
2010 年 9 月 23 日,Facebook 遭遇了迄今为止最严重的宕机事件之一,网站关闭了四个小时,情况非常严重。为进行恢复工作,工程师们不得不先让 Facebook 下线。虽然当时的 Facebook 规模还没有现在这么庞大,但仍然有超过 10 亿用户,宕机事件也没能逃过用户的眼睛。人们在推特上抱怨或取笑这次事件:
那么,到底是什么导致了这次宕机事件?事后的诊断报告提到:
今天,我们修改了一个错误的配置,每个客户端都看到这个错误的配置,然后试图更新它。因为更新数据需要查询数据库集群,集群很快就被每秒数十万次的查询拖垮。
一个错误的配置导致大量的数据库请求,这种蜂拥而至的请求被称为缓存踩踏(Cache Stampede)。这是困扰科技行业的一个常见问题,已经导致很多公司发生宕机事件,比如 2016 年的“互联网档案馆”(archive.org)事件。还有很多大型应用程序每天都在与之做斗争,比如 Instagram 和 DoorDash。
什么是缓存踩踏?
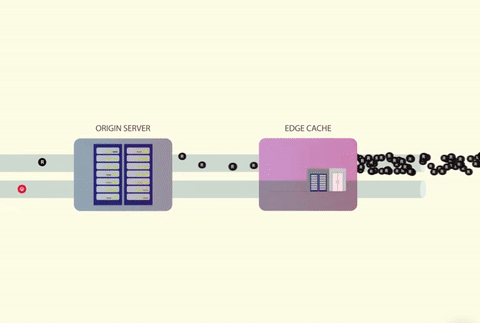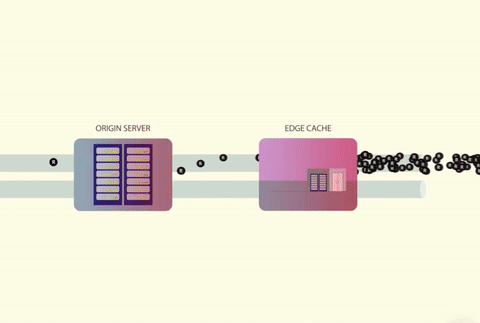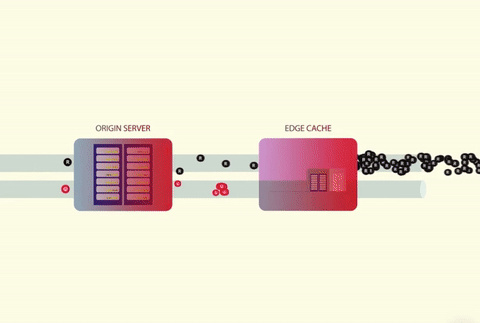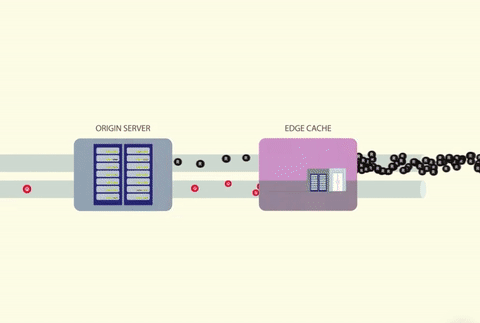
当多个线程试图并行访问缓存时,就会发生缓存踩踏。如果缓存的值不存在,那么线程将同时尝试从数据源获取数据。数据源通常是数据库,也可以是 Web 服务器、第三方 API 或任何其他可以返回数据的东西。
缓存踩踏之所以极具破坏性,一个主要原因是它会导致恶性的失败循环:
大量的并发线程无法从缓存中获得数据,然后直接调用数据库。
数据库由于巨大的 CPU 峰值发生崩溃,并导致超时错误。
收到超时错误后,所有的线程都会发起重试,从而导致另一次踩踏。
这个循环不断持续。
即使你没有 Facebook 那样的规模,也会遇到这个问题,因为它与规模无关。这个问题一直困扰着初创公司和科技巨头。
如何防止缓存踩踏?
我在得知 Facebook 宕机事件后问了自己这个问题。不出所料,自 2010 年以来,关于如何防止缓存踩踏这个问题,人们进行了大量研究,我从头到尾把它们看了一遍。
在本文中,我们将探索防止和减轻缓存踩踏影响的不同策略。毕竟,你不会希望等到发生宕机后才去了解可以采取哪些安全措施。
增加更多的缓存
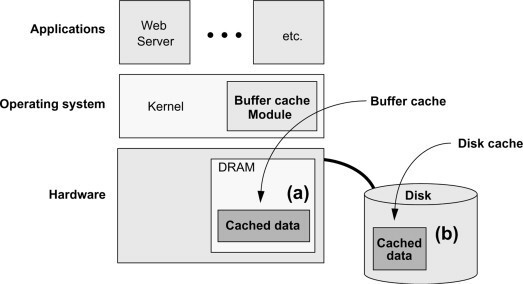
一个简单的解决方案就是增加更多的缓存。虽然这似乎有违直觉,但这与操作系统的工作原理是相似的。
操作系统利用了一个缓存层次结构,其中每个组件负责缓存自己的数据,以获得更快的访问速度。
你可以在应用程序中采用类似的模式,其中内存缓存是 Layer 1(L1)缓存,远程缓存是 Layer 2(L2)缓存。
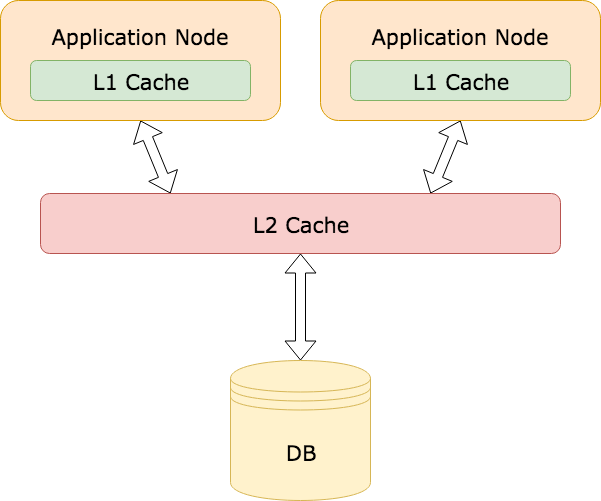
这对于防止被频繁访问的数据发生踩踏事件特别有用。即使 L2 缓存中的一个值过期,L1 缓存中可能仍然有缓存的值,避免了重新计算缓存值。
但这种方法有一些值得注意的地方。在应用服务器的内存中,缓存数据可能会导致内存不足,特别是在缓存大量数据的情况下。
此外,这种缓存策略仍然容易受跟随者踩踏的影响。
举一个跟随者踩踏的例子:当一个名人上传了新照片或视频到他们的社交媒体账户,所有关注者都收到通知,这个时候,他们会急于去查看新上传的内容。由于内容是新上传的,还没有被缓存,这个时候就会导致可怕的缓存踩踏。
那么,我们该如何解决跟随者踩踏问题呢?
锁和 Promise
缓存踩踏最主要的核心问题竟态条件——多个线程争夺共享资源。在这里,共享资源就是缓存。
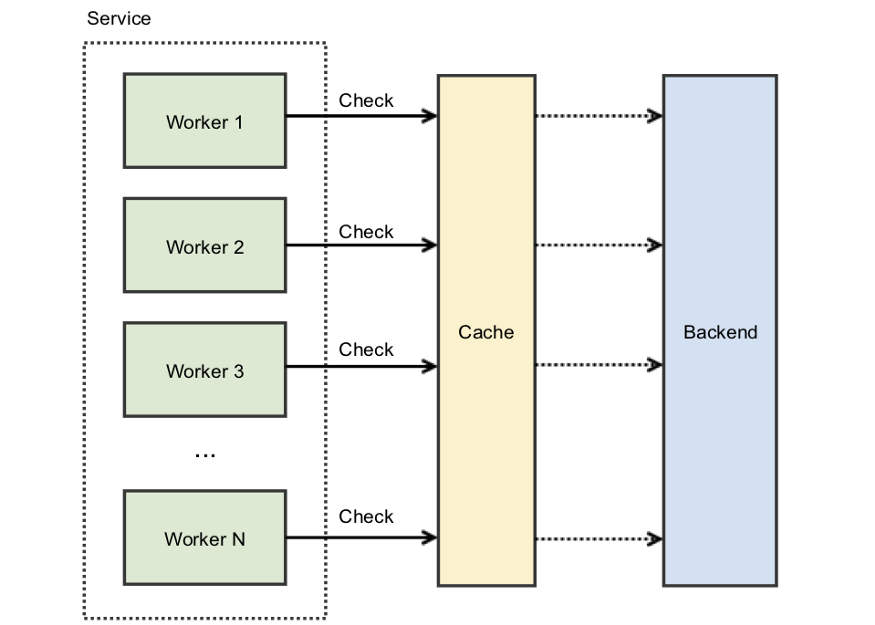
在高并发系统中,防止共享资源出现竟态条件的一种常见方法是使用锁。锁通常被用在同一台机器的线程上,但也有一些方法可以将分布式锁用于远程缓存。
通过给缓存键加锁,每次只有一个调用者能够访问这个缓存键。如果键丢失或过期,调用者可以重新生成数据,并放到缓存中,同时保持持有锁。其他任何试图读取同一个键的进程都必须等待,直到锁被释放。
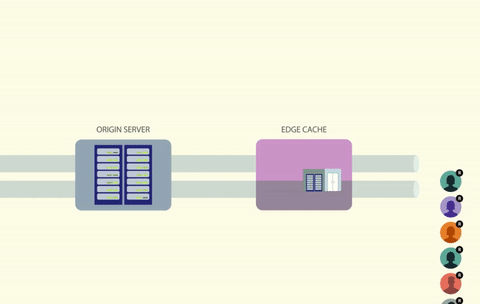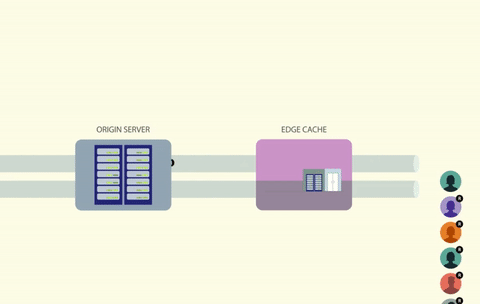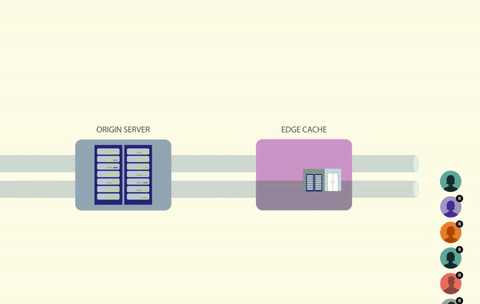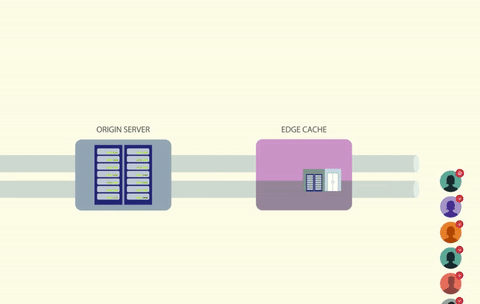
使用锁可以解决竟态条件问题,但它会带来另一个问题,即如何处理所有等待锁释放的线程?
使用自旋锁并让线程连续轮询锁?这造成了一种繁忙等待。
在检查锁是否可用前,让线程随机 sleep 一段时间?现在你要面对的是惊群效应问题。
引入退避和抖动机制来防止惊群效应?这可能行得通,但还有另外一个问题。持有锁的线程必须重新计算值,并在释放锁之前更新缓存键。
这个过程可能需要耗费一点时间,特别是当计算成本很高或存在网络问题时。如果因为计算缓存而耗尽了可用的连接池,仍然可能导致宕机。
所幸的是,一些顶级科技巨头正在使用一种更简单的解决方案:Promise。
如何通过 Promise 来避免自旋
引用 Instagram 工程博客的一篇文章“惊群效应和 Promise”:
在 Instagram,当我们启动一个新集群时,会遇到一个缓存踩踏问题,因为集群的缓存是空的。然后,我们使用 Promise 来解决这个问题:我们缓存的不是实际数据,而是最终会提供数据的 Promise。当访问缓存但获取不到数据时,我们不是立即去访问后端,而是创建一个 Promise 并将其放到缓存中。这个 Promise 会去查询后端。这样做的好处是,其他并发请求也会拿到这个 Promise,而所有这些并发线程都将等待后端请求返回的实际数据。
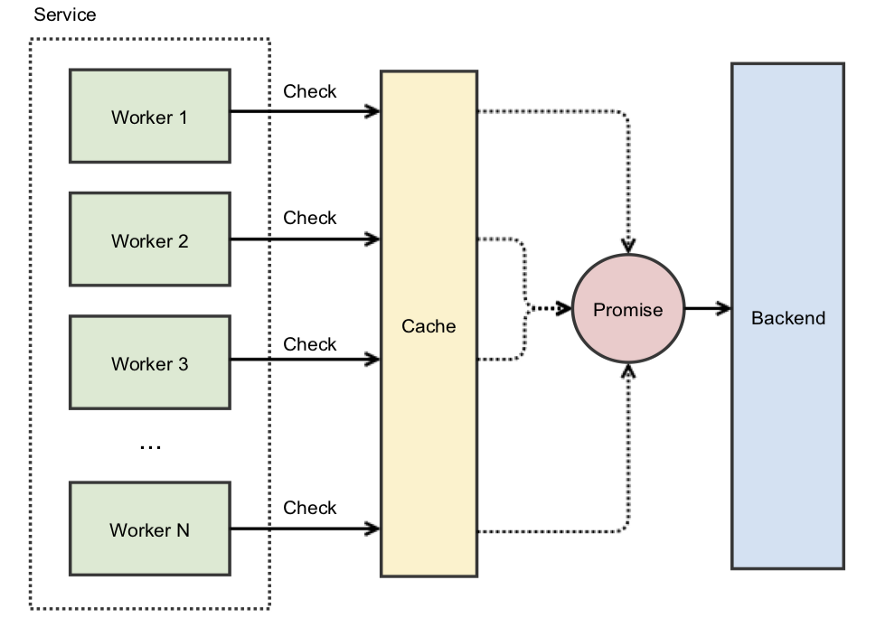
通过缓存 Promise 而不是实际数据,就不需要自旋锁。第一个获取缓存数据失败的线程将使用原子操作(例如 Java 的 computeIfAbsent)创建并缓存异步 Promise。所有后续的 fetch 请求都会立即返回这个 Promise。
你仍然需要使用锁来防止多个线程访问缓存键,但假设创建 Promise 是一个近乎即时的操作,那么线程停留在自旋锁中的时间长度就可以忽略不计了。
这就是 DoorDash 所采用的避免高速缓存踩踏的方法。
但是,如果重新计算缓存数据需要相当长的时间,那该怎么办?即使线程能够立即获取到缓存的 Promise,它们仍然需要等待异步进程完成后才能将数据返回。
虽然这种场景不一定会导致宕机,但仍然会导致尾部延迟和影响整体用户体验。如果保持较低的尾部延迟对于应用程序来说很重要,那么就需要考虑另外一种策略。
预先重计算
预先重计算(也称为提前过期)背后的原理很简单。在缓存键正式过期前,重新计算缓存值并延长过期时间。这可以确保缓存始终是最新的,并且不会发生缓存失效。
预先重计算最简单的实现是使用后台进程或 cron 作业。例如,假设有一个缓存键,它的 TTL 是一个小时,而重新计算缓存值需要两分钟。cron 作业可以在 TTL 到期前五分钟运行,并在更新数值后将 TTL 延长一个小时。
虽然这个想法理论上很简单,但它有一个明显的不足。除非你确切地知道将使用哪些缓存键,否则你就需要重新计算缓存中所有的键,这可能是一个非常费时费力的过程。
由于这些原因,我无法在生产环境中找到这种预先重计算的例子,但有一个例外。
概率性预先重计算
2015 年,一组研究人员发表了一份白皮书,叫作“最优概率性缓存踩踏预防"。在白皮书中,他们描述了一种算法,用于预测何时在缓存过期前重新计算缓存值。
虽然白皮书中提到了很多数学理论,但这个算法可以简单地归纳为:
currentTime - ( timeToCompute * beta * log(rand()) ) > expirycurrentTime 是当前时间戳。
timeToCompute 是重新计算缓存值所花费的时间。
beta 是一个大于 0 的非负数,默认值为 1,是可配置的。
rand()是一个返回 0 到 1 之间随机数的函数。
expiry 是缓存值未来被设置为过期的时间戳。
其思想是,每当线程从缓存中获取数据时,都会执行这个算法。如果返回 true,那么该线程将重新计算这个缓存值。离过期时间越近,这个算法返回 true 的几率就会显著增加。
虽然这个策略不是最容易理解的,但执行起来相当简单,不需要任何额外的组件,也不需要重新计算缓存中所有的值。
在 2016 年的宕机事件后,archive.org 开始使用这种方法。RedisConf17 的一个演讲对概率性预先重计算的工作原理进行了很好的概述,我强烈建议观看这个视频
当然,预先重计算假设有一个值需要重新计算,它本身并不能防止追随者踩踏问题。为此,你需要将其与锁和 Promise 结合起来使用。
如何停止正在发生的缓存踩踏
Facebook 的缓存踩踏事件之所以如此具有破坏性,其原因之一是即使工程师找到了解决方案,也无法进行部署,因为踩踏事件仍在进行当中。
事后诊断报告提到:
更糟糕的是,每次客户端在试图查询数据库时出现错误,都会将其解释为无效值,并删除相应的缓存键。这意味着即使原来的问题被修复,查询请求流仍在继续涌入。只要数据库无法满足某些请求的数据,就会带来更多的请求。我们陷入了一个不让数据库恢复到正常状态的循环中。
现实情况是,没有人能保证预防总是有效的,所以在出现问题时你还需要知道如何降低影响。防御性编程规定要制定好计划,以防流量绕过屏障发生踩踏事件。
所幸的是,有一个已知的模式可用来处理这个问题。
回路断路器
在程序中使用断路器的想法并不是什么新鲜事。在 Michael Nygard 的《Release It!》于 2007 年出版后,断路器模式就开始流行起来。Martin Fowler 在他的文章《回路断路器》中写道:
断路器背后的基本思想非常简单。你将一个受保护的函数调用封装在一个断路器对象中,断路器对象负责监控故障。一旦故障达到某一阈值,断路器就跳闸,所有对断路器的进一步调用都返回错误,根本调用不到受保护的函数。
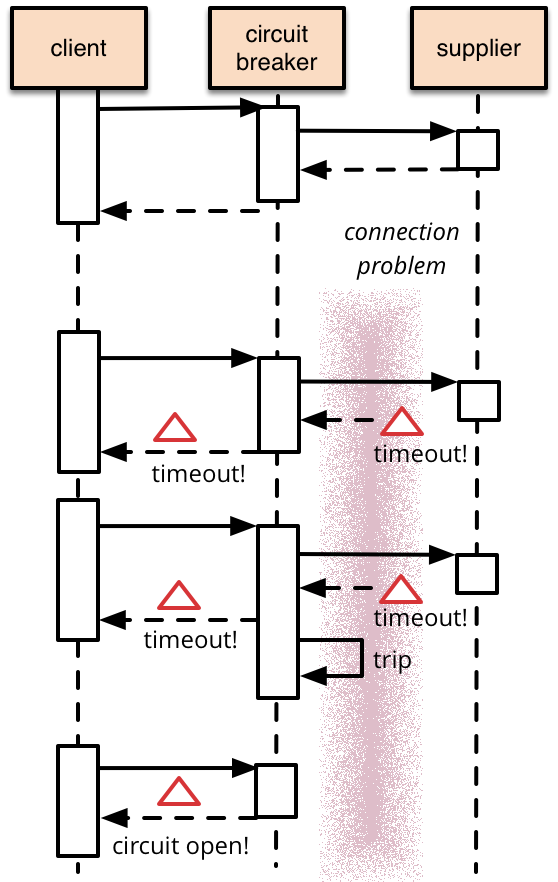
断路器是反应式的,所以它们无法防止宕机,不过它们可以防止连锁故障的发生。当事态失控时,它们提供了一个终止开关。如果 Facebook 使用了熔断机制,就可以避免让整个网站瘫痪下线。
当然,断路器不像在 2010 年那么流行了。现在,有几个库附带了断路器,如 Resilience4j、Istio 和 Envoy。Netflix 和 Lyft 等公司在生产环境中使用了这些服务。
Facebook 从中吸取了什么教训?
在本文中,我们讨论了很多关于解决高速缓存踩踏问题的不同策略,以及其他技术公司是如何使用它们的。那么 Facebook 呢?Facebook 从故障中吸取了什么教训?他们采取了什么措施来防止故障再次发生?
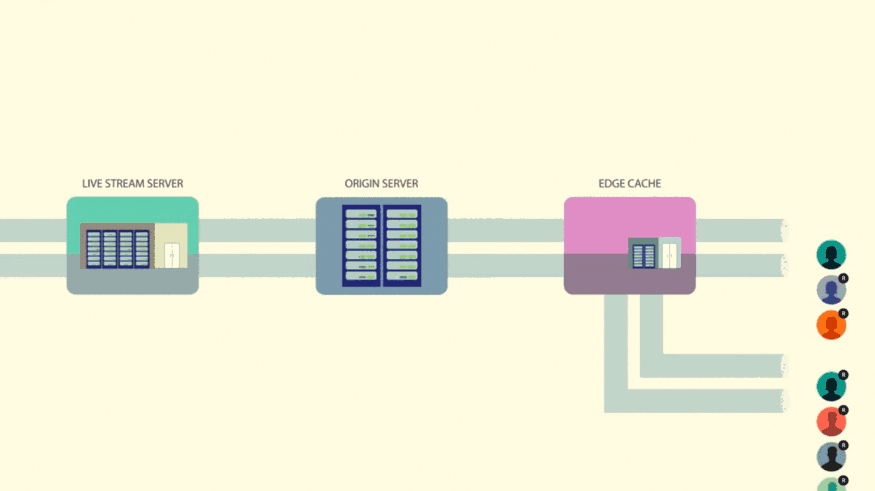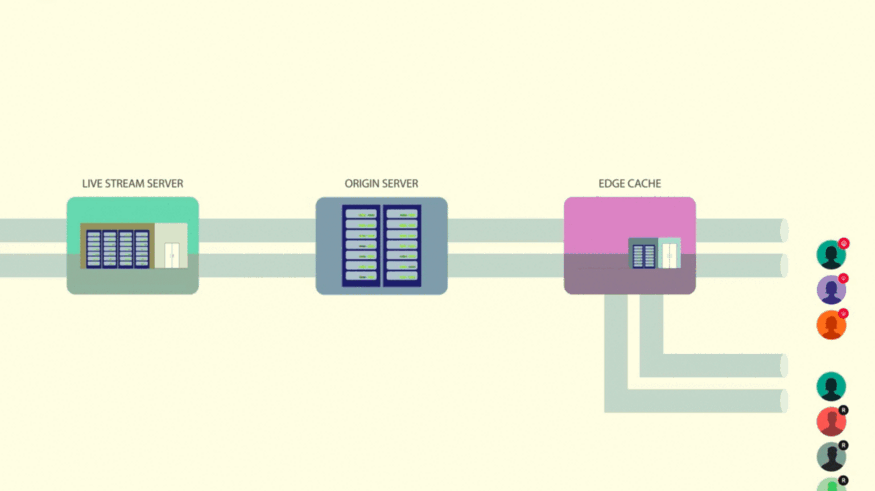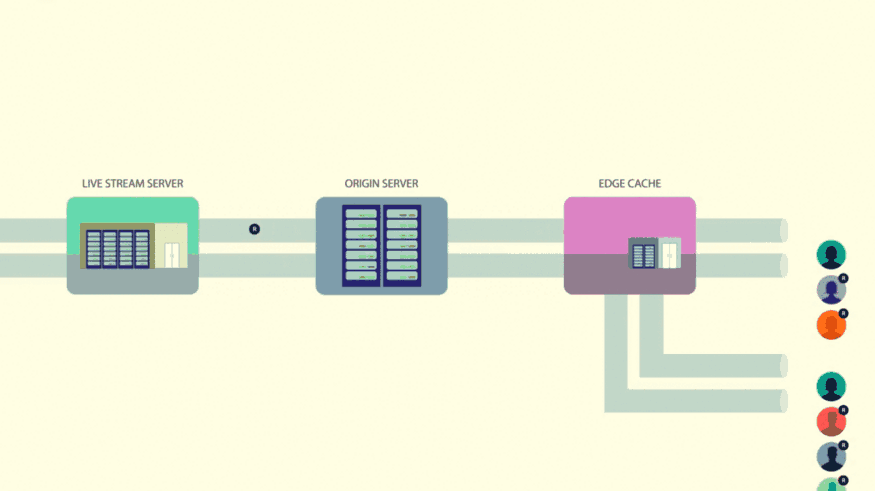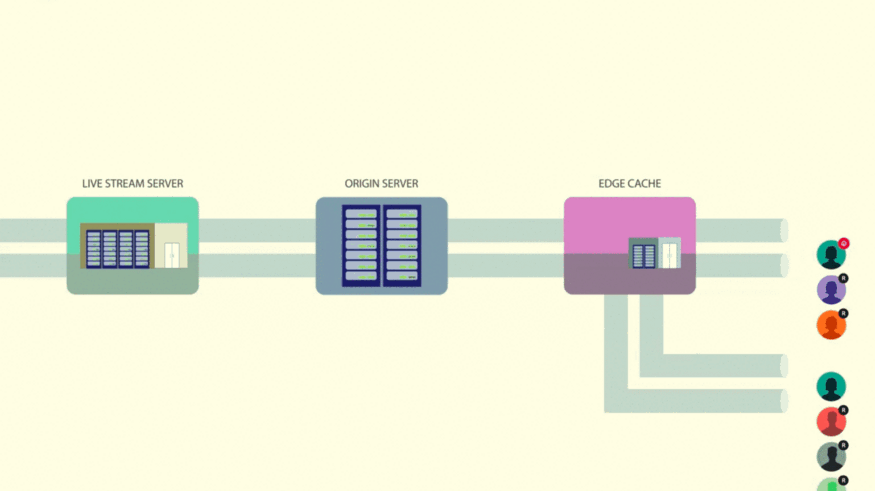
Facebook 工程博客的一篇文章“揭秘:向数百万人直播视频”讨论了他们对 Facebook 网站架构所做出的改进。这篇文章讨论了我们已经讨论过的内容,比如缓存层次结构,但也提到了一些新的方法,比如 HTTP 请求合并。这篇文章值得一读,如果你时间不够,这个视频为你提供了一个全面的概述。
可以说,Facebook 已经从过去的错误中吸取了教训。
写在最后:
虽然我认为有必要了解高速缓存踩踏是如对系统造成破坏的,但我不认为每个技术团队都一定要立即把文中提到的措施添加到自己的架构中。选择处理高速缓存踩踏问题的策略取决于你的实际场景、架构和流量负载。但是,当你在面对大规模的流量时,了解高速缓存踩踏问题和可能的解决方案对你来说肯定是有好处的。
原文链接:
相关推荐:




