
随着数字化进程的加速,数据处理的规模和速度需求持续攀升。传统数据库系统在处理大规模数据时,存在单表记录数不超过 500 万条的限制,这已成为业务发展的瓶颈。为了解决此问题,分布式数据库通过横向扩展来分担单节点的压力。然而,随着数据规模的增长,数据库节点的数量也会增加,这会导致成倍增长的运维问题和对 IT 运维工作的需求。
同时,移动互联网、智能设备、汽车和物联网终端的发展,对并发访问和响应时间提出了更高的要求。现有的解决方案通常基于独立的内存缓存来满足热点数据的读写需求,然而由于缓存容量有限且热点数据不在数据库中,导致无法参与统计分析,数据的价值没有得到充分利用,仍然存在优化空间。
除此之外,随着大数据应用场景的快速普及与创新业务的发展,传统的数据管理方案已愈发难以满足海量数据实时分析的需求。实时应用、高通量在线交易和实时分析等混合负载的场景成为业务的基本诉求。
面临这些新的挑战,我们认为有以下三个核心命题要去回答:
如何在不消耗大量算力资源的情况下,低成本地满足海量数据的计算要求?
如何设计一个高效、易用的数据库系统来满足不同的业务诉求?
如何避免差异化实现,高效构建一个统一行列存、混合负载的架构?
本文将从理论和工程两方面分享由“0”构建全自研数据库系统 YashanDB 的设计理念与背后思考,并试图回答上述的几个关键问题,与大家共同探讨面向未来数据库技术创新之道。
有界理论打破大数据算力增长挑战
关系代数理论诞生于上世纪 80 年代,为关系数据库系统奠定了基础。但是随着数据规模的不断增长,传统的数据库无法解决的问题越来越多。
因此,人们重新定义了大数据及其基于并行计算的解决方案。这种方案的核心理念是通过大量的计算资源来满足数据的计算需求。然而,计算资源的增长速度远远跟不上数据的增长速度,同时,数据库节点数量和运维复杂度也呈指数级增长,这成为大数据处理所面临的一项关键挑战。
但通过观察具体业务不难发现一个现象,绝大部分查询涉及的数据量与全量数据相比是微乎其微的,如果能针对查询找出一个特定的,包含所有正确结果的小数据集,那么就可以节省大部分针对无关数据的扫描和计算开销,这正是有界计算的出发点。
有界计算的关键挑战是如何避免数据扫描而找出查询相关的小数据集。首先需定义一个概念为“访问约束”,其意义为对于特定的 X 取值,其对应的 Y 的取值有且仅有 N 种可能,这里的 N 可理解为通过已知的 X 找到对应 Y 的边界。例如在知道某位同学对应班级的前提下,这位同学的 ID 取值不可能超过班级最大人数。
这种属性之间的语义在关系理论中并没有被识别和利用,下面我们通过一个简单的例子看下如何运用访问约束来解决查询问题,直观感受有界计算与传统方法的差异:我们想找出 2019 年 5 月份我朋友在 NYC 去过的餐馆的价位。
按传统方式需要将朋友关系表 friend 和就餐表 dine 进行连结后再通过餐馆信息表 cafe 找出其价格,但这样就涉及大量数据扫描和连结计算开销巨大,即使使用索引替代全表扫描也会因为随机 IO 使得提升有限。
而有界计算通过特定属性间的访问约束(Access Constraint),仅需要访问三个有限的小数据集,避免了大量无关数据之间的计算。
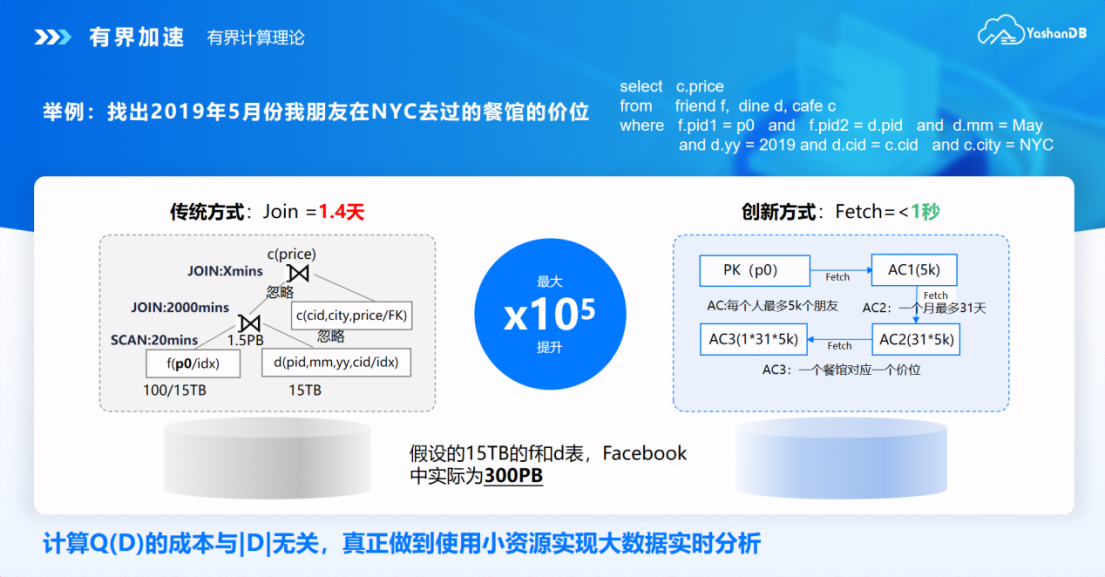
例子中提到的访问约束是基于 YashanDB 列式存储引擎实现的。将特定 X 取值对应的 Y 连续存储,可以基于轻量化算法实现去重和压缩,并在计算时还原原始取值确保语义完整。用户执行查询时优化器根据已有访问约束判断能否实现查询加速,无需人工干预或修改 SQL 语句。与此同时,访问约束也不是一成不变的,对于持续变化的业务数据,可以在业务运行过程中不断刷新已有访问约束,我们发现其维护成本远低于物化视图。
有界计算适用于记录中存在大量重复信息的详单分析场景,其原型实现已在电信详单管理和北美航空记录分析两个真实场景中完成验证,最大加速效果可达到 100000 倍。基于有界计算可以大大降低大数据分析的算力要求,拓展数据库系统的能力边界。该理论也获得了 2018 年的 Royal Society Wolfson Research Merit Award(英国皇家学会沃夫森研究优秀奖)。
自主技术架构:面向混合负载的存储与 SQL 技术
随着通信和互联网技术的不断发展,业务对数据管理的实时性要求持续提升。传统数据库受制于软硬件处理能力限制,将交易型操作和分析型查询分而治之,带来了数据分析的滞后性和数据库运维上的复杂性。
对于新型业务而言更强调混合负载实时数据管理的能力,这也需要数据库系统在存储引擎到 SQL 引擎上采用新的技术与架构。下面我们将详细介绍 YashanDB 如何从混合存储及 SQL 执行两方面实现混合负载能力的。
混合引擎架构
为了兼顾高并发数据访问和实时数据分析两类截然不同的需求,YashanDB 在存储架构上大胆尝试多种数据组织形式。
首先是支持面向高并发短事务的行式存储,简称行表(Heap),将一条记录的多个字段连续存储在一起。而作为存储的最小单元,同一个数据块上存储了多条完整记录和对应事务信息,这种方式可以最小化数据访问的开销,并通过支持原地更新进一步降低数据修改的管理成本。
另一方面,为了管理海量数据并支持实时分析,YashanDB 还支持冷热分离的列式存储,简称列表(LSC, Large-scale Storage Columnar Table)。与行表最大的差异是,列表将不同记录的相同字段连续存储在一起。由于大部分查询仅用到记录中的部分字段,因此按字段连续存储可以避免整行读取,从而提高 IO 资源利用率。与此同时,同一字段存在重复取值,基于轻量化压缩算法可实现存储空间的成倍缩减。列表相较行表对于写入不太友好,因为一条记录写入可能要访问多个数据块,造成大量 Cache Miss 和额外 IO。
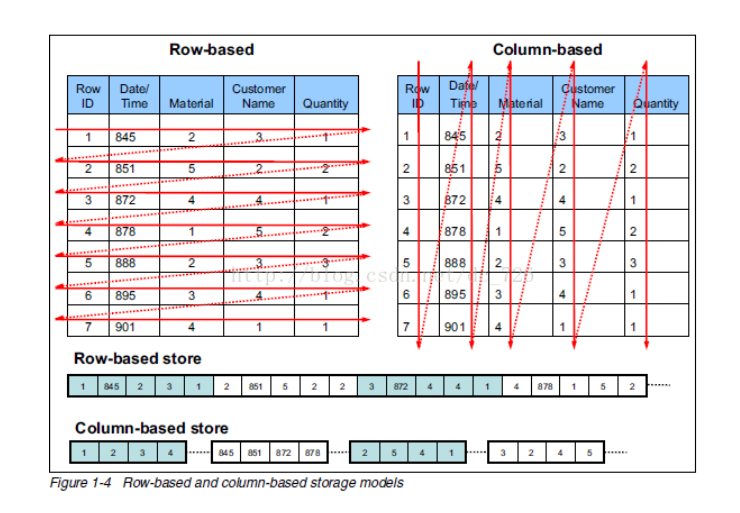
值得一提的是,存储引擎的能力不仅是数据组织与管理,还包括事务、持久化等。YashanDB 对于上述两类数据组织均提供完整事务和持久化能力,使得针对快速变化数据的高性能分析不再高不可攀。
业界在实现行列混合存储方面仍存在一定的优化空间:采用读写存储的内部转换,为了避免数据变化对列存储数据的影响,需要预留数据量两倍的内存空间;如按副本方式分别管理 TP 和 AP 数据,虽然可以在资源上进行隔离,但引入了数据转化的延迟与开销。
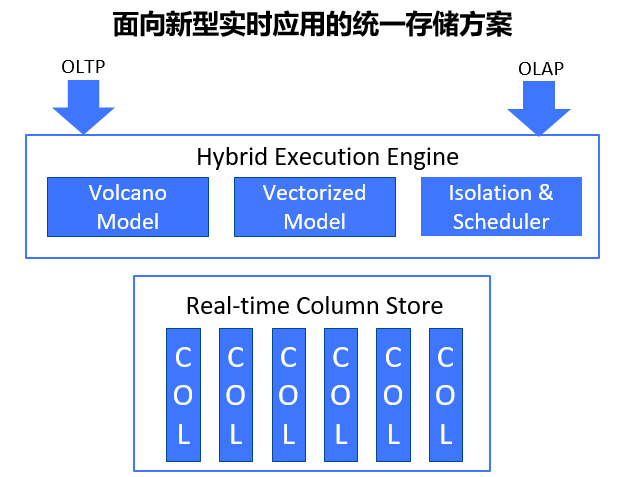
YashanDB 提出了一份数据上的混合负载能力,在保证完成 ACID 能力的前提下,提供可更新列存数据存储,通过不同的 SQL 执行引擎来同时实现高通量事务处理和低时延复杂查询。其架构如下图所示,主要差异在于数据仅保存一份,所有已提交的变更都可以通过查询反映到结果集中。这里面包含了三个技术点:
支持快速更新和查询的列式存储组织,通过 In-place Update 解决数据变更导致的空间膨胀和无效数据回收问题;
面向交易和分析负载的差异化需求,通过不同执行模型最大化资源利用率,火山模型支持低时延短事务,向量化模型支持全面扫描数据分析;
细粒度配置的资源与调度管理,避免不同类型处理之间的资源争抢和固定配置带来的资源闲置,会话级配置结合业务特征灵活调整。
SQL 引擎设计与关键优化
对于 SQL 引擎而言,优化器和执行器对查询性能的影响最为显著。而优化器的复杂度取决于执行器有多少种不同的算子,每种算子代表了一种可能的访问路径。特定算子之间可以根据规则进行优化。
YashanDB 的 SQL 引擎为了达到极致性能,同时支持了行列两类算子分别满足低时延短事务和大数据量查询场景的差异化需求。因此优化器的实现挑战要高于传统数据库系统。这里列举了我们实现的三个关键能力:
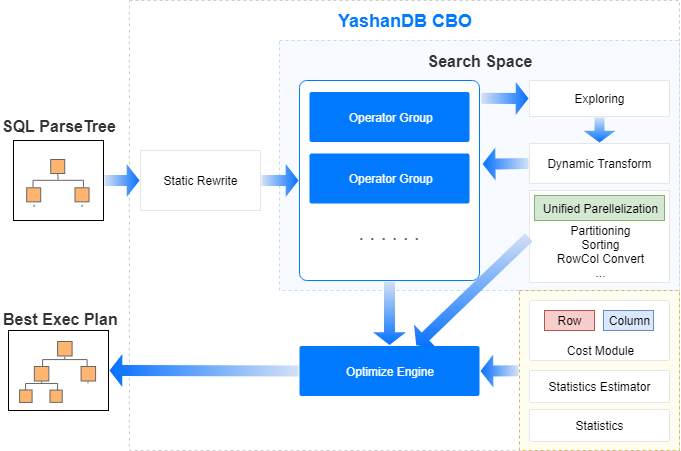
面向差异化代价模型的行列混合评估。针对行列算子建立独立的代码模型,在最优计划选择时考虑行转列或列转行的整体代价,并结合启发式算法提前排除不理想的备选计划,避免搜索空间过大问题。
行列统一的并行优化框架。并行计算是 YashanDB 高性能查询重要的能力,而针对行列算子使用一套并行框架也能大大降低优化器的复杂度,避免大量访问路径需要根据算子类型进行差异化实现。这套框架的并行执行单位为 Pipeline,能够支持单算子的并行,在不同 Pipeline 之间需要通过 PX 算子进行数据的交换,PX 算子可以适用于单机和分布式两种场景下的不同交换策略。
面向特定模型的动态优化规则。行列统一是 YashanDB 的架构目标,但在具体工程实现过程中由于算子实现难度各异,需要针对行列算子按照特殊规则进行调整。为了避免这类优化影响优化器基本框架,因此 YashanDB 优化器先生成不区分行列的通用计划,再执行前根据行列算子的特点进行动态优化调整。这其中包括部分列算子未实现的内置函数,都可以动态转为行算子来计算,同时提升了优化器的可维护性。
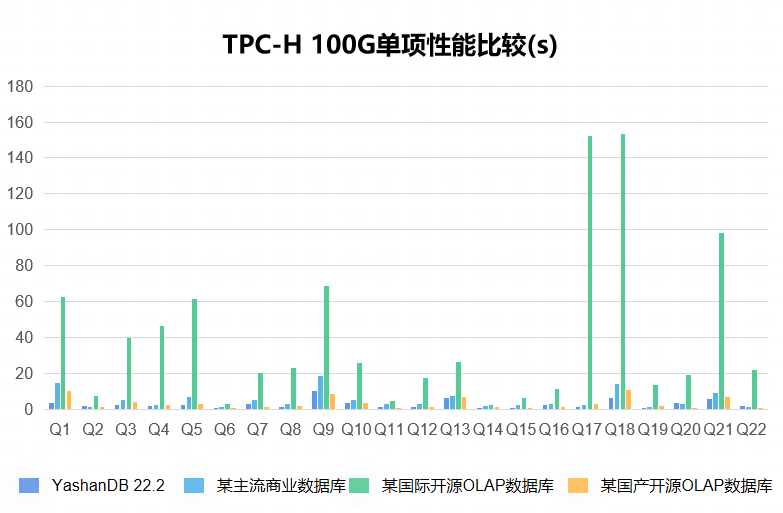
硬件配置:2288 虚拟机(16 核,160G 内存,3.4T SSD)
软件版本:OS(CentOS 7),DB(YashanDB 22.2)
测试模型:TPC-H 100G 数据
总体来说,SQL 引擎的整体性能和架构的持续演进非常重要,而优化器作为关键能力,需要充分发挥各执行算子的优势,并减少差异化规则带来的实现复杂性。我们正在探索基于深度学习的查询优化,但目前面临冷启动和假阳性等挑战。
深度兼容性和一键业务迁移
作为一款面向企业用户的新型全自研数据库系统,YashanDB 需要考虑用户在切换到该系统时所面临的挑战:一方面是业务系统需要改造以适应新的数据库系统,另一方面是数据搬迁过程如何实现平滑可控。
改造成本
首先是改造成本,这主要是由于新老数据库在 SQL 语法 / 数据类型 / 存储过程等方面存在差异导致的。YashanDB 从设计之初就确定了 Oracle 全面兼容的目标,这里的全面不止包含 SQL 语法 / 语义、各类数据类型的处理差异,还包括复杂存储过程,触发器以及系统视图等高级能力。另外,我们还考虑到了资深 DBA 习惯使用的一系列运维工具的支持,如 AWR 和 RMAN 等。在对 Oracle 的兼容性设计中,每一个细节都需要反复论证和推敲,避免全盘照搬导致泥沙俱下,以下是一个 Oracle 的例子。
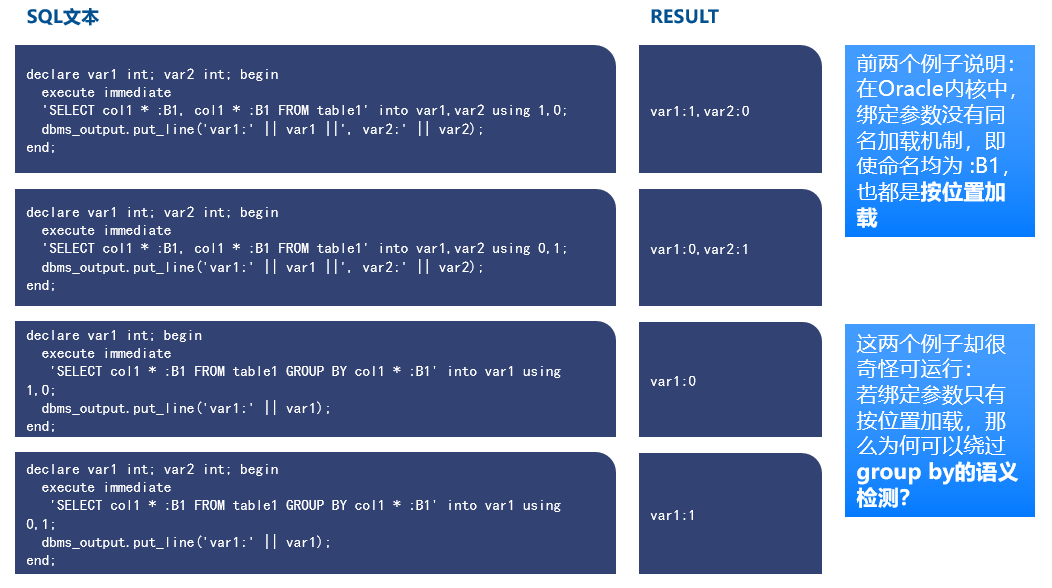
前两条语句结果证明在 Oracle 内核中,绑定参数没有同名加载机制,即使命名均为:B1,也都是按位置加载. 最后一条语句可以运行即证明并非所有场景都是按位置加载,猜测 Oracle 为了避免存储过程无法使用 GROUP BY 语句,对按位置加载的绑定参数原则,做了特殊“优化”,这类“优化”在语义表达上会让用户困惑。
数据迁移
其次是数据迁移。数据迁移的目标不仅仅是简单的数据导入 / 导出,而是基于业务设计的全自动化处理。YashanDB 的自动化迁移平台具备业务兼容性评估、一键数据迁移和数据完整性校验等功能。
业务兼容性评估为迁移计划提供必要的输入,识别当前数据库系统无法兼容的对象和 SQL 语句,并给出改造建议;
一键数据迁移可以满足存量数据搬迁和实时增量同步两类需求,目前支持 Oracle/MySQL/PostgreSQL 数据库系统;
数据完整性校验可以避免数据迁移在异常情况下的数据丢失 / 错误,自动识别并可在人工指导下自动修补错失数据,从而大大提升迁移的可靠性。
写在最后
随着数据规模的爆发式增长,我们创新性地将有界计算理论转化系统能力,在不消耗大量算力资源的情况下能够低成本地满足海量数据的计算要求。
同时随着数字化转型的持续深入, 很多客户都提出了数据驱动的实时业务决策,这要求数据库能够满足混合负载,兼顾高通量数据变更和实时查询,因此我们设计了一套统一行列存、混合负载的架构。同时充分考虑用户在切换到该系统时所面临的挑战,实现了高度的商业数据库兼容性,极大地降低了应用改造迁移成本。
当然我们不仅要考虑当前的需求,还要为未来的需求做好准备。那随着 AI 等技术的快速发展,我们认为智能化机遇将会给数据库带来重大变革:
首先,面向大模型场景,数据库管理的对象已经不再是关系表,而是 Embeddings 向量,这类对象的计算方式更复杂,且具有不可解释性,前景非常广阔。另一方面,机器学习也可以将传统数据库调优这类只有资深 DBA 才能搞定的任务变成固定的模型,大大降低了数据库的运维门槛;此外,NLP2SQL 在大模型的赋能下让更多用户可以使用大数据分析。
未来,我们将持续探索更多创新技术的可行性和落地方案,拓宽数据库应用的广度和深度,为更多企业的数字化转型提供有力支撑。
作者介绍
欧伟杰,武汉大学博士,深圳计算科学研究院 YashanDB 研发总监。10 年以上数据库内核设计与开发经验,多篇顶级会议论文及技术专利。作为创始成员之一加入 YashanDB 团队,负责 YashanDB 的架构设计与内核研发,从零到一打造全自研数据库产品在多行业落地应用。
活动推荐:FCon 金融科技大会
FCon 金融科技大将于 2023 年 11 月 19-20 日在上海举办!会议上设置了金融行业数字化转型挑战、基于大数据和 AI 的风控系统建设、大模型在金融行业的应用、人才培养等专题。已经邀请的嘉宾包括工商银行、光大银行、汇丰银行、富滇银行、蚂蚁集团等企业的专家。
现在购票,前 100 人可享 5 折特惠购票,咨询购票请联系:17310043226(微信同手机号)。





