
当逐渐后移的发际线和日益稀疏的刘海成为焦虑的源头,为了满足这届用户对于浓密秀发的向往,多年深耕人工智能领域的美图公司技术大脑——美图影像实验室(MT Lab)基于在深度学习领域积累的技术优势,落地了多个头发生成项目并实现了高清真实的头发纹理生成,目前已率先在美图旗下核心产品美图秀秀及海外产品 AirBrush 上线刘海生成、发际线调整与稀疏区域补发等功能,满足用户对发型的多样化需求。其中,刘海生成功能可以基于自定义的生成区域,生成不同样式的刘海(如图 1.1-1.3);发际线调整功能在保持原有发际线样式的情况下,可以对发际线的不同高度进行调整(如图 2.1-2.2);稀疏区域补发则可以在指定区域或者智能检测区域中,自定义调整稀疏区域的头发浓密程度。

图 1.1 刘海生成(左:原图,右:全刘海生成效果图)

图 1.2 刘海生成(左:原图,右:全刘海生成效果图)

图 1.3 多款刘海生成效果图

图 2.1 发际线调整前后对比图

图 2.2 发际线调整对比图
美图头发生成任务全流程
头发生成任务面临的挑战
头发编辑作为一般的生成任务,在落地实践过程中仍面临几个亟待突破的关键技术瓶颈:
首先是生成数据的获取问题。以刘海生成任务为例,在生成出特定款式的刘海时,一个人有无刘海的数据是最为理想的配对数据,但这种类型的真实数据获取的可能性极低。与此同时,如果采用针对性收集特定款式刘海数据,以形成特定属性非配对数据集的方式,那么获取高质量且多样式的数据就需要耗费较高的成本,基本不具备可操作性。
其次是高清图像细节的生成问题。由于头发部位拥有复杂的纹理细节,通过 CNN 难以生成真实且达到理想状态的发丝。其中,在有配对数据的情况下,虽然可以通过设计类似 Pixel2PixelHD$^[1]$、U2-Net$^[2]$等网络进行监督学习,但目前通过该方式生成的图像清晰度仍然非常有限;而在非配对数据情况下,一般通过类似 HiSD$^[3]$、StarGAN$^[4]$、CycleGAN$^[5]$的方式进行属性转换生成,利用该方式生成的图片不仅清晰度不佳,还存在目标效果生成不稳定、生成效果不真实等问题。
针对上述情况, MT Lab 基于庞大的数据资源与突出的模型设计能力,借助 StyleGAN$^[6]$解决了头发生成任务所面临的配对数据生成与高清图像细节两大核心问题。StyleGAN 作为当前生成领域的主要方向——Gan(生成式对抗网络)在图像生成应用中的主要代表,是一种基于风格输入的无监督高清图像生成模型。能够基于 7 万张 1024*1024 的高清人脸图像训练数据 FFHQ,通过精巧的网络设计与训练技巧生成清晰逼真的图像效果。此外,StyleGAN 还能基于风格输入的方式拥有属性编辑的能力,通过隐变量的编辑,实现图像语意内容的修改。

图 3 基于 StyleGAN 生成的图片
基于 StyleGAN 的头发编辑方案
1.配对数据生成
StyleGAN 生成配对数据最为直接的方式就是在 w+空间直接进行相关属性的隐向量编辑,生成相关属性,其中隐向量编辑方法包括 GanSpace$^[7]$、InterFaceGAN$^[8]$及 StyleSpace$^[9]$等等。但这种图像生成方式通常隐含着属性向量不解耦的情况,即在生成目标属性的同时往往伴随其他属性(背景和人脸信息等)产生变化。
因此,MT Lab 结合 StyleGAN Projector$^[6]$、PULSE$^[10]$及 Mask-Guided Discovery$^[11]$等迭代重建方式来解决生成头发配对数据的问题。该方案的主要思路是通过简略编辑原始图片,获得一张粗简的目标属性参考图像,将其与原始图像都作为参考图像,再通过 StyleGAN 进行迭代重建。
以为头发染浅色发色为例,需要先对原始图片中的头发区域染上统一的浅色色块,经由降采样获得粗略编辑简图作为目标属性参考图像,在 StyleGAN 的迭代重建过程中,生成图片在高分辨率尺度下与原始图片进行相似性监督,以保证头发区域以外的原始信息不发生改变。另一方面,生成图片通过降采样与目标属性参考图像进行监督,以保生成的浅色发色区域与原始图片的头发区域一致,二者迭代在监督平衡下生成期望中的图像,与此同时也获得了一个人有无浅色头发的配对数据(完整流程参考图 4)。值得强调的是,在该方案执行过程中既要保证生成图片的目标属性与参考图像一致,也要保证生成图像在目标属性区域外与原始图片信息保持一致;还需要保证生成图像的隐向量处于 StyleGAN 的隐向量分布中,才能够确保最终的生成图像是高清图像。
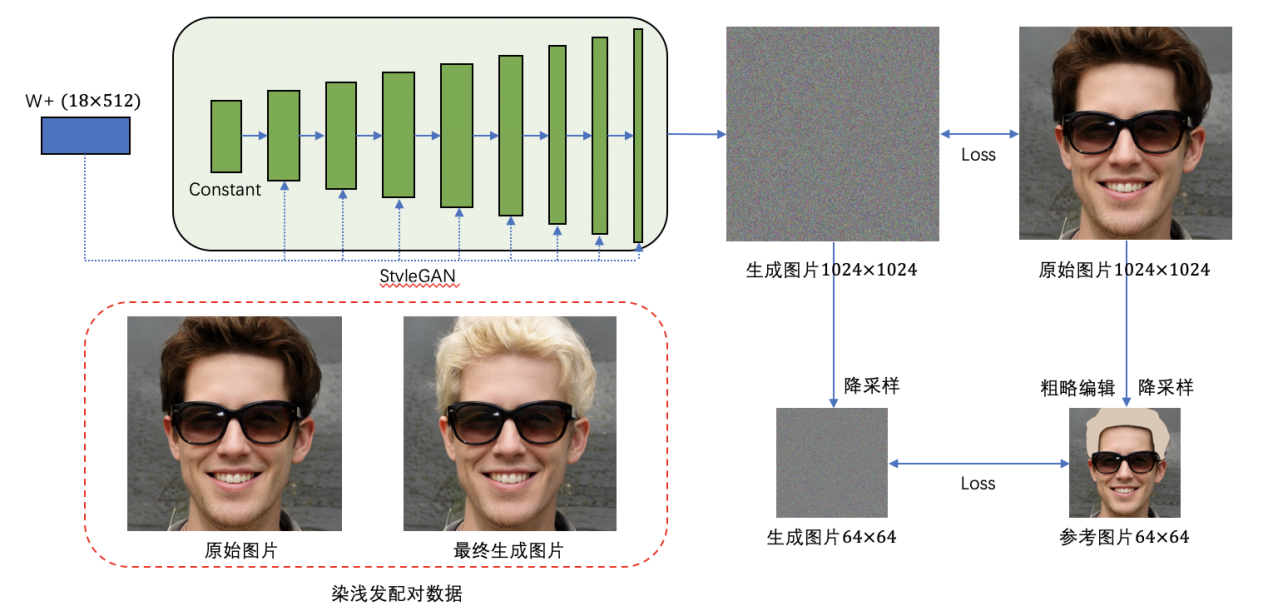
图 4 染浅色头发 StyleGAN 迭代重建示意图
此外,基于该方案的思路,在头发生成领域还可以获取到发际线调整的配对数据(如图 5)、刘海生成的配对数据(如图 6)以及头发蓬松的配对数据(如图 7)。

图 5 发际线配对数据

图 6 刘海配对数据

图 7 头发蓬松配对数据
2.配对数据增益
基于迭代重建,还能够获得配对数据所对应的 StyleGAN 隐向量,通过隐向量插值的方式还能实现数据增益,进而获得足够数量的配对数据。以发际线调整的配对数据为例,如图 8 所示,(a)和(g)是一组配对数据,(c)和(i)是一组配对数据,在每一组配对数据间,可以通过插值获得发际线不同程度调整的配对数据。如(d)和(f)分别是(a)和(g)、(c)和(i)之间的插值。同样的,两组配对数据间也可以通过隐向量插值获得更多配对数据。如(b)和(h)分别是(a)和(c)、(g)和(i)通过插值获得的配对数据。此外,通过插值获得的配对数据也能够生成新的配对数据,如(e)是(b)和(h)通过差值获得的配对数据,基于此可以满足对理想的发际线调整配对数据的需求。

图 8 配对数据增益
3.image-to-image 生成
基于 StyleGan 的迭代重建获得配对数据后,就可以通过 pixel2piexlHD 模型进行有监督的学习训练,这种 image-to-image 的方式相对稳定且具有鲁棒性,但生成图像的清晰度还无法达到理想的效果,因此选择通过在 image-to-image 模型上采用 StyleGAN 的预训练模型来帮助实现生成细节的提升。传统的 StyleGAN 实现 image-to-image 的方式是通过 encoder 网络获得输入图的图像隐向量,然后直接编辑隐向量,最后实现目标属性图像生成,但由这种方式生成的图像与原图像比对往往相似度较低,无法满足基于原图像进行编辑的要求。因此 MT Lab 对这种隐向量编辑的方式进行了改进,一方面直接将原图像 encode 到目标属性的隐向量,省去进行中间隐向量编辑的步骤,另一方面将 encoder 网络的特征与 StyleGAN 网络的特征进行融合,最终通过融合后的特征生成目标属性图像,以最大限度保证生成图像与原图像的相似度,整体网络结构与 GLEAN$^[12]$模型非常相似,该方式兼顾了图像高清细节生成与原图相似度还原两个主要问题,由此也完成了高清且具有真实细节纹理的头发生成全流程。(如图 9)
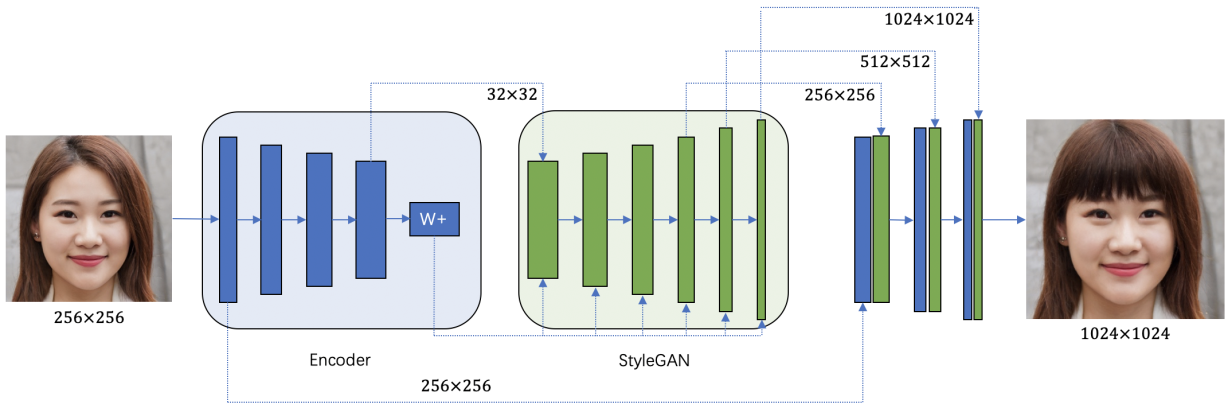
图 9 头发生成网络结构
基于 StyleGAN 编辑生成方案的拓展
基于 StyleGAN 编辑生成方案能够在降低生成任务方案设计难度的同时,提高生成任务的研发效率,实现生成效果的大幅度提升,与此同时也具有很高的扩展性。其中,结合 StyleGAN 生成理想头发配对数据的方式极大地降低了图像编辑任务的难度,如将该方案关注的属性拓展到头发以外,就能够获得更多属性的配对数据,例如五官更换的配对数据(如图 10),借此可以尝试对任何人脸属性编辑任务进行落地实践。此外,借助 StyleGAN 预训练模型实现 image-to-image 的方式能够保证生成图像的清晰度,因此还可以将其推广到如图像修复、图像去噪、图像超分辨率等等更为一般的生成任务中。

图 10 五官更换的配对数据:原图(左),参考图(中),结果图(右)
目前, MT Lab 已在图像生成领域取得新的技术突破,实现了高清人像生成并达到精细化控制生成。在落地头发生成以外还实现了牙齿整形、眼皮生成、妆容迁移等人脸属性编辑功能,还提供了 AI 换脸、变老、变小孩、更换性别、生成笑容等等风靡社交网络的新鲜玩法,一系列酷炫玩法为用户带来了更有趣、更优质的使用体验,也展现了其背后强大的技术支持与研发投入。未来,深度学习仍将是 MT Lab 重点关注的研究领域之一,也将持续深入对前沿技术的研究,不断深化行业技术创新与突破。
参考文献:
[1] Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao,Jan Kautz, and Bryan Catanzaro. High-resolution image syn-thesis and semantic manipulation with conditional gans. In CVPR, 2018.
[2] Xuebin Qin, Zichen Zhang, Chenyang Huang, Masood Dehghan, Osmar R Zaiane, and MartinJagersand. U2-net: Going deeper with nested u-structure for salient object detection. Pattern Recognition, 2020.
[3] Xinyang Li, Shengchuan Zhang, Jie Hu, Liujuan Cao, Xiaopeng Hong, Xudong Mao, Feiyue Huang, Yongjian Wu, Rongrong Ji. Image-to-image Translation via Hierarchical Style Disentanglement. InProc. In CVPR, 2021.
[4] Choi, Y., Choi, M., Kim, M., Ha, J.W., Kim, S., Choo, J.: Stargan: Unified genera-tive adversarial networks for multi-domain image-to-image translation. In CVPR, 2018.
[5] Choi, Y., Choi, M., Kim, M., Ha, J.W., Kim, S., Choo, J.: Stargan: Unified genera-tive adversarial networks for multi-domain image-to-image translation. In CVPR, 2018.
[6] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten,Jaakko Lehtinen, and Timo Aila. Analyzing and improvingthe image quality of StyleGAN. InProc. In CVPR, 2020.
[7] Erik H ?ark ?onen, Aaron Hertzmann, Jaakko Lehtinen, andSylvain Paris. Ganspace: Discovering interpretable gancontrols. In NIPS, 2020.
[8] Yujun Shen, Jinjin Gu, Xiaoou Tang, and Bolei Zhou. Inter-preting the latent space of gans for semantic face editing. In CVPR, 2020.
[9] Zongze Wu, Dani Lischinski, and Eli Shecht-man. StyleSpace analysis: Disentangled controlsfor StyleGAN image generation. In arXiv, 2020.
[10] Sachit Menon, Alexandru Damian, Shijia Hu, Nikhil Ravi,and Cynthia Rudin. Pulse: Self-supervised photo upsam-pling via latent space exploration of generative models. In CVPR, 2020.
[11] Mengyu Yang, David Rokeby, Xavier Snelgrove. Mask-Guided Discovery of Semantic Manifolds in Generative Models. In NIPS Workshop, 2020.
[12] K. C. Chan, X. Wang, X. Xu, J. Gu, and C. C. Loy, Glean: Generative latent bank for large-factor image super-resolution, In CVPR, 2021.




