
Twitter 是广告商吸引受众的一个热门平台。当广告商发起一个新的广告活动,它们会限定一个广告预算。Twitter 的广告服务器会检查广告活动的预算,以便确定是否还能继续投放广告。如果没有这个检查机制,我们可能会在广告活动达到预算限额后继续提供广告服务。我们把这种情况叫作超支。超支会导致 Twitter 的收入损失(由于机会成本的增加——例如,我们本可以在那个位置显示其他广告)。所以,我们要建立一个可靠的系统来防止发生超支。
背景简述
在深入研究超支是如何发生前,先来了解一下我们的广告系统是如何提供广告服务的。下面是我们广告服务管道的高级架构图:
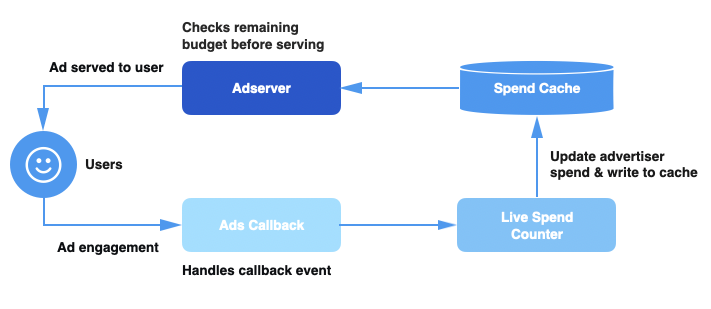
支出缓存(Spend Cache)——一个分布式缓存服务,可以跟踪每个广告活动的当前预算支出。
实时广告支出计数器(Live Spend Counter,LSC)——一个基于 Apache Heron 的服务,负责聚合广告活动并更新支出缓存。
广告回调(Ads Callback)——处理用户浏览事件的管道,为事件添加上下文信息,并将它们发送到 LSC。
广告服务器(Ad Server)——在处理请求时,决定是否应该从广告支出缓存中获取当前活动的支出。需要注意的是,这里所说的广告服务器包括了向用户提供广告的多种服务。
当用户在 Twitter 上浏览广告时,我们会向广告回调管道发送一个事件。一旦活动支出计数器收到这个事件,它将计算活动的总支出,并在支出缓存中更新活动的支出。对于每个传入的请求,广告服务器管道都会查询支出缓存,以便获得活动的当前支出,并根据剩余的预算确定是否继续提供服务。
广告预算超支
因为我们处理的广告活动的规模比较大(数据中心每秒有数以百万计的广告浏览事件),所以延迟或硬件故障随时都可能在我们的系统中发生。如果支出缓存没有更新最新的活动支出,广告服务器就会获取到陈旧的信息,并继续为已经达到预算上限的活动提供广告服务。我们将永远无法收取超出广告预算的那部分费用,导致 Twitter 的收入损失。
例如,假设有一个每天预算为 100 美元的广告活动,每一次点击的价格为 0.01 美元。在没有超支的情况下,这将为活动创造每天 10000 次点击的机会。

假设广告回调管道或 LSC 出现故障,导致支出缓存没有更新,丢失了价值 10 美元的事件,支出缓存只会报告支出为 90 美元,而实际上活动已经支出了 100 美元,那么该活动将获得额外的 1000 次免费点击机会。
跨数据中心一致性
Twitter 有多个数据中心,每个数据中心都部署了整个广告服务管道的副本,包括广告回调管道、实时支出计数器和支出缓存。当用户点击广告时,回调事件被路由到其中的一个数据中心,这个数据中心里的回调管道将负责处理这个事件。
那么,问题就来了:每个数据中心计算的总支出只计算该数据中心接收到的事件,不包括其他数据中心的数据。由于广告客户的预算是跨数据中心的,这意味着每个数据中心的支出信息是不完整的,可能会少算了广告客户的实际支出。
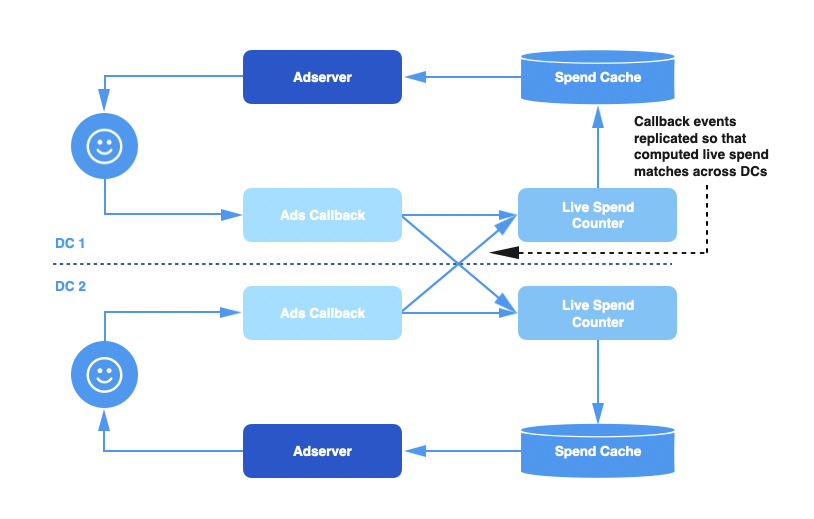
为了解决这个问题,我们给回调事件队列添加了跨数据中心复制功能,以便让每个数据中心都能够处理所有的事件。这确保了每个数据中心中的支出信息是完整和准确的。
单个数据中心的故障
尽管复制事件为我们带来了更好的一致性和更准确的支出信息,但系统的容错能力仍然不是很强。例如,每隔几周,跨数据中心复制失败就会导致支出缓存由于事件丢失或滞后而失效。通常,广告回调管道会出现系统问题,例如垃圾收集停顿或数据中心的不可靠网络连接导致的事件处理延迟。由于这些问题发生在数据中心本地,该数据中心中的 LSC 接收到的事件与延迟成正比,因此支出缓存的更新也将延迟,从而导致超支。
在过去,如果一个数据中心发生这些故障,我们会禁用这个数据中心的 LSC,并让其他数据中心的 LSC 同时更新本地缓存和发生故障的数据中心的 LSC,直到出现滞后的广告调管道和 LSC 重新追上来。
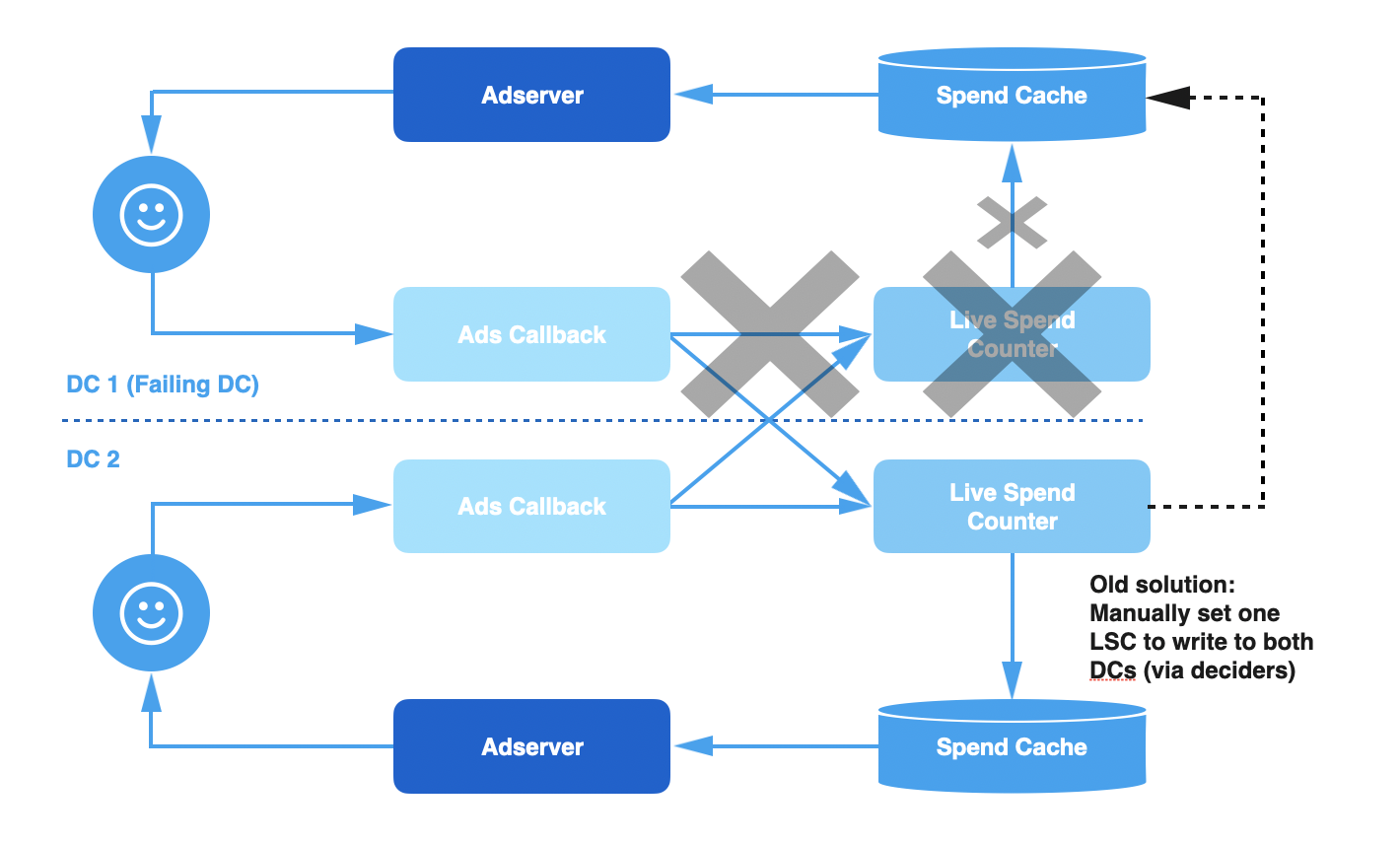
这种解决方法有效地避免了临时性的超支问题,但仍然有几个不足的地方:
手动切换:启用跨数据中心写入是一个手动执行的过程,需要按一定的顺序进行多个设置更改。我们最终使用了脚本,但仍然需要一个待命工程师手动执行脚本。
手动选择数据中心:需要一个包含多个步骤的手动执行过程来确定哪个数据中心是健康的以及启用跨数据中心写入是否安全。当故障恢复需要回到初始配置时,必须重复类似的过程。有时候,这个过程需要来自不同团队的多个待命工程师共同努力。
高运维成本:由于管理工作区涉及了多个手动步骤,回调基础设施问题会带来很高的运维成本。
跨数据中心写入方案
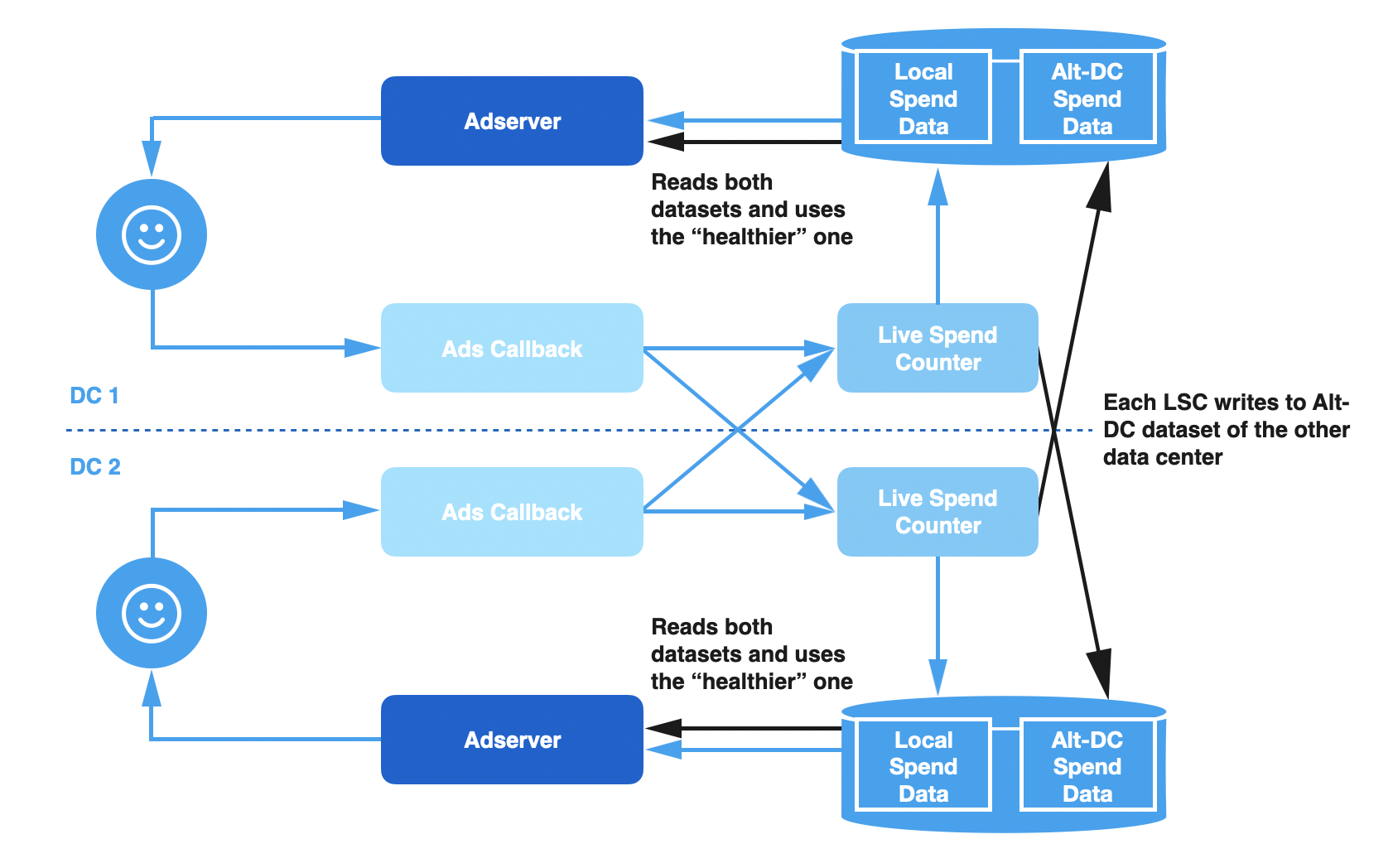
由于这种架构存在很多问题,我们重新设计了管道,让它能更有弹性地应对故障,并减少运维人员的干预。这个解决方案有两个主要组成部分:
跨数据中心写入:LSC 总是同时更新“备用”数据中心的支出缓存和本地缓存。它还会写入一些有关数据运行状况的元数据。每个 LSC 实例维护两个单独的数据集,一个只计算本地的信息,另一个只计算来自远程实例写入的数据。
数据集健康检查:在处理请求时,广告服务器管道读取两个版本的数据,并根据哪个数据集更健康自动选择使用哪个版本。
在正常情况下,新解决方案的工作原理与之前的设计完全一致。但是,如果本地支出缓存落后了,广告服务器能够检测到,并自动切换到包含来自远程写入数据的数据集。当本地的问题解决之后,广告服务器将自动切换回本地数据集。
我们怎么知道哪个数据集更健康?
我们通过常见的故障场景来决定数据集的健康情况:
延迟:当广告回调管道/LSC 无法及时处理大量的事件,就会出现延迟。事件是按照它们到达的顺序处理的,所以我们更倾向于选择包含最新事件的数据集。
丢失事件:在某些故障场景中,事件可能会完全丢失掉。例如,如果广告回调管道的跨数据中心复制失败,其中一个数据中心将丢失一些远程事件。因为所有的数据中心都应该处理所有的事件,所以我们应该选择处理了最多事件的那个数据集。
为了构建一个包含这两个因素的健康检查机制,我们引入了支出直方图的概念。
支出直方图
假设我们有一个滚动窗口,显示每个数据中心的 LSC 在任意给定时刻正在处理的事件计数。滚动窗口包含最近 60 秒内每毫秒处理了多少事件的计数。当到达窗口的末尾,我们删除头部的计数,并计算后面 1 毫秒的计数。我们可以看到 LSC 在 60 秒内处理的“事件计数”的直方图。直方图如下图所示:
为了能够选择最佳的数据集(在广告服务端),我们利用了这个直方图和最近的事件时间戳。LSC 将这些元数据与支出数据一起写入支出缓存。
LSC 在写入时不会序列化/反序列化整个直方图。在写入之前,它会汇总窗口中所有计数器的计数,并写入一个聚合值。这里使用事件的近似值就足够了,近似值可以作为这个数据中心的 LSC 总体健康状况的信号。这是由故障的本质决定的——如果故障足够严重,我们将立即看到故障的影响,计数会显著下降。如果不是很严重的话,数量几乎是一样的。
包含元数据的结构体是这样的:
struct SpendHistogram { i64 approximateCount; i64 timestampMilliSecs;}在处理请求时,广告服务器同时读取本地和远程的数据集。它使用 SpendHistogram 根据下面描述的数据中心选择逻辑来决定使用哪个数据集作为事实数据来源。
数据中心的选择
选择数据集的逻辑如下:
从两个数据中心获取 SpendHistogram。
首选具有最新时间戳和最高事件计数的数据集。
如果它们非常相近且都处于正常状态,就首选本地数据集,这样可以避免由于小的延迟而在两个数据中心之间来回切换。
这可以总结成以下的真值表:
x = LocalTimeStamp - RemoteTimeStamp
y = LocalApproxCount - RemoteApproxCount
ts = ThresholdTimeStamp
tc = ThresholdApproxCountPercent
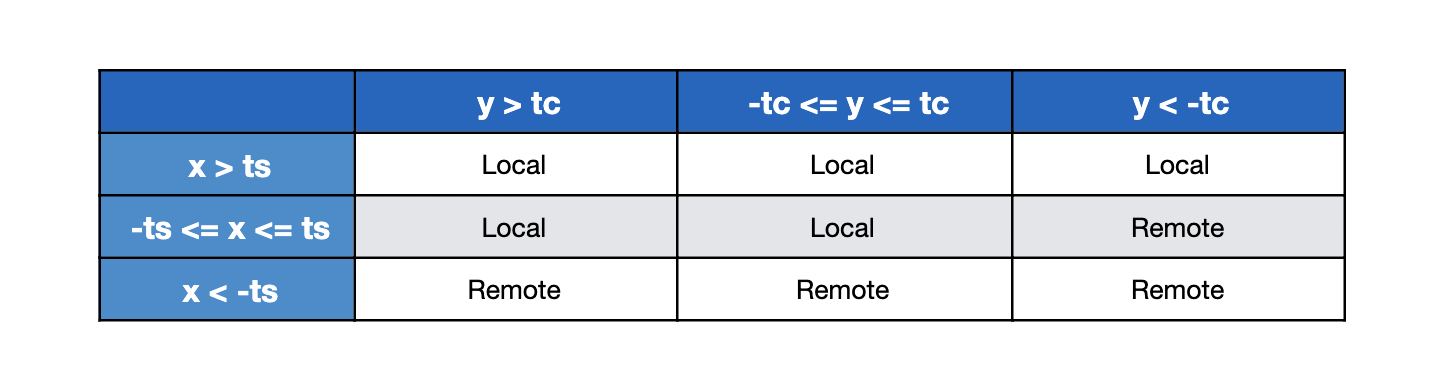
在切换到使用来自远程数据中心的数据集之前,我们使用 ts 和 tc 来确定容忍度阈值。如果差值在阈值内,我们会更倾向于使用本地数据集。我们尝试找到阈值,以便在不需要进行数据中心切换的情况下尽早检测故障。广告服务器在处理每个请求时都会发生这个选择过程,因此我们会在本地进行缓存,每隔几秒刷新一次,以防止频繁的网络访问影响整体性能。
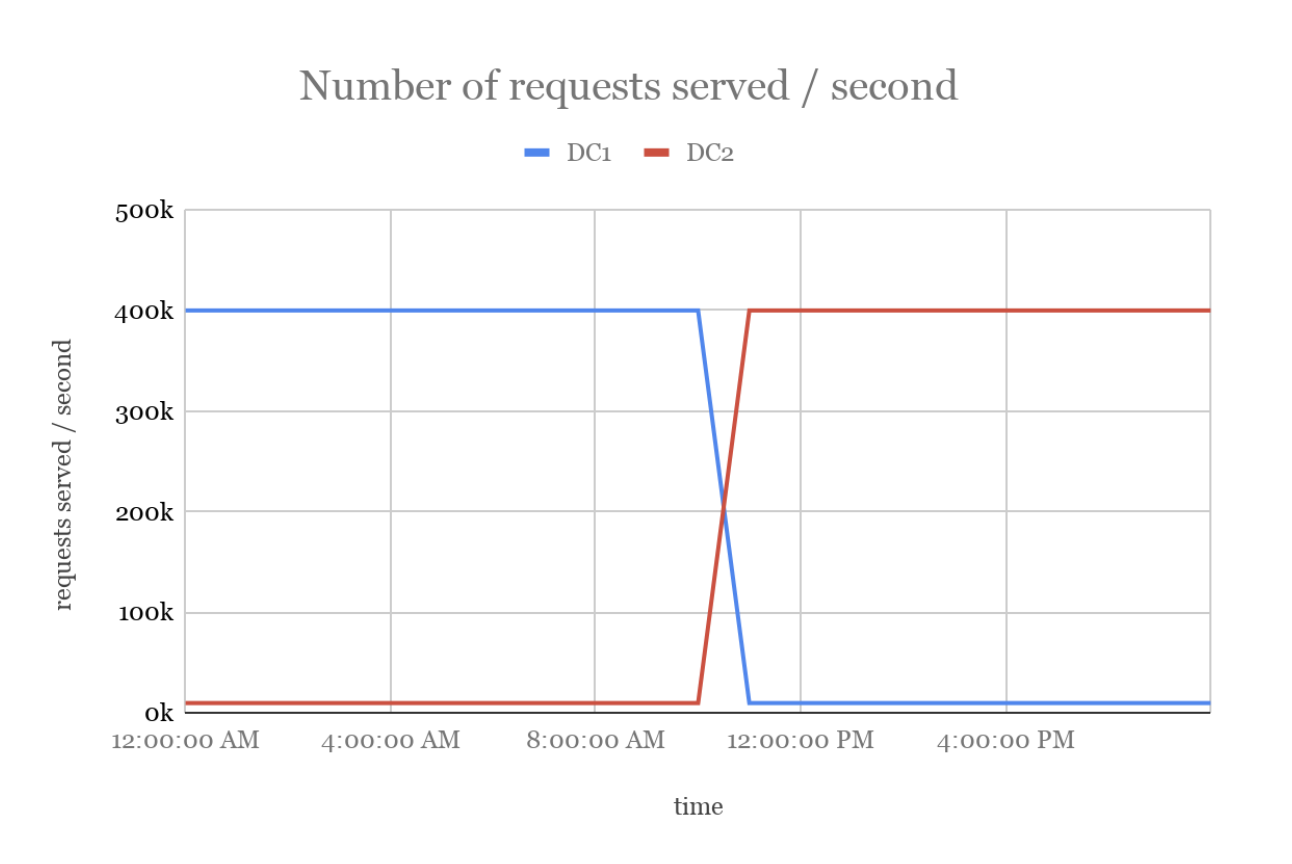
下面是切换使用数据中心数据的可视化表示。当 DC1 的 LSC 发生故障时,会导致 DC1 的广告服务器自动选择使用 DC2 的数据。
扩展到多个数据中心
到目前为止,我们讨论的方法只涉及两个数据中心。通过引入跨数据中心复制因子的概念,我们可以将设计扩展到“N”个数据中心。复制因子控制每个 LSC 服务写入的远程数据中心的数量。在读取数据时,我们使用了相同的逻辑,并做了一些优化,比如一次读取(批读取)所有必要数据,而不是分多次读取。
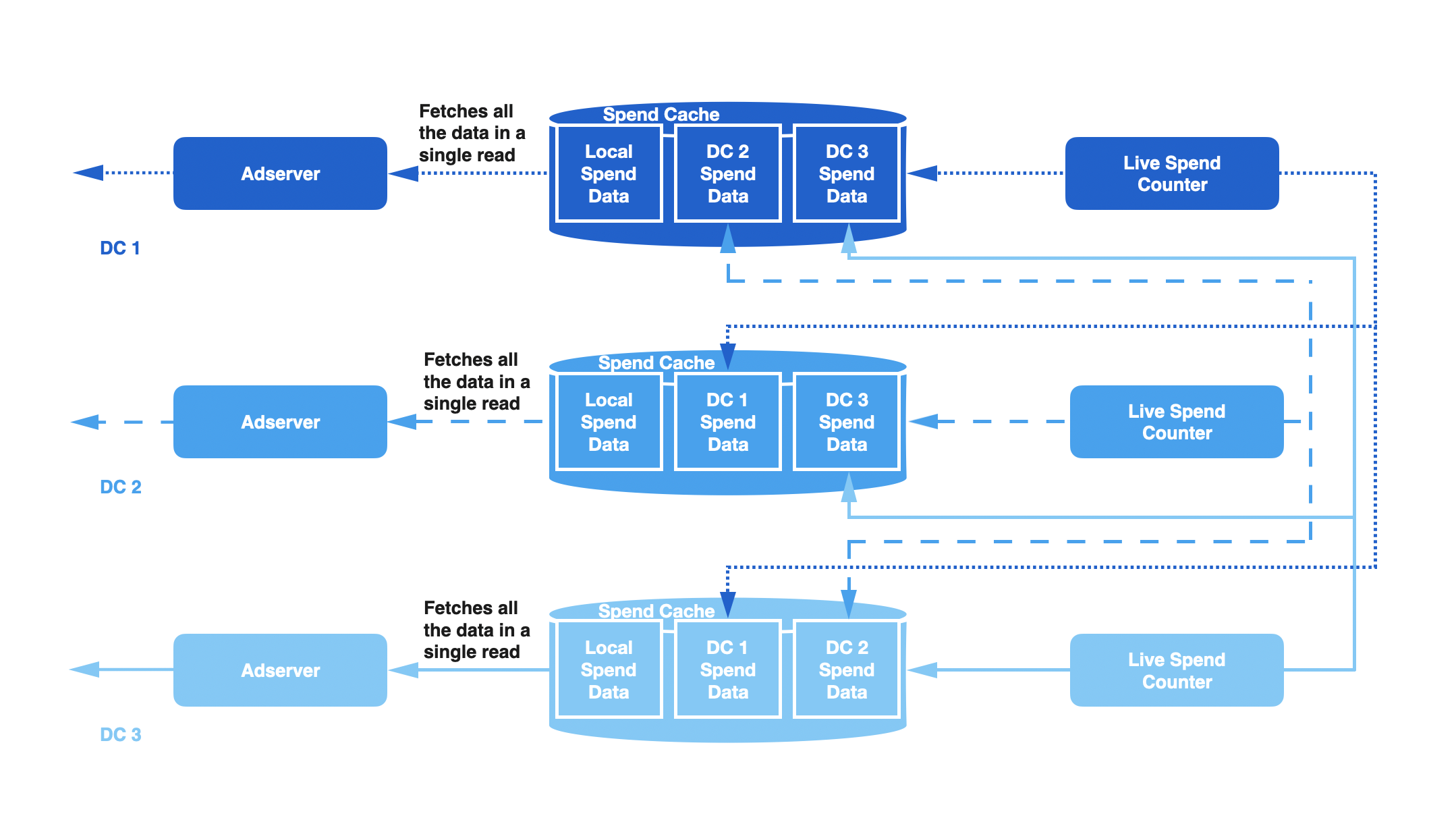
例如,假设 ReplicationFactor 设置为 2,DC1 中的 LSC 将写入到 DC1、DC2 和 DC3 的支出缓存,DC2 中的 LSC 将写入到 DC2、DC3 和 DC4 的支出缓存,DC3 中的 LSC 将写入到 DC3、DC4 和 DC1 的支出缓存。下图显示了三个数据中心的复制原理图。在每个数据中心中,广告服务器将读取三个支出直方图,并从所有这些数据中心选择首选的数据集。根据我们的网络和存储约束,我们选择 2 作为复制因子。
结论
在推出这些变更之后,我们注意到团队的运维成本发生了重大变化。之前每个季度由于系统问题会导致多次超支事件,而在过去的一年,都没有发生此类事件。这节省了大量的工程时间,并避免了由于基础设施问题而向广告商发放补偿。
通过识别系统健康关键指标,设计出最简单的工程解决方案,并根据这些指标自动采取行动,我们解决了一个影响服务管道正确性的关键性问题。我们不仅构建了一个具有容错能力和弹性的系统,而且释放了工程资源,把它们用在更有价值的地方。
原文链接:




