今年,大数据在很多公司都成为相关话题。虽然没有一个标准的定义来解释何为 “大数据”,但在处理大数据上,Hadoop 已经成为事实上的标准。IBM、Oracle、SAP、甚至 Microsoft 等几乎所有的大型软件提供商都采用了 Hadoop。然而,当你已经决定要使用 Hadoop 来处理大数据时,首先碰到的问题就是如何开始以及选择哪一种产品。你有多种选择来安装 Hadoop 的一个版本并实现大数据处理。本文讨论了不同的选择,并推荐了每种选择的适用场合。
Hadoop 平台的多种选择
下图展示了 Hadoop 平台的多种选择。你可以只安装 Apache 发布版本,或从不同提供商所提供的几个发行版本中选择一个,或决定使用某个大数据套件。每个发行版本都包含有Apache Hadoop,而几乎每个大数据套件都包含或使用了一个发行版本,理解这一点是很重要的。
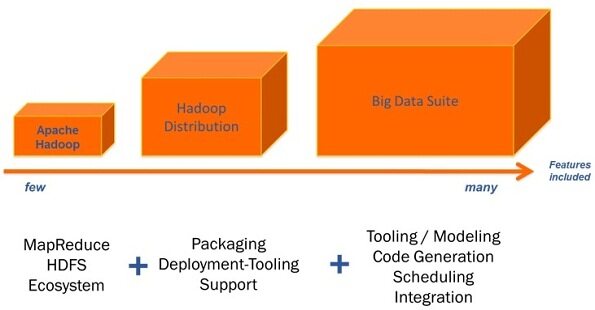
下面我们首先从Apache Hadoop 开始来好好看看每种选择。
Apache Hadoop
Apache Hadoop 项目的目前版本(2.0 版)含有以下模块:
- Hadoop**** 通用模块:支持其他 Hadoop 模块的通用工具集。
- Hadoop分布式文件系统(HDFS):支持对应用数据高吞吐量访问的分布式文件系统。
- Hadoop YARN:用于作业调度和集群资源管理的框架。
- Hadoop MapReduce:基于 YARN 的大数据并行处理系统。
在本地系统上独立安装 Apache Hadoop 是非常容易的(只需解压缩并设置某些环境变量,然后就可以开始使用了)。但是这只合适于入门和做一些基本的教程学习。
如果你想在一个或多个“真正的节点”上安装 Apache Hadoop,那就复杂多了。
问题 1:复杂的集群设置
你可以使用伪分布式模式在单个节点上模拟多节点的安装。你可以在单台服务器上模拟在多台不同服务器上的安装。就算是在该模式下,你也要做大量的配置工作。如果你想设置一个由几个节点组成的集群,毫无疑问,该过程就变得更为复杂了。要是你是一个新手管理员,那么你就不得不在用户权限、访问权限等诸如此类的问题中痛苦挣扎。
问题 2: Hadoop 生态系统的使用
在 Apache 中,所有项目之间都是相互独立的。这是很好的一点!不过 Hadoop 生态系统除了包含 Hadoop 外,还包含了很多其他 Apache 项目:
- Pig:分析大数据集的一个平台,该平台由一种表达数据分析程序的高级语言和对这些程序进行评估的基础设施一起组成。
- Hive:用于 Hadoop 的一个数据仓库系统,它提供了类似于 SQL 的查询语言,通过使用该语言,可以方便地进行数据汇总,特定查询以及分析存放在 Hadoop 兼容文件系统中的大数据。
- Hbase:一种分布的、可伸缩的、大数据储存库,支持随机、实时读 / 写访问。
- Sqoop:为高效传输批量数据而设计的一种工具,其用于 Apache Hadoop 和结构化数据储存库如关系数据库之间的数据传输。
- Flume:一种分布式的、可靠的、可用的服务,其用于高效地搜集、汇总、移动大量日志数据。
- ZooKeeper:一种集中服务,其用于维护配置信息,命名,提供分布式同步,以及提供分组服务。
- 还有其他一些项目。
你需要安装这些项目,并手动地将它们集成到 Hadoop 中。
你需要自己留意不同的版本和发布版本。不幸的是,不是所有的版本都能在一起完美地运行起来。你要自己比较发布说明并找出解决之道。Hadoop 提供了众多的不同版本、分支、特性等等。跟你从其他项目了解的 1.0、1.1、2.0 这些版本号不同,Hadoop 的版本可远没这么简单。如果你想更进一步了解关于“Hadoop 版本地狱”的细节,请阅读“大象的家谱(Genealogy of elephants)”一文。
问题3:商业支持
Apache Hadoop 只是一个开源项目。这当然有很多益处。你可以访问和更改源码。实际上有些公司使用并扩展了基础代码,还添加了新的特性。很多讨论、文章、博客和邮件列表中都提供了大量信息。
然而,真正的问题是如何获取像 Apache Hadoop 这样的开源项目的商业支持。公司通常只是为自己的产品提供支持,而不会为开源项目提供支持(不光是 Hadoop 项目,所有开源项目都面临这样的问题)。
何时使用 Apache Hadoop
由于在本地系统上,只需 10 分钟左右就可完成其独立安装,所以 Apache Hadoop 很适合于第一次尝试。你可以试试 WordCount 示例(这是 Hadoop 的“hello world”示例),并浏览部分 MapReduce 的 Java 代码 。
如果你并不想使用一个“真正的”Hadoop 发行版本(请看下一节)的话,那么选择 Apache Hadoop 也是正确的。然而,我没有理由不去使用 Hadoop 的一个发行版本——因为它们也有免费的、非商业版。
所以,对于真正的 Hadoop 项目来说,我强烈推荐使用一个 Hadoop 的发行版本来代替 Apache Hadoop。下一节将会说明这种选择的优点。
Hadoop 发行版本
Hadoop 发行版本解决了在上一节中所提到的问题。发行版本提供商的商业模型百分之百地依赖于自己的发行版本。他们提供打包、工具和商业支持。而这些不仅极大地简化了开发,而且也极大地简化了操作。
Hadoop 发行版本将 Hadoop 生态系统所包含的不同项目打包在一起。这就确保了所有使用到的版本都可以顺当地在一起工作。发行版本会定期发布,它包含了不同项目的版本更新。
发行版本的提供商在打包之上还提供了用于部署、管理和监控 Hadoop 集群的图形化工具。采用这种方式,可以更容易地设置、管理和监控复杂集群。节省了大量工作。
正如上节所提到的,获取普通 Apache Hadoop 项目的商业支持是很艰难的,而提供商却为自己的 Hadoop 发行版本提供了商业支持。
Hadoop 发行版本提供商
目前,除了 Apache Hadoop 外, HortonWorks、Cloudera 和 MapR 三驾马车在发布版本上差不多齐头并进。虽然,在此期间也出现了其他的 Hadoop 发行版本。比如 EMC 公司的 Pivotal HD、IBM 的 InfoSphere BigInsights。通过 Amazon Elastic MapReduce(EMR),Amazon 甚至在其云上提供了一个托管的、预配置的解决方案。
虽然很多别的软件提供商没有开发自己的 Hadoop 发行版本,但它们和某一个发行版本提供商相互合作。举例来说,Microsoft 和 Hortonworks 相互合作,特别是合作将 Apache Hadoop 引入到 Windows Server 操作系统和 Windows Azure 云服务中。另外一个例子是,Oracle 通过将自己的软硬件与 Cloudera 的 Hadoop 发行版本结合到一起,提供一个大数据应用产品。而像 SAP、Talend 这样的软件提供商则同时支持几个不同的发行版本。
如何选择合适的 Hadoop 发行版本?
本文不会评估各个 Hadoop 的发行版本。然而,下面会简短地介绍下主要的发行版本提供商。在不同的发行版本之间一般只有一些细微的差别,而提供商则将这些差别视为秘诀和自己产品的与众不同之处。下面的列表解释了这些差别:
- Cloudera:最成型的发行版本,拥有最多的部署案例。提供强大的部署、管理和监控工具。Cloudera 开发并贡献了可实时处理大数据的 Impala 项目。
- Hortonworks:不拥有任何私有(非开源)修改地使用了 100% 开源 Apache Hadoop 的唯一提供商。Hortonworks 是第一家使用了 Apache HCatalog 的元数据服务特性的提供商。并且,它们的 Stinger 开创性地极大地优化了 Hive 项目。Hortonworks 为入门提供了一个非常好的,易于使用的沙盒。Hortonworks 开发了很多增强特性并提交至核心主干,这使得 Apache Hadoop 能够在包括 Windows Server 和 Windows Azure 在内的 Microsft Windows 平台上本地运行。
- MapR:与竞争者相比,它使用了一些不同的概念,特别是为了获取更好的性能和易用性而支持本地 Unix 文件系统而不是 HDFS(使用非开源的组件)。可以使用本地 Unix 命令来代替 Hadoop 命令。除此之外,MapR 还凭借诸如快照、镜像或有状态的故障恢复之类的高可用性特性来与其他竞争者相区别。该公司也领导着 Apache Drill 项目,本项目是 Google 的 Dremel 的开源项目的重新实现,目的是在 Hadoop 数据上执行类似 SQL 的查询以提供实时处理。
- Amazon Elastic Map Reduce(EMR):区别于其他提供商的是,这是一个托管的解决方案,其运行在由 Amazon Elastic Compute Cloud(Amazon EC2)和 Amzon Simple Strorage Service(Amzon S3)组成的网络规模的基础设施之上。除了 Amazon 的发行版本之外,你也可以在 EMR 上使用 MapR。临时集群是主要的使用情形。如果你需要一次性的或不常见的大数据处理,EMR 可能会为你节省大笔开支。然而,这也存在不利之处。其只包含了 Hadoop 生态系统中 Pig 和 Hive 项目,在默认情况下不包含其他很多项目。并且,EMR 是高度优化成与 S3 中的数据一起工作的,这种方式会有较高的延时并且不会定位位于你的计算节点上的数据。所以处于 EMR 上的文件 IO 相比于你自己的 Hadoop 集群或你的私有 EC2 集群来说会慢很多,并有更大的延时。
上面的发行版本都能灵活地单独使用或是与不同的大数据套件组合使用。而这期间出现的一些其它的发行版本则不够灵活,会将你绑定至特定的软件栈和(或)硬件栈。比如 EMC 的 Pivotal HD 原生地融合了 Greenplum 的分析数据库,目的是为了在 Hadoop,或 Intel 的 Apache Hadoop 发行版本之上提供实时 SQL 查询和卓越的性能,Intel 的 Apache Hadoop 发行版本为固态驱动器进行了优化,这是其他 Hadoop 公司目前还没有的做法。
所以,如果你的企业已经有了特定的供应方案栈,则一定要核查它支持哪个 Hadoop 发行版本。比如,如果你使用了 Greeplum 数据库,那么 Pivotal 就可能是一个完美的选择,而在其他情况下,可能更适合采取更加灵活的解决方案。例如,如果你已经使用了 Talend ESB,并且你想使用 TalenD Big Data 来启动你的大数据项目,那么你可以选择你心仪的 Hadoop 发行版本,因为 Talend 并不依赖于 Hadoop 发行版本的某个特定提供商。
为了做出正确的选择,请了解各个发行版本的概念并进行试用。请查证所提供的工具并分析企业版加上商业支持的总费用。在这之后,你就可以决定哪个发行版本是适合自己的。
何时使用 Hadoop 发行版本?
由于发行版本具有打包、工具和商业支持这些优点,所以在绝大多数使用情形下都应使用 Hadoop 的发行版本。使用普通的(原文为 plan,应为 plain)Apache Hadoop 发布版本并在此基础之上构建自己的发行版本的情况是极少见的。你会要自己测试打包,构建自己的工具,并自己动手写补丁。其他一些人已经遇到了你将会遇到的同样问题。所以,请确信你有很好的理由不使用 Hadoop 发行版本。
然而,就算是 Hadoop 发行版本也需要付出很大的努力。你还是需要为自己的 MapReduce 作业编写大量代码,并将你所有的不同数据源集成到 Hadoop 中。而这就是大数据套件的切入点。
大数据套件
你可以在 Apache Hadoop 或 Hadoop 发行版本之上使用一个大数据套件。大数据套件通常支持多个不同的 Hadoop 发行版本。然而,某些提供商实现了自己的 Hadoop 解决方案。无论哪种方式,大数据套件为了处理大数据而在发行版本上增加了几个更进一步的特性:
- 工具:通常,大数据套件是建立像 Eclipse 之类的 IDE 之上。附加插件方便了大数据应用的开发。你可以在自己熟悉的开发环境之内创建、构建并部署大数据服务。
- 建模:Apache Hadoop 或 Hadoop 发行版本为 Hadoop 集群提供了基础设施。然而,你仍然要写一大堆很复杂的代码来构建自己的 MapReduce 程序。你可以使用普通的 Java 来编写这些代码,或者你也可以那些已经优化好的语言,比如 PigLatin 或 Hive 查询语言(HQL),它们生成 MapReduce 代码。大数据套件提供了图形化的工具来为你的大数据服务进行建模。所有需要的代码都是自动生成的。你只用配置你的作业(即定义某些参数)。这样实现大数据作业变得更容易和更有效率。
- 代码生成:生成所有的代码。你不用编写、调试、分析和优化你的 MapReduce 代码。
- 调度:需要调度和监控大数据作业的执行。你无需为了调度而编写 cron 作业或是其他代码。你可以很容易地使用大数据套件来定义和管理执行计划。
- 集成:Hadoop 需要集成所有不同类技术和产品的数据。除了文件和 SQL 数据库之外,你还要集成 NoSQL 数据库、诸如 Twitter 或 Facebook 这样的社交媒体、来自消息中间件的消息、或者来自类似于 Salesforce 或 SAP 的 B2B 产品的数据。通过提供从不同接口到 Hadoop 和后端的众多连接器,大数据套件为集成提供了很多帮助。你不用手工编写连接代码,你只需使用图形化的工具来集成并映射所有这些数据。集成能力通常也具有数据质量特性,比如数据清洗以提高导入数据的质量。
大数据套件提供商
大数据套件的数目在持续增长。你可以在几个开源和专有提供商之间选择。像 IBM、Oracle、Microsoft 等这样的大部分大软件提供商将某一类的大数据套件集成到自己的软件产品组合中。而绝大多数的这些厂商仅只支持某一个 Hadoop 发行版本,要么是自己的,要么和某个 Hadoop 发行版本提供商合作。
从另外一方面来看,还有专注于数据处理的提供商可供选择。它们提供的产品可用于数据集成、数据质量、企业服务总线、业务流程管理和更进一步的集成组件。既有像 Informatica 这样的专有提供商,也有 Talend 或 Pentaho 这样的开源提供商。某些提供商不只支持某一个 Hadoop 发行版本,而是同时支持很多的。比如,就在撰写本文的时刻,Talend 就可以和 Apache Hadoop、Cloudera、Hortonworks、MapR、Amazon Elastic MapReduce 或某个定制的自创发行版本(如使用 EMC 的 Pivotal HD)一起使用。
如何选择合适的大数据套件?
本文不会评估各个大数据套件。当你选择大数据套件时,应考虑几个方面。下面这些应该可以帮助你为自己的大数据问题作出合适的抉择:
- 简单性:亲自试用大数据套件。这也就意味着:安装它,将它连接到你的 Hadoop 安装,集成你的不同接口(文件、数据库、B2B 等等),并最终建模、部署、执行一些大数据作业。自己来了解使用大数据套件的容易程度——仅让某个提供商的顾问来为你展示它是如何工作是远远不够的。亲自做一个概念验证。
- 广泛性:是否该大数据套件支持广泛使用的开源标准——不只是 Hadoop 和它的生态系统,还有通过 SOAP 和 REST web 服务的数据集成等等。它是否开源,并能根据你的特定问题易于改变或扩展?是否存在一个含有文档、论坛、博客和交流会的大社区?
- 特性:是否支持所有需要的特性?Hadoop 的发行版本(如果你已经使用了某一个)?你想要使用的 Hadoop 生态系统的所有部分?你想要集成的所有接口、技术、产品?请注意过多的特性可能会大大增加复杂性和费用。所以请查证你是否真正需要一个非常重量级的解决方案。是否你真的需要它的所有特性?
- 陷阱:请注意某些陷阱。某些大数据套件采用数据驱动的付费方式(“数据税”),也就是说,你得为自己处理的每个数据行付费。因为我们是在谈论大数据,所以这会变得非常昂贵。并不是所有的大数据套件都会生成本地 Apache Hadoop 代码,通常要在每个 Hadoop 集群的服务器上安装一个私有引擎,而这样就会解除对于软件提供商的独立性。还要考虑你使用大数据套件真正想做的事情。某些解决方案仅支持将 Hadoop 用于 ETL 来填充数据至数据仓库,而其他一些解决方案还提供了诸如后处理、转换或 Hadoop 集群上的大数据分析。ETL 仅是 Apache Hadoop 和其生态系统的一种使用情形。
决策树:框架 vs. 发行版本 vs. 套件
现在,你了解了 Hadoop 不同选择之间的差异。最后, 让我们总结并讨论选择 Apache Hadoop 框架、Hadoop 发行版本或大数据套件的场合。
下面的“决策树”将帮助你选择合适的一种:
Apache:
- 学习并理解底层细节?
- 专家?自己选择和配置?
发行版本:
- 容易的设置?
- 初学(新手)?
- 部署工具?
- 需要商业支持?
大数据套件:
- 不同数据源集成?
- 需要商业支持?
- 代码生成?
- 大数据作业的图形化调度?
- 实现大数据处理(集成、操作、分析)?
结论
Hadoop 安装有好几种选择。你可以只使用 Apache Hadoop 项目并从 Hadoop 生态系统中创建自己的发行版本。像 Cloudera、Hortonworks 或 MapR 这样的 Hadoop 发行版本提供商为了减少用户需要付出的工作,在 Apache Hadoop 之上添加了如工具、商业支持等特性。在 Hadoop 发行版本之上,为了使用如建模、代码生成、大数据作业调度、所有不同种类的数据源集成等附加特性,你可以使用一个大数据套件。一定要评估不同的选择来为自己的大数据项目做出正确的决策。
作者简介
 Kai Wähner 是 Talend 公司的首席顾问。他擅长的主要领域是 Java EE、SOA、云计算、业务流程管理(BPM)、大数据以及企业架构管理。他还在像 JavaOne、ApacheCon 或 OOP 这样的国际 IT 会议上做演讲,为专业期刊撰文,并在博客上分享自己的经验。你可以在他的网站上找到更多详细信息和参考资料(演示文稿、文章、博客文章),可以点击这里或是通过Twitter: @KaiWaehner 来联系他。
Kai Wähner 是 Talend 公司的首席顾问。他擅长的主要领域是 Java EE、SOA、云计算、业务流程管理(BPM)、大数据以及企业架构管理。他还在像 JavaOne、ApacheCon 或 OOP 这样的国际 IT 会议上做演讲,为专业期刊撰文,并在博客上分享自己的经验。你可以在他的网站上找到更多详细信息和参考资料(演示文稿、文章、博客文章),可以点击这里或是通过Twitter: @KaiWaehner 来联系他。
查看英文原文: Spoilt for Choice – How to choose the right Big Data / Hadoop Platform?
感谢马国耀对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




