
机器学习在现实世界的应用潜力是无限的,但其实有 87%的机器学习应用项目在概念验证阶段就宣告失败。作者基于在 1 万多个项目上 5 万多模型训练的经验,总结了机器学习应用项目失败的一些原因,并提出从以模型为中心的开发模式转变为以数据为中心的开发模式是促使更多项目成功的解决方案。
既然你正在阅读这篇文章,我应该就没必要讲什么机器学习研究中那些动听的故事了,也没必要啰嗦人工智能在现实世界场景中的应用潜力有多大。然而,其实机器学习应用项目中有 87%在概念验证阶段就已经宣告失败,而从未进入生产阶段[1]。
我们已经和hasty.ai的用户一起开发了超过 1 万个项目,并且为生产环境训练了超过 5 万个视觉模型,我会在这篇文章中深入探讨开发和训练过程中所学到的东西。至于为何这么多的机器学习应用项目会失败,我总结了一些原因并提出了一个解决方案。
太长不看版: 我们需要一个范式转变,从以模型为中心转变为以数据为中心的机器学习开发。
免责声明:在hasty.ai,我们正在为以数据为中心的视觉 AI 建立一个端到端平台。因此,我用到的所有例子都是关于视觉领域的。不过,相信我提出的概念对其他领域的人工智能也同样适用。
许多机器学习应用团队是在模仿研究思维
要理解为什么 87%的机器学习项目会失败,需要先退一步,了解下当前大多数团队是如何构建机器学习应用的。这其实很大程度上取决于机器学习研究的工作方式。
研究团队大多是在尝试推进特定任务的前沿发展水平(SOTA),而 SOTA 是通过在给定数据集上达到的最佳性能评分来衡量的。研究团队需要保持数据集不变,尝试去改进现有方法的一小部分,以实现 0.x%的性能提升,因为这样是可以发表论文的。
研究领域中的每一次热点炒作都是在这种追逐 SOTA 的心态下产生的,许多从事机器学习应用的团队都怀揣这种心态,认为这同样也能带领他们走向成功。所以,他们会在模型开发方面投入大量的资源,却把数据当作给定或可以外包的东西。
追求 SOTA 是机器学习应用失败的秘诀
无论如何,追求 SOTA 这种思路是有缺陷的。
首先,机器学习研究和机器学习应用的目标差别很大。作为一个研究人员,你要确保自己处于领先水平。相反,如果从事机器学习应用,首要目标应该是让它在生产中发挥作用--就算使用一个五年前的架构,那又如何?
第二,你在现实世界中遇到的条件与研究环境大相径庭,事情会复杂得多。

在研究中,团队在完美的条件下用干净和结构化的数据开展工作。然而现实中,数据可能大不相同,团队需要面临一系列全新的挑战。图片由作者提供,通过 imgflip.com 创建。
讲一个我最喜欢的都市传说,来自自动驾驶领域:
和大多数机器学习研究一样,原型是在湾区开发的,在美国中西部首次试驾之前团队已经花了数年时间调整模型。但最终在中西部试驾时,模型却崩溃了,因为所有训练数据都是在阳光明媚的加州收集的。这些模型无法处理中西部的恶劣天气,当道路上突然出现雪、相机上出现雨滴时,模型就会混乱。
题外话:我反复听到这个故事,但一直没找到出处。如果你知道并分享给我,我会非常感激。
这件趣事揭示了一个大问题:在研究环境中,可能会碰到相当舒适的条件,就像加州的好天气。然而在实践中,条件会很恶劣,事情变得更具挑战性,你无法只用理论上的可行性来应付一切。
如果想做机器学习应用,通常意味着要面临一系列全新的挑战。而不幸的是,其实没有办法通过简单地改进底层架构和重新定义 SOTA 来克服这些问题。
机器学习应用 ≠ 研究
更确切地讲,以下是机器学习应用环境与研究环境的 5 个不同之处:
1、数据质量变得很重要
在机器学习应用中有这么一句话:
“进垃圾,出垃圾。”
这意味着,你的模型只有在训练它们的数据上才好用。在 10 个最常用的跨领域基准数据集上,其训练和验证数据上本身就有 3.4%的误分类率[2],而这总被研究人员忽视。
许多研究人员认为,不需要太关注这个问题,因为最终仍可以通过比较模型架构获得有意义的见解。但是,如果想在模型上建立一些业务逻辑,那么确定你看到的是一只狮子还是一只猴子就相当关键了。
2、更多时候,你需要定制数据
研究中使用的大多数基准数据集都是巨大的通用数据集,因为其目标是尽可能多地泛化。而在机器学习应用中,你很可能会遇到专门的用例,这些用例是不会出现在公开的通用数据集中的。
因此,你需要收集和准备自己的数据──能恰当地代表你具体问题的数据。通常,选择正确的数据对模型性能的影响要大过选择哪种架构或如何设置超参数。
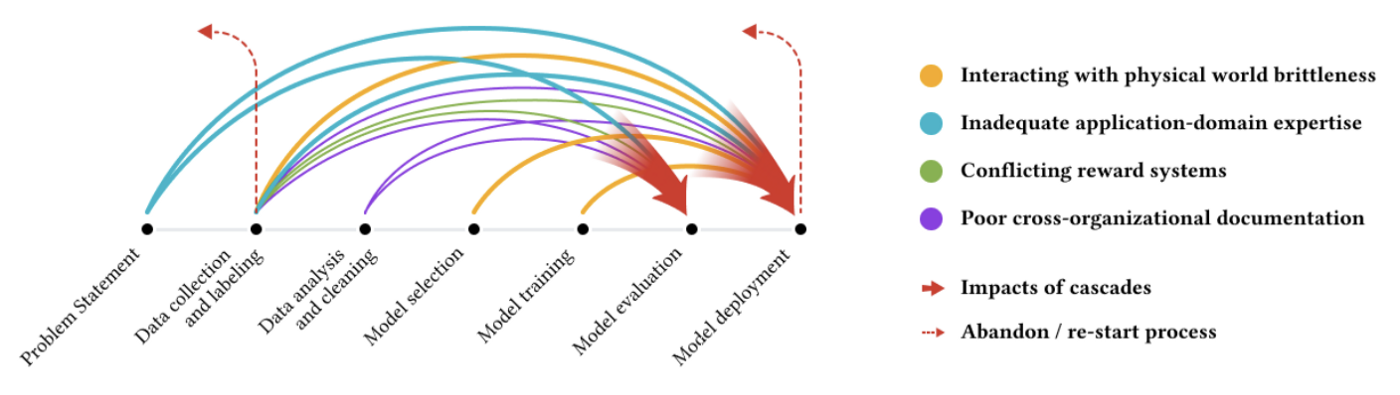
在机器学习开发过程中早期决策对最终结果有巨大影响。特别是一开始的数据收集和标签策略是至关重要的,因为每一步的问题都会逐级累积。图片取自[3]。
谷歌 AI lab 团队发表过一篇论文── “每个人都想做模型工作,而不是数据工作:高风险 AI 中的数据问题累积”[3],展示了如果在项目开始时选择错误的数据策略,将如何对模型的后期表现产生不利影响,我非常建议你去读一读。
3、有时候,你需要用小数据样本
在机器学习研究中,对于模型性能低下的一个常见答案是:"收集更多的数据"。通常情况下,如果你向会议期刊提交一篇训练了几百个样本的论文,大概率会被拒绝。即使达到了很高的性能,你的模型也会被认为是过拟合的。
不过在机器学习应用中,收集巨大的数据集往往是不可能的,要么代价太高,所以必须尽可能地利用你能得到的东西。
不管怎样,过拟合的说法在这里没那么要紧。如果对待解决的问题定义明确,并且运行在一个相对稳定的环境中,那么只要能产生正确的结果,训练一个过拟合的模型或许也是可行的。
4、别忘了数据漂移的问题
让机器学习应用变得更复杂的是你很可能会遇到某种数据漂移。当模型部署到生产环境后,现实世界的特征或目标变量的基本分布发生变化时,就会出现这种情况。
一个明显的例子是,在夏天收集了最初的训练数据并部署了模型,到了冬天世界完全变了样,模型就崩溃了。另一个更难预测的例子是,当用户在与模型互动后开始改变他们的行为。
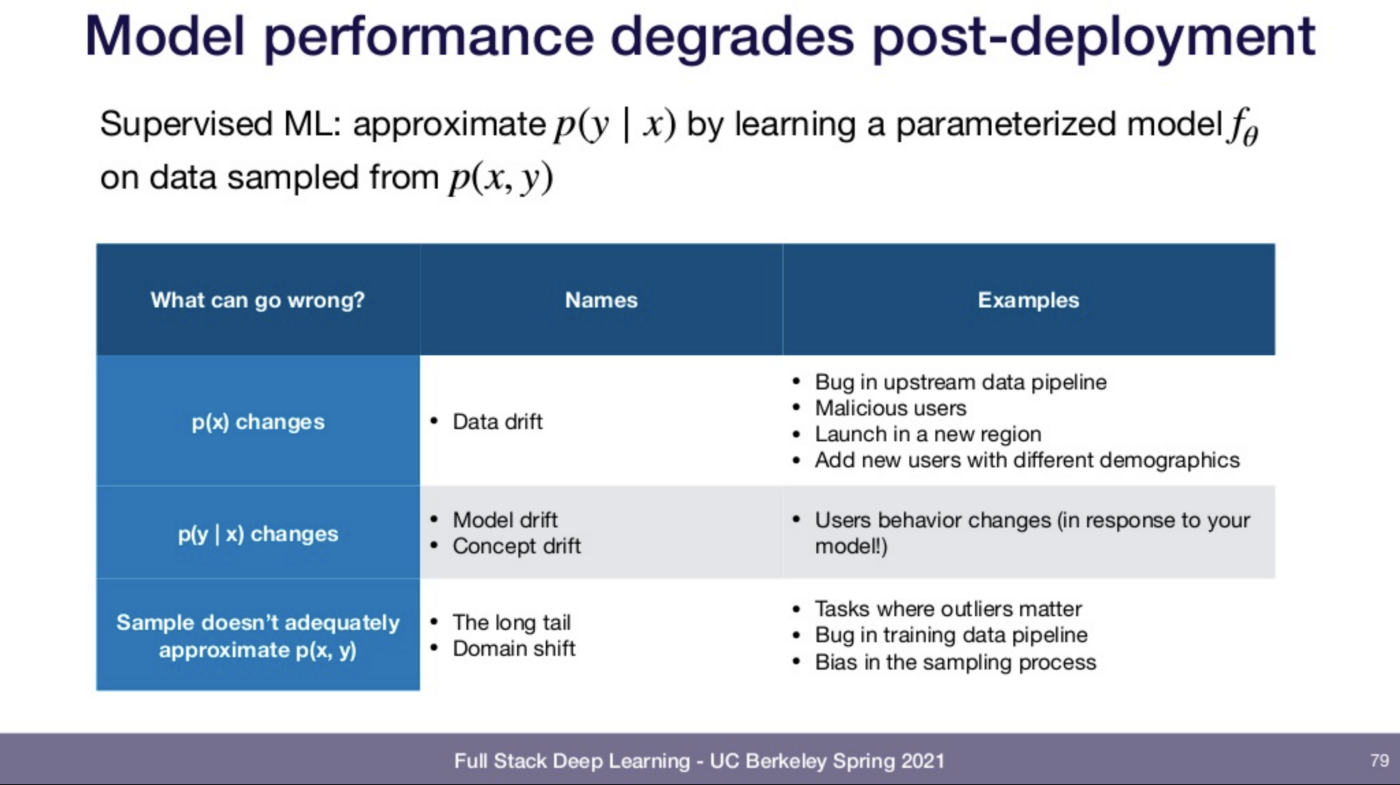
Josh Tobin 总结了数据漂移的最常见情况[4]
有一小部分研究会关注这个问题(见上图 Josh Tobin 的幻灯片),但大多数研究人员在追逐 SOTA 的工作中忽略了这一点。
5、你会在计算方面遇到限制
你有没有试过把一个深度模型部署到德州仪器的 ARM 设备上?我们做过。最终虽然成功了,但经历一个抓狂的过程。
实际上,有时候你不得不在边缘设备上进行推理,实时并行地为数百万用户提供服务,或者压根没有预算分给海量的 GPU 资源消耗。所有这些都对研究环境中的理论可行性增加了限制,而研究人员已经习惯了为一个项目在GPU上花费超过20000美元。
解决方案:从以模型为中心的机器学习到以数据为中心的机器学习
如上所述,机器学习应用中截然不同的环境带来了一系列全新的挑战。像往常研究那样,只关注模型的改进并不能应对这些挑战,因为模型和数据之间的关系比模型本身更重要!
然而,机器学习应用的大多数团队仍在采用研究思维,热衷追逐 STOA。他们把数据当作可以外包的商品,并把所有的资源投入到模型相关的工作上。根据我们的经验,这是许多机器学习应用项目失败的最重要原因。
不过,也有越来越多的从事机器学习应用的人认识到,只专注于模型会得到令人失望的结果。一个倡导机器学习应用新方法的运动正在兴起:他们正在推动从以模型为中心到以数据为中心的机器学习开发的转变。
Andrew Ng 有一场针对以数据为中心的机器学习的演讲,讲了一个更有说服力的案例。总结起来,他的主要的论点是:当你做机器学习应用时,没必要太担心 SOTA。即使是几年前的模型,对于大多数的用例来说也足够强大。调整数据并确保数据符合你的用例,以及保证良好的数据质量,才是能产生更大影响的工作。
为了更具体一点,我来分享演讲中提到的一个趣事。
Andrew 和他的团队在进行一个制造业的缺陷检测项目时,准确率卡在了 76.2%。于是他把团队拆分,一个小组保持模型不变,增加新的数据或提高数据质量,另一个小组保持数据不变,但尝试改进模型。从事数据工作的小组能够将准确率提高到 93.1%,而另一个小组却丝毫没能提高性能。
我们所见的大多数成功团队都遵循类似的方法,我们也在试图把这个理念植入到每个用户心中。具体来说,以数据为中心的机器学习开发可以总结出以下几点经验:
1、数据飞轮:同步开发模型和数据
在演讲中,Andrew 提到他的团队通常在项目早期先开发一个模型,一开始不去花时间调整它。在第一批标注数据上运行后,通常能发现数据的一些问题,比如某个类别的代表性不足,数据有噪音(例如,模糊的图像),数据的标签很差……
然后,他们花时间修整数据,只有当模型性能无法再通过修整数据改善时,他们才会回到模型工作中,比较不同的架构,进行微调。
我们也在利用一切机会倡导这种被称为数据飞轮的方法。思路是需要建一个机器学习管道,它允许你在模型和数据上协同地进行快速迭代。你可以快速建立模型,将其暴露在新的数据中,提取预测不佳的样本,标注这些样本,再将其添加到数据集中,重新训练模型,然后再次测试。这是建立机器学习应用的最快和最可靠的方法。
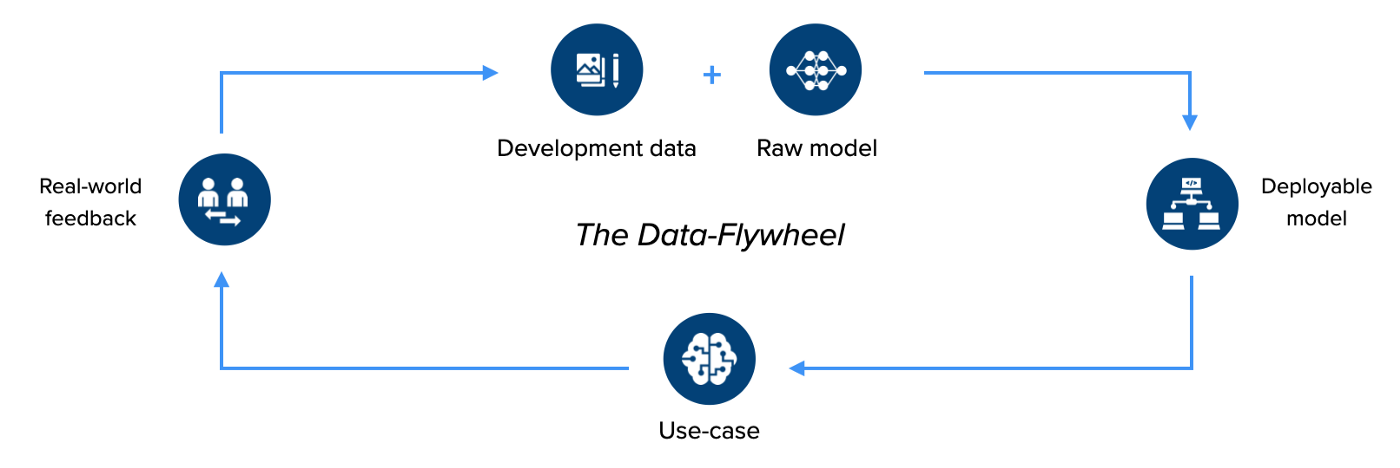
数据飞轮是一个迭代开发数据和模型的机器学习管道,可以在现实世界中不断提高性能。
这篇文章不是为了宣传,而是向你展示我们在hasty.ai对这个想法的认真态度:实际上,我们正是围绕这个思路建立起了整个业务,而且据我们所知,至少在视觉领域,我们是唯一这样做的公司。当你使用我们的标注工具时,就可以在交互界面得到一个数据飞轮。
在你标注图像时,我们在后台不断地为你(重新)训练模型,不需要你写一行代码。然后,我们用这个模型给你预测下一张图片上的标签,你可以纠正这些标签,从而有效提高模型的性能。你也可以使用我们的 API 或导出模型,用你自己的(可能是面向客户的)界面来建立飞轮。
当你通过改善Hasty中的数据达到性能稳定,就可以在Model Playground来微调模型,并达到 99.9%的准确率。
2、自己标注数据,至少在开始的时候
构建以数据为中心的机器学习意味着你应该自己标注数据。大多数停留在 SOTA 追逐思维的公司会把数据视为商品,并把标注工作外包。
然而,他们忽略了一些事实,真正在未来成为竞争优势的是他们正在建立的数据资产,而非训练的模型。如何建立模型是公共知识,而且很容易复制(对大多数的用例而言)。现在,每个人都可以免费学习机器学习基础。但是,建立一个大型的真实数据集是非常耗时和具有挑战性的,不投入足够时间的话是无法复制的。
用例越复杂,就越难建立数据资产。例子有很多,我简单挑一个,比如医学影像就需要一个相关领域的专家来进行高质量的标注。但是,即使把看起来很简单的标注工作外包出去也可能会导致问题,比如下面的例子,这个也是从 Andrew Ng 的精彩演讲中借来的。

如何标注对象并不总是十分明确。在标注时识别这样的边界情况,可能会节省你在调试模型时寻找它们的时间。
这是一幅来自ImageNet的图像。标注指令是 "使用边界框来表示鬣蜥的位置",这个指令乍听起来不难理解。然而,一位标注者在绘制标签时,没有让边界框重叠,并且忽略了尾巴。与此相反,第二位标注者考虑了左边鬣蜥的尾巴。
这两种方法本身都没有问题,但当其中一半标注采用一种方式,另一半用另一种方式时,就有问题了。当标注工作由外包完成时,你可能需要花几个小时才能发现这样的错误,而当你自己在内部做标注时,就可以更好地实现统一。
此外,处理这样的问题可以让你更好地了解边界情况,而这些边界情况有可能导致模型在生产环境中出现故障。例如,某只鬣蜥没有尾巴的时候看起来有点像青蛙,而你的模型可能会把这两者混淆在一起。
当然,这个例子是杜撰的,但是当你自己标注的时候,经常会遇到不确定如何标注的对象。当模型进入生产环境时,也会在同样的图像上挣扎。在早期就意识到这一点,可以让你提前采取行动,减少潜在问题的出现。
我在hasty.ai工作,当然也认为我们的标注工具是最好的。不过,我不是想说服你使用我们的工具。只是想强调,有必要审视一下现有的工具,看看哪一个最适合。使用正确的标注工具,可以让内部数据标注的成本降到可承受的水平,并给你带来上面提到的所有好处。
3、利用工具尽可能地减少 MLOps 的麻烦
遵循以数据为中心的方法会带来更多挑战,这并不仅限于标注数据方面。想建立如上所述的数据飞轮,在基础设施层面其实相当棘手。
如何把握好这一点是 MLOps 的艺术。MLOps 是机器学习应用领域中的一个新术语,描述了管道管理和如何确保模型在生产环境中按要求运行,有点像传统软件工程的 DevOps。
如果以前了解过 MLOps,你可能见到过谷歌论文《机器学习系统中隐藏的技术债务》中的图[5]。
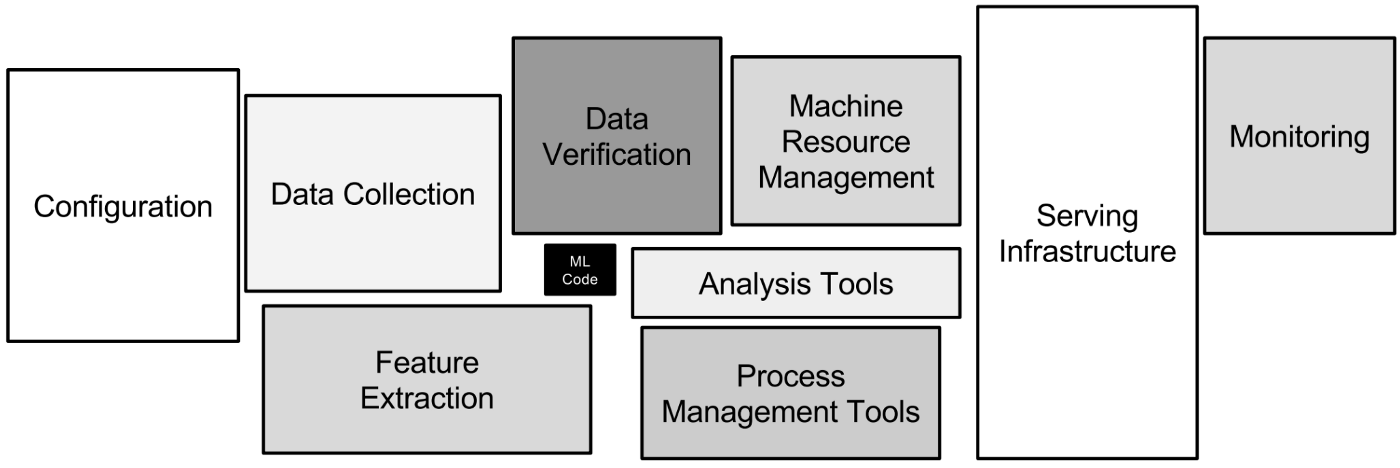
机器学习应用不仅仅是模型代码。所有其他的任务构成了 MLOps。现在越来越多的工具让 MLOs 变得简单。学聪明点,用这些工具来解决机器学习应用中的麻烦吧。图片来自[5]。
图中展示了 MLOps 的所有元素。在过去,有能力实现这一目标的公司需要建立庞大的团队,维护一系列的工具,编写无数行的胶水代码让它运行起来。大多数情况下,只有 FAANG(Facebook、Apple、Amazon、Netflix、Google)这样的公司才负担得起。
但现在出现了越来越多的创业公司,他们提供可以简化这一过程的工具,帮助你建立面向生产环境的机器学习应用,不需要再理会 MLOps 的喧嚣。我们hasty.ai就是其中之一,我们提供一个端到端的解决方案来构建复杂的视觉 AI 应用,并为你处理所有的飞轮信息。
但是,无论你最终是否使用Hasty,都应该明智地审视下有什么可以用,而不是尝试自己处理所有的 MLOps。这样可以腾出时间,让你专注于数据和模型之间的关系,增加应用项目的成功机率。
总结
将机器学习研究中发生的所有令人兴奋的事情应用于现实世界是有无限潜力的。然而,有 87%的机器学习应用项目仍然在概念验证阶段就宣告失败。
基于在 1 万多个项目上为生产环境训练 5 万多个模型的经验,我们认为,从以模型为中心的开发模式转变为以数据为中心的开发模式是促使更多项目成功的解决方案。我们并不是唯一有这样想法的公司,这已经成为行业中迅速发展的一种潮流。
许多机器学习应用团队还没有采用这种思维方式,因为他们在追逐 SOTA,模仿学术界做机器学习研究的方式,忽略了在机器学习应用中会遇到的不同情况。
不过,我决不是想贬低学术界,或者让人觉得他们的方法毫无价值。尽管对机器学习的学术界有一些合理的批评(这篇文章中我没有提及)[6],但在过去的几年中,他们做了这么多伟大的工作,这很迷人。我期待着学术界会有更多接地气的东西出来。
这也正是问题的关键,学术界的目标是做基础工作,为机器学习应用铺路。而机器学习应用的目标和环境完全不同,所以我们需要采用不同的、以数据为中心的思维方式来让机器学习应用发挥作用。
根据我们的经验,以数据为中心的机器学习可以归结为以下三点:
数据飞轮:协同开发模型和数据
自己标注数据,至少在刚开始时要这样做
使用工具,尽可能减少 MLOps 的麻烦
谢谢你阅读这篇文章并坚持到这里。我很想听到你的反馈,并了解你如何对待机器学习应用的挑战。你可以随时在 Twitter 或 LinkedIn 上与我联系。
如果你喜欢这篇文章,请分享它来传播数据飞轮和以数据为中心的机器学习思想。
如果你想阅读更多关于如何做以数据为中心的 VisionAI 的实践文章,请务必在 Medium 上关注我。
参考文献
[1] “为什么87%的数据科学项目从未真正投入生产” (2019), VentureBeat magazine article
[2] C. Northcutt, A. Athalye, J. Mueller,测试数据集中普遍存在的标签错误破坏了机器学习基准的稳定性(2021), ICLR 2021 RobustML and Weakly Supervised Learning Workshops, NeurIPS 2020 Workshop on Dataset Curation and Security
[3] N. Sambasivan, S. Kapania, H. Highfill, D. Akrong, P. Paritosh, L. Aroyo,每个人都想做模型工作,而不是数据工作:高风险AI中的数据问题累积(2021), proceedings of the 2021 CHI Conference on Human Factors in Computing Systems.
[4] S. Karayev, J. Tobin, P. Abbeel,全栈式深度学习(2021), UC Berkely course
[5] D. Sculley, G. Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V. Chaudhary, M. Young, J. Crespo, D. Dennison,机器学习系统中隐藏的技术债, Advances in Neural Information Processing Systems 28 (NIPS 2015)
[6] J. Buckmann,就公然地进行更多的学术欺诈吧(2021), personal blog
作者介绍:
Tobias Schaffrath Rosario,Hasty.ai 社区战略负责人,教机器如何看见世界,持续关注视觉 AI 领域。
原文链接:
https://towardsdatascience.com/stop-treating-data-as-a-commodity-ee2ac23fa578




