
介绍
随着近年来直播、短视频、在线会议等音视频相关应用愈发普及,对用户体验的要求也随之提高。为了实现把声音和画面送达到用户面前就需要通过网络来分发,所以如何在各种网络环境下提高网络的效率,从而提高用户体验就变得很重要。如果使用基于 TCP 的协议来分发音视频数据,不能较大程度地满足用户体验上的需求,比如在直播场景下,播放快、卡顿少、延迟低等问题。我们可以通过减少建联时间,减少重传等手段来优化体验。所以基于 UDP 构建传输协议的需求越来越多,比如 quic , rtp 。其次随着云服务的兴起, golang 也逐渐在很多地方使用了起来。在我们直播 CDN 场景下,流媒体服务器需要承担较高的流量, golang+udp 这个组合在我们内部实践中会遇到性能不满足要求的情况,所以本文会分享如何提高用 golang 实现的基于 UDP 的传输协议的性能提升。
分析方法
早期,我们的流媒体服务器在基于 UDP 的可靠传输协议下,我们的服务器能承受的带宽远低于 TCP 几倍,导致了基于 UDP 的协议无法大面积应用。所以便有了着手提升相关性能的需求,主要是通过分析程序性能火焰图,操作系统各项指标(如锁,软中带,负载分布等)来确定性能低的原因。下面会介绍下常用的几个工具. pprof 是 golang 自带的一款性能分析工具,由于其相当的简单好用,所以不管是在性能分析,还是 bug 定位等场景出现的频率都很高。要是用 pprof ,比较简单的一个方法是通过引入net/http/pprof 包,会自动嵌入到默认 http 服务器里,如果服务没有 http 服务可以通过在 goroutine 里创建一个。

然后通过127.0.0.1:5601/debug/pprof这个地址就 可以获取到。当然 golang 也提供了可视化的工具,go tool pprof -http=:5555 http://127.0.0.1:5601/debug/pprof/profile 可以从网页里以火焰图的方式分析各部分开销占比,然后针对性的制定我们的优化方法。对于操作系统的一些开销,通过 pprof 我们是捕捉不到的,可能得借助一些其他的工具来分析。
比较常用的就是 top 、 perf 、 sar 、 ss 、 ethtool 等。
perf 可以比较方便的统计出比如 CPU 开销, cache miss 等。 top 可以比对分析进程和总 CPU 的占用,软中断等的占用。 sar 可以统计网卡 PPS 等。 ss 和 ethtool 可以用于诊断 socket 和网卡的一些信息。通过 pprof ,可以比较容易的得出 CPU 开销主要在内存分配,系统调用, runtime ,内存拷贝几部分。
下面会分享一些有用和没用的手段。
系统调用
mmsg
收发数据包的系统调用的占比比较大,这两个系统调用正好提供了在一次系统调用下收发多个包,极大的降低系统调用的数量级,所以用好这两个 API ,我们的性能就能有较大的提升了。

参数指定了要读取或者发送的数据包的数量,以及一些设置标志,接收还有个超时时间的参数,这个参数有点坑,后面会讲到。这两个系统调用其实是属于 recvmsg/sendmsg 的封装,大致类似于 for 循环里调用 sendmsg/recvmsg 。
sendmmsg
sendmmsg 的主要点在于如何聚合更多的包在一次系统调用中发送,可以选择把多个 session 的发送数据包进行聚合,那么聚合数量就可以大大提高。但是这样的话,会对质量有一定的影响,因为聚合的话可能得花一点时间来聚合足够多的数据包。
recvmmsg
socket ,属于 noneblock socket ,在 recvmmsg 的时候会出现读取到很少量的东西就返回了,因为当没有东西可读的时候会返回 EAGAIN ,会导致系统调用直接返回,需要等待一会。但是当使用自己创建的 block 的 socket 的时候,如果没制定 none block ,会出现未读满指定数量的包是不会返回的,即使设置了超时时间,导致前面的包一直得不到处理,这个情况下我们可以使用MSG_WAITFORONE这个 flag 。 在 CDN 场景下,主要是下行压力, recvmmsg 的主要特点在于可靠传输协议的 ack 数据包上。如果可以,我们可以考虑降低 ack 的数量比,从而减少 recvmmsg 的系统调用开销和中断开销。
效果
从给出的测试性能数据来看,在一次发送 64 个数据包的情况下能够提高 20% 的性能 **[1]** 。这个测试有一定局限性,在实际应用场景下提升还是远远超过这个值的。实际在服务器配置和网卡更好的情况下,首先可以提高 mmsg 的数量,达到 128 、 256 等。在协议栈应用上能提升一倍的效果。
GSO
GSO 的全称是( Generic Segmentation Offload ),他还有另外一个兄弟 GRO 。由于 MTU 的限制,所以对于 UDP 的写入,如果写入的数据超过 MTU 大小,且没有禁用 IP 分片,那么将会被进行 IP 分片,但是 IP 分片是不利于做可靠传输协议的,因为丢包成本太高了,丢一个 IP 包就等于丢了所有。前面我们提到减少系统调用,如果使用 GSO 的话也是可以的,我们可以一次写入更大的 buffer 来达到减少系统调用的目的,不过这个有个前提是每次需要写入的数据足够大,且对内核版本要求较高。另外 GSO 除了可以一次写入较大 buffer ,在支持的 GSO offload 的网卡还有相应的硬件加速,可以通过ethtool -K eth0 tx-udp-segmentation on来开启。
GSO 可以通过两种方式去使用,一种是设置 socket option 开启,一种是通过 oob 去对 msg 级别设置。 一般通过 oob 的方式去进行设置,因为这样比较灵活一些,缺点的话就是会多 copy 一点内存。
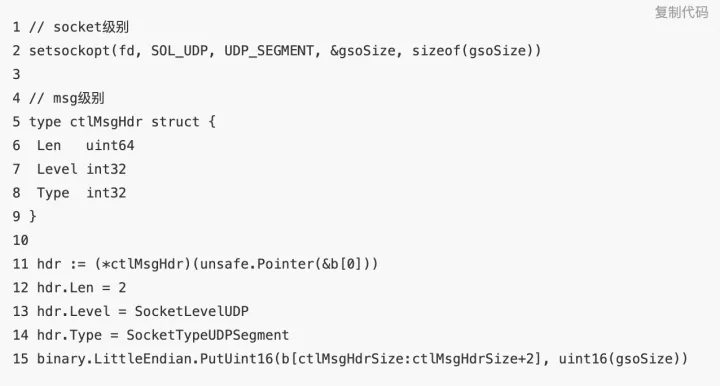
允许小于 64K 的 buffer 一次性写入且不会分片,会按照 gsoSize 进行分成多个 IP 包。根据 Google 的测试数据,性能提升能达到 1.7 倍左右 [2] 。不过在一次写入的数据量较少的情况下是比较难以利用起来的。比如直播的码率不高的情况下,单链接能写入的数据量是有限的。不过在码率较低的直播流,一次写入的数据较少的情况下 GSO 效果不是特别明显。在高码率下这个还是能带来很大的提升的,值得尝试。如果可以的话,也是可以聚合下多次的数据来提高 GSO 写入数据量。不过由于 GSO 是等分,所以在如何让每一个 UDP 包等大上比较麻烦。
内存分配
包相关的内存分配

比如像上面的 recvmmsg 系统调用,我们需要为本次系统调用准备内存空间, iovec 结构, msghdr 结构等等。对于一个几百万 PPS 的协议栈来说,上面的内存肯定不能每次都分配,我们必须得采取复用。对于 iovec 这样的结构,完全可以每次系统调用复用同一块内存,把对应的值 copy 过去就行。对于目的地址, oob 等,我们也可以与分配并存储在 session 的内存里,直接传他的地址就行。 oob 的话,可能每次传递的都不一样,我们可以准备多份,比如是否使用 GSO ,选择需要的那一份就行。像 golang 的 github.com/golang/net/… 提供的 recvmmsg API 的话由于没有处理内存分配的问题,所以不适合直接使用。数据包的 buffer 这个也是毋庸置疑需要复用的,简单点的场景我们可以使用 sync.Pool 。这个 buffer 我们可以和 sockaddr 、 oob 等的 buffer 复用同一片 buffer 。

其中 rawBuffer 是真正分配的内存区域。 Data 指向 rawBuffer 中数据包的位置, SockAddr 指向 rawBuffer 中相应的位置, Oob 同理。这样可以减少多次 sync.Pool 的调用和内存分配次数。
interface
在 golang 里, interface (指 empty interface )由下面的 struct 表示。

当把一个具体类型的变量转换为 interface 类型时,如果这个值是 copy 类型,那么需要给他分配空间然后拷贝过去,所以这是一个潜在的内存分配 case 。下面的代码展示把 64 位的整数转换到 interface ,最近的版本增加了优化,对于小于 256 的数字提前预分配好。

举个例子:
1 log.Debug(formats string, v ...interface)
像上面的那个 debug 的 log 函数,虽然在线上的日志级别不会执行,但是由于参数是 interface ,所以会涉及到类型转换,在大量出现调用的情况下就会有很大的内存分配开销。下面是一个简单场景测试,说明下问题。

测试结果

锁开销
在我们引入了一批 96C 的服务器后,发现性能并没有提升,反而有所下降。通过 perf top 可以发现__raw_caller_save___pv_queued_spin_unlock 和trigger_load_blance的 CPU 占用比较高。根据测试, 88 核机器和 44 核机器的服务能力差不多一致。所以可以认为 88 核机器改造成两台 44 核的性能提升能有一倍。推荐机器虚拟化/容器化为多个小核心数的机器或者多进程模式,这样能够更好的利用机器资源。包括对于两颗及以上 CPU 的机器,多进程分别绑定到每颗也能有较可观的提升,可以减少 CPU 间切换的代价。绑定可以通过 numactl 来进行控制。
zerocopy

UDP 的 ZEROCOPY 在 5.0 内核也支持上了, zerocopy 的 API 主要两部分组成,一个发送时声明使用 zerocopy ,另一个是接收内存可回收的回调。但是对于小数据包的 ZEROCOPY ,性能反而会负向,因为会多产生一次系统调用。并且在 UDP 下并不能在一次 MSG 里传送超过 MTU 的数据包,即使开启 GSO ,也不过 64K ,从 Google 给出的数据来看,有 13% 的提升 [3] 。根据我们的测试,在 GSO 数量较小的情况下,性能负向还挺多的。这个特性使用起来也有一定的复杂性,所以不建议使用,可以更多的考虑下 UIO 相关的技术。
RPS
我们接入了一批核心数比较高的虚拟机后,发现负载并没有上升。通过观察 CPU 负载,发现只有少数核心负载比较高。在查询资料后了解到这可能是网卡接收队列数和 CPU 核心数不匹配,导致接收队列的软中断都调用到前面的 CPU 核心上了。通过 ethtool 可以查看网卡队列的数量,如果和 CPU 核心数量不匹配,目前解决方法有两个,一个是要求机器的核心数和网卡队列要匹配;另一个较次一点的方案是配置 RPS , RPS 可以让一个队列绑定到指定的 CPU 核心上。这个实际上会带来一部分的额外 CPU 开销,因为他的实现原理是收到软中断后再分发到其他的 CPU 核心上,不过好处是可以把空置的 CPU 核心利用起来。 RPS 通过/sys/class/net/eth0/queues/rx-[n]/rps_cpus 这个文件来进行配置,文件内容代表每个网卡队列到 CPU 核心的映射关系,每一个二进制位为 1 代表可映射,以 16 进制字符串保存。
IO 模型
关键手段
reuseport
原生 socket
无锁队列
每个 CPU 一个处理循环
详细实现和效果
在做性能提升工作期间,也摸索了一些代码结构模型相关的东西。可以作为一个参考,每个项目自身不一样,所以并不一定适合。
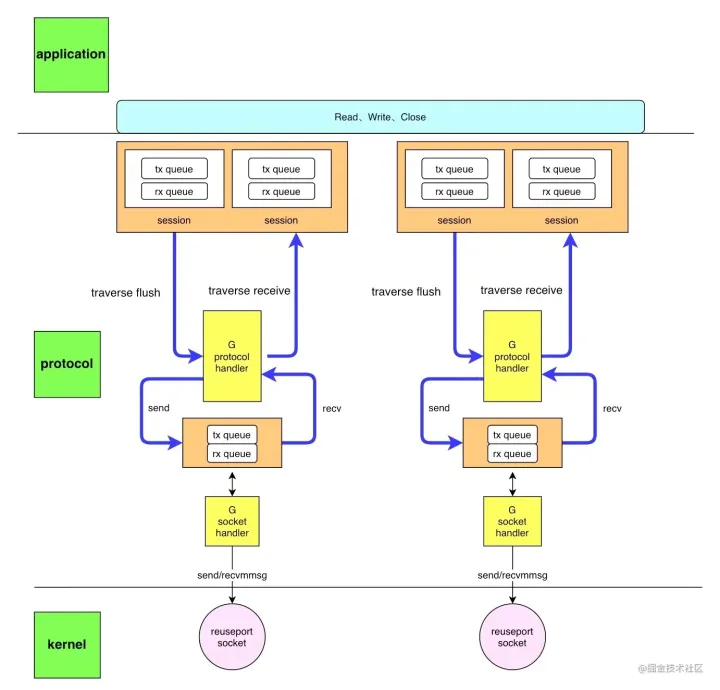
直接通过 syscall 创建 socket ,因为 golang 的 API 创建的 socket 是绑定了 epoll 的,在我们的场景下 socket 的数量是一定且少量的,不需要 IO 多路复用来提高吞吐,这样能够避免掉 epoll 带来的 CPU 开销。设置 socket 为非阻塞的,这样才可以在一个 goroutine 处理收和发。对于创建的 socket ,通过使用 reuseport 来负载均衡到所有 CPU 核心上,提高机器的利用率。现在的网卡一般都是多队列的,所以是能够做到分发到多个核心上的。分发策略一般通过
ethtool -N eth0 rx-flow-hash udp4 sdfn来设置,具体设置项可以参考 man page ,分发策略一般也是不需要动的。
goroutine 来处理链接。每个这样的 goroutine 处理一组链接的收包,发包,超时等,也可以比较方便的汇聚多个链接的数据调用一次系统调用。协议栈和应用层,数据包收发层通过无锁队列传递数据,采用这样的结构设计主要目的是为了减少 golang 调度的触发和锁的开销。 goroutine 的数量不随链接增加,也可以减少调度的压力。
前面两步的 goroutine 可以调用
runtime.LockOSThread把自己送入调度器全局队列来提高调度优先级,避免调度延迟。
总结
在用 golang 来实现的协议栈,性能问题可以分为两块:语言层面和系统层面。语言层面内存分配,和 rutime 的开销一般比较多。系统层面系统调用和锁的开销比较多。像开源的 quic-go 就会有这些问题,需要我们逐步去分析并解决。在 QUIC 和 HTTP3 的趋势下,内核在 UDP 方面的功能和性能相关工作也开始增多,相信也会有更多的方法来提高性能。不过个人觉得 Golang 确实不太适合在高性能,高调度精度等场景, GC 和内存分配的不可控性,与操作系统的抽象隔离也会在这些场景下限制发挥。现在服务器配置也越来越高,核心数量多,代码就容易出现锁竞争激烈的情况,导致额外开销大幅增加。所以容器化、虚拟化等技术把机器变为核心数较小的多实例模式也是很有价值的。
参考文献
[2] vger.kernel.org/lpc_net2018…




