
1 月 25 日,LeptonAI 发布了一个基于自家服务的小 demo,用 500 行 Python 代码实现了一个大模型加持的对话式搜索引擎。随后,号称要干掉谷歌搜索的 Perplexity 创始人声称 LeptonAI 在“借鉴”、“致敬”他们的产品。作为 LeptonAI 的创始人,贾扬清在 Twitter 上进行了公开回击。此前,LeptonAI 正打算开源该演示工具的全部代码。
事情经过
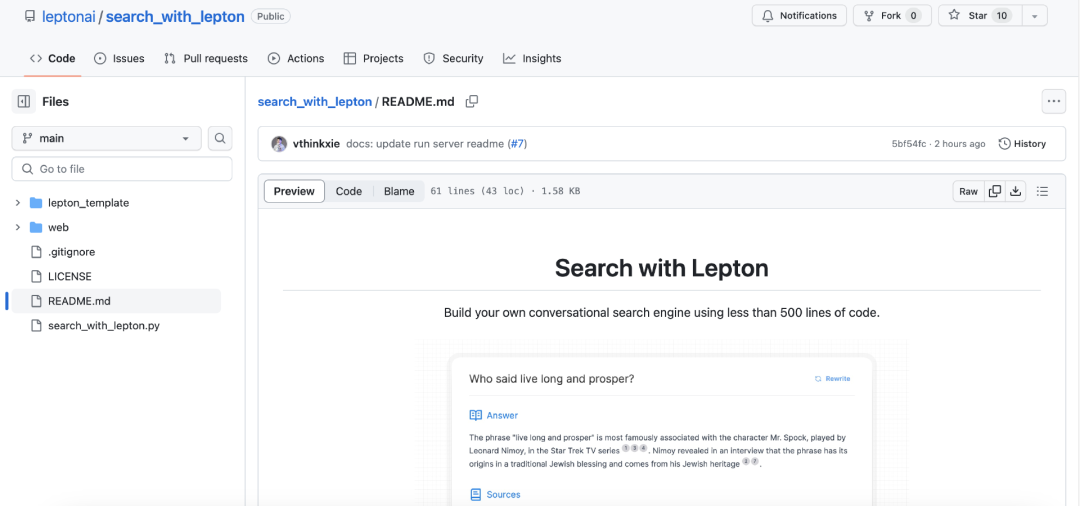
LeptonAI 于近日发布了一个对话式搜索引擎 demo,名为“Lepton Search”。该 demo 界面主要是一个对话框,在对话框中输入想问的问题后,Lepton Search 会根据提问,返回答案、对应来源(Sources)、相关问题(Related)。
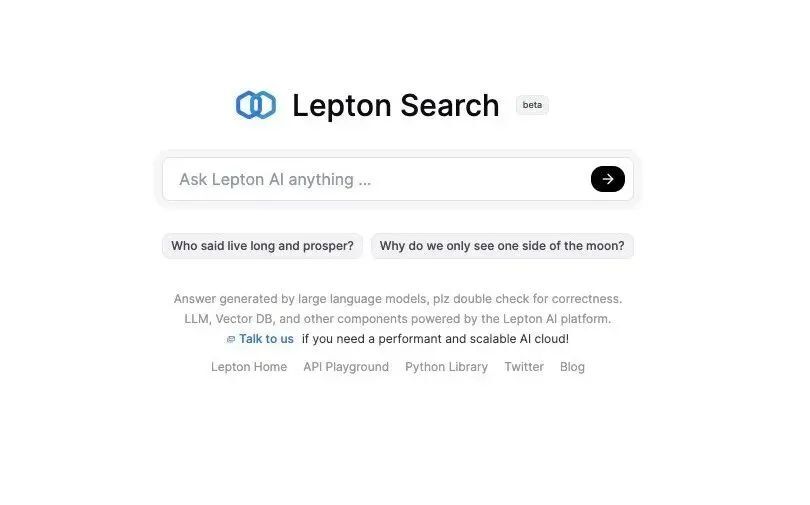
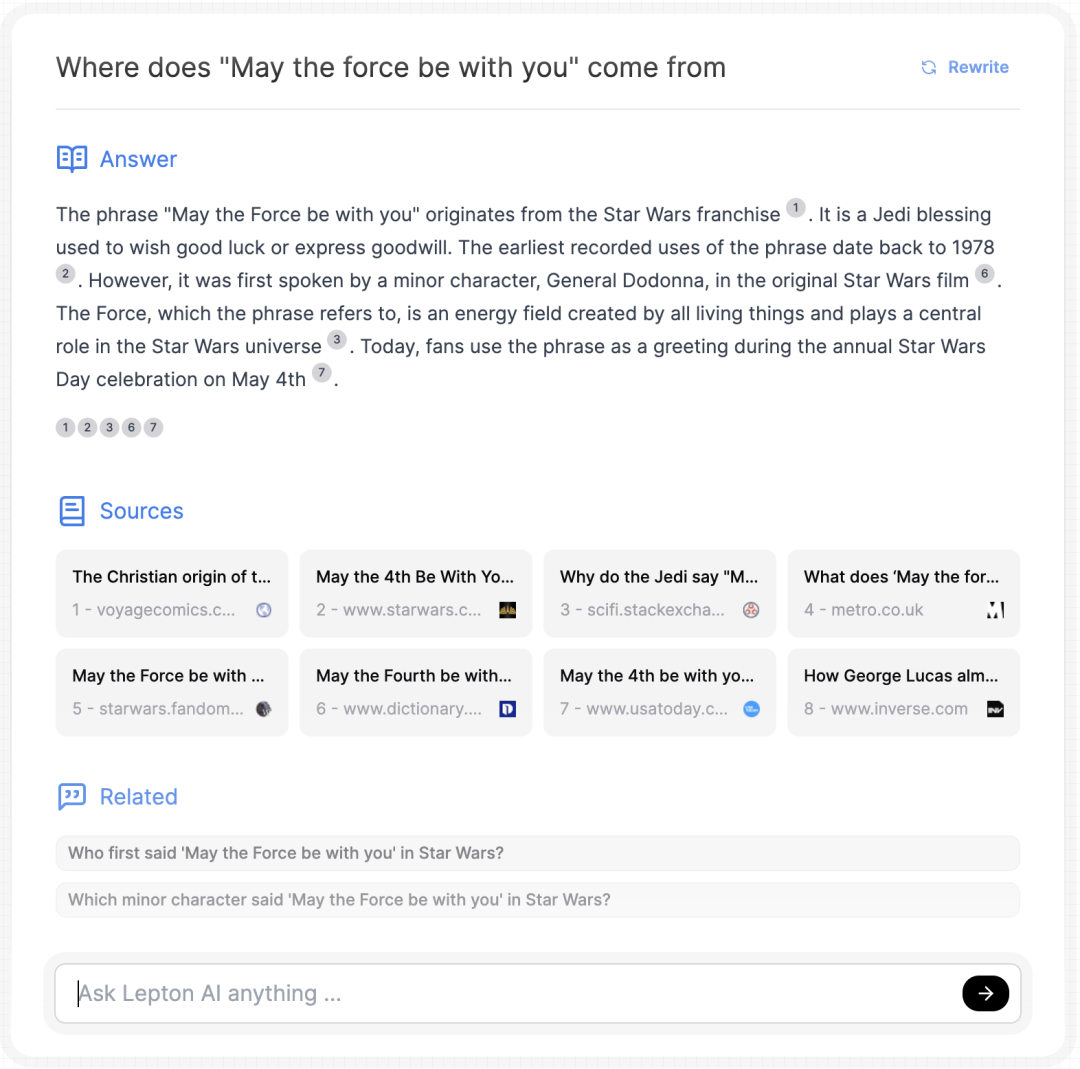
截图来源:https://search.lepton.run/
LeptonAI 以此为例,向大家解释现在构建一个人工智能应用已经相当简单:这个演示程序,他们只用了不到 500 行 Python 代码,后端是一个非常快的 Mixtral-8x7b 模型,运行在 LeptonAI 自家的 playground 托管平台上,正常情况下吞吐量可高达约 200 个令牌 / 秒。该搜索引擎目前建立在 Bing 搜索 API 上,用 Lepton KV 作为无服务器存储。

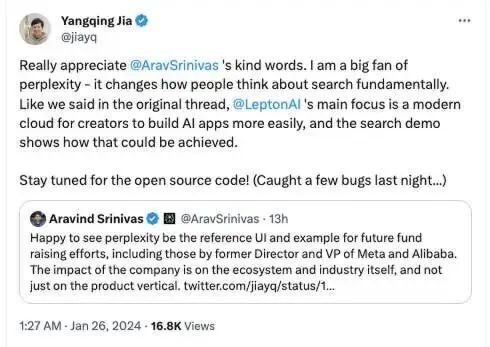
原本是基于 LeptonAI 云平台的一个简单 demo,没想到贾扬清在 Twitter 上发布演示视频后,Perplexity 的创始人突然出现,并发文感谢 LeptonAI 向他们“致敬”:“太棒了,看到 Perplexity 成为未来融资活动的标杆,前 Meta 和阿里巴巴高管都来取经!这说明 Perplexity 的影响力不局限于产品本身,而是辐射到了整个科技生态和行业发展,令人振奋!”
Perplexity AI 成立于 2022 年 8 月,总部设在旧金山。Aravind Srinivas 是 Perplexity AI 的创始人兼首席执行官,2017 年从印度理工学院毕业,考入加州大学伯克利分校攻读博士学位,后来又在 OpenAI 担任过一年的研究科学家。创始团队还包括 Denis Yarats 和 Johnny Ho,均具有人工智能相关背景。

截图源自 The Wall Street Journal
2022 年 9 月,Perplexity 获得 310 万美元的种子轮投资。2023 年 3 月,Perplexity 获 2560 万美元 A 轮融资。今年 1 月,再获英伟达领投的超 7000 万美元融资。
自 2023 年 12 月在亚马逊云科技 re: Invent 主题上亮相后,Perplexity 就受到了广泛关注,并得到了包括前 GitHub 首席执行官 Nat Friedman 等在内的一众大佬热捧。
Srinivas 的目标是挑战谷歌,他表示他自己是拉里·佩奇和谷歌的忠实粉丝:“我一直有做一些与谷歌同样规模和雄心的事情的冲动。”“目前看来,世界似乎对谷歌仍感到满意,他们的流量并没有实质性的变化。不过,就像谷歌和 Facebook 改变了人们获取新闻的方式一样,远离传统搜索引擎的转变最终会发生。”
Perplexity 的一众粉丝则表示 LeptonAI “借鉴”了他们的界面。
而其他粉丝则一脸懵“这是有专利吗?人家只是演示而已。”
对 Perplexity 的挑衅,贾扬清大佬罕见地进行了正面回击,“对话搜索”的领导者地位并不是来源于 Perplexity:“灵感在有一次贾扬清和微软最年轻的技术专家吴忧喝咖啡的时候,讨论 RAG 的效果究竟是源自搜索还是源自大模型,为了分析这个问题,所以自己手搭了一个 demo,同时展示 Lepton 对于 AI 创作者的效率提升。值得一提的是,吴忧是微软的搜索、对话式搜索等技术背后的核心技术领导者。”
并表示在发布这个 demo 之初已经声明要开源该演示工具的全部代码。当天下午,LeptonAI 如约将其开源,采用 Apache-2.0 许可证。
开源地址如下:https://github.com/leptonai/search_with_lepton
会话式搜索引擎原理是什么样的?
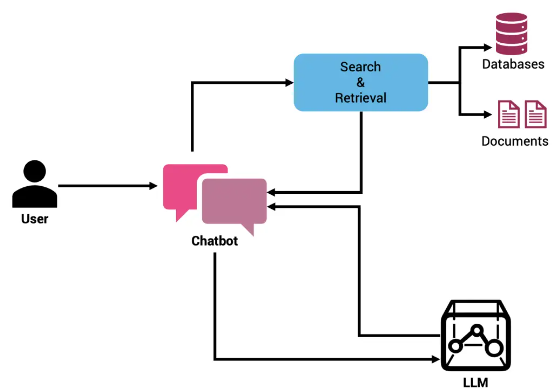
作为一款想取代谷歌的搜索引擎,从表面看来,Perplexity 的工作原理是:当用户输入一个查询时,它会理解并重新构建这个查询,从实时索引中提取出相关链接。然后,Perplexity 将回答用户查询的任务交给 LLM,要求它阅读所有链接,并从每个链接中提取出相关段落整合内容,最终形成一段精准答案。
目前,大语言模型(LLM)主要面临两大挑战:数据陈旧、偶发幻觉。由于基础模型所使用的预训练数据集具有明确的截止日期,因此无法根据最新数据做出响应。即使是当前最强大的模型,也往往会因数据过时而编造答案,也就是人们常说的“幻觉”问题。
对于无法访问最新数据,可以有两种方法,第一种是通过搜索引擎,通过执行网络搜索并向大模型提交输来改善决策质量。Perplexity AI 更依赖于这种方法。

第二种方法是,通过所谓检索增强生成(RAG),这项成熟技术可以解决一定程度的“幻觉”问题。与前面提到的动态调用搜索 API 方法不同,RAG 强调从公开数据存储中检索数据,例如向量数据库或者由外部维护的全文搜索索引等。
通过对 Perplexity Copilot 底层技术的深入研究,还有专家称其灵感来自论文《FreshLLMs:使用搜索引擎增强更新大语言模型》(FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation)提出的搜索引擎增强大模型。
FreshLLM 提出了按搜索内容的发布日期顺序注入热门搜索摘要的想法。除了添加上下文之外,文章还建议配合少量提示词,引导大模型根据具体示例做出回应。论文作者还尝试了一种名为 FRESHPROMPT 的技术解决大模型无法回复实时问题的局限性,这项技术将来自搜索引擎的最新上下文信息注入经过预训练的大模型当中。
面对给定问题,这种方法会先在搜索引擎上查询该问题,检索全部搜索结果,包括答案框、相关结果及其他有用信息(包括知识图谱、公共问答平台上的信息,以及其他用户搜索过的相关问题等)。之后,再利用这些信息指导大模型对检索到的证据进行推理,基于多条提示词改善模型输出准确响应的能力。
Perplexity AI 底层以两套在线大语言模型为基础,同时借助内部数据承包商构建起高质量、多样化的大型训练数据集,打造了这么一套大模型搜索产品。这两套模型分别为 pplx-8b-online 和 pplx-70b-online,可以通过 API 公开访问,允许开发者将该技术整合进自己的应用程序与网站当中。
在 RAG based search 中,召回 + 排序出相关内容,然后再由模型来推理生成。在大模型同质化的年代,对于对话式搜索引擎来说,召回 + 排序才是核心竞争力。
而 LeptonAI,正如贾扬清所说,他们焦点在于一个帮助开发者构建人工智能应用程序的现代云平台,而不是做一个搜索引擎。那么基于此目的来通过调用已有基础架构方式构建出来的搜索引擎,其实也相对简单,所以能用不到 500 行代码来实现。





