
背景
Spark 是目前最流行的分布式大数据批处理框架,使用 Spark 可以轻易地实现上百 G 甚至 T 级别数据的 SQL 运算,例如单行特征计算或者多表的 Join 拼接。
第四范式 OpenMLDB 是针对 AI 场景优化的机器学习开源数据库项目,实现了数据与计算一致性的离线 MPP 场景和在线 OLTP 场景计算引擎。其实 MPP 引擎可基于 Spark 实现,并通过拓展 Spark 源码实现数倍性能提升。
Spark 本身实现也非常高效,基于 Antlr 实现的了标准 ANSI SQL 的词法解析、语法分析,还有在 Catalyst 模块中实现大量 SQL 静态优化,然后转成分布式 RDD 计算,底层数据结构是使用了 Java Unsafe API 来自定义内存分布的 UnsafeRow,还依赖 Janino JIT 编译器为计算方法动态生成优化后的 JVM bytecode。但在拓展性上仍有改进空间,尤其针对机器学习计算场景的需求虽能满足但不高效,本文以 LastJoin 为例介绍 OpenMLDB 如何通过拓展 Spark 源码来实现数倍甚至数十倍性能提升。
机器学习场景 LastJoin
LastJoin 是一种 AI 场景引入的特殊拼表类型,是 LeftJoin 的变种,在满足 Join 条件的前提下,左表的每一行只拼取右表符合一提交的最后一行。LastJoin 的语义特性,可以保证拼表后输出结果的行数与输入的左表一致。在机器学习场景中就是维持了输入的样本表数量一致,不会因为拼表等数据操作导致最终的样本数量增加或者减少,这种方式对在线服务支持比较友好也更符合科学家建模需求。

包含 LastJoin 功能的 OpenMLDB 项目代码以 Apache 2.0 协议在 Github 中开源(github.com/4paradigm/OpenMLDB),所有用户都可放心使用。
基于 Spark 的 LastJoin 实现
由于 LastJoin 类型并非 ANSI SQL 中的标准,因此在 SparkSQL 等主流计算平台中都没有实现,为了实现类似功能用户只能通过更底层的 DataFrame 或 RDD 等算子来实现。基于 Spark 算子实现 LastJoin 的思路是首先对左表添加索引列,然后使用标准 LeftOuterJoin,最后对拼接结果进行 reduce 和去掉索引行,虽然可以实现 LastJoin 语义但性能还是有很大瓶颈。
相比于兼容 SQL 功能和语法,Spark 的另一个特点是用户可以通过 map、reduce、groupby 等接口和自定义 UDF 的方式来实现标准 SQL 所不支持的数值计算逻辑。但 Join 功能用户却无法通过 DataFrame 或者 RDD API 来拓展实现,因为拼表的实现是在 Spark Catalyst 物理节点中实现的,涉及了 shuffle 后多个 internal row 的拼接,以及生成 Java 源码字符串进行 JIT 的过程,而且根据不同的输入表数据量,Spark 内部会适时选择 BrocastHashJoin、SortMergeJoin 或 ShuffleHashJoin 来实现,普通用户无法用 RDD API 来拓展这些拼表实现算法。
在 OpenMLDB 项目中可以查看完整的 Spark LastJoin 实现,Github 代码地址:github.com/4paradigm/OpenMLDB。
第一步是对输入的左表进行索引列扩充,扩充方式有多种实现,只要添加的索引列每一行有 unique id 即可,下面是第一步的实现代码。
// Add the index column for Spark DataFrame def addIndexColumn(spark: SparkSession, df: DataFrame, indexColName: String, method: String): DataFrame = { logger.info("Add the indexColName(%s) to Spark DataFrame(%s)".format(indexColName, df.toString())) method.toLowerCase() match { case "zipwithuniqueid" | "zip_withunique_id" => addColumnByZipWithUniqueId(spark, df, indexColName) case "zipwithindex" | "zip_with_index" => addColumnByZipWithIndex(spark, df, indexColName) case "monotonicallyincreasingid" | "monotonically_increasing_id" => addColumnByMonotonicallyIncreasingId(spark, df, indexColName) case _ => throw new HybridSeException("Unsupported add index column method: " + method) } } def addColumnByZipWithUniqueId(spark: SparkSession, df: DataFrame, indexColName: String = null): DataFrame = { logger.info("Use zipWithUniqueId to generate index column") val indexedRDD = df.rdd.zipWithUniqueId().map { case (row, id) => Row.fromSeq(row.toSeq :+ id) } spark.createDataFrame(indexedRDD, df.schema.add(indexColName, LongType)) } def addColumnByZipWithIndex(spark: SparkSession, df: DataFrame, indexColName: String = null): DataFrame = { logger.info("Use zipWithIndex to generate index column") val indexedRDD = df.rdd.zipWithIndex().map { case (row, id) => Row.fromSeq(row.toSeq :+ id) } spark.createDataFrame(indexedRDD, df.schema.add(indexColName, LongType)) } def addColumnByMonotonicallyIncreasingId(spark: SparkSession, df: DataFrame, indexColName: String = null): DataFrame = { logger.info("Use monotonicallyIncreasingId to generate index column") df.withColumn(indexColName, monotonically_increasing_id()) }第二步是进行标准的 LeftOuterJoin,由于 OpenMLDB 底层是基于 C++实现,因此多个 join condition 的表达式都要转成 Spark 表达式(封装成 Spark Column 对象),然后调用 Spark DataFrame 的 join 函数即可,拼接类型使用“left”或者“left_outer"。
val joined = leftDf.join(rightDf, joinConditions.reduce(_ && _), "left")第三步是对拼接后的表进行 reduce,因为通过 LeftOuterJoin 有可能对输入数据进行扩充,也就是 1:N 的变换,而所有新增的行都拥有第一步进行索引列拓展的 unique id,因此针对 unique id 进行 reduce 即可,这里使用 Spark DataFrame 的 groupByKey 和 mapGroups 接口(注意 Spark 2.0 以下不支持此 API),同时如果有额外的排序字段还可以取得每个组的最大值或最小值。
val distinct = joined .groupByKey { row => row.getLong(indexColIdx) } .mapGroups { case (_, iter) => val timeExtractor = SparkRowUtil.createOrderKeyExtractor( timeIdxInJoined, timeColType, nullable=false) if (isAsc) { iter.maxBy(row => { if (row.isNullAt(timeIdxInJoined)) { Long.MinValue } else { timeExtractor.apply(row) } }) } else { iter.minBy(row => { if (row.isNullAt(timeIdxInJoined)) { Long.MaxValue } else { timeExtractor.apply(row) } }) } }(RowEncoder(joined.schema))最后一步只是去掉索引列即可,通过预先指定的索引列名即可实现。
distinct.drop(indexName)总结一下基于 Spark 算子实现的 LastJoin 方案,这是目前基于 Spark 编程接口最高效的实现了,对于 Spark 1.6 等低版本还需要使用 mapPartition 等接口来实现类似 mapGroups 的功能。由于是基于 LeftOuterJoin 实现,因此 LastJoin 的这种实现比 LeftOuterJoin 还差,实际输出的数据量反而是更少的,对于左表与右表有大量拼接条件能满足的情况下,整体内存消耗量还是也是非常大的。因此下面介绍基于 Spark 源码修改实现的原生 LastJoin,可以避免上述问题。
拓展 Spark 源码的 LastJoin 实现
原生 LastJoin 实现,是指直接在 Spark 源码上实现的 LastJoin 功能,而不是基于 Spark DataFrame 和 LeftOuterJoin 来实现,在性能和内存消耗上有巨大的优化。OpenMLDB 使用了定制优化的 Spark distribution,其中依赖的 Spark 源码也在 Github 中开源 (GitHub - 4paradigm/spark at v3.0.0-openmldb) 。
要支持原生的 LastJoin,首先在 JoinType 上就需要加上 last 语法,由于 Spark 基于 Antlr 实现的 SQL 语法解析也会直接把 SQL join 类型转成 JoinType,因此只需要修改 JoinType.scala 文件即可。
object JoinType { def apply(typ: String): JoinType = typ.toLowerCase(Locale.ROOT).replace("_", "") match { case "inner" => Inner case "outer" | "full" | "fullouter" => FullOuter case "leftouter" | "left" => LeftOuter // Add by 4Paradigm case "last" => LastJoinType case "rightouter" | "right" => RightOuter case "leftsemi" | "semi" => LeftSemi case "leftanti" | "anti" => LeftAnti case "cross" => Cross case _ => val supported = Seq( "inner", "outer", "full", "fullouter", "full_outer", "last", "leftouter", "left", "left_outer", "rightouter", "right", "right_outer", "leftsemi", "left_semi", "semi", "leftanti", "left_anti", "anti", "cross") throw new IllegalArgumentException(s"Unsupported join type '$typ'. " + "Supported join types include: " + supported.mkString("'", "', '", "'") + ".") }}其中 LastJoinType 类型的实现如下
// Add by 4Paradigmcase object LastJoinType extends JoinType { override def sql: String = "LAST"}在 Spark 源码中,还有一些语法检查类和优化器类都会检查内部支持的 join type,因此在 Analyzer.scala、Optimizer.scala、basicLogicalOperators.scala、SparkStrategies.scala 这几个文件中都需要有简单都修改,scala switch case 支持都枚举类型中增加对新 join type 的支持,这里不一一赘述了,只要解析和运行时缺少对新枚举类型支持就加上即可。
// the output list looks like: join keys, columns from left, columns from rightval projectList = joinType match { case LeftOuter => leftKeys ++ lUniqueOutput ++ rUniqueOutput.map(_.withNullability(true)) // Add by 4Paradigm case LastJoinType => leftKeys ++ lUniqueOutput ++ rUniqueOutput.map(_.withNullability(true)) case LeftExistence(_) => leftKeys ++ lUniqueOutput case RightOuter => rightKeys ++ lUniqueOutput.map(_.withNullability(true)) ++ rUniqueOutput case FullOuter => // in full outer join, joinCols should be non-null if there is. val joinedCols = joinPairs.map { case (l, r) => Alias(Coalesce(Seq(l, r)), l.name)() } joinedCols ++ lUniqueOutput.map(_.withNullability(true)) ++ rUniqueOutput.map(_.withNullability(true)) case _ : InnerLike => leftKeys ++ lUniqueOutput ++ rUniqueOutput case _ => sys.error("Unsupported natural join type " + joinType)}前面语法解析和数据结构支持新的 join type 后,重点就是来修改三种 Spark join 物理算子的实现代码了。首先是右表比较小时 Spark 会自动优化成 BrocastHashJoin,这时右表通过 broadcast 拷贝到所有 executor 的内存里,遍历右表可以找到所有符合 join condiction 的行,如果右表没有符合条件则保留左表 internal row 并且右表字段值为 null,如果有一行或多行符合条件就合并两个 internal row 到输出 internal row 里,代码实现在 BroadcastHashJoinExec.scala 中。因为新增了 join type 枚举类型,因此我们修改这两个方法来表示支持这种 join type,并且通过参数来区分和之前 join type 的实现。
override def doConsume(ctx: CodegenContext, input: Seq[ExprCode], row: ExprCode): String = { joinType match { case _: InnerLike => codegenInner(ctx, input) case LeftOuter | RightOuter => codegenOuter(ctx, input) // Add by 4Paradigm case LastJoinType => codegenOuter(ctx, input, true) case LeftSemi => codegenSemi(ctx, input) case LeftAnti => codegenAnti(ctx, input) case j: ExistenceJoin => codegenExistence(ctx, input) case x => throw new IllegalArgumentException( s"BroadcastHashJoin should not take $x as the JoinType") } }BrocastHashJoin 的核心实现代码也是使用 JIT 来实现的,因此我们需要修改 codegen 成 Java 代码字符串的逻辑,在 codegenOuter 函数中,保留原来 LeftOuterJoin 的实现,并且使用前面的参数来区分是否使用新的 join type 实现。这里修改的逻辑也非常简单,因为新的 join type 只要保证右表有一行数据拼到后就返回,因此不需要通过 while 来遍历右表候选集。
// Add by 4Paradigm if (isLastJoin) { s""" |// generate join key for stream side |${keyEv.code} |// find matches from HashRelation |$iteratorCls $matches = $anyNull ? null : ($iteratorCls)$relationTerm.get(${keyEv.value}); |boolean $found = false; |// the last iteration of this loop is to emit an empty row if there is no matched rows. |if ($matches != null && $matches.hasNext() || !$found) { | UnsafeRow $matched = $matches != null && $matches.hasNext() ? | (UnsafeRow) $matches.next() : null; | ${checkCondition.trim} | if ($conditionPassed) { | $found = true; | $numOutput.add(1); | ${consume(ctx, resultVars)} | } |} """.stripMargin }然后是修改 SortMergeJoin 的实现来支持新的 join type,如果右表比较大不能直接 broacast 那么大概率会使用 SortMergeJoin 实现,实现原理和前面的修改类似,不一样的是这里不是通过 JIT 实现的,因此直接修改拼表的逻辑即可,保证只要有一行符合条件即可拼接并返回。
private def bufferMatchingRows(): Unit = { assert(streamedRowKey != null) assert(!streamedRowKey.anyNull) assert(bufferedRowKey != null) assert(!bufferedRowKey.anyNull) assert(keyOrdering.compare(streamedRowKey, bufferedRowKey) == 0) // This join key may have been produced by a mutable projection, so we need to make a copy: matchJoinKey = streamedRowKey.copy() bufferedMatches.clear() // Add by 4Paradigm if (isLastJoin) { bufferedMatches.add(bufferedRow.asInstanceOf[UnsafeRow]) advancedBufferedToRowWithNullFreeJoinKey() } else { do { bufferedMatches.add(bufferedRow.asInstanceOf[UnsafeRow]) advancedBufferedToRowWithNullFreeJoinKey() } while (bufferedRow != null && keyOrdering.compare(streamedRowKey, bufferedRowKey) == 0) } }最后是 ShuffleHashJoin 的实现,对应的实现在子类 HashJoin.scala 中,原理与前面也类似,调用 outerJoin 函数遍历 stream table 的时候,修改核心的遍历逻辑,保证左表在拼不到时保留并添加 null,在拼到一行时立即返回即可。
private def outerJoin( streamedIter: Iterator[InternalRow], hashedRelation: HashedRelation, isLastJoin: Boolean = false): Iterator[InternalRow] = { val joinedRow = new JoinedRow() val keyGenerator = streamSideKeyGenerator() val nullRow = new GenericInternalRow(buildPlan.output.length) streamedIter.flatMap { currentRow => val rowKey = keyGenerator(currentRow) joinedRow.withLeft(currentRow) val buildIter = hashedRelation.get(rowKey) new RowIterator { private var found = false override def advanceNext(): Boolean = { // Add by 4Paradigm to support last join if (isLastJoin && found) { return false } // Add by 4Paradigm to support last join if (isLastJoin) { if (buildIter != null && buildIter.hasNext) { val nextBuildRow = buildIter.next() if (boundCondition(joinedRow.withRight(nextBuildRow))) { found = true return true } } } else { while (buildIter != null && buildIter.hasNext) { val nextBuildRow = buildIter.next() if (boundCondition(joinedRow.withRight(nextBuildRow))) { found = true return true } } } if (!found) { joinedRow.withRight(nullRow) found = true return true } false } override def getRow: InternalRow = joinedRow }.toScala } }通过对前面 JoinType 和三种 Join 物理节点的修改,用户就可以像其他内置 join type 一样,使用 SQL 或者 DataFrame 接口来做新的拼表逻辑了,拼表后保证输出行数与左表一致,结果和最前面基于 LeftOuterJoin + dropDuplicated 的方案也是一样的。
LastJoin 实现性能对比
那么既然实现的新的 Join 算法,我们就对比前面两种方案的性能吧,前面直接基于最新的 Spark 3.0 开源版,不修改 Spark 优化器的情况下对于小数据会使用 broadcast join 进行性能优化,后者直接使用修改 Spark 源码编译后的版本,在小数据下 Spark 也会优化成 broadcast join 实现。
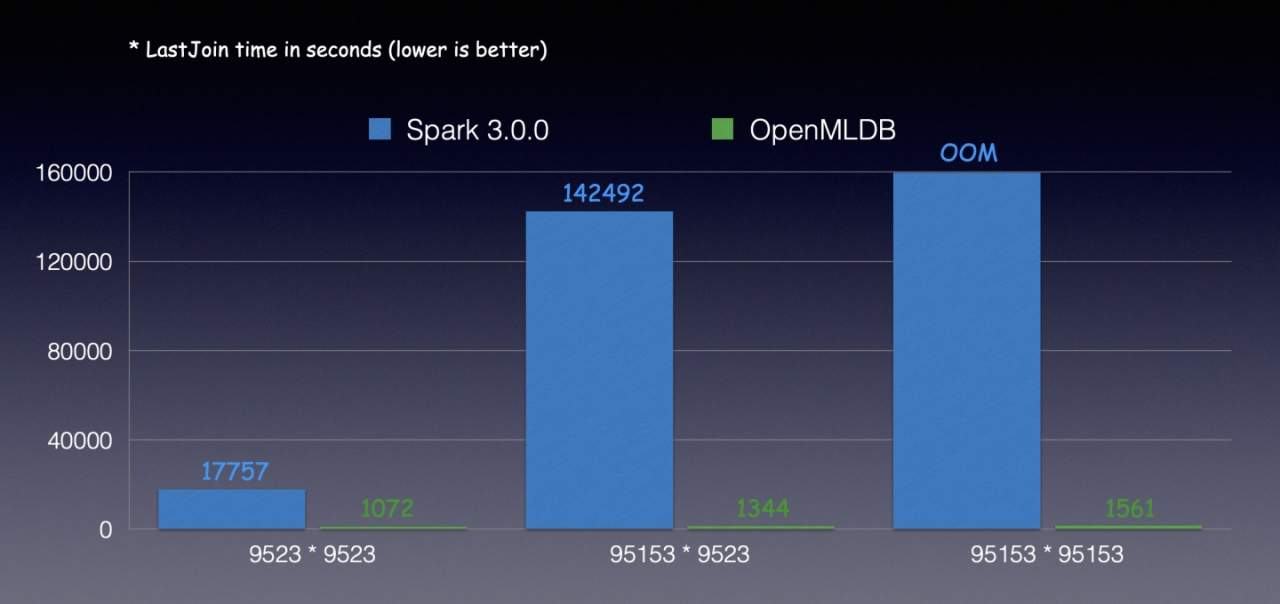
首先是测试 join condiction 能拼接多行的情况,对于 LeftOuterJoin 由于能拼接多行,因此第一个阶段使用 LeftOuterJoin 输出的表会大很多,第二阶段 dropDuplication 也会更耗时,而 LastJoin 因为在 shuffle 时拼接到单行就返回了,因此不会因为拼接多行导致性能下降。

从结果上看性能差异也很明显,由于右表数据量都比较小,因此这三组数据 Spark 都会优化成 broadcast join 的实现,由于 LeftOuterJoin 会拼接多行,因此性能就比新的 LastJoin 慢很多,当数据量增大时 LeftOuterJoin 拼接的结果表数据量更加爆炸,性能成指数级下降,与 LastJoin 有数十倍到数百倍的差异,最后还可能因为 OOM 导致失败,而 LastJoin 不会因为数据量增大有明显的性能下降。
右表能拼接多行对 LeftOuterJoin + dropDupilicated 方案多少有些不公平,因此我们新增一个测试场景,拼接时保证左表只可能与右表的一行拼接成功,这样无论是 LeftOuterJoin 还是 LastJoin 结果都是一模一样的,这种场景下性能对比更有意义。

从结果上看性能差异已经没有那么明显了,但 LastJoin 还是会比前者方案快接近一倍,前面两组右表数据量比较小被 Spark 优化成 broadcast join 实现,最后一组没有优化会使用 sorge merge join 实现。从 BroadcastHashJoin 和 SortMergeJoin 最终生成的代码可以看到,如果右表只有一行拼接成功的话,LeftOuterJoin 和 LastJoin 的实现逻辑基本是一模一样的,那么性能差异主要在于前者方案还需要进行一次 dropDuplicated 计算,这个 stage 虽然计算复杂度不高但在小数据规模下耗时占比还是比较大,无论是哪种测试方案在这种特殊的拼表场景下修改 Spark 源码还是性能最优的实现方案。
技术总结
最后简单总结下,OpenMLDB 项目通过理解和修改 Spark 源码,可以根据业务场景来实现新的拼表算法逻辑,从性能上看比使用原生 Spark 接口实现性能可以有巨大的提升。Spark 源码涉及 SQL 语法解析、Catalyst 逻辑计划优化、JIT 代码动态编译等,拥有这些基础后可以对 Spark 功能和性能进行更底层的拓展。




