
EC 原理
1. EC 算法
EC 是一种编码容错技术,最早用于通信行业数据传输中的数据恢复。Hadoop3.0 版本将 EC 加入到 HDFS 中。这里简要介绍 EC 中使用广泛的两个算法:XOR Codes 与 Reed-Solomon Codes。
XOR Codes
XOR 编码即“异或”编码,其原理是:数据编码时按照位进行异或运算,数据解码(数据恢复)时则通过结果与其他数据位进行异或操作。这里,我们不妨抽象成数学运算用于解释,例如:1 ⊕ 1 = 0 中,运算位中的任何一位丢失,则能通过另外两位计算得出,但是如果丢失两位则无法恢复。对应到 HDFS 中,实现该算法的 EC 策略是 XOR-2-1-1024k,如果使用 XOR 编码 3 个数据块,则最多能容忍一个数据块丢失。该编码常用于 HDFS 测试。
Reed-Solomon Codes
Reed-Solomon Codes 缩写为 RS 码,使用复杂的线性代数运算来生成多个奇偶校验块,因此可以容忍多个数据块故障。RS 码在使用的时候需指定 2 个参数 RS(n, m),n 代表的是数据块的数量,m 代表的是校验块的数量,校验块由数据块编码产生。RS 编码的编码与解码原理如图 1 所示(网络图)。编码时,利用生成矩阵 B(这里选用范德蒙单位矩阵)与数据列向量 D 的乘积得到信息列向量 D+C;重构时,利用现存的信息列向量 Survivors 与对应的逆矩阵 B'-1 乘积得到原数据列向量 D,从而达到恢复原数据的目的。
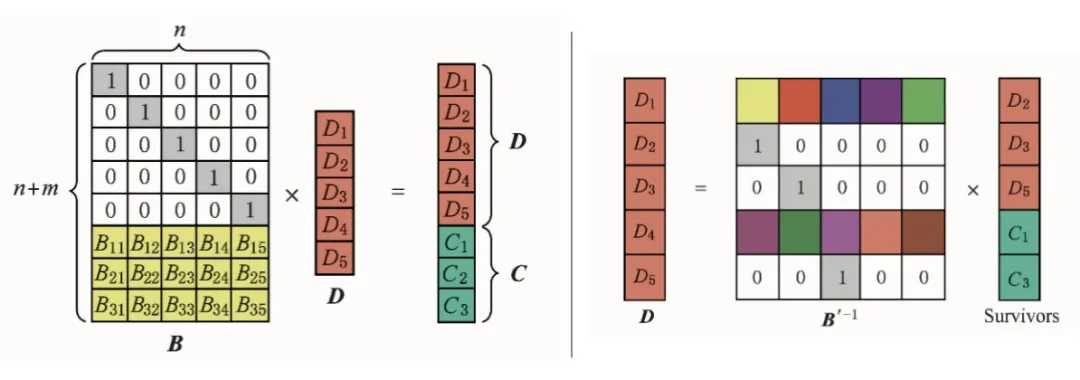
图 1 RS 编码的编码与重构原理
2.HDFS EC 块布局
先回顾一下 3 副本存储的连续存储方式(Contiguous Block Layout),3 副本存储以块(Block)为单位,会将数据连续写入 Block 中,直至达到该 Block 大小(如 128M)再去申请下一个 Block,每个 Block 会有 3 个相同数据的副本存于 3 个 DataNode(DN)上。连续存储示意图如图 2(a)所示。HDFS EC 采用条带条带式存储布局(Striping Block Layout)。条带式存储是以块组(BlockGroup)为单位,横向式地将数据保存在各个 Block 上,同一个 Block 上的不同分段的数据是不连续的。写完一个块组再申请下一个块组。条带式的存储结构图 2(b)所示(图示为 RS(6,3)策略下 1 个 BlockGroup 布局示意图)。
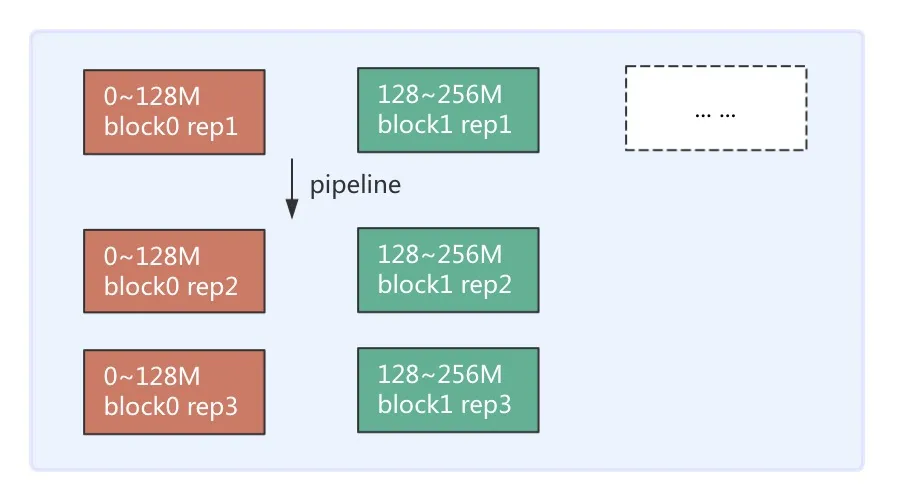
图 2(a) 3 副本存储示意图
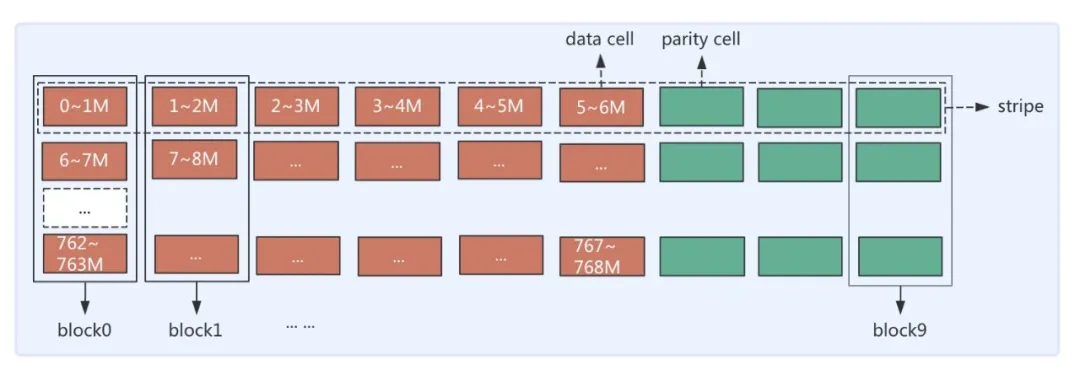
图 2(b) EC 存储示意图
EC 在滴滴的实践
1. EC 落地工作
为了将 EC 存储引入生产环境,我们做了如下的定制和优化。
升级 NameNode 与 DataNode 到 3.2 版本
EC 是 Hadoop3 才有的新特性,因此服务端需要升级。在 EC 投入生产环境之前,滴滴内部已经完成了 HDFS 2.7 版本到 3.2 版本的滚动升级(不停服务,对用户无感知)。版本升级的相关总结见「 HDFS3.2升级在滴滴的实践」。
定制 Hadoop2 兼容 EC 读写客户端
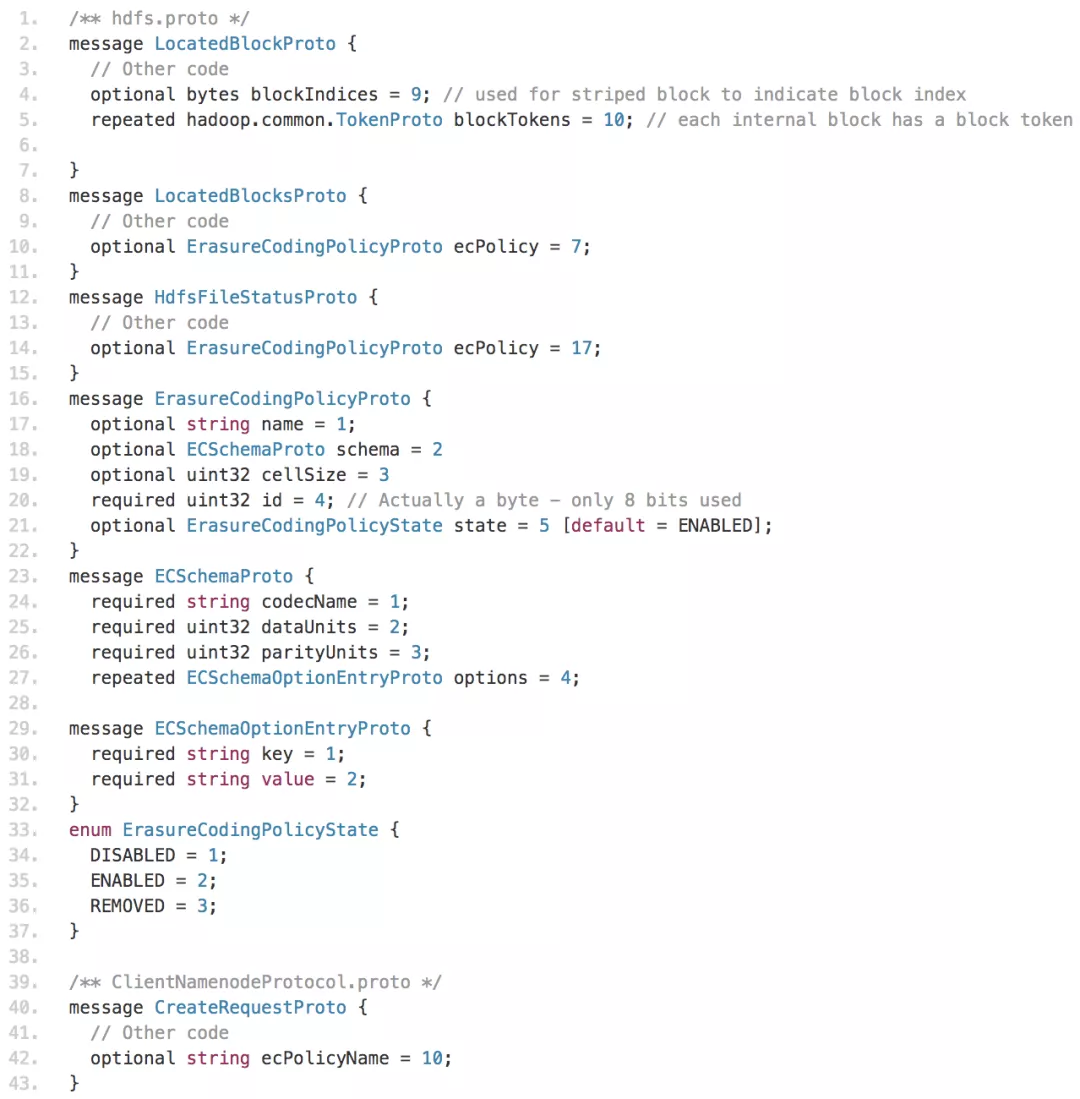
客户端(Client)受到 Spark,Hive,Flink 等很多组件依赖,目前这些组件还不支持 Hadoop3,因此客户端暂时保持 2.7 版本不变,这就要求内部的 Hadoop2.7 版本客户端要做 EC 读写兼容。我们将 Hadoop3.2 中的 hadoop-common、hadoop-hdfs、hadoop-hdfs-client 中关于 EC 读写相关部分移植到 Hadoop2.7 版本。同时,RBF 部分也需要做相应的兼容工作。这里,我们展示一些代码举例,例如,在 hdfs.proto 协议和 ClientNamenodeProtocol.proto 协议中,我们增加了 EC 相关字段:
自研转 EC 系统
目前,将文件转为 EC 存储的途径是将文件写入启用 EC 特性的目录中(社区正在开发更优雅的方式见:HDFS-14978)。将文件/目录 mv 到已启用 EC 的目录不会自动转换存储方式,只有写操作才会。因此,通常执行以下步骤来将副本存储方式的文件转 EC 存储方式:

为了能够可靠地、高效地将副本文件转 EC,滴滴内部做了如下工作:
定制 distcp 工具。在将副本文件转 EC 文件后,必须要保证数据一致性。这就要求复制的源和目标文件 checksum 必须相同。由于存储方式不同,使用传统的 CRC 校验方式不能适用于副本文件和 EC 文件的校准。因此,定制版本将 Hadoop3 中的 COMPOSITE_CRC 校验方式(HDFS-13056)引入到 Hadoop2 的 distcp 中供内部使用。
自研转 EC 系统(Anty 系统)用于周期性(或手动)执行转 EC 作业,以及统计集群 EC 文件存储量、占比等信息。具体介绍见后文的实践场景部分。
定制离线计算物理空间工具
内部资产平台需要周期性地离线分析整个集群的存储空间用于评估成本。若对每个文件使用 du 命令将对 NameNode 产生不小的压力。解析 fsimage 镜像文件可以得到每个文件的逻辑大小,副本文件的物理空间计算非常简单,即逻辑大小 * 副本因子;EC 文件的物理空间由于其条带式存储而复杂许多,这里简要介绍下计算方法。
考虑到最后一个块组的最后一个 strip 有两种情况(如图 3 所示):
第一个块的 cell 写满了,则校验块 cell 大小也写满
第一个块的 cell 只写了 k (k

图 3 最后一个 strip cell 写满情况示意图
为了简化计算,可以不用考虑有多少个块组,只关心一共写了多少 strip。EC 物理存储计算示意图 4 所示。
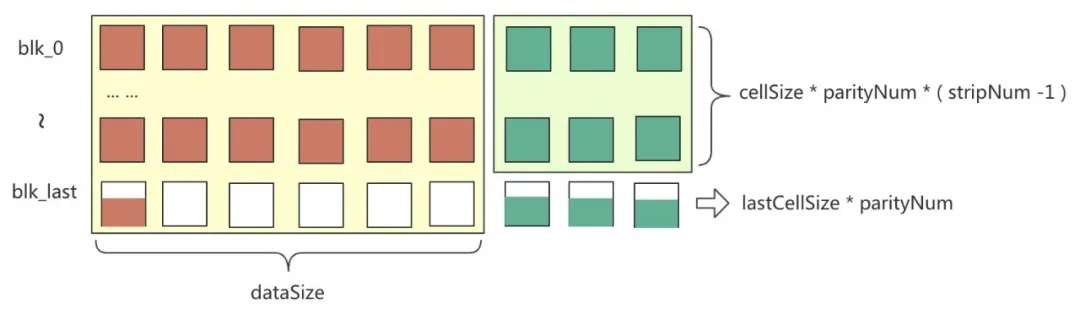
图 4 EC 物理存储计算示意图
部分代码如下所示:
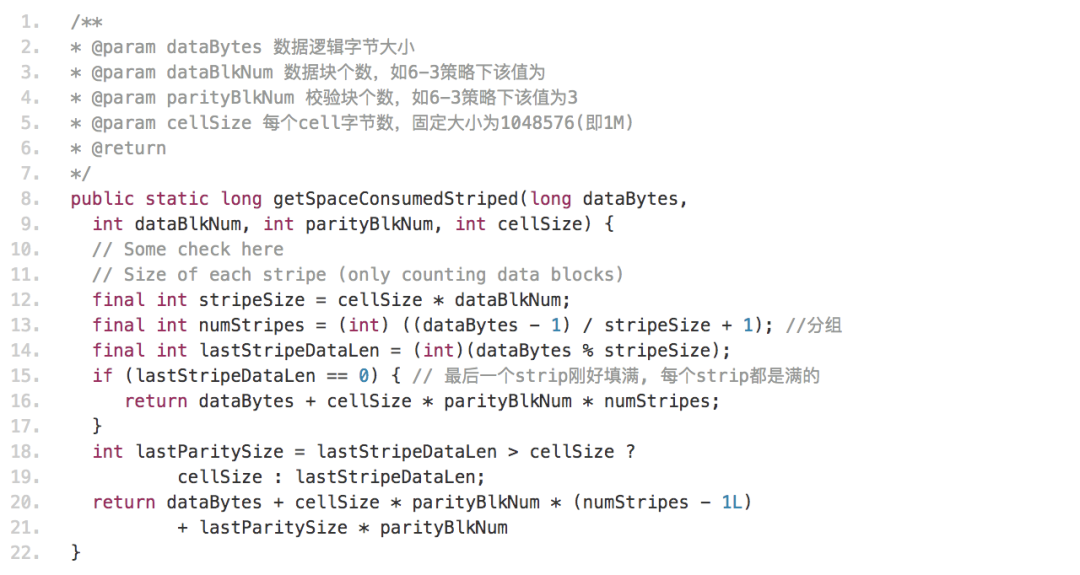
FastCopy 支持 EC 文件的改进
由于在 Federation 集群中会有集群间数据迁移的情况,在 3 副本文件场景下 FastCopy(HDFS-2139)是一个高效的迁移方案,其通过将块进行硬链接的方式来达到快速迁移的目的。由于 FastCopy 不支持 EC 文件操作,滴滴内部版本做了 FastCopy 兼容 EC 文件的改进,极大地方便了 Federation 集群间的数据迁移。
2. EC 的实践场景
首先要考虑的是 EC 策略的选择。通过 hdfs ec -listPolicies 命令可以列出已经实现的 EC 策略。各个策略的一些特性如表 1 所示。
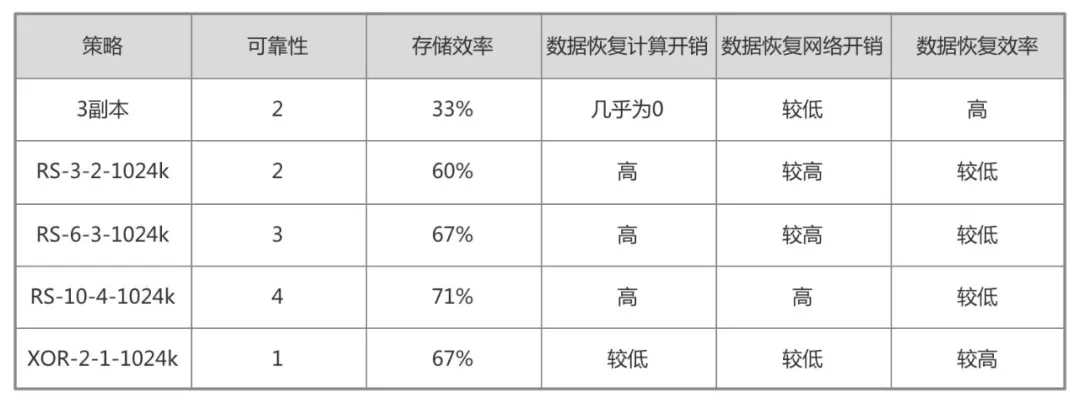
表 1 EC 策略特性对比
综合考虑,滴滴内部只开启了 RS-6-3-1024k 策略。考虑到 EC 策略目录的规范性,目前只支持管理员设置 EC 策略。
实践 1:冷数据转 EC 存储
国内离线集群已有上百 P 的逻辑数据,数据量的增长对集群的存储也带来了一定压力。为了节约存储成本,滴滴内部对冷数据进行了转 EC 存储。考虑到并不是所有 3 副本文件在转 EC 后都有更少的空间存储,这里需要对转 EC 的文件做大小限制。在 RS(6,3)策略下,我们限制待转 EC 的目录下的非空平均文件大小>=6M。数据源选择如图 5 所示。

图 5 转 EC 文件数据源
转 EC 存储流程如下(自研 Anty 系统将自动化完成所有过程):
周期性地(每天)从 fsimage 表中计算出需要转 EC 的叶子目录
每个目录的转 EC、替换原文件操作记为一次 pipeline。多个 pipeline 并行操作进行转 EC
每个目录的转 EC 状态记为该目录的生命周期 lifecycle,生命周期有变化时更新到 mysql,用于前端页面对转 EC 情况的展示
整个转 EC 流程如图 6 所示。
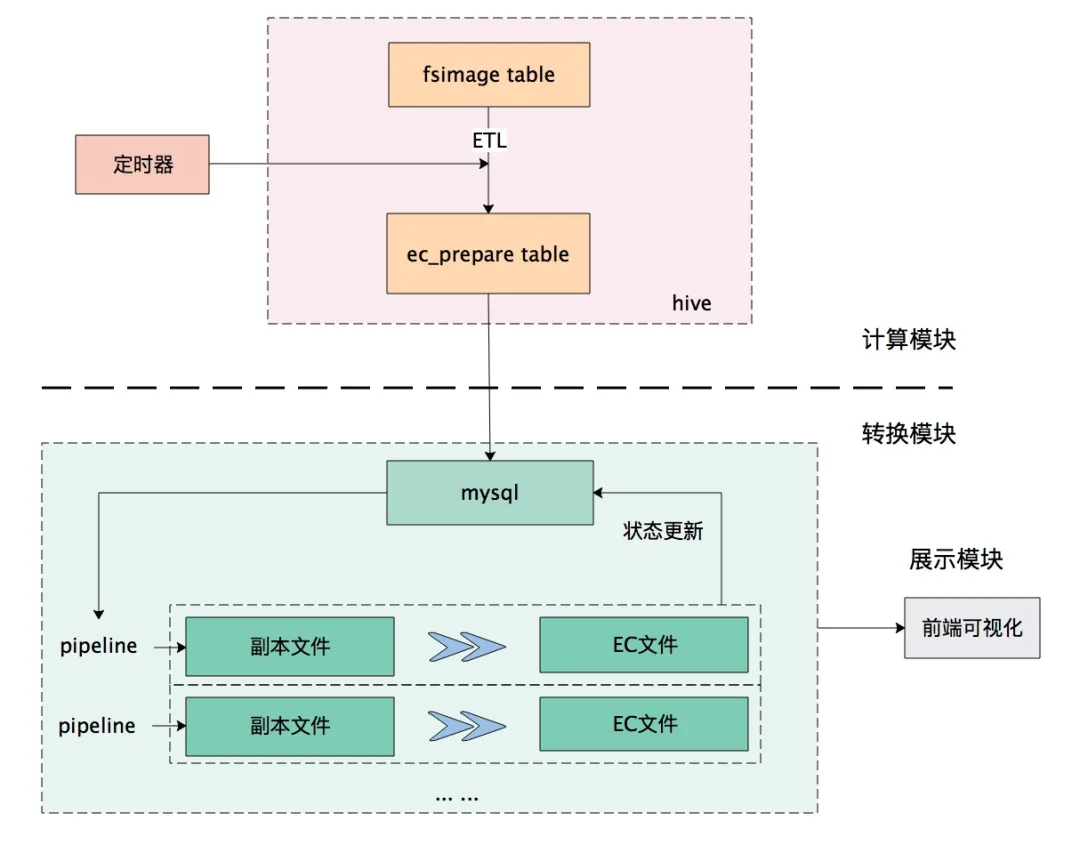
图 6 转 EC 流程图
经过半年多的实践,生产环境已有大量符合条件的冷数据进行了转 EC 存储,整个集群的 EC 文件存储效率(EC 物理存储/EC 逻辑存储)在 1.500 ~ 1.505 之间,节省了可观的物理空间。
实践 2:核心数据跨机房 EC 备份
为数据容灾考虑,01 机房的核心数据将每天增量地备份到 02 机房。这种场景非常适合将 02 机房数据使用 EC 存储。其备份流程如下:
通过数据资产平台每天的定时分析,获得 01 机房核心增量数据
自研的 Anty 系统将增量核心数据通过定制的 distcp 写到 02 机房存储为 EC 文件
系统内部细节不再赘述,整体流程如图 7 所示。
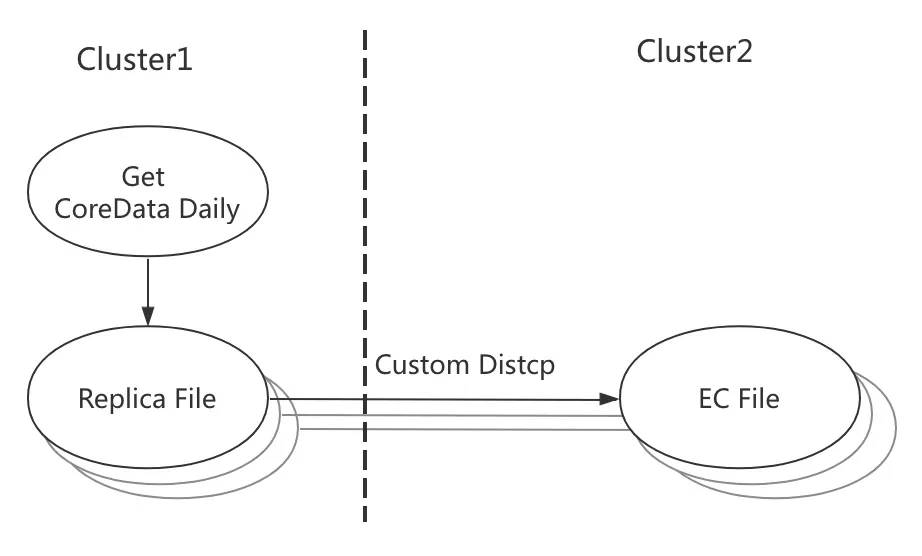
图 7 核心数据跨机房备份流程示意图
3.遇到的问题及解决办法
在 EC 存储落地的过程中,我们遇到过一些问题,有些问题社区高版本已经解决,有些问题我们已提给社区。这里,我们列举一些典型的问题做简要说明。
写 EC 文件客户端 hang 住问题
在转 EC 的过程中,偶现客户端线程 hang 住问题。详情见(HDFS-15398)。
DN 下线失败问题
下线过程中,在某些场景下触发 DN 下线失败问题。详情见(HDFS-14920、HDFS-14847)。
DN 重构 EC 块有脏数据问题
DN 由于读超时出现 NPE,使用脏数据重构 EC 块问题。引入(HDFS-15240)解决。
Standby 内存泄露问题
线上出现 StandbyNN 内存偏高问题。经 MAT 及监控指标(dfs.FSNamesystem.PendingDataNodeMessageCount)发现 PendingDataNodeMessages 类存在内存泄露,如图 8。引入(HDFS-14687)解决。

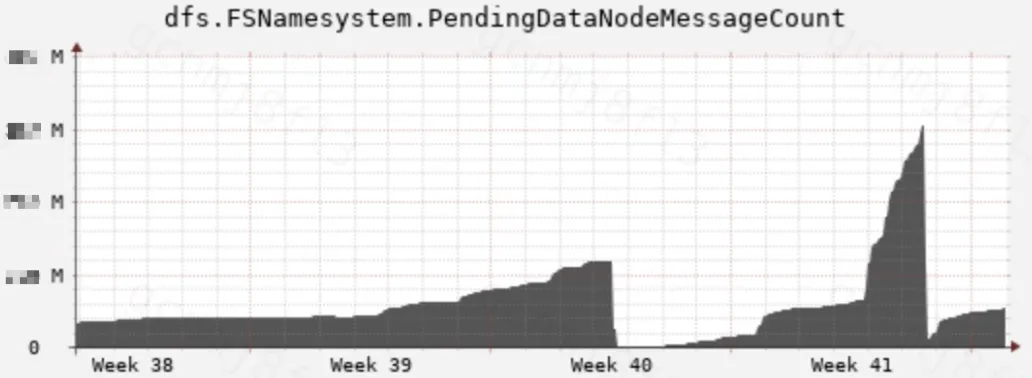
图 8 standby PendingDataNodeMessages 内存泄露示意图
总结与展望
相比 3 副本存储,EC 存储也有一些不足的地方,如读写性能有损失(滴滴暂未开启 intel isa-l 加速库)、小文件不适合转 EC 等。HDFS EC 还处于发展的第一阶段,社区也在持续优化,滴滴内部也紧跟社区步伐。相信随着 HDFS 社区的不断发展,越来越多的公司将受益于 EC 技术。
参考文献:
[1] https://issues.apache.org/jira/browse/HDFS-7285
头图:Unsplash
作者:Bean Henry
原文:https://mp.weixin.qq.com/s/AW0MmiBxTlkweJFaluu4vQ
原文:HDFS EC 在滴滴的实践
来源:滴滴技术 - 微信公众号 [ID:didi_tech]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




