

从 ChatGPT 发布以来,大家对大模型相关生态的关注急剧上升,本人也在过去的一段时间里深度参与了大模型相关的一些基础工作。众所周知,目前围绕大模型相关的开发仍然以 Python 编程语言为主,作为一个 Julia 编程语言爱好者,我一直在思考的一个问题是,大模型时代我们可以用 Julia 做什么?
本文是 “2023 InfoQ 年度技术盘点与展望” 系列文章之一,笔者将结合自己在大模型领域的开发经验和对 Julia 生态的理解,尝试从两个不同的角度来回答上述问题。首先,我们将大模型研发的过程拆解开来,逐点分析目前已有的做法和面临的挑战,探讨 Julia 在该方向上落地的潜在可能性;然后纵览 Julia 以及一些其它编程语言中大模型相关开发的生态,试图找出一条更适合 Julia 编程语言的发展道路。
训练基座模型
基座模型的训练所面临的挑战在于,超大规模的参数量。目前主流开源的模型参数量都在数十亿、数百亿乃至数千亿的规模。想要高效地训练如此大参数量的模型并非易事,目前开源界主流的训练框架是 ++Megatron-LM++,在其之上还有一些其它工具库提供开箱即用的训练脚本。Megatron 的核心功能主要包括:Tensor Parallel(TP)、Data Parallel(DP)、Pipeline Parallel(PP)等。
TensorParallel 要解决的核心问题是,如何在单卡无法放入整个 Tensor 的情况下,高效地做 Tensor 之间的计算。
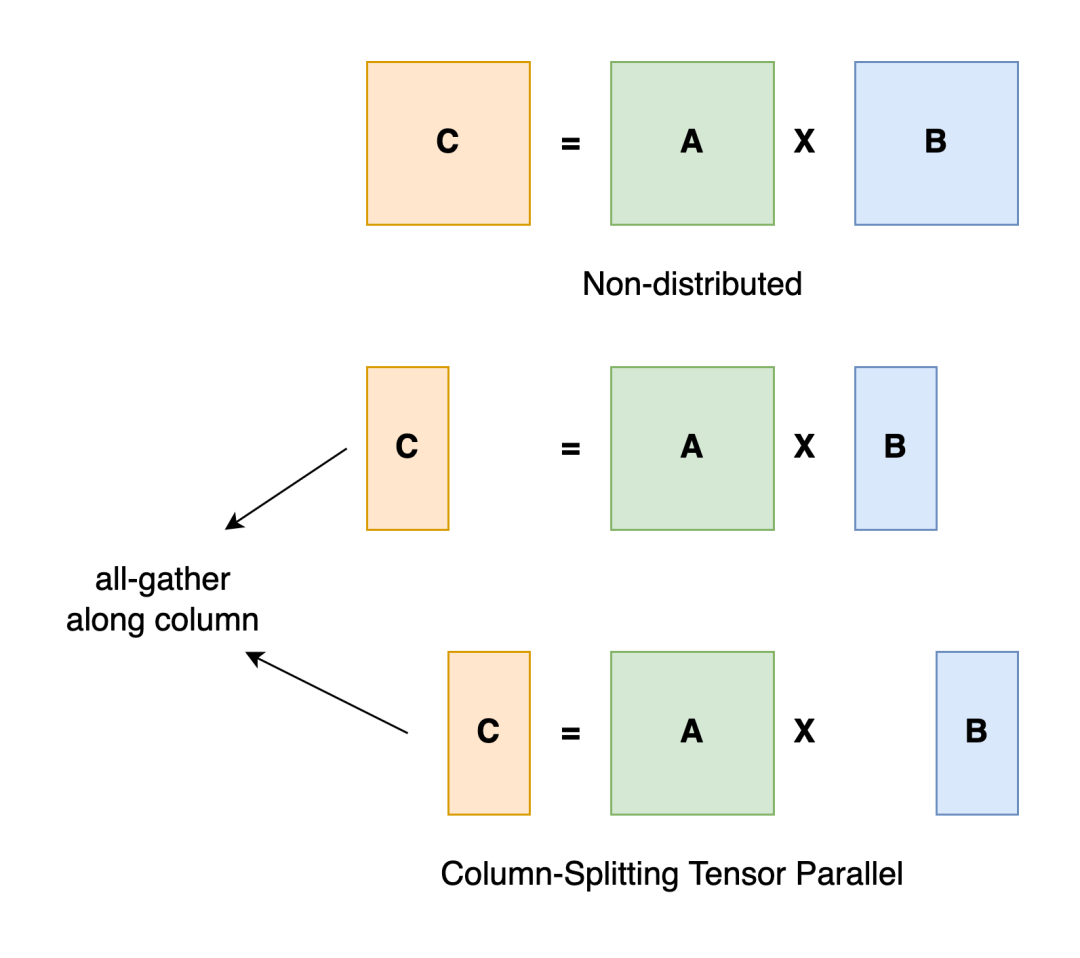
来源:https://colossalai.org/docs/concepts/paradigms_of_parallelism/#tensor-parallel
以矩阵相乘(A x B)为例,目前已有的做法是,将其中一个矩阵 B 拆分到不同的 GPU 卡上,然后执行分块矩阵的计算,最后合并计算结果。
在 Julia 语言中,类似的需求可以通过 DistributedArrays.jl 来实现,其封装好了一个 DArray 类型的结构,底层不同 worker 可以独立并行地做计算。
```juliausing DistributedArraysA = rand(1:100, (100,100))DA = distribute(A, procs = [1, 2], dist = [1,2])不过遗憾的是,该软件包并不支持 GPU 上的操作。在 Python 这边,GPU 上的通信操作通常依赖于 NCCL 的实现,首先需要执行类似 broadcast 的操作将 A 矩阵分配到各个节点上,完成计算后执行 all-gather 的操作将计算结果同步到每个节点。尽管目前在 CUDA.jl 的文档中有提到,如果想要实现单机多卡或者多级多卡之间的通信,可以借助一些基于 GPU 的 MPI 的实现,但目前仍缺少一些相关的实践。此外,另外一条可行的路径是,借助 Yggdrasial 中封装的 NCCL library,直接做多机多卡之间的通信,不论是基于 Distributed.jl 来实现还是独立再封装,具体实现上仍有不少工作,理想情况下,该工具库可以提供类似 torch.Distributed 的功能。
DP 的核心是将多份数据同时应用到模型的多个副本上,从而提升训练期间模型的吞吐量,缩短训练周期。该过程最核心的挑战在于降低同步多个副本之间参数的通信量。在 Megatron 中,有一系列工作来优化该步骤,其中最核心的一个组件是 DistributedOptimizer 。
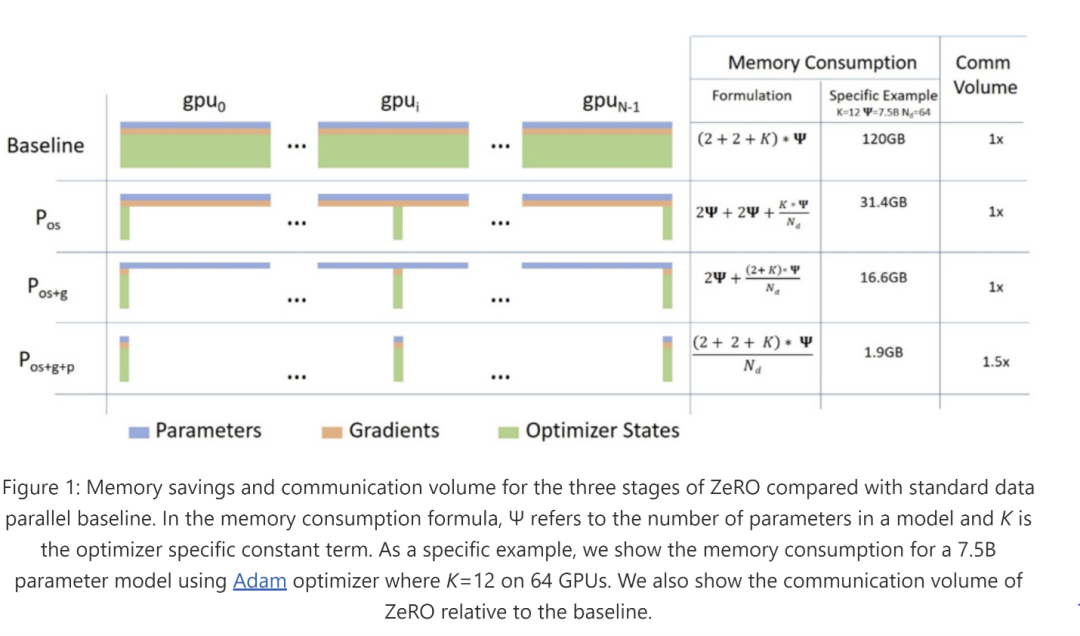
简单来讲,将 Optimizer 本身的参数,以及模型本身的参数和梯度等切分到不同的节点,再按需进行同步,可以大大降低模型优化过程中的通信成本。实现该优化器本身的难度并不大,但其前置条件(高效易用的 NCCL 实现)却是最大的障碍点。
值得一提的是,近来在 Flux.jl 之外,又多了一个 Lux.jl 选择,相比之下,其宣称的最大不同点在于“显式参数化”,在分布式优化场景下,这种特性具有其特殊的现实意义,即将参数展开之后,可以很容易地实现分片操作以及多机多卡之间的高效通信。
Fused Kernel
此外,在预训练(以及推理阶段),常见的一个优化手段是将几个算子做聚合,降低额外的显存开销并提升计算速度。最广为人知的是 Flash Attention 的实现,采用 C++ 显著地提升了 scaled dot production attention 的计算,然后通过 binding 提供给 Python 用户。在 Julia 这边,通常类似的操作我们会选择用 CUDA.jl 来实现,其优势在于一种语言即可完整地实现整个需求。对于一般的使用场景而言,确实如此。但在 Flash Attention 这类场景中,想要用纯 Julia 来实现出和 C++ 类似的效果,却是一件并不容易的事情,其原因在于,一方面,CUDA.jl 支持的指令落后一些,导致需要手动插入类似异步拷贝、扩展 WMMA 指令等操作,另一方面,细粒度优化导致最终实现出来的代码和 C++ 版的复杂度差异不大。不过,未来一个值得尝试的方向是,可以集成类似 OpenAI Triton 这类库,然后将 Python 或 Julia 作为前端语言,进一步优化此类操作的门槛。
混合精度计算
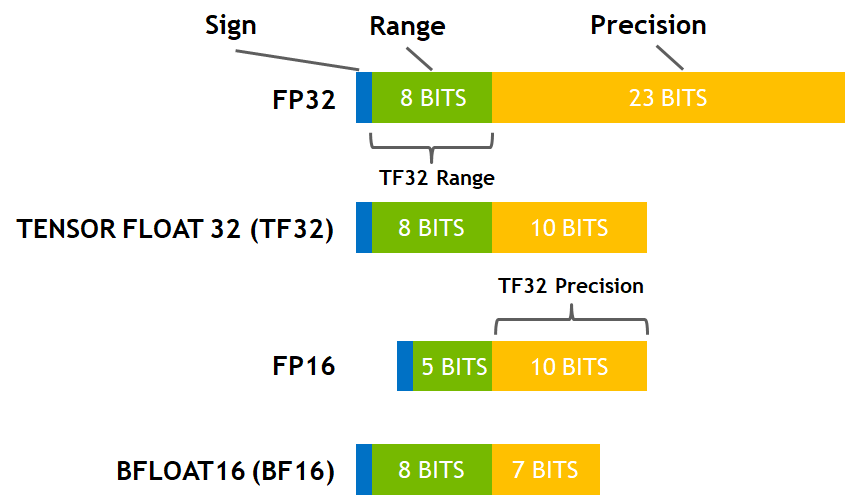
来源:https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/
为了降低显存的占用,提升计算效率,模型的权重、前向后向计算部分一般采用半精度的格式,而优化器的计算则会采用全精度。遗憾的是,在 Julia 这边想要实现混合精度的计算目前还是比较困难的一件事。类似 BF16/FP8 的支持还未实现,而想要使用该功能仍需等待 CUDA.jl 中的实现。
指令微调
从语言支持层面来讲,微调部分并没有引入额外的复杂度。目前指令微调的常见做法包括 SFT、DPO、RLHF 等,其中较为复杂的部分一环是 RLHF,完整的 RLHF 训练通常涉及到 4 个不同的模型组件之间协同操作,其最大的难点在于管理好多个模型在多机多卡上的调度以及相互之间训练数据的同步。
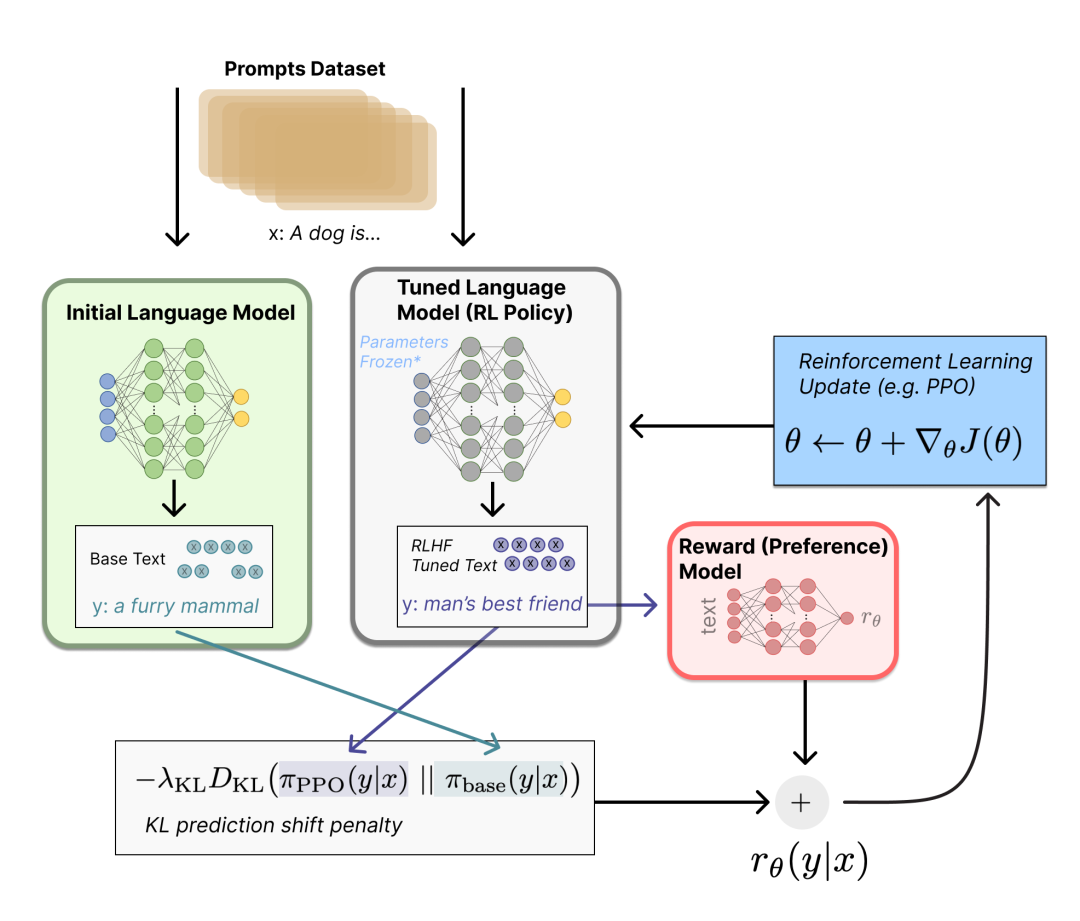
来源:https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/rlhf/rlhf.png
目前主流支持 RLHF 的库主要基于 Ray 来实现,借助 Ray 的资源调度能力和 Actor 之间高效的通信机制,可以在 Ray 之上实现大模型的微调。在 Julia 这边,单机版的 RL 算法(如 PPO 等)已经在 ReinforcementLeaning.jl 中有实现,但想要扩展到多机的版本仍有不少工作,其主要的工作量在于多节点之间的高效通信,若 NCCL 能与 Distributed.jl 完美集成,则分布式版 RLHF 的实现难度会大大降低。此外,为了降低训练期间对 GPU 资源的占用,有一些 PEFT (Permeter Efficient Fine-Tuning) 的相关工作也值得关注。
量化与部署
在量化方面,主流的两种算法是 GPTQ 和 AWQ。抛开其具体的实现细节,一个值得关注的点是,其高效实现仍有赖于底层 CUDA kernel 的实现。一方面,对已有模型的量化压缩是一次性的工作(除了一些在训练过程中做量化压缩的算法以外),另一方面,此类 CUDA kernel 的实现并非简单调用 CUDA.jl 即可完成,需要对底层指令有比较详细的了解,对于 Julia 开发者而言,并没有太多动力去从事相关的研发。
在部署方面,目前的主流仍然是 vllm ,想要在其它编程语言中想要完整实现类似的功能模块,会遇到和量化一样的困难。不过由于在私有化部署过程中往往在这块有一些个性化的需求,因此其它编程语言的开发者仍然有足够的动力通过对底层的 C++ 进行二次封装之后,在上层提供服务。
应 用
目前围绕大模型的应用层出不穷,从底层软件开发的角度来看,主要有两类,一类是围绕 Prompt 的实践,另一类是围绕大模型本地化部署及应用。
对于围绕 Prompt 的应用而言,其对编程语言的要求较低,更多地属于通用编程领域范畴。以 Python 中比较流行的库 LangChain 为例,其内置支持的多种复杂场景下使用大语言模型的基础工具库,对于 Julia 编程语言而言,由于其相关生态仍然有限,目前的主流的做法是通过类似 PythonCall 的工具库来实现调用。
此外,一个值得关注的细分领域是 Retrieval Augmented Generation,其核心在于借助向量检索等工具扩展上下文,主流的做法是将知识信息以向量的形式,存储到向量检索数据库中。Julia 在这一块有一些不错的向量检索工具库(如 SimilaritySearch.jl、HNSW.jl 等),虽然距离一个成熟的数据库还有一定距离,但仍然非常有潜力形成一套端到端的系统。
在大模型部署方面, Julia 对 GGML/GGUF 等格式的支持仍然有限,而这也进一步限制了桌面端应用的相关开发。目前,基于 Llama2 的架构,有一些不错的尝试,如 https://github.com/cafaxo/Llama2.jl ,对于个人开发者而言,是一个不错的起点来尝试和理解 Llama 架构。
此外,如果想要实际开发和接入目前 HuggingFace 上已有的大模型生态,则推荐大家基于 Transformers.jl 进行开发,目前这块经过多次迭代,已经能很好地支持一些主流的大语言模型,包括从 HuggingFace 的 load 和 save,本地的训练推理以及微调等。对于中小尺寸的模型,已经可以比较方便地利用其做一些原生的 Julia 相关应用开发。
其它编程语言中大模型相关生态
在主流的 Python 编程语言之外,目前发展较好的是 Rust,从最早基于 Rust 实现的 Tokenizer,再到近来有 HuggingFace 光环加持的 candle 等库,逐步涵盖了训练、推理、量化和部署等完整链路,可以看到其相关生态正在逐步形成。其整个链路对于 Julia 社区有很强的借鉴意义,即先从推理入手,然后丰富单机多卡的训练微调等任务,再在其之上构建完整的应用体系。
其它编程语言的生态目前主要以本地化部署和 Prompt Engineering 为主,比如由 Go 语言实现的工具 Ollama (https://github.com/jmorganca/ollama) 以及 LocalAI (https://github.com/mudler/LocalAI),凭借其易用性收获了大量的开发者和用户;以及 LocalAI (https://github.com/mudler/LocalAI),主打本地化部署,实现 OpenAI 的私有化平替;再如 Elixir 语言编写的 LangChain 类的工具 https://github.com/brainlid/langchain,提供 Elixir 语言下的大模型工具集成。
结论与展望
以下是本人在大模型领域观察到的一些趋势和预判:
在预训练领域,模型的结构越来越趋于统一,这主要是因为模型的探索成本较高。这对于其它小众编程语言而言,是一个利好消息,因为对于维护者而言可以重点支持某些特定的架构。
AutoTrain 等类似的工具会大幅降低微调大模型的门槛,成熟的算法会逐步沉淀到工具库中,而终端用户仅需关注数据层面。
基于纯 Julia 来实现完整的大模型训练还有很长的路要走,这一点可以参考 JAX 目前的发展,尽管 JAX 的生态已经要比 Julia 好很多,但目前在开源界仍然缺少成熟的应用。
基于纯 Julia 实现的应用层软件相比其它编程语言并没有压倒性优势,更需要关注如何与 Julia 领域已有的科学计算生态打通。
对于 Julia 编程语言爱好者而言,更务实的路线是,用好大模型(推理、部署) -> 改造大模型(微调) -> 训练大模型。Christopher 最近的一篇 blog 里通过详细的例子介绍了 ChatGPT 在许多编程问题上 Julia 的效果都明显好于其它语言,而我本人也在从事训练更好的 Julia 专用模型,期待后续能有更多内容可以和大家分享。
作者介绍:
田俊,Julia 编程语言爱好者,目前在零一万物从事大模型基础架构方面的工作
如果你觉得本文对你有帮助,或者你对编程语言在大模型时代的发展有自己的思考,欢迎在文末留言告诉我们!
InfoQ 2023 年度技术盘点与展望专题重磅上线!与 50+ 头部专家深度对话,探明 AIGC 创新浪潮下,重点领域技术演进脉络和行业落地思路,点击订阅/收藏内容专题,更多精彩文章持续更新 ing~
另,InfoQ 年度展望系列直播将于 2024 年 1 月 2 日首场开播,持续输出精彩内容,关注 InfoQ 视频号,与行业技术大牛连麦~





{kind=link}