
Serverless 研究成果和亮点
第三个研究课题主要是 Serverless 文件系统 —— 状态性方面的优化,也是非常有价值的一个方向。
下面的图可以解释当前 Serverless 计算的状态共享/存储模式。当前有两个层面,在计算层,主要通过 FaaS 提供服务,其特点是实例之间相互隔离,并且只有短暂的状态性。短暂的状态性指的是 FaaS 服务运行完毕后,实例销毁,状态也随之销毁。如果希望永久存储,则需要持续的写入到存储层(例如对象存储、K-V 存储等)即 BaaS 服务中,实现状态信息的长期存储和共享。
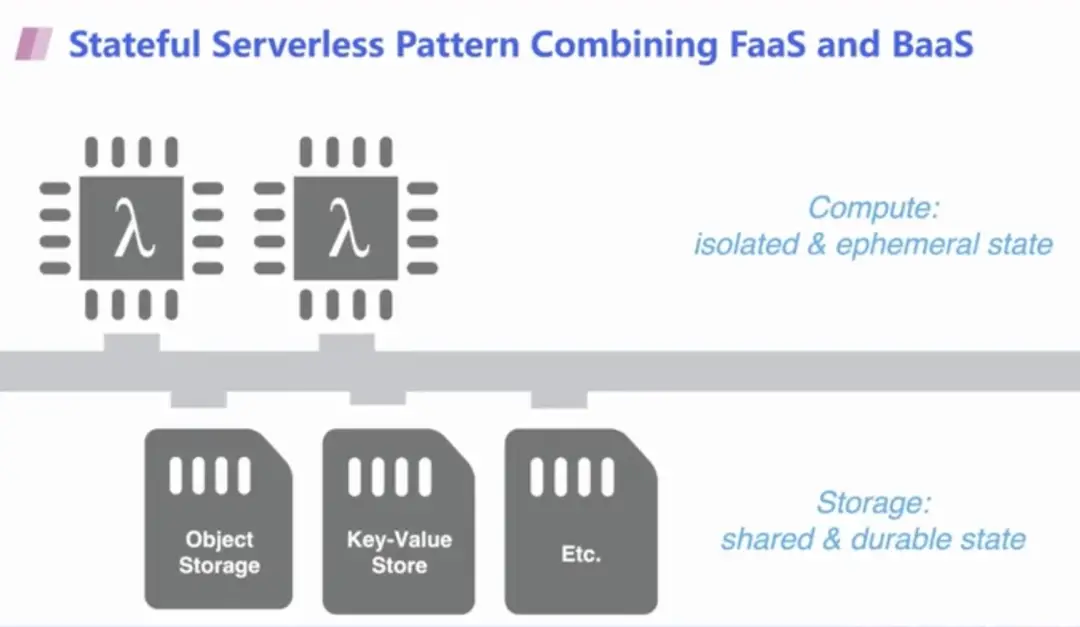
但当前这样的模式面临两个主要的问题:(26:31)
一方面是延迟问题,也是许多 BaaS 服务目前存在的问题;另一方面,对象存储或者 K-V 存储是通过 API 进行服务的,并不能感知到底层的存储情况,因此在开发应用或迁移时难以信任这些存储资源(改变了以往的开发使用方式)。所以我们的诉求很简单,是否可以提供类似本地磁盘一样的存储能力,区别只是在云端呢?
这就是 Serverless 云函数文件系统(CFFS, Cloud Function File System)所要提供的能力。该文件系统有以下几个特点:
基于标准 POSIX API 的文件系统,提供持久化的存储能力。
CFFS 提供了透明传输机制,也就是在函数启动时,CFFS 也随之启动一个传输;而当函数销毁时,这个传输会被提交。这样做可以获取到函数执行过程中的许多状态信息。
虽然通常情况下传输会对性能有影响,但如果能够积极利用本地状态和缓存,这种方式相比传统的文件存储系统,对性能有很好的提升。

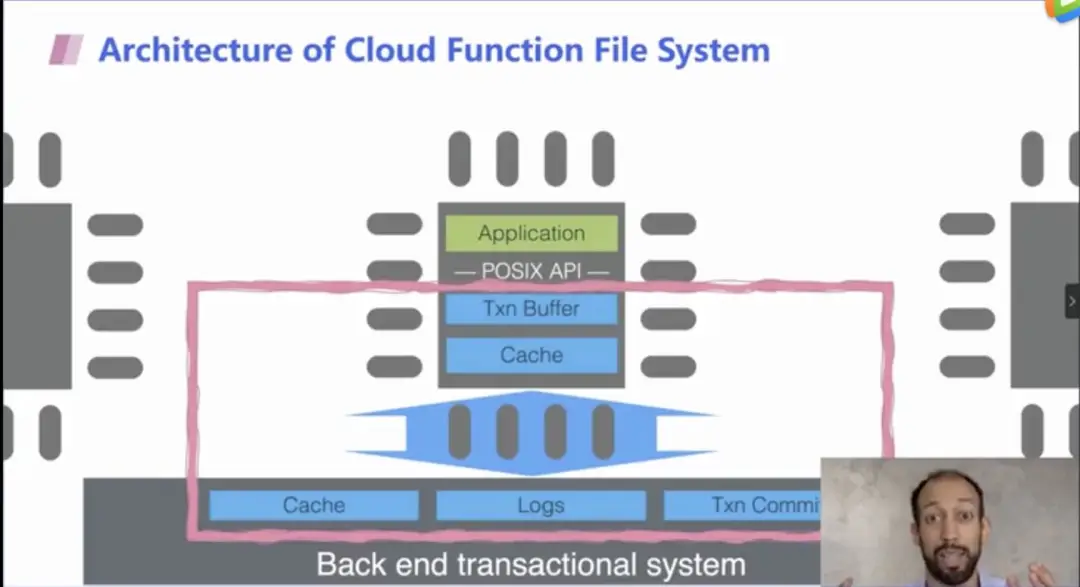
下面是 CFFS 的架构图,可以看出 CFFS 在云服务商的 FaaS 环境中运行,在前端通过标准的 POSIX API 进行调用,后端的存储系统则利用缓存等,专为云函数 FaaS 设计并提供服务。
参考文献:
http://www.hpts.ws/papers/2019/schleier-smith-hpts-2019.pdf
第四个研究课题 Cloudburst 也是致力于解决 Serverless 中状态问题的项目。 Cloudburst 更侧重于怎样将 Serverless 应用在状态敏感、延时敏感的应用场景中。例如社交网络、游戏、机器学习预测等。
Cloudburst 主要基于 Python 环境,能够低延迟的获取共享可变状态(shared mutable state),和 CFFS 类似, Cloudburst 也在函数执行器中利用了数据缓存来提升性能,但和 CFFS 不同的是,Cloudburst 可以保证因果一致性(Causal Consistency)来达到更好的性能。

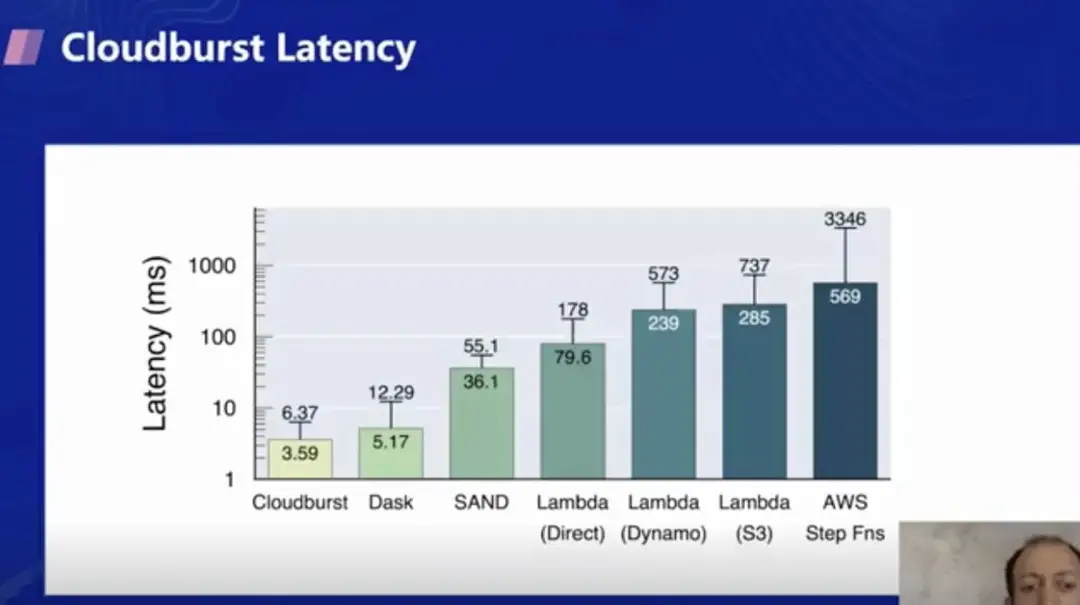
实验结果上也表明 Cloudburst 有很强的性能优势。在相同条件下,用了 DynamoDB(K-V 数据库)服务的 Lambda 函数约有 239 ms 的延迟,但用 Cloudburst 的延迟低于 10 ms。
参考文献:
https://github.com/hydro-project/cloudburst
https://arxiv.org/pdf/2001.04592.pdf
最后一个研究课题是 Serverless 数据中心。当我们思考服务器的组成时,一般会想到 CPU,内存,有时候还有 GPU 和硬盘这些基本硬件。而千千万万这些硬件组合在一起,之后进行网络连接,就成了数据中心。像个人电脑、服务器集群等都是通过这样的方式构建的。
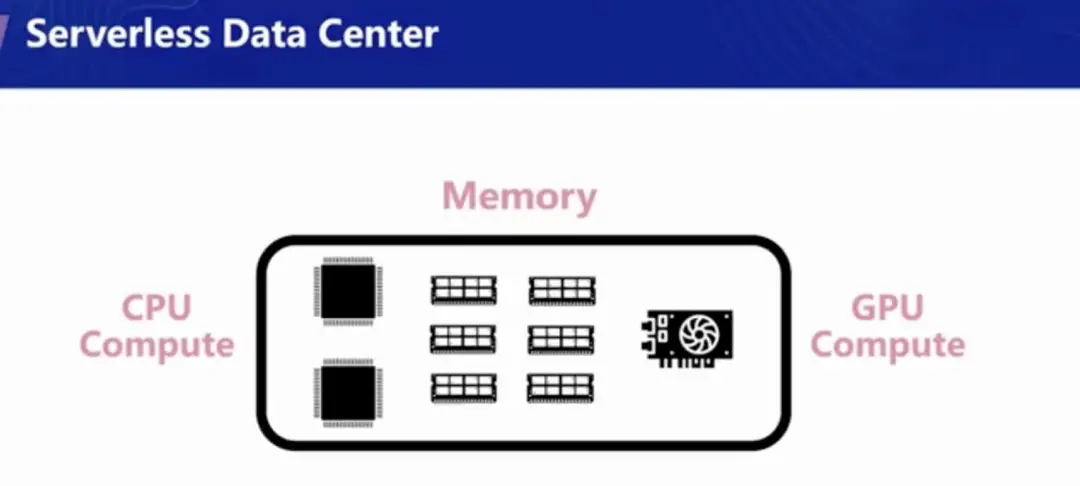
但是从应用层的角度,这样的组合方式并不是唯一的。所以有一种新的概念叫做分布式集群(distributed datecenter),也叫 Warehouse-scale computer,思路是将同类型的硬件元素(例如 CPU、内容)组合在一起,当应用用到对应的资源时,例如需要 GPU 加速时,才会分配对应的资源。同理,可以用在硬盘或者一些自定义的加速器上面。这个概念类似于将一个数据中心看做一台计算机,来提升资源的利用率。
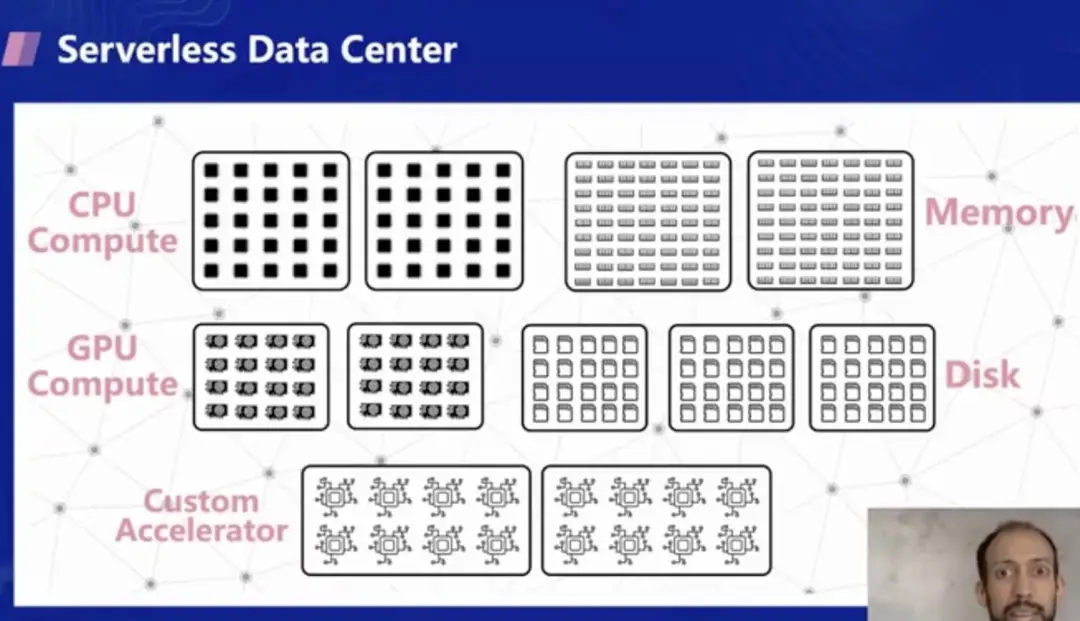
针对 Warehouse-scale computer 的硬件开发已经在持续进行中了,因此 Serverless 也应该考虑下在这种集群模式下,怎样适配和使用这种集群模式。而且这也将对当前针对单机的应用开发模式做出改变。
参考文献:
https://www.usenix.org/conference/fast14/technical-sessions/presentation/keynote
https://www.usenix.org/sites/default/files/conference/protected-files/fast14_asanovic.pdf
Serverless 方向预测
接下来,我将阐述下 Berkeley 对 Serverless 计算未来方向的预测。早在 2009 年,Berkeley 就对云计算的未来做过一次预测。回看当时的分析,发现有些预测是正确的,例如无限大的资源池,无需为前期使用付费等。同时,有一些预测并不那么准确,因为当时的我们并没有看到云计算将进入第二阶段,即 Serverless 阶段。

以下是我们对 Serverless 计算的预测:
特定应用场景及通用场景将会成为使用 Serverless 计算的主流。如下图所示,云服务商负责的是粉色区域的部分,而用户只关心粉色区域的上层。在特定应用场景下,你可以在弹性伸缩的平台中实现特定的操作,例如写数据库、实时数据队列、或者机器学习等。这些场景中,用户业务代码需要在遵循平台限制,例如运行环境、运行时长、没有 GPU 加速等,当然这些限制也会随着技术成熟而逐步放宽,从而更好地支持这些场景。
另一种则是更通用的 Serverless 架构,在这种场景下,你的 FaaS 函数会被其他 BaaS 服务所拓展,例如 Starburst、缓存等服务;并且有对象存储或文件存储可以用于长期存储状态信息。之后,在此基础上,用户可以自定义一些软件服务,例如提供 SQL 的能力等,并且将对应的应用运行在上面,从而实现流数据处理、机器学习等各种场景。
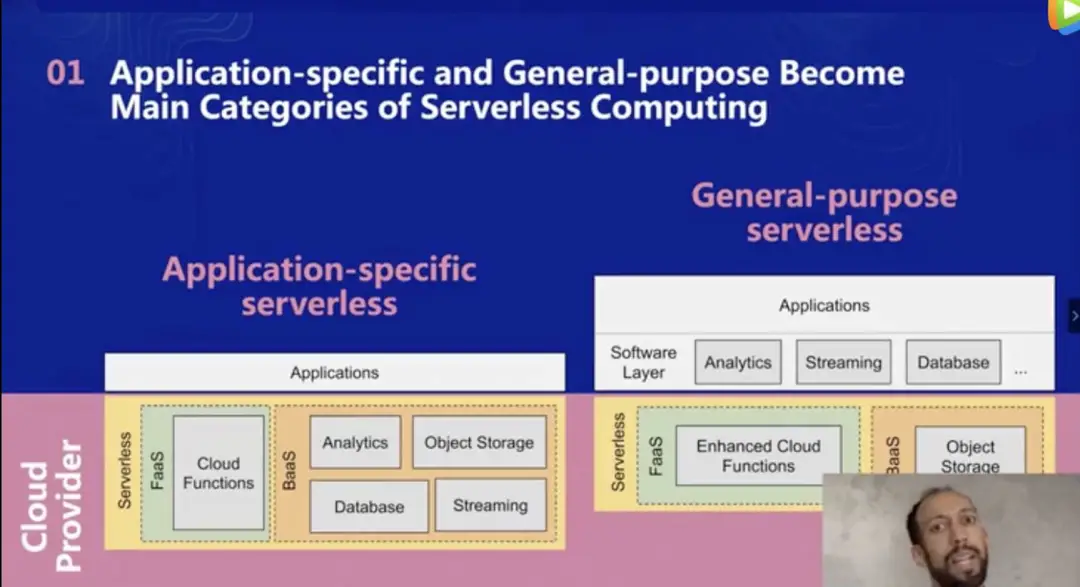
通用的 Serverless 几乎能够支持任何应用场景,从底层架构上来看,所有能运行在服务器上的场景,都可以被视为通用 Serverless 场景支持。

我们认为在未来,Serverless 架构比服务器在成本上会更有竞争力,当你用了 serverless 架构时,就已经获得了高可靠,弹性扩缩容的能力。此外,Serverless 的计费模式会更加精确,资源利用率也将逐步提升,确保做到真正的按需使用和付费。因此相比预留资源,在价格上会更有竞争力,更多的人也会因此选择 Serverless 架构。

此外,云服务商会针对机器学习场景做优化,包括性能、效率和可靠性等方面。云服务商会提供一些类似工作流调度,环境配置等能力来实现该场景的支持(例如预置内存)。通过这些上下游能力,也可以进一步帮助通用场景下的平台性能得到提升。

最后,是各类硬件方面的发展。当前云计算已经强依赖 X86 架构,但 Serverless 可以考虑引入新的架构,从而让用户或云服务商自行选择最适合的硬件来处理任务,从而实现更高的利用率和更强的性能。

总结 Summary
首先,我们认为 Serverless 计算是云计算的下一个阶段。而 Serverless 最重要的三个特征是:隐藏了服务器的复杂概念、按需付费和弹性伸缩。此外 Serverless 的实现是由 FaaS 和 BaaS 共同组成的(参考上面的经典案例)。直观来说,Serverless 带来的转变就像租车到打车一样。
此外,还分享了几个当前学术界针对 Serverless 的研究方向。包括效率提升(性能、可用性等)、具体应用的抽象(例如机器学习,数据处理等),和通用层面的抽象(让 Serverless 支持更加通用的场景)。
Serverless 计算可能会改变我们对计算机的看法,摆脱了本机硬件的限制,你可以直接从云端获取无限的资源,随取随用。

头图:Unsplash
作者:Johann
原文:https://mp.weixin.qq.com/s/3yqDTTN-96VFSTtqOs6RXg
原文:权威指南:Serverless 未来十年发展解读 — 伯克利分校实验室分享(下)
来源:TencentServerless - 微信公众号 [ID:ServerlessGo]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




