
1. 篇首
最近看到 GC 这个异常古老的话题又被抛了出来,OpenJDK11 中出现了大道至简、返璞归真的 Epsilon GC 垃圾回收器,ZGC,Shenandoah GC 作为在 G1 的基础之上的两个分别合入了 OpenJDK11 和 OpenJDK12 的项目,两个项目的代号分别为分别为 JEP333、JEP189,这两款目前正在发展中的垃圾回收器成为了与 CMS、G1 两款早期并发回收器进行性能对比的主角。然后我就突然找到了一个主题,那就是比较两款垃圾回收器的性能就是在比较什么?要比较的究竟是哪些性能?是否有一款垃圾回收器能够在性能维度的方方面面碾压另一款垃圾回收器?这个问题我心里有自己的一些看法。我也一直在思考,在 JVM 这方面,周志明老师的大作《深入理解 Java 虚拟机》第三版于 2019 年中完成,其中对 ZGC,ShenandoahGC 两个面向低延时的垃圾回收器已经做了详细的原理解析,是否还需要再写文章做一些说明呢。但是转念又想,对于 JVM 垃圾回收器这部分虽然有如此多的珠玉在前,但是如果我自己的观点哪怕只有一点点是有价值的,那么不分享出来让大家看到也是一种知识价值的浪费。所以几番犹豫后,还是决定把自己对于 JVM GC 的理解写下来分享给大家。
那么我们说的 JVM 垃圾回收器不可能的三角是个什么规模的事情呢?先看一张图,我们都知道,我们可以把 JDK、JRE、JVM 的关系这样来表示:

而我们本文需要讨论的内容仅仅是 Java HotSpot Client and Server VM 中的一部分:垃圾回收器
描述一个垃圾回收器最重要的指标是哪些呢?
按照周志明老师在《深入理解 Java 虚拟机》2019 年第三版中的描述:分别是——
a. Heap 区间的内存占用(堆外辅助内存空间大小)
b. 无 GC 情况下的吞吐量(读写屏障的影响)
c. 延迟停顿( STW 时长),这三个指标形成了一个类似于事务的 CAP 理论的不可能三角。
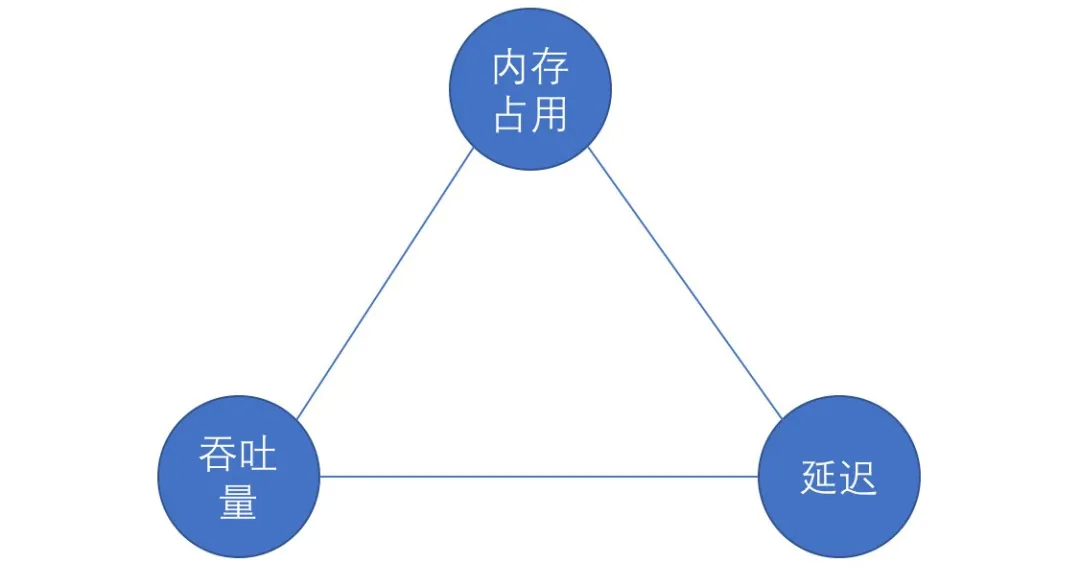
我们在形容垃圾回收器的时候所采用的所有维度说明,都是为了解决这三件事之间的矛盾,无外乎是选择谁、牺牲谁或者给谁多点、给谁少点的问题。
再看一张图,我们在讨论垃圾回收器的时候通常会讨论如下问题:
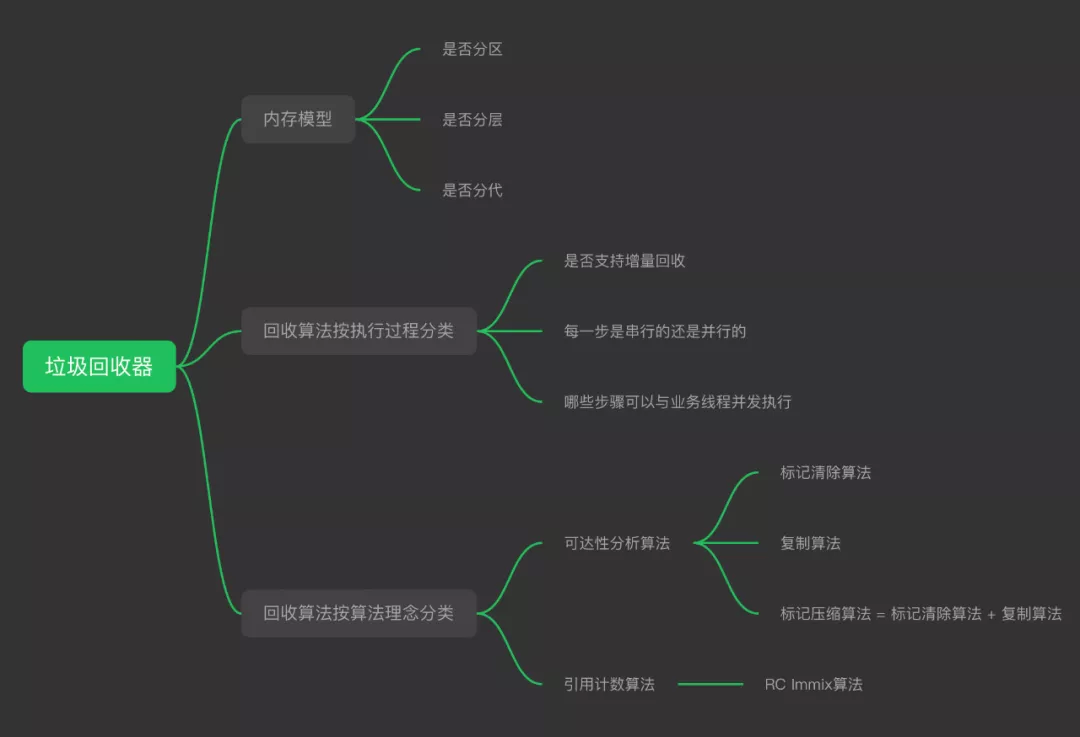
下面我们对这三组分类:内存模型分类、回收算法按执行过程分类和回收算法按算法理念分类,逐一做一个简单说明,本文限于篇幅,核心关注点是按照内存模型进行分类。
根据 java 虚拟机规范,java 虚拟机管理的内存将分为下面五大区域。
严格来说,下面的图不能够叫内存模型,应该叫内存的划分:
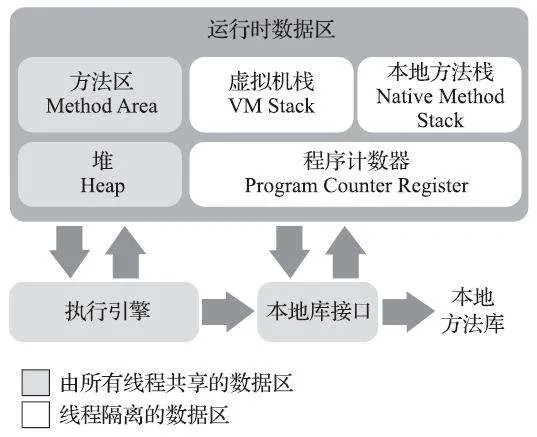
JVM 垃圾回收器主要管理的是这五大内存区域中的堆区间,我们所说的内存模型主要说的就是 JVM 堆区的内存模型。
对于 JVM 来说,通过我的总结,堆内存空间的类型大致分为四类:
A.分代模型 B.分代分区模型 C.分区模型 D.分层分区模型
援引我司冯志明老师对于内存模型的一段解释性说明,这段说明娓娓道来、简单明确,不援引出来分享给大家十分可惜:
内存模型(也叫内存一致性模型)这个概念是来自硬件的。是为了解决 CPU 缓存和内存一致性问题所构造出来的一个概念。
因为有读写两个操作,所以一致性场景有 4 个:LoadLoad,LoadStore,StoreLoad,StoreStore 。
每款 CPU 都有自己的内存模型。有的是强一致性模型,比如 x86,就只有 StoreLoad 场景下,会有一致性问题。有的是弱一致性模型,比如 ARMv7,就是 4 个场景都有一致性的问题。
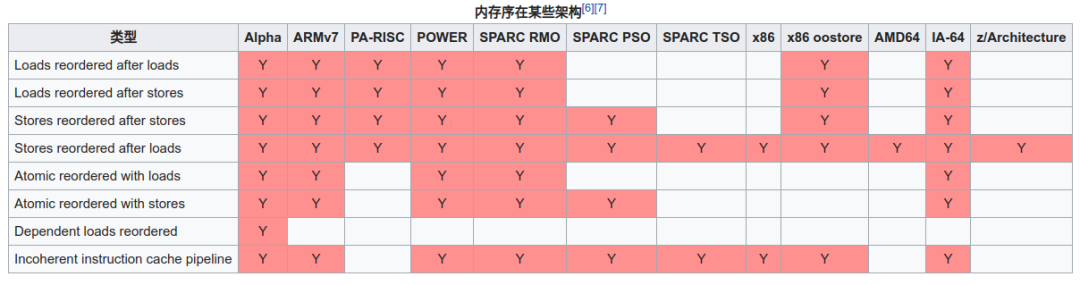
一致性模型越弱,CPU 结构会越简单,性能也会越高。但是对于软件开发者的要求也越高。
Linux 提供了 3 种汇编原语,来应对不同的一致性场景,那就是:写屏障,读屏障和全屏障。就是为了针对不同 CPU 下,不同内存模型下,做好数据同步操作。
JVM 是软件,也是虚拟机(虚拟的 CPU),所以 JVM 也一定也会有自己的内存模型(JMM)。
这个内存模型还要涵盖所有 CPU 下的内存模型,所以 JMM 就更通用也更晦涩。
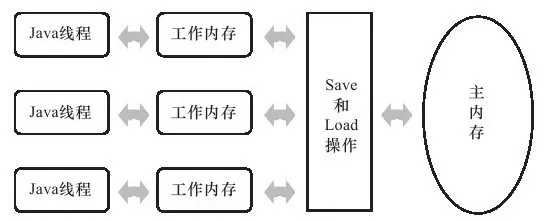
所以以前的 JMM 定义了 8 大操作(已经过时的概念)read,load,store,write 等等很晦涩的内容。
工作内存很容易被误解成内存中的一个部分,其实它指的是 CPU 缓存。
JMM 模型虽然分了 4 个场景,但是观察 x86 下的 JVM 源码,就会发现,只有 StoreLoad()里面有真正的屏障代码。其他三个屏障函数,都是空的。
总结来看,就是 JMM 是通用的内存模型,JVM 根据不同的 CPU,再遵从 CPU 的内存模型而执行代码。
2. 分代模型
Serial 收集器、ParNew 收集器、Parallel Scavenge 收集器、Serial Old 收集器、Parallel Old 收集器、CMS 收集器。堆内存分为新生代和老年代,新生代和老年代是物理隔离的。
分代模型细致介绍:我们现在常说的分代回收模型——如下图所示,也叫做 David Ungar 堆内存模型:
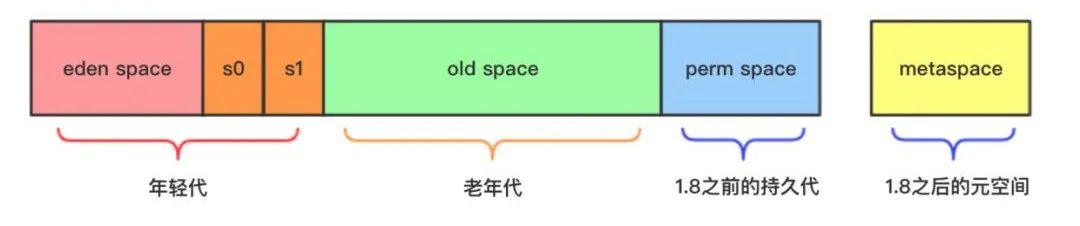
该内存模型的设计者及垃圾回收算法的发明人是一位叫做 David Ungar 的美国工程师,关于分代回收最早的描述出现在 David Ungar 1984 年的论文《Generation Scavenging: A Non-Disruptive High Performance Storage Reclamation Algorithm》中。
为什么会有分代回收产生?主要原因是基于内存中的大量对象会在较短的时间内达到不可达。很多对象用过几次之后就没用了虽然是经验之谈,但是适用于大多数的情况。在周志明老师的书中有三个构成分代收集基础的假说,分别是:
1)弱分代假说:绝大多数对象都是朝生夕灭的。
2)强分代假说:熬过越多次垃圾收集过程的对象就越难以消亡。
3)跨代引用假说:跨代引用相对于同代引用来说仅占极少数。
以这三个假说为前提,新生代 GC 只把新生成的对象当做对象,这样一来,通过减小对象范围,能够减少相同 Heap 区间内垃圾回收的时间消耗。老年代 GC 是针对较难变为垃圾的老年代对象执行的。执行老年代 GC 要比执行新生代 GC STW 间隔要更长但是不会长于不分代的情况下如果执行 fullgc 的长度。
假设在不分代的情况下与分代回收算法老年代通常采用的垃圾回收器,如标记清除算法相同,我们可以认为这种算法与不分代的标记清除算法相比 GC 吞吐效率提升 4 倍,最大 STW 间隔时间不变。
值得注意的是,这种 GC 吞吐效率提升是概率性的,如果恰好这个服务生成的对象都会生存很久,那么我们的 GC 吞吐效率反倒会降低,因为分代回收会在做 FGC 的基础之上,多做多次 YGC,即便不考虑 YGC 的因素,也会因为分代产生的写屏障而降低吞吐效率。
另外要提一下的是,针对假设 3:凡 JVM 分代回收器都存在类 Remembered Set 组件,在 JVM 中这个类 Remembered Set 组件叫做卡表(Card Marking),这个组件的作用就是记录老年代对象对新生代对象的引用,防止在进行 YGC 的时候去遍历老年代对象,以确认老年代对象是否有对新生代对象的引用。我们可以看到,如果假设 3 不成立,那么大家可以脑补一下场景,YGC 不仅仅要遍历新生代对象而且要遍历 Remembered Set 中规模与老年代体量相当的对象,GC 的吞吐效率是一定很低的,并且 JVM 浪费大量的内存空间来做 Remembered Set,JVM 整体的内存有效利用率是不高的。
Card Marking 方法是 Paul Wilson 和 Thomas Moher 1989 年发表在 ACM SIGPLAN Notices 中的,在这个方法中,首先把老年代空间按照相等的大小分割开来,分割出来的一个个空间就称为卡片,当老年代某区间有对象引用了新生代的对象时,与此老年代相对应的卡片就会写入指向新生代对象的指针,这样在垃圾回收时,新生代的对象被卡表中的卡片引用时,则不会被回收。
说到了 Remembered Set 和 Card Marking 就不得不说另一个概念叫做写屏障(write barrier),写屏障做的事情就是描述识别这个引用的变化需不需要加到 Remembered Set 中的一些逻辑,用白话讲就是写入之前或之后执行的一条特定操作。分代回收器或含分代理念的垃圾回收器都有写屏障的概念,JVM 中,写屏蔽的实现方式为脏卡模式(Dirty Card)。
3. 分代、分区模型
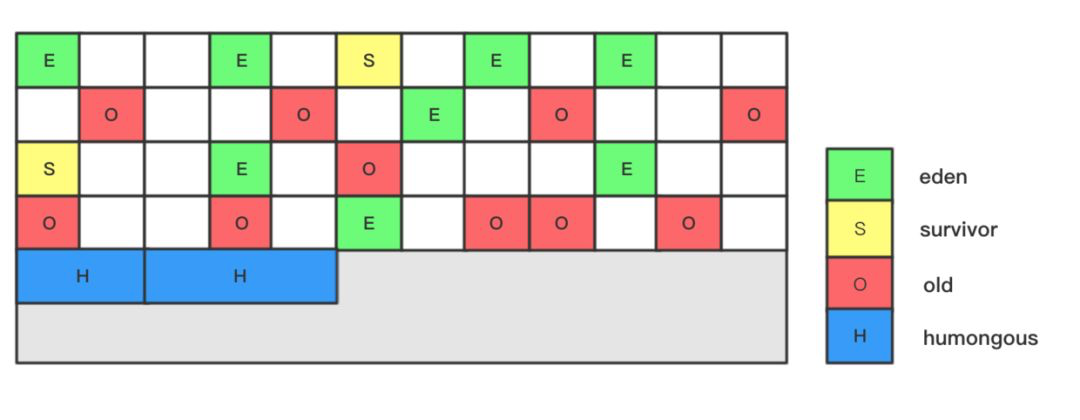
分代、分区模型的代表是 Garbage First(G1) 垃圾回收器,G1 打破了以往将收集范围固定在新生代或老年代的模式,G1 将 Java 堆空间分割成了若干相同大小的区域,即 region,包括 Eden、Survivor、Old、 Humongous 四种类型。其中,Humongous 是特殊的 Old 类型,专门放置大型对象。这样的划分方式意味着不需要一个连续的内存空间管理对象。G1 将空间分为多个区域,优先回收垃圾最多的区域。G1 采用的是好的空间整合能力不会产生大量的空间碎片。Region 的数值是在 1M 到 32M 字节之间的一个 2 的幂值数,JVM 会尽量划分 2048 个左右、同等大小的 Region。G1 的一大优势在于可预测的停顿时间,在可预测的时限内能够尽可能快的完成垃圾回收任务。在 JDK11 中,已经将 G1 设为默认垃圾回收器。
G1 作为一款初始理念产生于 2004 年,最终于 2012 年 4 月 JDK7 update4 发布的垃圾回收器,我们可以认为 G1 是一款介乎于分代模型与分区模型之间的一款垃圾回收器,起到了垃圾收集器历史上承上启下的重要作用。
G1 垃圾回收器之所以采用了分代、分区的做法来源于 G1 垃圾回收器的理念,追求吞吐率与最大 STW 时间的平衡,既不像纯粹的分代垃圾回收器一样追求垃圾回收的极致效率,也不似更后面的垃圾回收器,追求极致的最大 STW 时间,如 Shenanoah 和 ZGC 均追求低于 10ms 的最大 STW 时间。
相对而言,G1 垃圾回收器对内存空间的利用率这方面做了比较大的妥协,G1 垃圾回收器的 RememberedSet 相对来说是非常复杂的,其大小约为堆空间的 20%。
G1 垃圾回收器除了有所有分代垃圾回收器都有的因 Remembered Set 机制产生的并发写屏蔽,还有并发标记过程中基于 SATB(Snapshot at the Beginning)的写屏蔽,G1 垃圾回收器仍然会遇到 FGC 的情况,FGC 仍然会使用并行标记清除算法,STW 最大间隔并不会比更早起的分代回收器更为优秀。
4. 分区模型
分区模型的代表是 Shenandoah。
Shenandoah 垃圾回收器在周志明老师 2019 年的新作《深入理解 Java 虚拟机》第三版中被加入到了低延迟垃圾回收器中,与之相对应的我们所熟知的分代回收垃圾收集器以及 G1 垃圾收集器都被归为经典垃圾收集器。Shenandoah 的起源要追溯到 2014 年之前,最早由 Red Hat 公司发起,目标是利用现代多核 CPU 的优势,减少大堆内存在垃圾回收时产生的停顿时间。Shenandoah 与 G1 有很多相似之处,比如都是基于 Region 的内存布局,都有用于存放大对象的 Humongous Region,默认回收策略也是优先处理回收价值最大的 Region。Shenandoah 使用连接矩阵 (Connection Matrix) 记录跨 Region 的引用关系,替换掉了 G1 中的记忆级 (Remembered Set),内存和计算成本更低。并且,相比于 G1,Shenandoah 的内存模型是不分代的。
Shenandoah 收集器内存模型示意图如下:
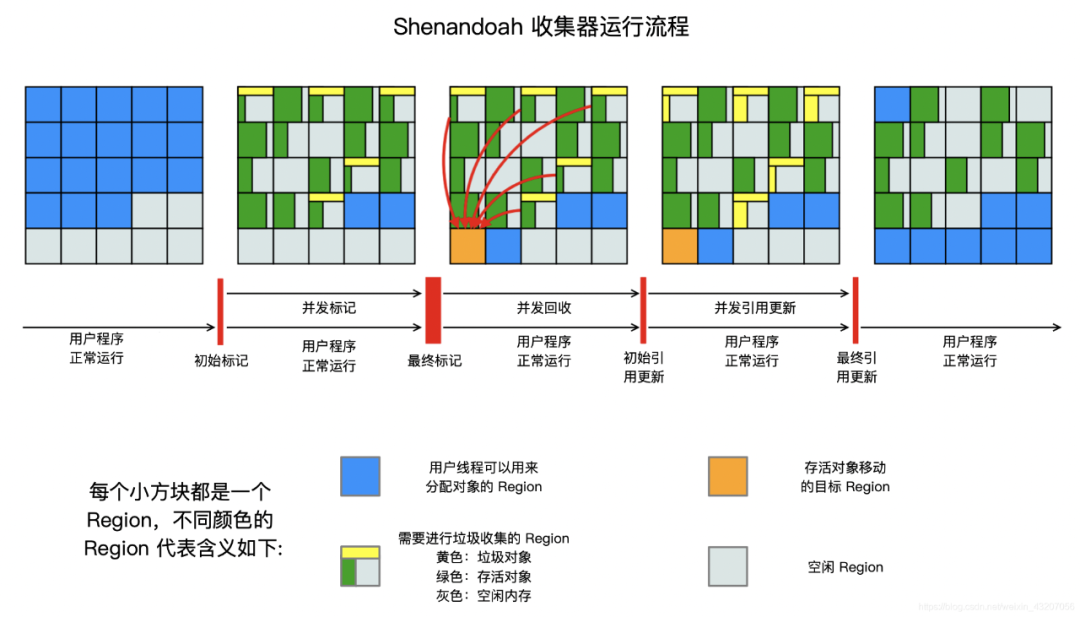
Shenanoah 垃圾回收器也有类似于卡表和 Remembered Set 的组件来占用内存空间。在 Shenanoah 垃圾回收器中,这个组件叫做“连接矩阵”(Connection Matrix),看起来很像是二维的卡表,用来记录跨区域的引用关系,和 Remembered Set 相比,对象跨区域引用指针维护相对简单。
如下图所示:
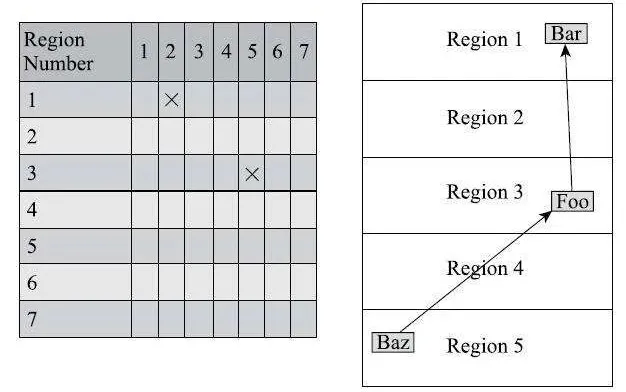
连接矩阵可以简单理解为一张二维表格,如果区域 N 有对象指向区域 M,就会在表格的 N 行 M 列中打上一个标记,如果区域 5 中的对象 Baz 引用了区域 3 中的对象 Foo,区域 3 中的对象 Foo 又引用了区域 1 中的对象 Bar。那么连接矩阵中的第 5 行第 3 列,连接矩阵中的第 3 行第 1 列就应该被打上标记。在进行垃圾回收时通过这个连接矩阵就可以得出哪些区域之间产生了跨代引用。
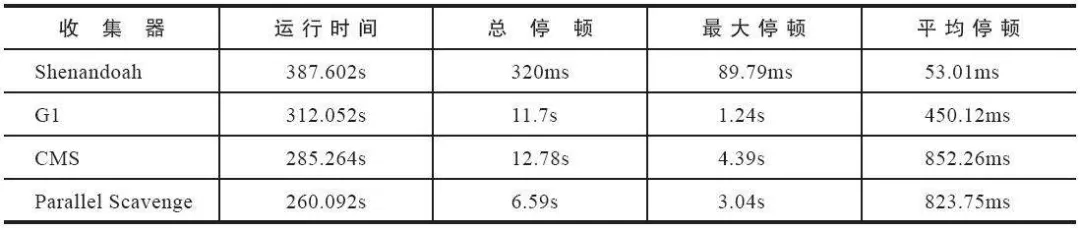
在周志明老师的《深入理解 Java 虚拟机》第三版中有一个几款垃圾回收器的性能测试:
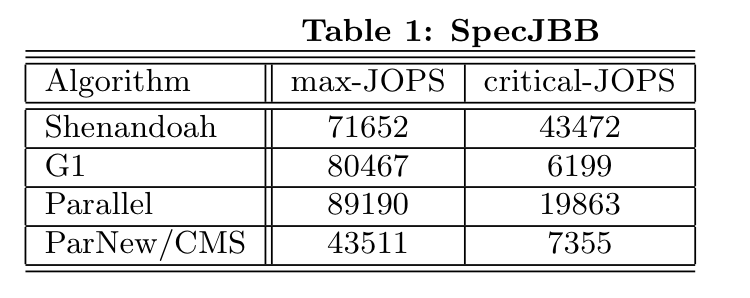
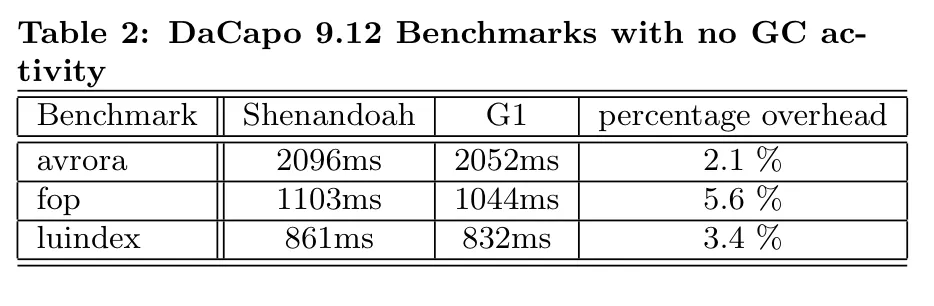
在周志明老师的《深入理解 Java 虚拟机》第三版中的图示之外,再补充两个 2016 年论文《Shenandoah: An open-source concurrent compacting garbage collector for OpenJDK》中的实验表格:
5. 分层分区模型
分层分区模型的代表是 ZGC。
ZGC 和 Shenanoah 的目标是高度相似的,都希望在尽可能对单位时间内 GC 吞吐量影响不太大的前提下,实现在任意堆内存大小下都可以把垃圾收集的停顿时间限制在 10ms 以内的低延迟。
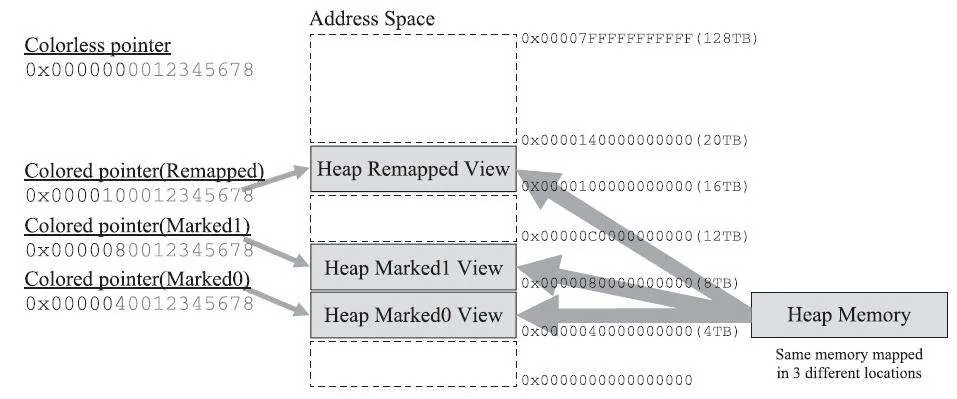
ZGC 是一款基于可变 Region 内存布局,使用了读屏障、染色指针和内存多重映射等技术实现了可并发的标记-压缩算法的垃圾收集器。
ZGC 与 Shenandoah 相比是一款理念更为先进的垃圾收集器,更先进主要体现在虚拟内存空间与实际内存空间的多对一映射与隔离,染色工作体现在指针上,而不是指针指向的对象上。也就是说从 ZGC 开始,我们不再需要通过垃圾回收器入侵到 Heap 区间的对象中去污染 Heap 中的对象来满足垃圾回收的需要,而是通过染色指针及虚拟空间映射,在虚拟空间完成了对对象的分类。从 ZGC 开始,垃圾回收不再需要 Heap 中的对象内存空间对垃圾回收提供帮助。用三体的话来说,就是 ZGC 从一个将 Heap 区间看作二维空间的模型变成了一个三维空间的模型,是一种理念上的跨越式发展,也是 GC 可以向着内存模型稳定化,同时 GC 接口标准化前进的一个重要平台。
值得一提的是,ZGC 的理念与 2011 年的论文《C4: The Continuously Concurrent Compacting Collector 》高度一致,C4 是运行在 Azul 公司收费 JVM ZingVM 中的低延时垃圾回收器。值得一提的是,论文中 C4 对自己是这么描述的*“C4 is a generational, continuously concurrent compacting collec- tor algorithm, it expands on the Pauseless GC algorithm [7] by in- cluding a generational form of a self healing Loaded Value Bar- rier (LVB), supporting simultaneous concurrent generational col- lection, as well as an enhanced heap management scheme that re- duces worst case space waste across the board*”,可以预期,在未来 ZGC 也会支持类似分代回收的算法,不确定是否这个分代也是类似于染色指针继续在虚拟内存层实现。
ZGC 与 Shenanoah 最大的不同点是实现了染色指针+多重映射。ZGC 直接通过染色指针来把标记信息记在引用对象的指针上,ZGC 通过“遍历引用图来标记引用”。
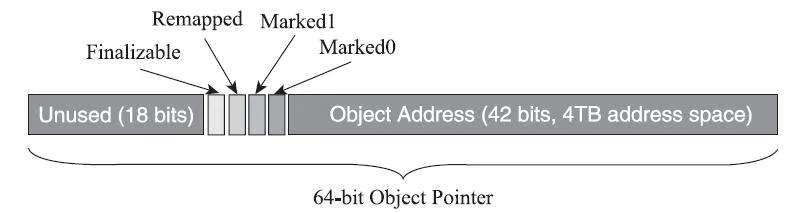
在 JEP333 文档中,作者用大量的篇幅来描述染色指针:
A core design principle/choice in ZGC is the use of load barriers in combination with colored object pointers (i.e., colored oops). This is what enables ZGC to do concurrent operations, such as object relocation, while Java application threads are running.
From a Java thread's perspective, the act of loading a reference field in a Java object is subject to a load barrier.
In addition to an object address, a colored object pointer contains information used by the load barrier to determine if some action needs to be taken before allowing a Java thread to use the pointer.
For example, the object might have been relocated, in which case the load barrier will detect the situation and take appropriate action.
Compared to alternative techniques, we believe the colored-pointers scheme offers some very attractive properties. In particular:
It allows us to reclaim and reuse memory during the relocation/compaction phase, before pointers pointing into the reclaimed/reused regions have been fixed. This helps keep the general heap overhead down.
It also means that there is no need to implement a separate mark-compact algorithm to handle a full GC.
It allows us to have relatively few and simple GC barriers. This helps keep the runtime overhead down. It also means that it's easier to implement, optimize and maintain the GC barrier code in our interpreter and JIT compilers.
We currently store marking and relocation related information in the colored pointers. However, the versatile nature of this scheme allows us to store any type of information (as long as we can fit it into the pointer) and let the load barrier take any action it wants to based on that information.
We believe this will lay the foundation for many future features. To pick one example, in a heterogeneous memory environment, this could be used to track heap access patterns to guide GC relocation decisions to move rarely used objects to cold storage.
多重映射是 ZGC 实现染色指针的载体:
下面的数据是截取了 JEP333 中提供的 Performance 比较:
ZGC 并没有如 Shenanoah 一般给出 Benchmark with no GC activity 的数据,不过可以推测,ZGC 只有读屏障而没有写屏障,数据应该会好于 Shenanoah,考虑到 Shenanoah 的数据与 G1 不相上下,可以得出 ZGC 优于或至少等于 G1 的结论。
Performance
Regular performance measurements have been done using SPECjbb® 2015 [1]. Performance is looking good, both from a throughput and latency point of view. Below are typical benchmark scores (in percent, normalized against ZGC's max-jOPS), comparing ZGC and G1, in composite mode using a 128G heap.
(Higher is better)

Below are typical GC pause times from the same benchmark. ZGC manages to stay well below the 10ms goal. Note that exact numbers can vary (both up and down, but not significantly) depending on the exact machine and setup used.
(Lower is better)
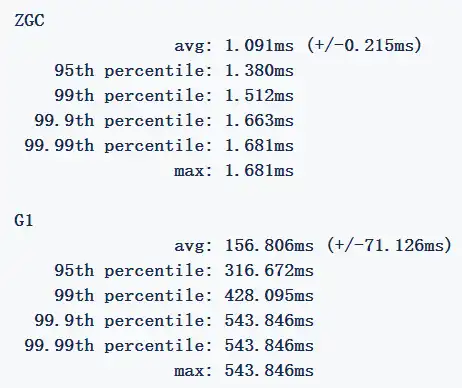
Ad-hoc performance measurements have also been done on various other SPEC®benchmarks and internal workloads.In general, ZGC manages to maintain single-digit millisecond pause times.
[1] SPECjbb® 2015 is a registered trademark of the Standard Performance Evaluation Corporation (spec.org). The actual results are not represented as compliant because the SUT may not meet SPEC's requirements for general availability.
6. 本文总结
首先通过一张表对本文所写的内容做一个小结:
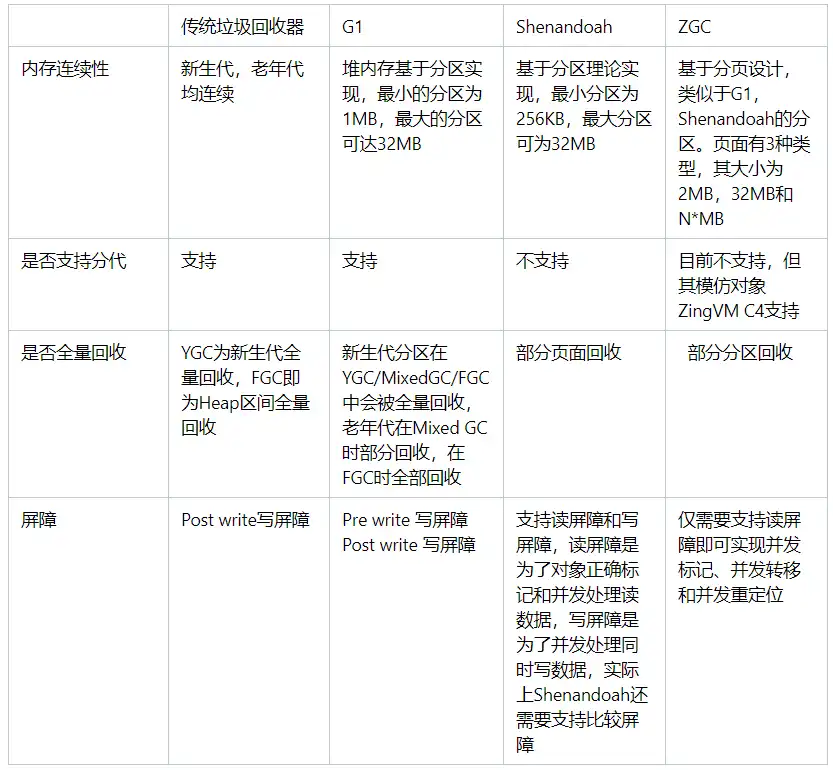
如同本文开始说的,GC 可以从多个不同的角度去理解和分类,而任何一本描述 GC 的书,都要有其思路轨迹和分类脉络。没有任何一种分类可以说是完全科学的,本文先按照 Heap 内存模型这个角度对 GC 垃圾回收器做一个分类,本文对每个垃圾回收器的描述并不全面,只是从 Heap 区内存模型这一个角度来描述,原因也是后面的文字会从其他的角度来继续描述目前 Hotspot JVM 支持的各垃圾回收器。期待最终我把各段文字拼凑在一起,包括我在内的读者可以大致看到各垃圾回收器的全貌。
本文还强调的一点是,无论从 GC 垃圾回收器的任何一个角度来看垃圾回收器的特点,目的都是做到:
a. Heap 区间的内存占用(堆外辅助内存空间大小)
b. 无 GC 情况下的吞吐量(读写屏障的影响)
c. 延迟停顿(STW 时长) 这三件事情的再平衡
在硬件条件既定的情况下,不存在既要 Heap 区利用充分,也要程序吞吐量大,还要延迟停顿低这三件事情同时发生的情况,只是在对的硬件环境下,用对的 GC 垃圾回收器,达到更好的平衡,这点也是我自己不仅使用垃圾回收器,而且尽量挤时间去了解一些垃圾回收器原理的目的。
参考书目:
《C4: The Continuously Concurrent Compacting Collector 》Gil Tene ,Balaji Iyengar, Michael Wolf
《Shenandoah An open-source concurrent compacting garbage collector for OpenJDK 》Christine H. Flood ,Roman Kennke ,Andrew Dinn ,Andrew Haley, Roland Westrelin
《Generation Scavenging: A Non-Disruptive High Performance Storage Reclamation Algorithm》David Ungar
《Virtual Machines》 James Smith, Ravi Nair
《JEP 333: ZGC: A Scalable Low-Latency Garbage Collector》Per Liden, Stefan Karlsson
《JEP 189: Shenandoah: A Low-Pause-Time Garbage Collector》Christine H. Flood, Roman Kennke
《深入理解 Java 虚拟机》周志明
《垃圾回收的算法与实现》中村成洋
《ZGC 设计与实现》彭成寒
作者介绍:
王植萌
去哪儿网工程师
2013 年 5 月加入去哪儿网,目前专注于 API 标准化建设、DDD 驱动业务重塑、技术成熟度评估、团队数字化管理等方面的工作。
本文转载自公众号 Qunar 技术沙龙(ID:QunarTL)。
原文链接:




