
Airbnb开发的Riverbed是一个Lambda风格的数据框架,用于生成和管理分布式物化视图。该框架支持 50 多个涉及重度数据读取的应用场景,在这些场景中,数据来自 Airbnb 面向服务架构(SOA)平台的多个数据源。它分别使用 Apache Kafka 和 Apache Spark 作为在线和离线处理组件。
Airbnb 观察发现,一些跨多个不同数据存储的复杂查询是导致该平台主要功能出现延迟的罪魁祸首。开发团队不能使用数据库提供的标准的物化视图,因为计算物化视图所需的数据不在单个数据库中。
开发团队尝试使用一种技术来创建分布式物化视图,该技术使用了变更数据捕获(CDC)、流处理和专门用来存储最终结果的数据库。他们仔细权衡了数据处理架构:
Lambda 和 Kappa 是两种实时数据处理架构。Lambda 结合了批处理和实时处理,可以有效地处理大数据量,而 Kappa 仅专注于流处理。Kappa 的简单性提供了更好的可维护性,但在实现回填机制和确保数据一致性方面存在挑战,特别是对于乱序事件。
Riverbed 框架采用了 Lambda 架构,并提供了一种声明式的方式,使用GraphQL为在线(实时事件)和离线(数据回填)组件定义数据查询和计算逻辑。该框架负责并发、版本控制和数据正确性保证,以及与基础设施组件的集成。
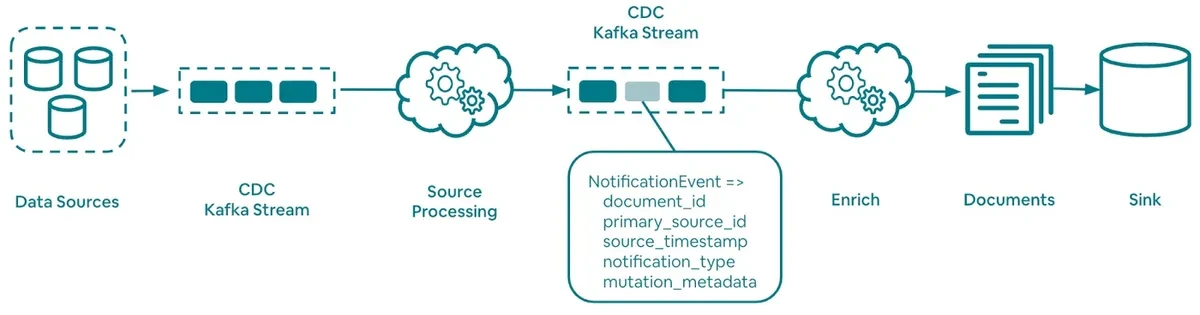
Riverbed 的流式处理(来源:Airbnb工程博客)
对于实时处理,Riverbed 使用Apache Kafka消费数据源发出的变更数据捕获(CDC)事件来进行消息传递。来自 CDC 的事件通过执行用 GraphQL 定义的聚合逻辑来更新物化视图,结果文档存储在物化视图数据库中。为了提高效率,处理是高度并行化和批量化的。
流式管道避免了竞态条件,因为 CDC 事件在 Apache Kafka 中基于物化视图文档的标识符被重新分区,因此对物化视图的更新是顺序完成的。此外,在在线(实时)和离线(批处理)处理之间使用乐观并发控制来避免并发写和潜在的数据不一致。
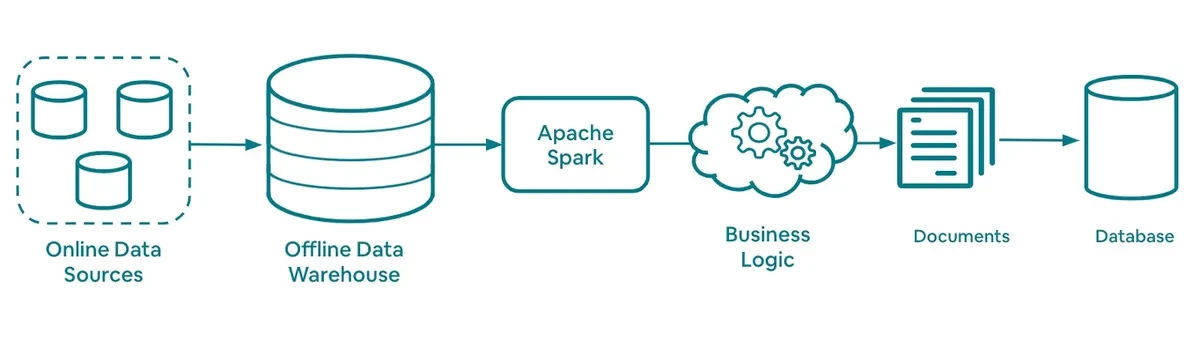
Riverbed 的批处理(来源:Airbnb工程博客)
Riverbed 支持数据回填和协调,以防出现因丢失 CDC 事件导致的实时处理问题。这一部分使用Apache Spark来处理存储每日快照的数据仓库中的数据。该框架基于在 Riverbed 中配置的 GraphQL 定义生成Spark SQL。
Riverbed 目前每天处理 24 亿个事件,写入 3.5 亿个文档,处理与 Airbnb 的支付、搜索、评论、行程和内部产品等功能相关的 50 多个物化视图。
原文链接:
https://www.infoq.com/news/2023/10/airbnb-riverbed-introduction/




