
作者 | UCloud 优刻得
微调模型可以让模型更适合于我们当前的下游任务,但当模型过大或数据集规模很大时,单个加速器(比如 GPU)负载和不同加速器之间的通信是值得关注的问题,这就需要关注并行技术。
并行化是大规模训练中训练大型模型的关键策略,本文 UCloud 将为大家带来“加速并行框架”的技术科普和实践。在学习 Accelerate、DeepSpeed、Megatron 加速并行框架之前,我们先来了解一下数据并行和模型并行。
1 数据并行与模型并行
1.1 数据并行
数据并行可分为 DP(Data Parallelism,数据并行)、DDP(Distributed Data Parallelism,分布式数据并行)、ZeRO(Zero Redundancy Optimizer,零冗余优化器)3 种方式。
其中,DP 的做法是在每个设备上复制 1 份模型参数,在每个训练步骤中,一个小批量数据均匀地分配给所有数据并行的进程,以便每个进程在不同子集的数据样本上执行前向和反向传播,并使用跨进程的平均梯度来局部更新模型。
DP 通常用参数服务器(Parameters Server)来实现,其中用作计算的 GPU 称为 Worker,用作梯度聚合的 GPU 称为 Server,Server 要和每个 Worker 传输梯度,那么通信的瓶颈就在 Server 上。受限于通信开销大和通信负载不均的因素,DP 通常用于单机多卡场景。
DDP 为了克服 Server 的带宽制约计算效率,采用 Ring-AllReduce 的通信方式。在 Ring-AllReduce 中,所有的 GPU 形成 1 个环形通信拓扑,在 1 轮环形传递后,所有 GPU 都获得了数据的聚合结果,带宽利用率高。在 Ring-AllReduce 的每 1 轮通信中,各个 GPU 都与相邻 GPU 通信,而不依赖于单个 GPU 作为聚合中心,有效解决了通信负载不均的问题。DDP 同时适用于单机和多机场景。
ZeRO 采用的是数据并行结合张量并行的方式,后面将详细展开讲解。
1.2 模型并行
模型并行(MP,Model Parallelism)可分为流水线并行(PP,Pipeline Parallelism)和张量并行(TP,Tensor Parallesim),都是解决当 GPU 放不下一个模型时,而将模型拆分到不同的 GPU 上的方法。
1.2.1 流水线并行
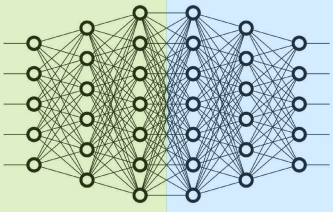
如上图所示,PP 将模型在 Layer 层面上进行水平切分,不同切分部分在不同 GPU 上运行,并使用微批处理(Micro-Batching,在 1 个 Batch 上再划分得到 Micro-Batch)和隐藏流水线泡沫(Pipeline Bubble,GPU 空转的部分)。由于水平分割和微批处理,模型功能(如权重共享和批量归一化)的实现都很困难。
1.2.2 张量并行
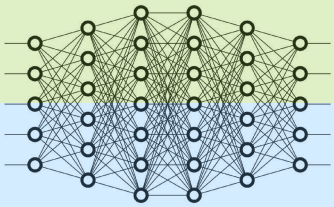
如上图所示,TP 在模型的 Layer 内部进行切分,所有 GPU 计算所有层的不同部分在单个节点之外无法高效扩展,这是由于细粒度计算和昂贵的通信所致。
2 Megatron
2019 年英伟达发布的 Megatron 是一个基于 PyTorch 的分布式训练框架,实现了一种简单高效的层内模型并行方法(TP,是切分矩阵的形式实现的),可以训练具有数十亿参数的 Transformer 模型。Megatron 不需要新的编译器或库更改,可以通过在 PyTorch 中插入几个通信操作来完全实现。当然 Megatron 目前支持 TP、PP、SP(Sequence Parallelism)和 Selective Activation Recomputation,此处对 TP 进行讲解。
2.1 切分矩阵的方式
切分矩阵的方式可按行或者按列,其目的是为了当 1 个模型无法完整放入 1 个 GPU 时,让这个模型能塞到多个 GPU 中[1]。
2.1.1 对于 MLP 层的切分
MLP(多层感知机)的计算可表示为 Y=GeLUXA。如果将输入数据 X 按列切开,模型权重 A 按行切开。由于计算结果为 Y=GeLUX1A1+X2A2,然而 GeLUX1A1+X2A2≠GeLUX1A1+GeLUX2A2,所以这种切割方式必须在 GeLU 计算前,先执行一次 All-Reduce,也就产生了额外的通讯量。
那么,对将输入数据 X 在每个 GPU 上复制一份,模型权重 A 按列切开,则有
GeLUY=GeLUXA1GeLuXA2,就无需额外通信。综上,MLP 层的第 1 层将权重 A 按列切开,将权重 B 按行切开。如图所示:
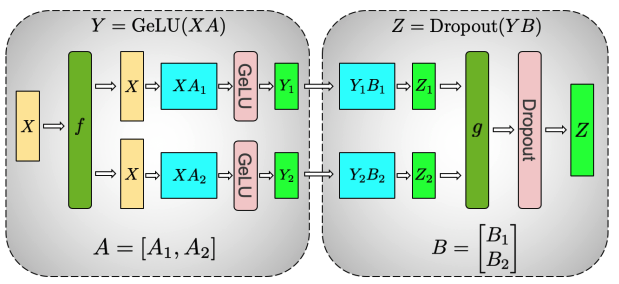
上图中的 f 和 g 分别表示 2 个算子,每个算子都包含一组 Forward + Backward 操作,也就是前向传播和后向传播操作。具体[2]可表示为:
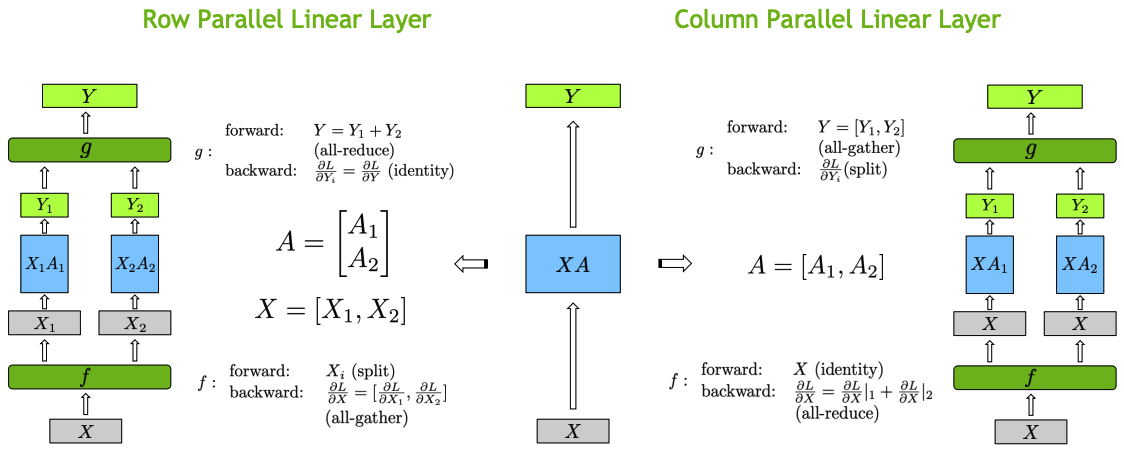
左侧为输入数据 X 按列切开,将权重矩阵 A 按行切开。右侧为将输入数据 X 复制到 2 个 GPU 上,将权重矩阵 A 按列切开。当然,这里是 2 个 GPU 的例,同理可类推到多个 GPU 的情况。
2.1.2 对于 Multi-Head Attention 层的切分
Multi-Head Attention,也就是多头注意力,其结构如下图所示:
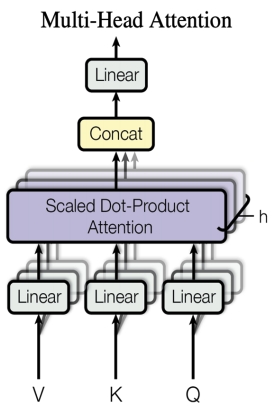
其每个 Head 本身就是独立计算,再将结果 Concat 起来,就可以把每个 Head 的权重放到 1 个 GPU 上。当然,1 个 GPU 上可以有多个 Head。
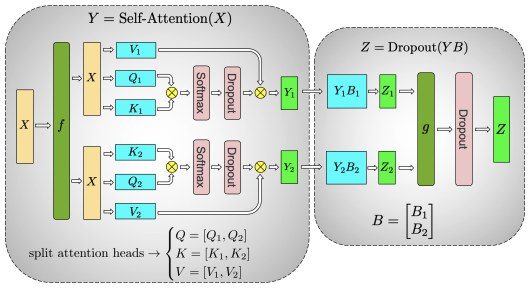
如上图所示,先把输入数据 X 复制到多个 GPU 上,此时每个 Head 分别在 1 个 GPU 上。对每个 Head 的参数矩阵 Q、K、V 按列切开,切分原理、算子 f、算子 g 与 MLP 层切分章节中的描述一致。之后,各个 GPU 按照 Self-Attention 的计算方式得到结果,再经过权重 B 按行切开的线性层计算。
2.2 MLP 层和 Multi-Head Attention 层的通信量
2.2.1 MLP 层的通信量
由上述章节可知,MLP 层进行 Forward 和 Backward 操作都有一次 All-Reduce 操作。All-Reduce 操作包括 Reduce-Scatter 操作和 All-Gather 操作,每个操作的通讯量都相等,假设这 2 个操作的通讯量都为φ,则进行一次 All-Reduce 的通讯量为 2φ,MLP 层的总通讯量为 4φ。
2.2.2 Multi-head Attention 层的通信量
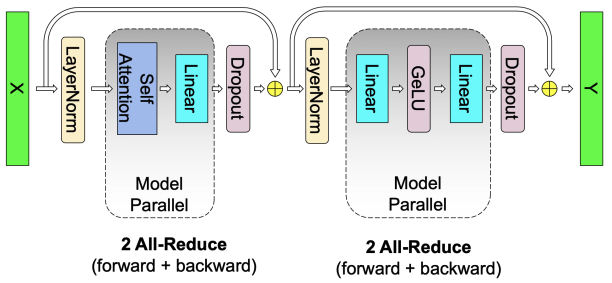
由上图可知,Self-Attention 层在 Forward 和 Backward 中都要做一次 All-Reduce,总通讯量也是 4φ。
2.3 张量并行与数据并行的结合
2.3.1 MP+DP 混合的结构
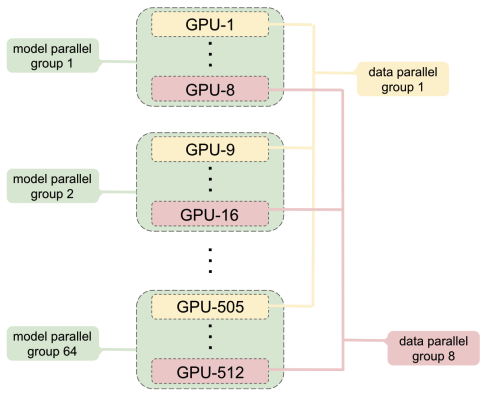
由上图可知,中间每个虚线框表示一台机器,每台机器有 8 个 GPU,合计 512 个 GPU。同一个机器内的 1 个或多个 GPU 构成 1 个模型并行组,不同机器上同一个位置的 GPU 构成 1 个数据并行组,图中有 8 路模型并行组和 64 路数据并行组。
2.3.2 MP 与 MP+DP 的通信量对比
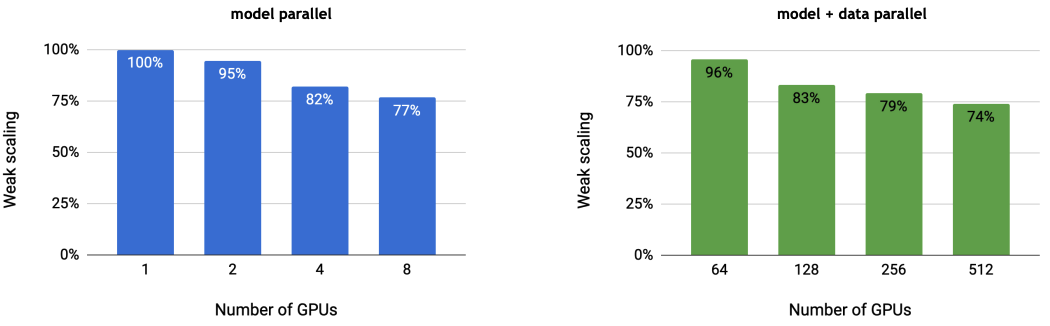
左图是 MP 模式,可以看到单个 GPU 的计算效率为 100%。随着 GPU 个数的增加,通信量增大,GPU 的计算效率有一定的下降。右图是 MP+DP 模式,64 个 GPU(可理解为 64 台机器,1 台机器 1 个 GPU,此时相当于 DP 模式)的计算效率有 96%之高,是由于 DP 在计算梯度时,可一边继续往下做 Backward,一边把梯度发送出去和 DP 组内其他 GPU 做 All-Reduce。同理,当 GPU 个数增多,GPU 的计算效率也会下降。
3 DeepSpeed
2020 年微软发布了分布式训练框 DeepSpeed 和一种新型内存优化技术 ZeRO-1,极大地推进了大模型训练的进程。后续,微软又陆续推出 ZeRO-2、ZeRO-3 技术等,ZeRO 这 3 个阶段称为 ZeRO-DP(ZeRO-Powered Data Parallelism)。另外,DeepSpeed 还支持自定义混合精度训练处理,一系列基于快速 CUDA 扩展的优化器,ZeRO-Offload 到 CPU 和磁盘/NVMe。DeepSpeed 支持 PP、DP、TP 这 3 种范式,支持万亿参数模型的训练。
其中,ZeRO-DP 用来克服数据并行性和模型并行性的限制,通过将模型状态(参数、梯度和优化器状态)在数据并行进程之间进行分片,使用动态通信调度实现在分布式设备之间共享必要的状态。ZeRO-R 技术可减少剩余的内存消耗。在模型训练过程中产生的激活值(Activations)、存储中间结果的临时缓冲区、内存碎片,我们称之为剩余状态。
3.1 ZeRO-DP
3.1.1 ZeRO-DP 的 3 个阶段
ZeRO-DP[3]的 3 个阶段,可在参数 zero_optimization 中设置。比如:
其中,stage_number 可写 1、2、3,当然也可以写 0。ZeRO-1 只对优化器状态进行分片,ZeRO-2 在 ZeRO-1 的基础上还对梯度分片,ZeRO-3 在 ZeRO-2 的基础上还对模型参数分片。当 stage_number 为 0 时,不做任何分片处理,此时相当于 DDP。
在 ZeRO-DP 优化的 3 个阶段下,1 个模型状态在各个 GPU 上内存消耗情况,如下图所示:
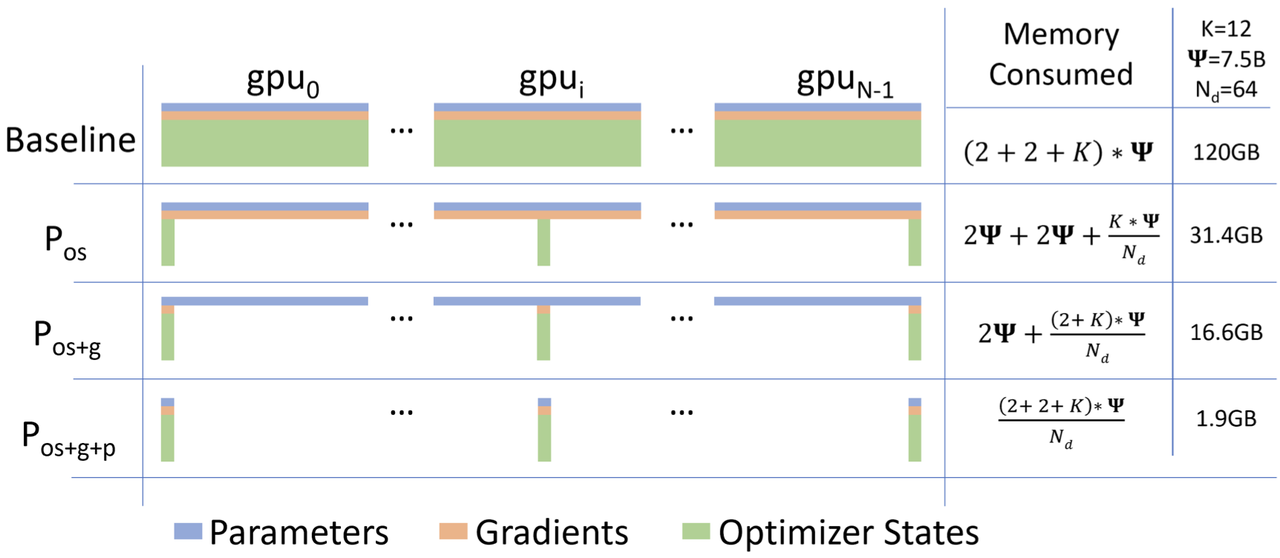
其中Ψ表示模型大小(参数数量),K 表示优化器状态的内存倍增器。Nd 表示数据并行度,也就是 GPU 的个数。
Pos 对应优化器状态分片,也就是 ZeRO-1,内存减少 4 倍。
Pos+g 对应添加梯度分片,也就是 ZeRO-2, 内存减少 8 倍。
Pos+g+p 对应模型参数分片,内存减少与数据并行性程度 Nd 线性相关。
论文中提到,使用 64 个 GPU(Nd = 64)将导致内存减少 64 倍、通信量略有增加约 50%。
3.1.2 ZeRO-DP 的通信量
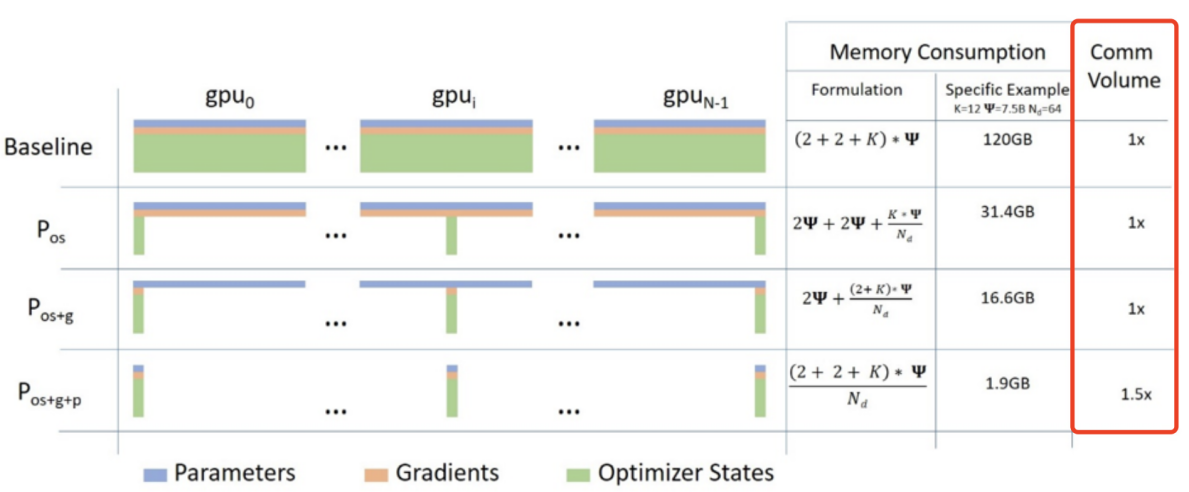
由上图可知,ZeRO-DP 在使用 Pos 和 Pg 时不会增加额外的通信,同时可以实现高达 8 倍的内存减少。使用 PP,除了 Pos 和 Pg 之外,ZeRO-DP 最多会引入 1.5 倍的通信开销,同时进一步降低内存占用 Nd 倍。
3.2 ZeRO-R
3.2.1 ZeRO-R 的思路
将 Activations Checkpoints 分片到各个 GPU 上,并使用 All-Gather 操作按需重构它们,消除了模型并行中的内存冗余。对于非常大的模型,甚至可以选择将激活分区移动到 CPU 内存。
使用固定大小的缓冲区来避免随着模型大小的增加而导致临时缓冲区过大,以平衡内存和计算效率。将 Activations Checkpoints 和梯度移动到预分配的连续内存缓冲区中,在运行时进行内存碎片整理。
3.2.2 ZeRO-R 的通信量
分片 Activations Checkpoints(记为 Pa)的通信量权衡取决于模型大小、Checkpoints 策略和模型并行策略。对于模型并行来说,Pa 的总通信开销不到原始通信量的 10%。
当模型并行与数据并行结合使用时,Pa 可以用来将数据并行的通信量降低一个数量级,代价是模型并行的通信量增加了 10%,并在数据并行通信成为性能瓶颈时显著提高效率。
4 Accelerate
Accelerate[4]由 Huggingface 于 2023 年发布,是一个适用于 Pytorch 用户的简单封装的库,其简化了分布式训练和混合精度训练的过程。Accelerate 基于 torch_xla 和 torch.distributed,只需要添加几行代码,使得相同的 PyTorch 代码可以在任何分布式配置下运行!简而言之,它使得大规模训练和推理变得简单、高效和适应性强。Accelerate 可与 DeepSpeed、Megatron-LM 和 FSDP(PyTorch Fully Sharded Data Parallel)等扩展一起使用。
5 小结
Accelerate 更加稳定和易于使用,适合中小规模的训练任务。DeepSpeed 和 Megatron 支持更大规模的模型。通过 accelerate 库,可轻松在单个设备或多个设备上结合 Megatron、DeepSpeed 进行分布式训练。当然,Megatron、Deepspeed 也可以结合使用,比如 Megatron-DeepSpeed,这是 NVIDIA 的 Megatron-LM 的 DeepSpeed 版本。
6 在 UCloud 云平台选择 A800 进行 Baichuan2 大模型的微调实验
首先参照 UCloud 文档中心(https://docs.ucloud.cn),登录 UCloud 控制台(https://console.ucloud.cn/uhost/uhost/create)。
在 UCloud 云平台上创建云主机,选择显卡为 A800,配置如下:

实验项目代码获取:https://github.com/hiyouga/LLaMA-Efficient-Tuning。
模型下载方式:Git Clone https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat。
数据集来源于:
本实验的微调任务是从一段文字中提取出概括性的标题。选 8 万条数据去训练,1000 条数据作为测试集,数据样例为:
根据以下配置去执行训练(此处并未做参数调优):
再进行测试,测试结果为:
上述结果中,BLEU-4 是一种用于评估机器翻译结果的指标。ROUGE-1、ROUGE-2 和 ROUGE-L 是 ROUGE 系统中的三个常用变体,一组用于评估文本摘要和生成任务的自动评估指标。
predict_runtime 是模型进行预测所花费的总运行时间,单位为秒。predict_samples_per_second 是模型每秒钟处理的样本数量。predict_steps_per_second 是模型每秒钟执行的步骤数量。
相关资料
[1]《Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism》
[3]《ZeRO: Memory Optimizations Toward Training Trillion Parameter Models》
[4] accelerate Hugging Face: https://huggingface.co/docs/accelerate/index




