
本文最初发布于 incident.io。
我是单体架构的忠实粉丝。即使不是每个函数调用都需要一个网络请求,编写代码也已经够困难的了,而且这还没有考虑可观察性、RPC 框架以及让你可以在微服务环境中保持较高生产力的开发环境等方面的投资。
我就管理着一个 Ruby 单体应用程序,在 5 年的时间里,工程师从 20 名发展到 200 名,它的 Postgres 数据库从 10GB 增长到 5TB。无疑,当到达某个点时,痛苦会超过好处。
本文旨在探讨一项技术——拆分工作负载——它能够显著减轻痛苦,而且成本低,可以很快应用。如果做得好,你就可以更长久地享受单体的美好。
让我们开始吧!
大停机!
早在 2022 年 11 月就出现了一次停机,我们亲切地称之为“反复崩溃导致的间歇性停机”。
这可能是我们第一次真正遇到大故障,我们的应用程序在 32 分钟内反复崩溃,让人倍感压力,尤其是那些花了一整天时间构建事件工具的响应者。
我们事后进行了详细的分析,要点如下:
我们的应用程序在 Heroku 上以 Go 单体的形式运行,我们使用了 Heroku Postgres 数据库,以及 GCP Pub/Sub 异步消息队列。
我们的应用程序运行单个二进制文件的多个副本,包括 Web、worker 和 cron 线程。
当二进制文件获取到错误的 Pub/Sub 消息时,无法处理的 panic 将导致整个应用程序崩溃,这意味着 Web、worker 和 crons 线程都将死亡。
这很糟糕,而且似乎很容易避免。如果我们将所有的东西都构建为微服务,那就只有负责处理该消息的服务会崩溃,对吗?
什么是可靠性?真是那样吗?
团队选择微服务架构,最常见的原因往往是可靠性或可扩展性。通常,这两个词可以互换使用。
这意味着:
问题波及范围——比如,就像我们上面所说的,错误的 Pub/Sub 消息将被限制在它所在的服务中,而且通常允许服务优雅地降级(继续服务于大多数请求,只是某些功能失败)。
每个微服务都可以管理自己的资源,例如设置 CPU 或内存限制,而且在需要时,服务可以扩展所需的任何资源。这可以防止不良代码路径把有限的资源耗尽并影响其他代码,就像在单体应用程序中可能发生的那样。
当然,微服务解决了这些问题,但也带来了大量的包袱(分布式系统问题、RPC 框架等)。如果我们想获得微服务的好处而又不想背这些包袱,就需要一些替代解决方案。
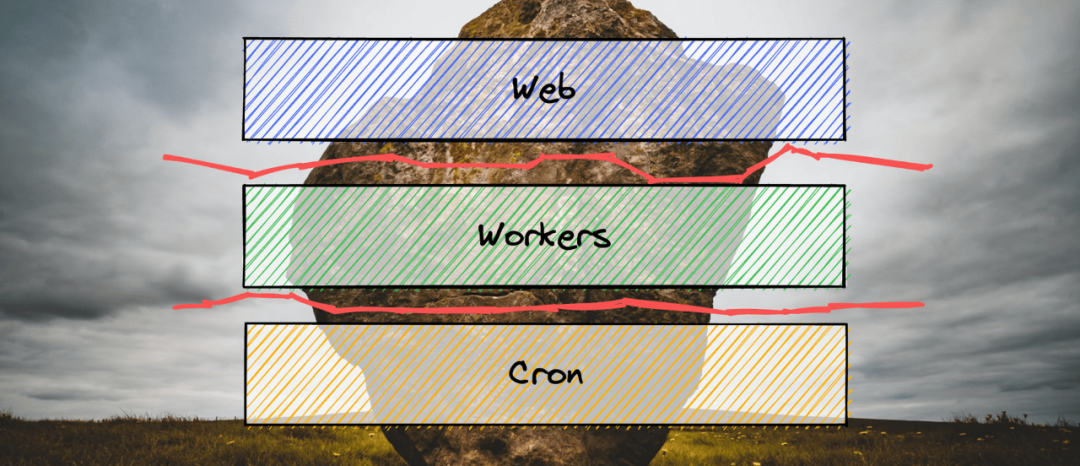
原则 1:永远不要混合工作负载
首先,我们应该遵循运行单体的基本原则,即永远不要混合工作负载。
对于 incident.io 应用,我们有三个关键的工作负载:
处理传入请求的 Web 服务器。
处理异步工作的 Pub/Sub 订阅者。
按时间表执行的 Cron 作业。
我们打破了这个原则,在同一个进程中运行了所有这些代码(实际上是在同一个 Linux 进程中)。混合工作负载让我们面临着以下问题:
代码库中特定部分的错误代码会导致整个应用崩溃,就像我们去年 11 月遇到的事件一样。
如果我们部署了一个会占用大量 CPU 的 Pub/Sub 订阅者(可能是压缩 Slack 图片,或者是一个写得很糟糕的循环),整个应用程序都会受到影响,导致所有的 Web/worker/cron 活动变慢直至停止。在这个进程中,CPU 是一种有限的资源,如果我们消耗了 90%,其他工作就只能利用剩下的 10% 了。
在事件发生的同一天,我们按照工作负载的类型将应用程序拆分为不同的部署层。也就是说,在 Heroku 中创建三个独立的 dyno 层。这样,应用程序的三个独立部署就只需要处理自己所负责类型的工作负载了。

你可能会问,既然我们都这样做了,为什么不彻底点,改成独立的微服务呢?
答案是,这种拆分既保留了单体的所有好处,同时又完全解决了我们上面提到的问题。每次部署都运行相同的代码,使用相同的 Docker 镜像和环境变量,唯一不同的是启动代码的命令。不需要复杂的开发设置,也不需要 RPC 框架,还是原来的那个单体,只是操作方式不同。
应用程序的入口点代码大概是下面这样:
package mainvar ( app = kingpin.New("app", "incident.io") web = app.Flag("web", "Run web server").Bool() workers = app.Flag("workers", "Run async workers").Bool() cron = app.Flag("cron", "Run cron jobs").Bool())func main() { if *web { // run web } if *workers { // run workers } if *cron { // run cron } wait()}你可以轻松地将上述代码添加到任何应用程序中。在本地开发环境中,你可以在单个热重载进程中运行所有组件(对于许多微服务来说,这是不可能的!)
请注意,盲目切换会有一个小问题,假设所有东西都在同一进程中运行,这样的代码既难以识别,又容易产生微妙的错误,而且难以修复。例如,如果你的 Web 服务器代码将数据存储在进程本地缓存中,而 worker 又试图访问该缓存,那么你就要经历一段悲伤的时光了。
好消息是,这些依赖关系通常会体现为代码气味,只要将协调过程放到外部存储(如 Postgres 或 Redis)中就可以很容易地解决了。而且,只要更改一次就不会再出问题。在我看来,即使不拆分代码,这样做也是值得的。
注意,拆分工作负载的粒度并没有什么限制。我以前见过每个队列甚至每个作业类一个部署的情况,也见过单个应用程序环境中多达 20 个部署的情况。
原则 2:应用护栏
好了,我们的单体不再是一个运行所有东西的大代码包:它是三个独立、相互隔离、可以单独成功或失败的部署。太好了。
但是,大多数应用程序不只是进程中运行的代码。最主要的可靠性风险之一是恶意代码,甚至是行为良好但消耗了单体应用最宝贵的有限资源的定时代码。
比如数据库,我们用的是 Postgres。
即使你拆分了工作负载,底层数据存储也还是需要某种形式的保护。而这正是微服务(通常不共享任何东西)可以提供帮助的地方,每个服务部署都只能通过另一个服务 API 间接地消耗数据库时间。
不过,这个问题在我们的单体中也是可以解决的,我们只需要围绕资源消耗创建护栏和限制,而限制的粒度可以是任意的。
在我们的代码中,围绕 Postgres 数据库的护栏是这样的:
package mainvar ( // ... workers = app.Flag("workers", "Run async workers").Bool() workersDatabase = new(database.ConnectOptions).Bind( app, "workers.database.", 20, 5, "30s"))func main() { // ... if *workers { db, err := createDatabasePool(ctx, "worker", workersDatabase) if err != nil { return errors.Wrap(err, "connecting to Postgres pool for workers") } runWorkers(db) // 开始运行workers }}上述代码设置数据库池并允许针对 worker 进行专门的定制。在默认情况下,“最大活动连接数为 20,最大空闲连接数为 5,语句超时时间为 30 秒”。
从 app --help 的输出也许更容易看出来:
--workers.database.max-open-connections=20 Max database connections to open against the Postgres server--workers.database.max-idle-connections=5 Max database connections to keep open while idle--workers.database.max-connection-idle-time=10m Max time to wait before closing idle Postgres server connections--workers.database.max-connection-lifetime=60m Max time to reuse a connection before recycling it--workers.database.statement-timeout="30s" What to set as a statement timeout大多数应用程序都会指定连接池的值,但关键是,我们有单独的池来处理我们想要限制的任何类型的工作,预计它可能(在事件情况下)消耗过多的数据库能力并影响服务的其他组件。
以下是两个例子:
eventsDatabase 是一个包含 2 个连接的池,供一个 worker 使用,而该 worker 会消耗每个 Pub/Sub 事件的副本,并将其推送给 BigQuery 以供稍后分析。我们不关心这个队列是否落后,但如果它给数据库造成了压力,那将非常糟糕,尤其是在我们的服务非常繁忙的时候(这是很自然的)。
triggersDatabase 包含 5 个连接,由一个 cron 作业使用,而该 cron 作业会扫描所有事件以获取最近的活动,帮助生成类似“已经有一段时间了,您是否想发送另一个事件更新?”这样的提示。这些查询非常昂贵,并且只要尽力而为即可,所以我们宁愿落后,也不愿为了跟上速度而伤害数据库。
使用这样的限制可以帮助你保护共享资源(如数据库能力),防止单体的任何一部分过度消耗。如果这些限制非常容易配置——就像我们通过共享的 database.ConnectOptions 辅助器一样——那么只需要很小的工作量就可以预先指定“我希望这个资源最多只能消耗 X,超过这个数要通知我”。
对于任何中等规模的单体,这一方案都很有用。但当代码库的不同部分由多个团队开发时,需要优先保证每个人免受其他人的影响。
你的单体该怎么处理?
保持单体就好!
不用说,你在扩展单体时会遇到问题,但症结在于:微服务并不都是好处,分布式系统的问题真的可能很糟糕。
所以我们要避免把婴儿连同洗澡水一起倒掉。当你遇到单体扩展问题时,问下自己“真正的问题是什么?”在大多数情况下,你可以在代码中添加护栏或限制,通过模仿微服务来获得一些好处,同时保留单代码库并避免 RPC 的复杂性。
原文链接:
https://incident.io/blog/monolith
声明:本文为 InfoQ 翻译,未经许可禁止转载。
延伸阅读:
从微服务转为单体架构、成本降低 90%,亚马逊内部案例引发轰动!
今日好文推荐
因低薪、高强度工作感到被公司“虐待”,一程序员跳槽前炮制惊天数据窃取案,勒索上千万终获刑
阿里取消 CTO 岗位;星火大模型“套壳”OpenAI?科大讯飞回应;近一半微软员工担心被 AI 抢饭碗|Q资讯




