Datomic 是一种以简单服务组合为设计目标的新数据库。它试图在传统 RDBMS 的功能与新一代冗余分布式存储系统的弹性可伸缩性方面找到一种平衡。
动机
Datomic 力图完成以下几个目标:
- 提供可靠的信息模型,而避免原地更新(update-in-place)
- 充分利用冗余的可伸缩存储系统
- 提供 ACID 事务和一致性
- 在应用中支持声明性数据编程
任何数据库系统都需要有支持它的数据模型观点。传统的关系型数据库支持与某种世界更新语义(world-update semantic)关联的关系模型。与该领域相对的另一端,一些新的 NoSQL 系统对它们自身包含的信息却知之甚少,仅仅在保证最终一致性的情况下以简单的键值方式存储 blobs。Datomic 将数据库视为信息系统,而信息是一组事实(facts),事实是指一些已经发生的事情。鉴于任何人都无法改变过去,这也意味着数据库将累积这些事实,而非原地进行更新。虽然过去可以遗忘,但却是不能改变的。因此,如果某些人“修改了”他们的地址,Datomic 会存储他们拥有新地址这个事实,而非替换掉老的事实(它只是在这个时间点被简单的回收了)。这个不变性(immutability)带来了很多重要的架构优势和机会。
目前在定义高可用、冗余、分布式和可扩展存储系统方面已经取得了很多伟大的成就,比如 Amazon 的 Dynamo 。为了避免单片(monolithic)设计,Datomic 力图对这些系统提供直接的支持,为用户提供对存储系统、位置、成本以及可扩展性等特性的选择。
ACID 事务对很多的业务流程来说都相当重要。正如我们所见,虽然对 ACID 进行扩展非常困难,但是 Datomic 将事务从读和查询中分离出来,这样一来可以最大化事务组件的吞吐量。也就是说,我们在这里做了明确的折衷,重点在于 Datomic 赞成使用 ACID 事务而非无限制的写扩展性,并专注于适合折衷的领域。一致性这一特性可以极大的简化系统,带来了更加健壮的解决方案,如果没有足够的理由我们不应该丢弃它。(会有某些时候,存在足够的理由,但是请确认是否对你适用!)
传统的关系型数据库提供了超强逻辑的,声明性的和面向集合的语言来操纵数据。不幸的是,这种强大的能力只局限在服务器端,一旦数据被应用获取后,往往就会陷入循环和命令式操纵的海洋。Datomic 提供了(根本上来说是)一种分布式索引,并允许声明性组件在应用服务器层驻留。查询引擎能够操纵 Datomic 托管的数据和内存中的数据源,以此提供一种一致、高级别的方式。
全局关注点
在 Datomic 的架构之中遍布着很多的概念,其中包括:
- 单一和组成。系统应该由服务的集合组成,而每个服务都只做好一件事情,并且对其他事情知之甚少或不知道。较为推崇的是,一些简单的组件如果在某个特定领域已经存在,例如存储或缓存,那它们应该是可以被集成的。
- 存储和查询的可扩展性和灵活性。如果你需要更多的存储或查询性能时,你应该可以动态地增加机器。同样,如果需求减少,只要移除它们,而不需要重新配置。
- 位置灵活性。特定组件不需要关心其他组件所在的位置。
- 普遍不变性。编程时使用原地更新这种想法已经过时了。大多数编程工作都应该可以通过不变的值来完成。在 Datomic 中,甚至是数据库自身都可以被作为一个值来对待。
- 数据即接口。系统应该是可编程的。为此,主要的接口应该是可以数据驱动的,而非充斥着语法的字符串。在 Datomic 中,模式、事务、查询和查询结果都会以 lists 和 maps 这样的普通数据来定义。
逻辑模型
Datomic 包含如下服务:
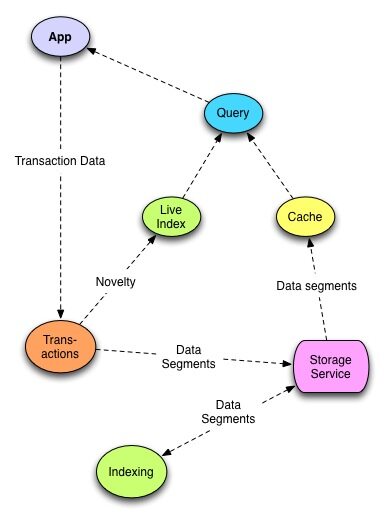
- 存储
- 事务协调和通知
- 索引
- 应用数据模型和查询
- 缓存
对于存储所需的能力已被最小化——主要存储小型 (<64k)blob。系统使用存储的方式与传统数据库使用文件系统的方式非常类似——主要是用于日志和索引片段,这些片段是不可变的。此外,它会使用一个较小的键值集合(set of keys)来作为日志和索引根节点的引用,这是对存储唯一的可变使用方式。同是还需要存储系统提供一致性写 / 读,而目前,可以支持基于条件或版本的 put 操作。
所有信息被添加到数据库时都会采用一种事务协调器提交新内容(novelty)的方式。协调器会序列化所有的事务,并确保 ACID 的语义,将新信息写入存储中的日志片段。根据持久化存储,协调器会通知事务提交者和事务中受新信息作用的任意相关部分。
存储的第二个用处是索引,索引事实上是数据库中数据的一些集合,它们以不同的顺序排序,并以树的形式来表示数据片段。索引服务会定期从存储的日志中提取新信息来生成这些排过序的集合。因为索引片段不可变,所以索引进程会一直创建新的索引树,该索引树会尽可能与之前的索引树共享结构。
Datomic 为应用服务器层提供了数据库的视图,使得数据库好比是内存中的值。这个数据库值提供的视图就像是一幅包含了所有实体及其属性的图片。此外,该数据库对象自身提供了对其索引的直接可遍历访问功能。最后,数据库值可以在可声明查询中充当参数。为了呈现数据库“当前”的最新视图,数据库对象必须将最近的索引与在内存中的新内容索引(自从上次持久化索引被创建后发生的新变化)进行合并。
Datomic 也为应用服务器提供了一个嵌入式查询引擎,该引擎可以像操作内存中的集合一样操作数据库值。
Datomic 模型完整地集成了缓存。与一些典型的场景不同,在其中缓存被视为应用层问题,并用于缓存查询结果以减轻服务器负载,Datomic 可以自己管理缓存,它亲自缓存索引片段,并将它们从存储加载到内存或应用进程中。这个能力可以缓存那些不变索引片段和分布式查询的查询结果。
物理模型
逻辑模型以一种直接的方式映射到物理模型,大多数的服务都具有独立的子系统。
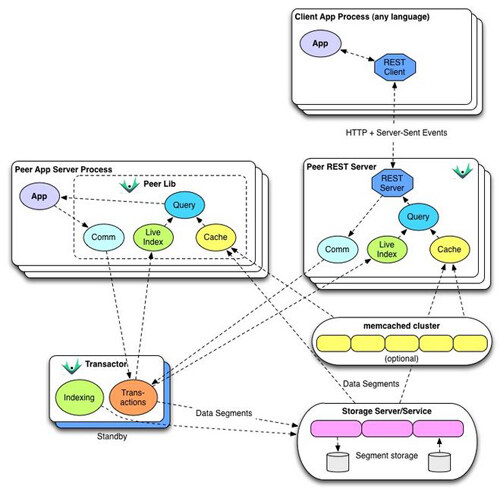
- 存储服务
也许有些出人意料,Datomic 并不在磁盘上做文章。取而代之的是,它集成了各种类型的存储服务器和系统,只要他们能满足前面提到的那些最小的需求。以下是支持存储的一些例子:
- 进程内内存(无存储)。Datomic 可以完全运行在内存里,进程中,这对开发和测试来说是非常友好的。
- SQL。任何遵守 JDBC 的 SQL 数据库都可以充当存储。
- 键 / 值存储。下一代分布式冗余键 / 值存储,例如 Amazon 的 DynamoDB 就非常的适合 Datomic。
- 内存网格。分布式数据网格,例如 Infinispan ,可以在冗余内存足够耐用时被使用。
以上的存储“服务规范(servicification)”会带来大量的灵活性。值得注意的是,在很多情况下(比如 SQL 和 Infinispan),Datomic 不需要专用的存储资源。你只需在现有的 SQL server 上简单添加一个独立的表,就可以马上使用 Datomic 了。当和 DynamoDB 这样的高扩展性存储一起使用时,Datomic 将获得同样弹性的读扩展性。这是基于组件架构的另一个优势——读写的扩展可以根据不同的权衡点进行正交决策(orthogonal decisions)。
Datomic 封装了不同的存储,并可以使用统一的方式在其上进行操作。你只需要简单地通过向 / 从一个 S3 存储段(bucket)或本地目录进行导入 / 导出,就可以将系统从一种存储迁移到另一种上。同时,也可以通过修改少量的属性文件和一个不同的 URI,就可以将你的应用从一种存储迁移到另一种上。
- 事务处理器(Transactor)
事务处理器是一种致力于协调事务的进程,它接受来自应用服务器节点的持久化连接。事务处理器在这些连接上接受事务,并序列化它们,将日志片段提交到存储,然后将最新的内容广播到所有的连接节点。目前,索引也会以后台进程的形式在事务处理器上运行。可以通过再运行一个备用事务处理器来确保高可用。由于存储事实上是被共享的,所以没有必要在活跃的事务处理器和备用者之间建立专用的连接。事务处理器本身不具备任何存储,所以也不会对任何的读与查询负载服务。因此,相比于一个单片模型(monolithic model),它的争用情况会少很多。也就是说,当你需要无限制写扩展时,Datomic 并不是一个好的选择。
- 节点库(Peer library)
一个 JVM 库提供了数据库值代码、连接代码、内存索引和查询引擎,它被称为“节点(peer)”库,这个库被充分授权并运行在应用服务器上。该库提供了 Java API 并适用于 Java, Clojure, Scala, JRuby, Groovy 和其他所有的 JVM 语言。每个节点可以直接(只读)访问存储,节点还持有索引片段的顶级缓存,这些片段可以被扩展成 JVM 对象。
节点级别的编程与客户端服务器的数据库编程有相当大的区别。虽然节点并不是完整的副本,但它们可以快速缓存工作集,而数据库感觉上就像是内存中的对象。该功能并不是个装饰,它由一种 ORM 提供。此外,查询是局部的。因此,查询并不运行在数据库的上下文中,而是将数据库作为查询中的参数。查询可以将多个数据库,以 and 或 or 的关系生成数据库组合或普通的集合。
Datomic 自带了一种 Datalog 查询引擎。Datalog 是一门容易学习、面向模式的查询语言,它非常适合 Datomic 的数据模型和程序集(programmatic collections)。它是面向集合和关系的,就像 SQL 一样。你会有这样一种感觉,即使查询引擎是正交的,作为直接索引访问也会提供支持其他查询语言的使用。例如,Clojure 用户可以使用 Clojure 中类似 Prolog 的 core.logic 库来更好的查询 Datomic。
所有这些应用程序的交互是通过一个数据驱动,表面粒度极小的 API 发生的。
- memcache
Datomic 可以自动使用一个 memcache 集群作为在进程内节点缓存和存储间的二级缓存。如上所述,这是 “属于”索引片段查询的缓存。因为它们是不可变的,它们是应答(answers)的来源,而不是具体的应答,这对缓存索引片段有着极大的影响力,没有缓存通常的复杂性,即缓存一致性、失效等。事务处理器可以被配置预先将数据写入 memcache,就像写入存储一样,这样一来即使是首次读都可能会促使缓存被命中。这样可以新增一层来提高可扩展性和性能,而不是在基础存储上(举例,如果是一个单实例的 SQL server)。当与存储一起使用时,Datomic 不需要专用的 memcache 集群。它使用基于 UUID 的键,这样可以避免与同一缓存的其他用途发生冲突。
REST API 和客户端
Datomic 自带了一个 REST 组件,可以切换进程来在 HTTP 服务中运行节点库,从而支持 Datomic API。该组件可以被非 JVM 语言或者是更轻量级的客户端使用,它们不需要节点那些完整的进程内功能。REST 是完全可发现并可以通过 text/html 媒体类型来自行描述的。应用通常只要请求 application/edn 类型,这可以支持以 edn 格式的数据来进行提交。
REST API 的客户端会丧失少许与数据库缓存共享进程的一些好处,然而仍保留着模型的重要特性——以数据编程,查询可以跨越数据源,或者合并程序数据,并且独立的查询可以基于相同的数据基础而无需任何事务,这是因为实际情况中特定数据库值可以具有固定链接(permalinks)。
作为节点 API 的调用者,客户端以相同结构的接口传递和接收完全相同的数据结构。这不是在比较 REST API 和 peer API——是说以数据编程是个好的想法,不管是有线还是无线。
总结
我希望本文带给了你关于 Datomic 架构最本质的了解以及它的一些细节。如果什么都没有,它起码提供了很多关于不变性的架构价值的例子。数据库作为服务的组合,例如 Datomic,将可能变得更加通用。正如我们抛弃单片架构(monolithic architectures)的局限性,尝试保留他们的功能,并最终找到了新的方式。
Datomic 有多个方面,包括信息模型、进程具体化、将数据库作为值、查询模型和时间模型等,这些方面都是与架构协同工作的。你可以从 Datomic 文档学到更多的内容。
关于作者

Rich Hickey, Clojure 的作者及 Datomic 的设计者,是一位在多个领域拥有超过 25 年工作经验的软件工程师。Rich 的工作涉及调度系统,广播自动化,音频分析,指纹识别,数据库设计,收益管理,选举投票系统以及针对多种语言的机器监听。
原文链接: The Architecture of Datomic
感谢侯伯薇对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




