
近日,快手和苏黎世理工宣布开源分布式训练框架 Bagua(八卦),相比于 PyTorch、TensorFlow 等现有深度学习开源框架仅针对系统层面进行优化,Bagua 突破了这一点,专门针对分布式场景设计了特定的优化算法,实现了算法和系统层面的联合优化,性能较同类提升 60%。
研发背景
随着摩尔定律的失效,单个计算单元的能力已经远远无法满足数据的指数级增长。比如,快手每天上传的新视频超过千万条,即便训练简单的分类模型(比如 ResNet),使用单机单卡的算力,训练快手日内新增视频都需要超过一百天的时间。因此,在数据爆炸性增长的互联网行业,多机多卡的并行训练成为了大数据时代的必然。随着深度学习模型功能的日益强大,分布式训练任务的通信成本和所需算力也随之急剧增长。
然而,由于多机多卡并行带来的额外通讯成本,加速比(speedup)经常让大家失望,从而形成了大厂“堆资源”,没资源的“干瞪眼”的局面。比如,Google 的 Downpour 框架 [1] 使用 80 个 GPU 训练 ImageNet,加速比却只有 12/80=15%。因此如何提升多机多卡中训练的通讯效率成为了并行训练乃至解决数据爆炸性增长的核心问题之一。
项目 GitHub 地址:https://github.com/BaguaSys/bagua
现有的深度学习开源框架(PyTorch,TensorFlow)主要针对系统层面优化,把已有的单机单卡优化算法扩展到多机多卡的场景。虽然系统层面的优化使得并行效率不断提升,但是边际效益却越来越明显。针对这个问题,快手和苏黎世理工(ETH Zürich)联合开发了一款名为“Bagua”的分布式训练框架,突破单纯的系统层面优化,专门针对分布式的场景设计特定的优化算法,实现算法和系统层面的联合优化,极致化分布式训练的效率。用户只需要添加几行代码,便能把单机单卡训练扩展到多机多卡训练并得到非常可观的加速比。
Bagua 设计思路
从单机单卡的训练到多机多卡训练的核心,是每个卡把自己的计算结果进行累加和传播。这个过程好比每个人把自己知道的信息传递给他人,然后又从其他人那里获取信息,最后完成全局的信息同步。如果把计算单元之间的信息同步类比为人与人之间的信息同步,那么社会实践经验告诉我们,“八卦”可能是消息传递最高效的模式。“八卦”消息传播具有去中心化、异步通讯、信息压缩的特点,这与 Bagua 里面实现的通讯算法刚好一一呼应。
为了提升分布式训练效率,Bagua 实现了自研以及前沿的算法,包括去中心化/中心化、同步/异步以及通讯压缩等基础通讯组件,通过软硬结合的设计极致优化了这些组件的效率,并且灵活支持这些算法的组合,以及更复杂的算法设计。
Bagua 将通信过程抽象成了如下的算法选项:
中心化或是去中心化(Centralized or Decentralized):在中心化的通讯模式中,梯度或模型的同步过程需要所有的工作节点进行参与,因此,较高的网络延时往往会导致训练效率的降低。去中心化的通信模式 [5,6] 往往可以有效的解决这一问题:在该模式下,工作节点可以被连接成特定的拓扑结构(例如环),在通信过程中,每一个工作节点只与和它相邻的节点进行通信。
同步或是异步(Synchronous or Asynchronous):同步模式中,在每一次迭代过程中,所有工作节点都需要进行通信,并且下一步迭代必须等待当前迭代的通信完成才能开始。反之,异步式分布算法 [2] 则不需要等待时间:当某个节点完成计算后就可直接传递本地梯度,进行模型更新。
完整精度模式或信息压缩模式(Full-Precision or Low-Precision):完整精度模式,会使用与本地模型相同的 32 位浮点数(float32)进行传输。另一方面,在通讯存在瓶颈的情况下,基于大量已有研究通过量化 (quantization [3]) 或稀疏化 (sparsification [4]) 等方法压缩梯度,再用压缩后的梯度更新参数。在很多场景下,可以达到和完整精度相同的精度,同时提升通讯效率。
虽然为了提升通讯效率,Bagua 没有依照传统的方式同步所有计算节点的结果,甚至每次同步的信息还有偏差,但是得益于最新理论上的进展,这几种通讯策略以及他们的组合最终收敛解的正确性和效率仍然能得到充分保证,而且计算复杂度跟同步中心化和信息无损的方法相当,但是通讯效率更高 [10]。
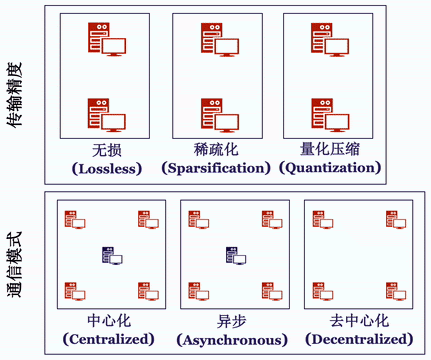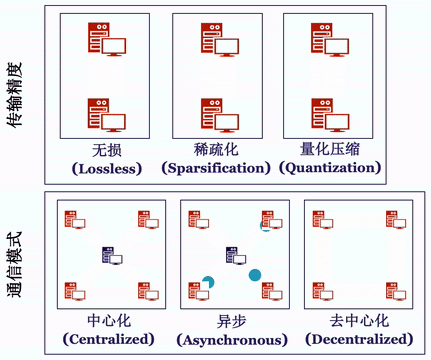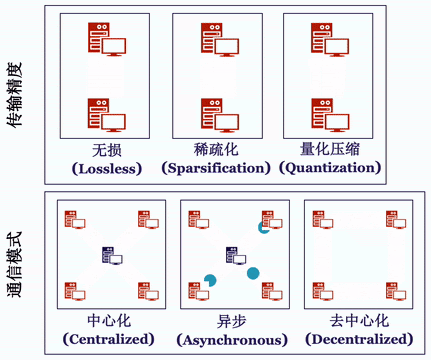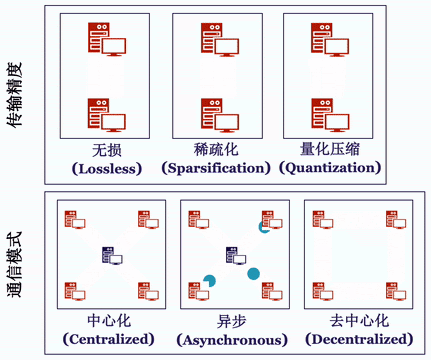
值得注意的是,在实践中,分布式训练算法往往会使用不止一种上述的优化方法,从而适配更为极端的网络环境 [7,8,9]。对于分布式算法感兴趣的读者,我们在这里推荐一份最新的完整综述报告 [10]。Bagua 提供了一套详尽的通信模式来支持用户在上述模式中任意选择组合,我们将这一分布式训练系统对于上述算法选项的支持情况总结在下表中:
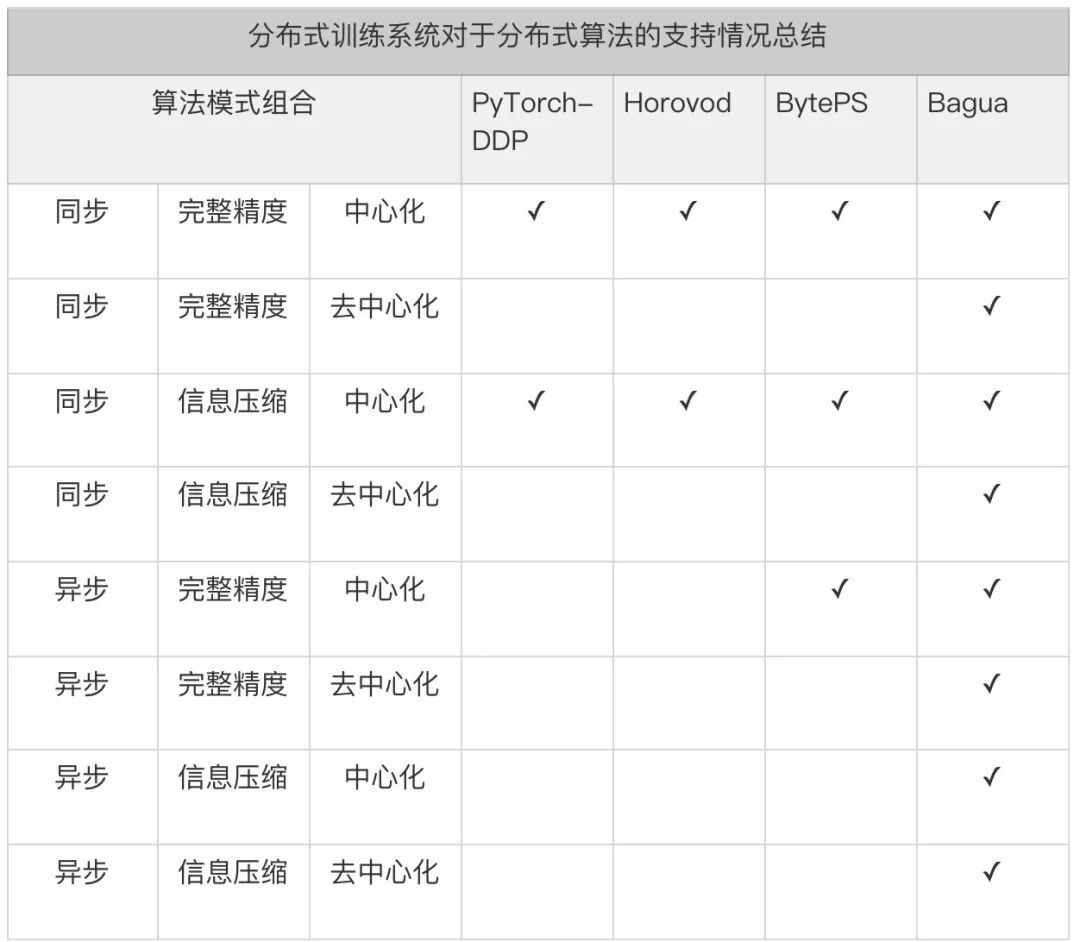
从表格中不难看出,现有框架的优化只是针对较为通用的算法(中心化同步完整精度),对于其他的算法组合,这些系统的支持非常有限。对于中心化同步进行信息压缩,这些系统往往只能支持较为简单的 float32->float16 压缩,相较而言,Bagua 则可以支持更为复杂的 ByteGrad,QAdam 等算法。对于其他的算法组合,现有的框架通常无法支持,而 Bagua 则可以自由支持。
然而,简单地支持这项算法选项并不能直接在大规模集群上带来性能的提升。Bagua 的核心优势在于,为了追求极致化的性能,而实现算法和实现的联合优化。具体来讲,基于上述的通信层抽象,用户既可以方便得选择系统提供的各种算法组合从而获得性能提升,又能灵活得实现新的分布式 SGD 算法 —— Bagua 将自动为这一算法实现提供系统层优化。这些系统优化包含:
将通讯时间隐藏在计算时间中:为了降低通信开销,Bagua 能够将部分通信时间隐藏在计算时间中。具体来讲,在反向梯度的计算过程中,部分已经完成的梯度可以在剩余梯度的计算过程中同时进行通信——通过这种流水的处理方式,部分通信时间可以被有效地“隐藏”在反向梯度的计算过程中,从而减小数据并行带来的通信开销。
参数分桶及其内存管理:频繁的传输碎片化数据,会降低通信的效率。因此,Bagua 将模型参数分割成桶,并且分配连续的内存空间来对每一个桶进行管理,这样通讯的单位就变成了桶,从而能够更高效地利用通信模型。此外,由于支持了信息压缩算法,对于压缩和解压的函数,其操作的基本单位也是桶,这样也能使得这些操作的开销降低。
分层化的通信实现:由于工业级别的分布式训练往往需要多机多卡,而不同物理连接方式所带来的延时和带宽也有较大差异,因此,通讯的有效抽象也对性能的提升至关重要。Bagua 将涉及多机的通信抽象成:“机内”和“机间”,并对于相应的通信抽象做了优化。例如,对于信息压缩传输,分层化通讯将会把这一算法解读成“机内”完整精度,“机间”信息压缩,从而为不同的物理链接提供最合适的通信算法。
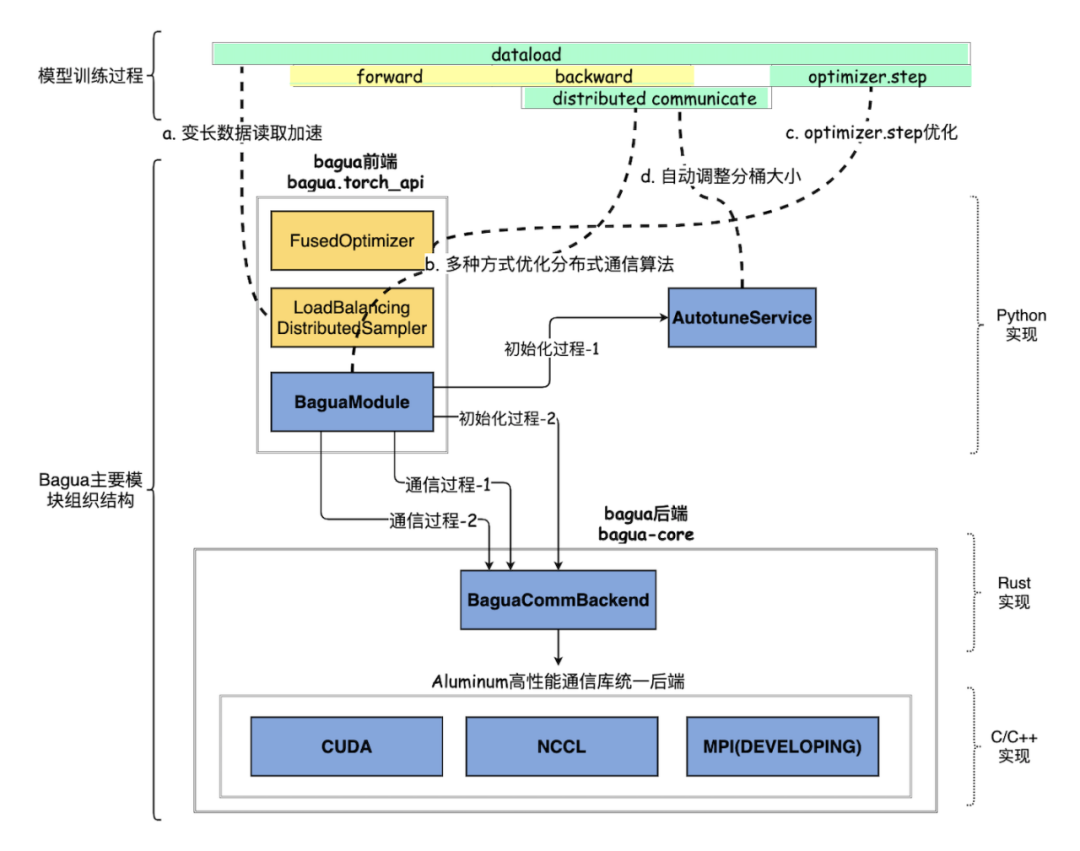
我们想要强调的是,这些系统实现层面的优化是对于各种算法组合广泛适用,而非局限在某一特定的算法设置上。因此,所有的系统优化都可以被灵活的复用到各种算法实现中去,这在保证“端到端”的性能提升的同时,也为开发新的分布式算法提供了良好的平台。
经过实验,Bagua 的特点如下:
并行性能显著提高:在 ImageNet 数据集上,相较当前开源分布式框架(PyTorch-DDP,Horovod,BytePS),当配置同样的算力(128GPU)与通信网络(100Gbps),达到相同的训练精度,Bagua 只需其他框架 80% 左右的时间;
对网络环境更鲁棒:由于有效的支持了各类算法优化(信息压缩,异步,和去中心化),Bagua 在各类网络环境下(包括不同延时和带宽)都体现出了良好的适配性。尤其是在高延迟低带宽的情况下,Bagua 体现出比其他框架更优的加速比,比如:在 10Gbps 网络带宽环境下,同样的 ImageNet 任务,Bagua 只需其他框架 50% 左右的训练时间来达到同样的训练精度;
“一键式”使用:Bagua 对于端用户非常友好,现有利用 PyTorch 的模型都可以作为 Bagua 的输入,Bagua 将自动为其提供丰富的并行方案——只需增加几行代码,训练就可以运行在分布式集群上;
分布式通讯算法易拓展性:Bagua 提供了针对算法的高拓展性,对于分布式优化算法的开发者,Bagua 提供了有效的通讯抽象,开发者实现的新算法也可以直接复用 Bagua 的系统优化;
可用于工业级场景大规模使用:Bagua 为 Kubernetes 实现了定制化的 operator,支持云原生部署,同时考虑机器资源和故障问题,有机结合 PyTorch Elastic 和 Kubernetes 实现了容灾功能和动态训练扩缩容。用户可以通过使用 Bagua ,在少量机器空闲时就开始训练,在更多机器资源释放的情况下,训练任务自动扩容到更多机器。同时机器节点损坏时,自动剔除坏节点继续训练。方便工业级训练场景使用,也方便与机器学习平台结合使用;
安全、故障易排查:Bagua 通讯后端由注重内存安全、速度和并发性的 Rust 语言实现,在编译期就排除了大量的内存安全问题。同时基于 tracing 实现了分模块、分层级的 log 输出,使得实际场景中故障排查更加轻松。
此外,Bagua 在快手内部也经过了工业级任务的实践检验,Bagua 已经在快手内部多个核心业务场景投入使用,相较其他开源框架取得了显著的性能提升:
大规模自然语言处理(GPT2-xl 量级大小的模型),提升效率 65%
大规模图像识别(10+ 亿图像 / 视频),提升效率 20%~30%
大规模语音识别(TB 级别语音资料),提升效率 20%~30%
大规模推荐系统(万亿级别参数模型训练,支持亿级别 DAU 的应用),提升效率 100% 以上
Bagua 和其他开源方案的性能对比
快手选用了包括图像,文本,语音,图像文本混合等多个训练任务对 Bagua 的性能进行测试,并与 PyTorch-DDP,Horovod,BytePS 进行比较。得益于 Bagua 系统的高效性和算法的多样性,Bagua 可以在不同任务中选用相应最优的算法,从而保证在训练精度和其他系统持平的前提下,训练速度明显提高。值得注意的是,当网络状况不佳时,Bagua 系统的优势将更加明显。下面我们选取 GPT2-XL,BERT-Large 和 VGG16 三个典型的通信密集型任务进行对比说明,更多结果可在 Bagua 论文和网站中(https://github.com/BaguaSys/bagua)进一步了解。
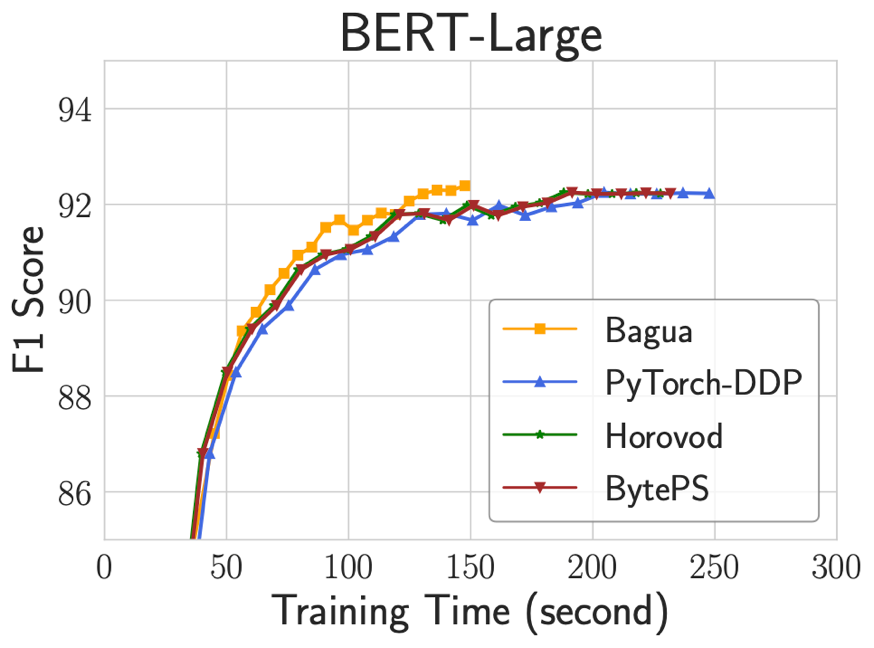
1. End-to-end 训练时间对比
下图展示了在 128 个 V100 GPU 上 fine-tune BERT-Large (SQuAD 数据集),模型 F1 精度随训练时间的变化曲线。Bagua 使用 QAdam-1bit 算法加速,机器之间采用 100Gbps TCP/IP 网络互联。我们可以看到,即使在高速网络下,达到相同的训练精度,Bagua 需要的时间仅为其他系统的 60%。
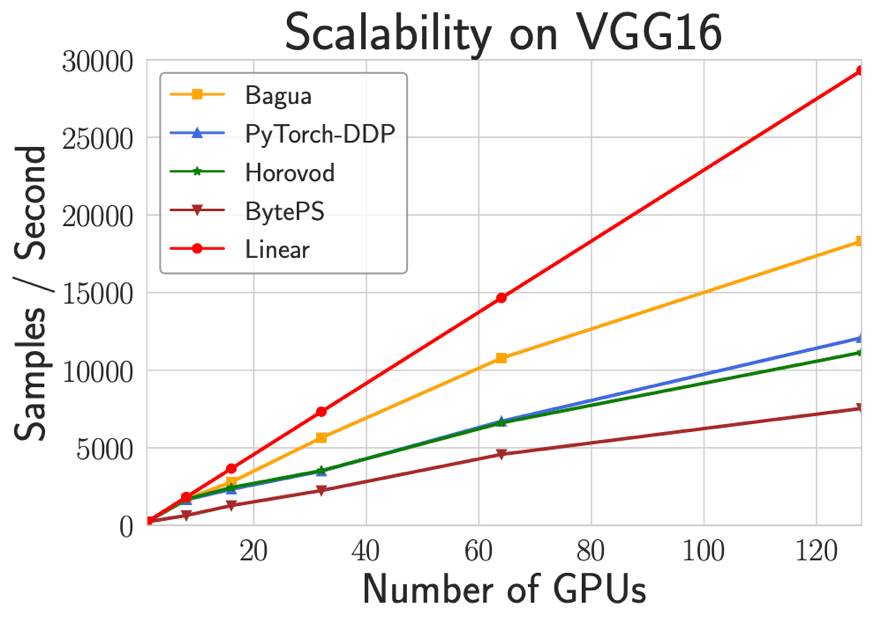
2. 扩展性对比
下图展示了各个系统在 VGG16 模型(ImageNet 数据集)上的训练速度与 GPU 数量之间的关系。在测试中分别使用了 1,8,16,32,64,128 个 V100 GPU 进行测试。该任务中 Bagua 使用 8bitsGrad 算法加速。可以看出 Bagua 的扩展效率相比其他系统有较明显的提升。
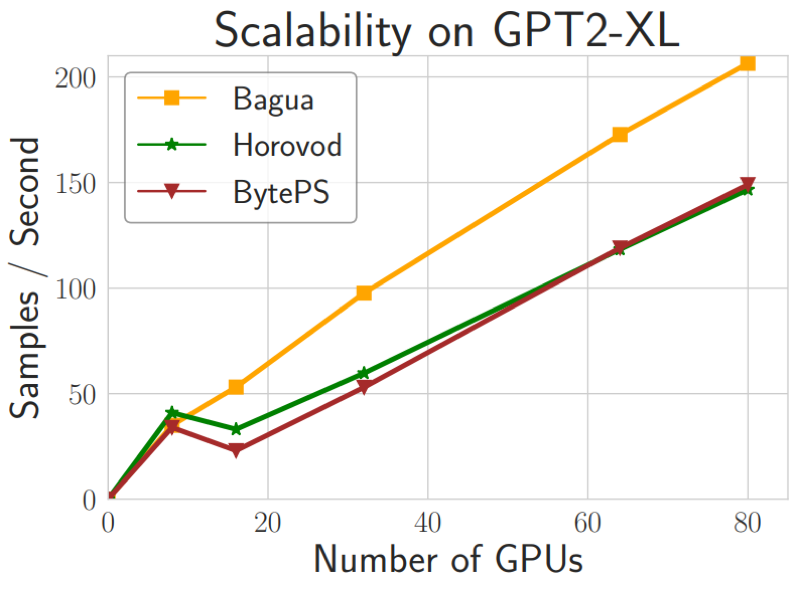
下图展示了各个系统在 GPT2-XL 模型上的训练速度与 GPU 数量之间的关系。GPT2-XL 模型有 1.5 billion 参数,在大模型中具有一定代表性。Bagua 使用 8bitsGrad 算法加速。在测试中分别使用了 8,16,32,64,80 个 V100 GPU 进行测试。同样可以看出 Bagua 的扩展效率相比其他系统有较明显的提升。
3. 不同网络环境对比
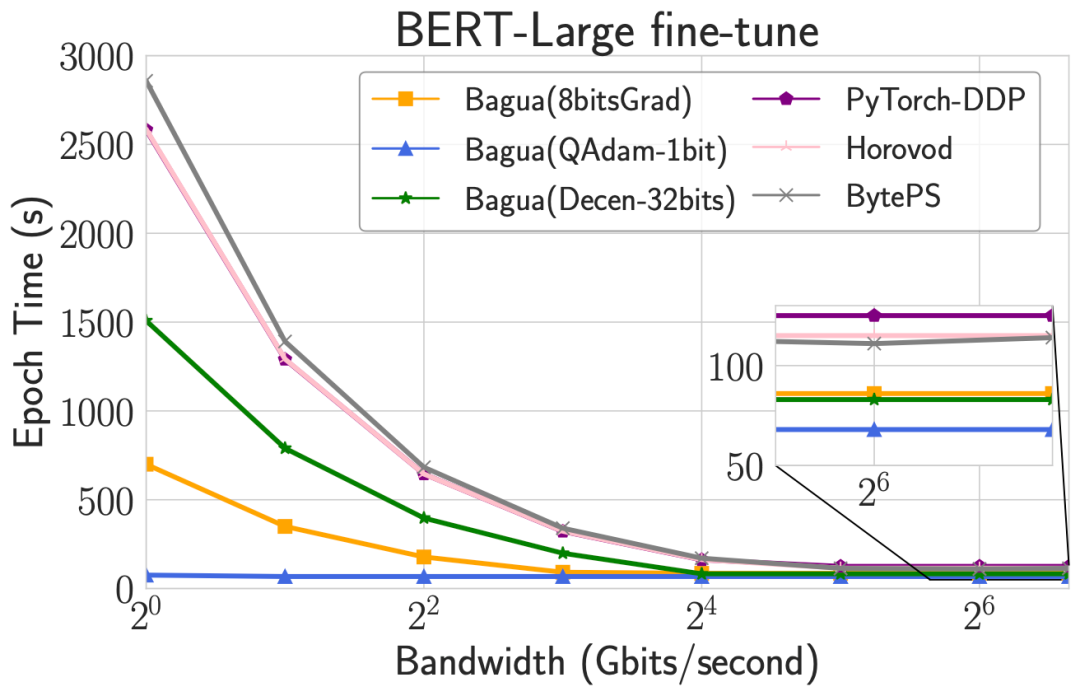
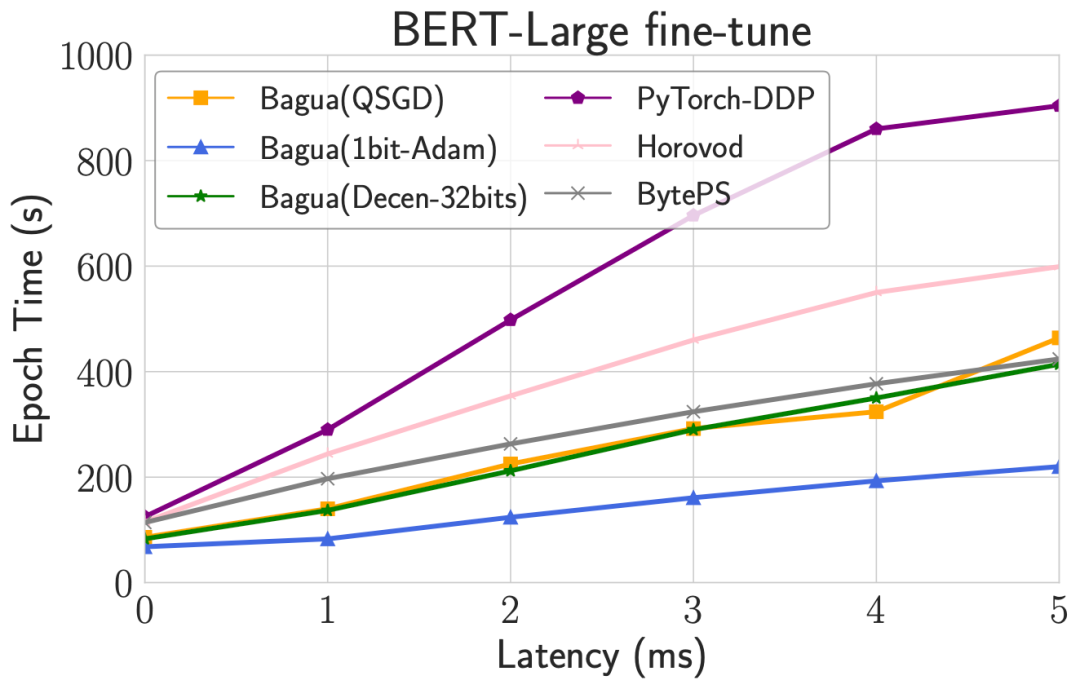
算法是 Bagua 的灵魂。当网络环境变化时,不同的算法会表现出不同的性能特点。在下图中,我们以 BERT-Large fine-tune 为例,调整机器之间网络的带宽和延迟,对比 Bagua 中各个算法的 epoch 时间。可以看出,随着带宽降低,压缩算法的优势会越来越明显,且和压缩程度相关;当延迟逐渐升高,去中心化算法逐渐展现出优势。除此之外,当网络环境不佳时,Bagua 对比其他系统的优势也进一步扩大。
Bagua 使用实例
在已有的训练脚本中使用 Bagua 非常简单,在代码中算法使用者只需要增加如下几行代码对已有模型进行初始化操作即可。以使用 GradientAllReduce 算法为例:
首先,我们需要 import 一下 bagua
import bagua.torch_api as bagua随后,我们可以初始化 Bagua 的进程组:
torch.cuda.set_device(bagua.get_local_rank())bagua.init_process_group()对于数据集的初始化,Bagua 完全兼容 PyTorch 的实现:
train_dataset = ...test_dataset = ...train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset, num_replicas=bagua.get_world_size(), rank=bagua.get_rank())train_loader = torch.utils.data.DataLoader( train_dataset, batch_size=batch_size, shuffle=(train_sampler is None), sampler=train_sampler,)test_loader = torch.utils.data.DataLoader(test_dataset, ...)最后,用户只需要选择要训练的模型和优化器即可以使用 bagua:
# 定义模型model = ...model = model.cuda()# 定义优化器optimizer = ...# 选择 Bagua 算法来使用from bagua.torch_api.algorithms import gradient_allreduce# 实例化 Bagua 算法algorithm = gradient_allreduce.GradientAllReduceAlgorithm()# 对现有模型启用 Bagua 算法model = model.with_bagua( [optimizer], algorithm)这样,使用 Bagua 的多机多卡训练算法就实现完成了。完整例子和更多场景,欢迎参考 Bagua Tutorial 文档(https://github.com/BaguaSys/bagua)。
论文: https://arxiv.org/abs/2107.01499
项目 GitHub 地址:https://github.com/BaguaSys/bagua
参考文献
[1] Dean, Jeffrey, Greg S. Corrado, Rajat Monga, Kai Chen, Matthieu Devin, Quoc V. Le, Mark Z. Mao et al. “Large scale distributed deep networks.” (2012).
[2] Zhengyuan Zhou, Panayotis Mertikopoulos, Nicholas Bambos, Peter Glynn, Yinyu Ye, Li-Jia Li, and Li Fei-Fei. 2018. Distributed asynchronous optimization with unbounded delays: How slow can you go?. In International Conference on Machine Learning. PMLR, 5970–5979.
[3] DanAlistarh, DemjanGrubic, JerryLi, RyotaTomioka, and MilanVojnovic. 2016. QSGD: Communication-efficient SGD via gradient quantization and encoding. arXiv preprint arXiv:1610.02132 (2016).
[4] Dan Alistarh, Torsten Hoefler, Mikael Johansson, Sarit Khirirat, Nikola Konstanti- nov, and Cédric Renggli. 2018. The convergence of sparsified gradient methods. In Proceedings of the 32nd International Conference on Neural Information Processing Systems. 5977–5987.
[5] Anastasia Koloskova, Sebastian Stich, and Martin Jaggi. 2019. Decentralized stochastic optimization and gossip algorithms with compressed communication. In International Conference on Machine Learning. PMLR, 3478–3487.
[6] Xiangru Lian, Ce Zhang, Huan Zhang, Cho-Jui Hsieh, Wei Zhang, and Ji Liu. 2017. Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent. In Proceedings of the 31st International Conference on Neural Information Processing Systems. 5336–5346.
[7] Christopher De Sa, Matthew Feldman, Christopher Ré, and Kunle Olukotun. 2017. Understanding and optimizing asynchronous low-precision stochastic gradient descent. In Proceedings of the 44th Annual International Symposium on Computer Architecture. 561–574.
[8] Xiangru Lian, Wei Zhang, Ce Zhang, and Ji Liu. 2018. Asynchronous decentral- ized parallel stochastic gradient descent. In International Conference on Machine Learning. PMLR, 3043–3052.
[9] Hanlin Tang, Shaoduo Gan, Ce Zhang, Tong Zhang, and Ji Liu. 2018. Com- munication compression for decentralized training. In Proceedings of the 32nd International Conference on Neural Information Processing Systems. 7663–7673.
[10] Ji Liu, Ce Zhang, et al. 2020. Distributed Learning Systems with First-Order Methods. Foundations and Trends® in Databases 9, 1 (2020), 1–100.




