考虑 ECC,那就会有 72 或 80 位,但有效的数据是 64 位。消费类内存(UDIMM)可能只有 1 个 Rank(颗粒数量较少的情况下),但追求大容量的服务器内存(RDIMM)基本上都至少有 2 个 Rank。在以往的内存模式当中,一次只读取一个 Rank 的数据,另一个 Rank 暂时闲置时可以做刷新操作,以保持数据——这种轮流读取、刷新 Rank 的特点延续了多年。MRDIMM 设计了一个数据缓冲区,通过将两个内存 Rank 分别读入这个缓冲区,再从缓冲区一次性传输到 CPU 的内存控制器,由此实现了带宽翻倍。第一代 DDR5 MRDIMM 的目标速率为 8800 MT/s,其实每个 Rank 只相当于 4400MT/s。现在 DDR5 6400 已经开始普及,因此 MR DIMM 的第二阶段目标是达到 12800 MT/s,预计在 2030 年代的三代会提升至 17600 MT/s。
3、 CXL 内存扩展。第四代至强可扩展处理器开始引入 CXL 支持,当时是 1.1 版本,暂时也没有公开支持 Type 3 设备(也就是 CXL 内存)。从第五代开始正式引入了 CXL 2.0,包括 Type 3,可以帮助扩展内存容量和带宽。在至强 6 上,CXL 设备的应用将更为普及,关键的 CXL2.0 标准设备,以及后向兼容的 CXL1.1 设备,预计都会陆续涌现。
这里重点说一下 CXL 内存的优势。CXL2.0 支持链路分叉,使一个主机端口可以对接多个设备,而且提供更强的 CXL 内存分层支持,可实现容量和带宽扩展。至强 6 支持 3 种 CXL 内存扩展模式:CXL Numa Node、CXL Hetero Interleaved、Flat Memory。

在 CXL Numa Node 模式下,系统的标准内存和 CXL 扩展内存被视为两个独立的 Numa 节点进行控制。每个 Numa 节点都有自己的内存地址空间,系统软件或应用程序可以将任务分配到不同的 Numa 节点,从而优化内存的使用。CXL Numa Node 模式适用于需要精细内存管理的应用,可以通过操作系统、虚拟机管理程序(Hypervisor)或应用程序本身来辅助分层管理内存。
Hetero Interleaved(异构交织)模式通过将系统的标准内存和 CXL 内存混合在一起,形成一个统一的 Numa 节点。每个内存地址空间中的数据可以交替存储在 DRAM 和 CXL 内存中,从而均衡内存带宽,减少延迟。异构交织模式适用于对内存带宽有高需求的应用,特别是当需要将 DRAM 和 CXL 内存结合使用时。此模式只有在配备性能核的至强 6700P、6900P 上才支持。假设将每颗至强 6900P 的 64 通道 CXL 用满,可以额外增加 256GB/s 的内存带宽,单处理器就可以实现 TB 级的内存带宽,还是相当可观的。
Flat Memory(平面内存)模式下,CXL 内存和标准内存被视为单一的内存层,操作系统可以直接访问统一的内存地址空间。硬件辅助的分层管理可以确保常用数据优先存储在标准内存中,次要数据存储在 CXL 内存中,从而最大限度地提升内存使用效率。平面内存模式最大的价值在于无需修改软件即可利用 CXL 内存扩展,而且这种模式适用于所有的至强 6 处理器。但平面内存模式要求标准内存和 CXL 内存是 1:1 配置,这略为限制了硬件采办、升级的灵活性。整体而言,平面内存模式是至强 6 时期最易用、收效最直观的模式,有望成为 CXL 内存扩展的主要模式。
踏上 Chiplet 异构之路
至强 6 是至强家族首次将计算和 IO 芯片独立,再通过 Chiplet 形式封装在一起,总算是把高级封装的优势真正发挥出来了。
第四代至强可扩展处理器是英特尔的首个 Chiplet 设计的至强处理器。其 XCC 版本内部是 4 颗芯片通过 10 组 EMIB 对等连接,每颗芯片提供 15 个内核、2 通道内存控制器、1 组加速单元,以及 UPI、PCIe PHY 若干。另外,还可以通过 EMIB 封装 4 颗 HBM。
第五代至强可扩展处理器使用 2 颗芯片封装而成,所使用的 EMIB 数量明显减少,相应地也节约了芯片面积。虽然内核数量略有增加,但也损失了 UPI、PCIe 的数量,也不再能够搭配 HBM。
随着制造工艺演进,偏重计算性能和晶体管密度的处理器内核,与偏重高速信号互联的 IO 控制器对制造工艺的要求产生了差异,因此,典型的 Chiplet 设计将计算和 IO 分离,分别应用不同的制造工艺。英特尔在 14 代酷睿上便采用了这种方式,分为 Compute Tile、SoC Tile、IO Tile、Graphic Tile。代号 Ponte Vecchio 的英特尔 Data Center GPU Max 利用 Foveros 和 EMIB 技术,将 47 个小芯片封装在一起,包括 Compute Die、Base Die、Rambo、IO Die 等。
至强 6 终于也拆分成计算单元(Compute Tile)和 IO 单元(IO Tile),分别由 Intel 3 和 Intel 7 工艺制造。
计算单元
根据收集到的信息,对于能效核,目前只出现了一种计算单元的设计,每个单元最多提供 144 个内核、4 组内存控制器共八通道;对于性能核,则是有三种计算单元的设计,可分别用于组合高核数、中等核数、低核数的规格。
至强 6900P 使用了三个计算单元,每个单元 43 个内核、两个内存控制器,总共构成 129 个内核(只使用 128 个)和 12 个内存通道。这种计算单元姑且称之为单元 A,三个单元 A 构成的处理器被称为 UCC。

未来发布的 6700P 核数跨度会很大,其中单路型号规划为 16~80 核,多路型号为 8~86 核。单元 A 有 4 个内存通道,两个单元 A 组合可以提供最高 86 核,下限应该不低于 48 核(否则屏蔽的内核数量就实在太多,也太浪费 EMIB 成本),这种规模的处理器被称为 XCC。48 核以下的中等核数被称为 HCC,使用一种专门开发的单元 B,每个单元提供 48 个内核和 4 个内存控制器。HCC 核数的下限预计在 24 核左右。8 和 16 核的 6700P 被称为 LCC,需要使用第三种单元 C,16 个内核和 4 个内存控制器。

通过使用 3 种计算单元进行组合,至强 6 性能核可以构建跨度从 8~128 核的、非常绵密的规格。也许会有人认为,相比其他厂商只用一种规格计算单元实现扩展的设计,英特尔需要设计三颗不同的芯片的成本会更高。但我认为,这是英特尔优先考虑性能的结果。首先,至强 6 将内存控制器安排在计算单元中,离内核更近,延迟更低,即使因此牺牲了单元组合使用的灵活性也是值得的。其次,至强 6 性能核给不同规模的内核数量规划不同的网格规模,有利于降低核间的延迟,甚至,有可能 LCC 会针对较低的核数改用环形总线。综上,预计至强 6 性能核相对同等规模的其他厂商的产品依旧可能会拥有内存延迟低、缓存延迟低的优势。
IO 单元
IO 单元方面,至强 6900、6700 系列都使用 2 颗相同的 IO 芯片。每个 IO 芯片由 2 个 IO 模块、4 个 UIO 模块、2 个加速器模块,以及 IO 网络接口构成。每个 IO 模块提供 x16 PCIe 或 CXL 连接;每个 UIO 模块提供 x24 UPI2.0,或复用为 x16 的 PCIe 或 CXL;每个加速器模块提供 DSA、IAA、QAT、DLB 加速器各一个。
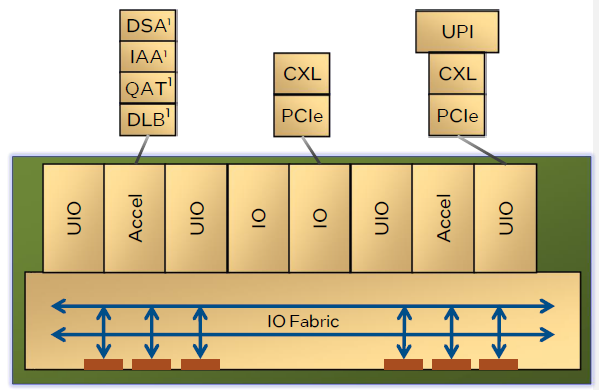
以这次发布的至强 6900P 为例,两个 IO 单元总共提供 8 个 UIO 和 4 个 IO 模块。其中 6 组 UIO 负责提供 6 个 UPI2.0 互连,剩余的 2 个 UIO 和 4 个 IO 模块正好提供 6×16=96 通道的 PCIe 5.0。双路至强 6900P 的 UPI 不但速率高(24GT/s,高于五代的 20GT/s 和四代的 16GT/s),连接数量也提升了 50%。
对于还未发布、也是主力产品的至强 6700 系列,估计由于要使用规模较小的插座,只提供最多 4 组 UPI 用于多路的互联,PCIe 通道也有所缩减。但即使如此,至强 6700 系列的单路型号在将所有 UIO 配置为 PCIe 之后,单插槽就可以提供多达 136 个 PCIe 通道,或 64 通道 CXL。如果用单路至强 6700 配合半宽主板构建双节点服务器,那一个机箱内的 PCIe/CXL 扩展能力(272 /128)远远超过已知的任何双路服务器。这种机箱可能会成为新的池化形态,可以更高的密度提供 NVMe 存储、CXL 内存、加速器等。
结语
由于英特尔在 14nm 到 10nm 制造工艺的迭代过程遇到了一些问题,以致此前几代至强平台在“核战”(比拼核数)中略显被动,但这个局面在至强 6 上有望完全逆转,改良后的 EUV 制造工艺看来没有束缚至强 6 的实力,核心数量、缓存容量、内存带宽等关键指标全都进入领先行列,一句话总结就是算力和存力的表现全部拉满。至强 6900P 系列在各种项目的测试当中,其代际性能提升就都是以倍数计,而非百分之十几、几十的进步。这种形势也使得英特尔得以全面竞争科学计算、大数据、AI 等领域的性能王座。
此外,至强 6 终于实现计算与 IO 的解耦,也让至强 6 及未来的产品线走上了正确、灵活的道路,得以充分发挥 Chiplet 的优势。将 Chiplet 视作降低成本、提高良率的手段是狭隘的。Chiplet 的价值在于灵活、复用、重构。英特尔长期以来很注重细分市场的耕耘,产品线非常复杂,正确利用 Chiplet 可以达到事半功倍的效果。我们非常期待至强 6 后续产品的陆续发布能够给业界带来什么样的想象力。




