
近年来,Deepfake 图像做得越来越逼真了。在某些情况下,人类甚至没法轻易看出这些图像与真实图像之间的区别。尽管 Deepfake 图像的检测仍然是业界面对的一大挑战,但由于这项技术的水平越来越高,检测它的动机也越来越充分,例如:如果 Deepfake 图像不仅是为了娱乐和技术展示用途,而被用于大规模欺诈行为该怎么办?
今天,我们与密歇根州立大学(MSU)合作,展示了一种检测和归因(attributing)Deepfake 图像的研究方法,这种方法的基础是对单张 AI 生成图像的生成模型的逆向工程。我们的方法将推动真实世界环境中的 Deepfake 图像检测和跟踪研究,现实中 Deepfake 图像本身通常是检测器唯一能用到的信息。

为什么要逆向工程?
当前讨论 Deepfake 图像的方法侧重于判断图像是真实的还是 Deepfake(检测),或识别图像是否由训练期间看到的模型生成(基于“封闭集”分类的图像归因)。但是,要想应对 Deepfake 图像激增的趋势,需要更进一步的研究,并设法将图像归因(image attribution)扩展到训练中存在的有限模型集之外。重点在于超越封闭的图像归因方法限制,因为 Deepfake 图像可能是用在训练中没见过的生成模型来创建的。
逆向工程是解决 Deepfake 图像问题的另一种方式,但它在机器学习中并不是一个新概念。之前关于逆向工程 ML 模型的研究是通过检查其输入/输出对来获得模型的,这种方法将模型本身视为一个黑匣子。另一种方法假设硬件信息(例如 CPU 和内存使用情况)在模型推理期间是可用的。这两种方法都依赖关于模型本身的先验知识,这限制了它们在现实世界中的实用性,因为这些信息通常是不可用的。
我们的逆向工程方法的基础是找出用于生成单个 Deepfake 图像的 AI 模型背后的独特模式。我们从图像归因开始,然后设法发现用于生成图像的模型属性。将图像归因泛化到开放集识别后,我们就可以推理出用于创建 Deepfake 图像的生成模型的更多信息,而不只是判断出某个模型是从未见过的。
通过追踪一组 Deepfake 图像模式之间的相似性,我们还可以判断一系列图像是否来自单一来源。这种检测哪些 Deepfake 图像是从同一 AI 模型生成的能力,可以用来发现使用大量 Deepfake 图像发起的误导宣传或其他恶意攻击的实例。
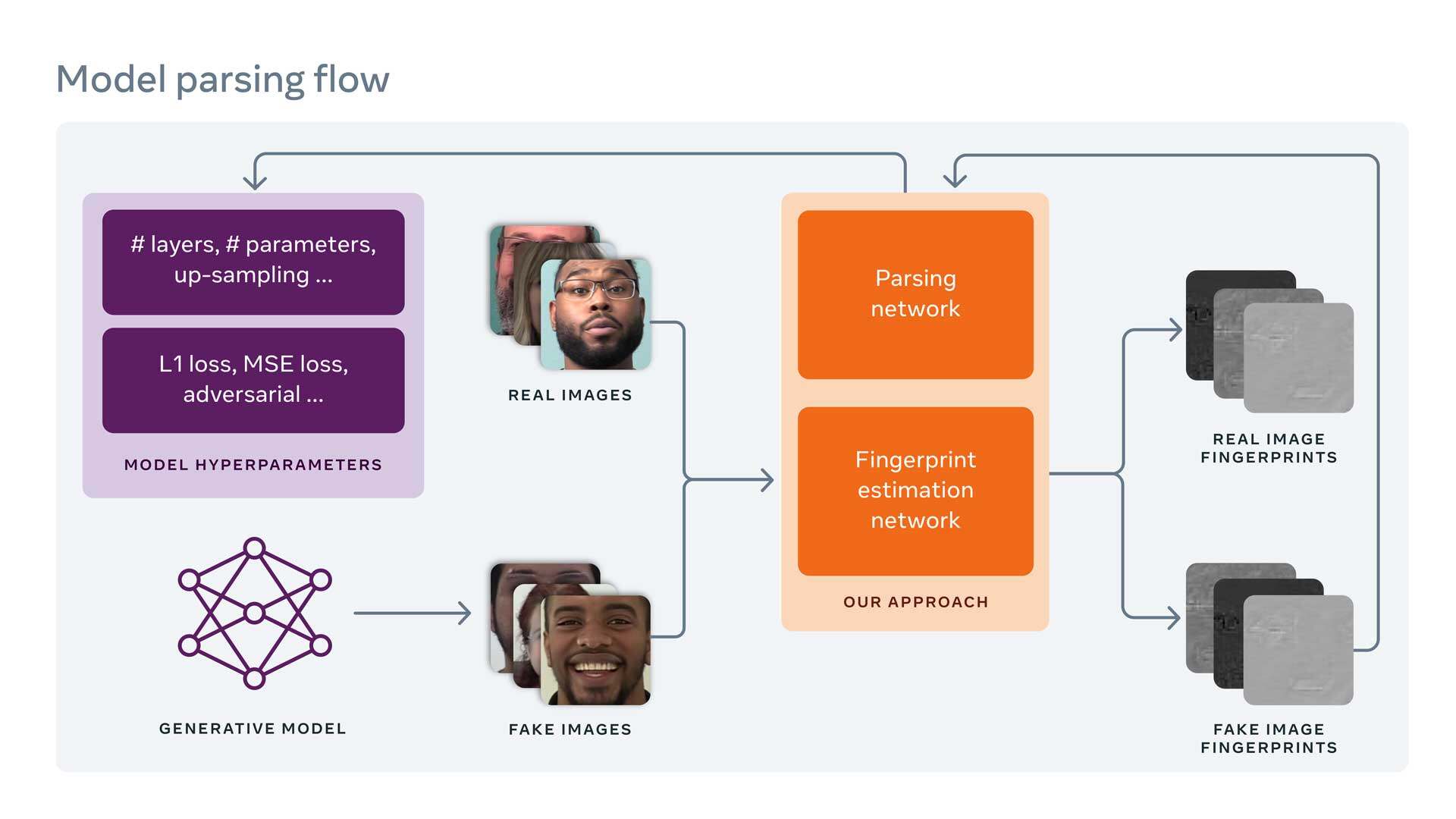
工作机制
我们首先通过一个指纹估计网络(FEN)运行一个 Deepfake 图像,以估计生成模型留下的指纹细节。
设备指纹是由特定设备由于生成过程中的缺陷,在每个图像上留下的微妙但独特的图案。在数码摄影中,指纹是用来识别用于生成图像的数码相机的。与设备指纹类似,图像指纹是由生成模型在生成的图像上留下的独特模式,同样可用于识别图像的生成模型。
在深度学习时代之前,研究人员一般使用一套小型的、手工制作的、众所周知的工具来生成照片。这些生成模型的指纹是通过他们手工制作时留下的特征来估计的。深度学习让可用于生成图像的工具集变得无穷无尽,让研究人员无法通过手工制作的特征来识别特定的“信号”或指纹属性。
为了应对这种无限的可能性,我们使用指纹的属性作为开发约束来执行无监督训练。换句话说,我们根据指纹的常见属性使用不同的约束来估计指纹,包括指纹大小、重复性、频率范围和对称频率响应等。然后我们使用不同的损失函数将这些约束应用于 FEN,强制它生成的指纹具有这些所需的属性。一旦指纹生成完成,指纹就可以用作模型解析的输入。
模型解析是一个新问题,它使用估计的生成模型指纹来预测模型的超参数,即构成模型架构的属性,包括网络层数、块数和每个块中使用的操作类型。模型的超参数影响它生成的 Deepfake 图像类型的一个例子是,它的训练损失函数指导模型的训练方式。
模型的网络架构及其训练损失函数类型都会影响其权重,从而影响其生成图像的方式。为了更好地理解超参数,我们可以将生成模型视为一种汽车,将其超参数视为各种特定的发动机组件。不同的汽车可能看起来很相似,但在引擎盖下,它们可能有着非常不同的发动机和截然不同的组件。我们的逆向工程技术有点像根据汽车的声音来识别汽车的组件,即使这是我们以前从未听过声音的新车。
通过我们的模型解析方法,我们同时估计用于创建 Deepfake 图像的模型的网络架构及其训练损失函数。我们对网络架构中的一些连续参数做了归一化以便于训练,并且还进行了分层学习以对损失函数类型进行分类。由于各个生成模型在网络架构和训练损失函数方面大都是不一样的,因此从 Deepfake 或生成图像到超参数空间的映射,使我们能够获得用于创建它的模型特征的关键信息。
为了测试这一方法,MSU 研究团队用了一个伪造图像数据集,其中包含从 100 个公开可用的生成模型生成的 100,000 张合成图像。100 个生成模型各对应一个由整个科学界的研究人员开发和共享的开源项目。一些开源项目已经发布了伪造图像,在这种情况下 MSU 研究团队随机选择 1,000 张图像。
在开源项目没有任何可用的伪造图像的情况下,研究团队会运行他们发布的代码来生成 1,000 张合成图像。鉴于测试图像可能来自现实世界中一个未曾见过的生成模型,研究团队通过交叉验证来模拟现实世界的应用程序,以在我们数据集的不同分割上训练和评估我们的模型。
我们的结果
由于我们是第一个做模型解析的团队,因此没有现有的对比基线。我们随机打乱了 ground-truth 集中的每个超参数,形成了一个称为随机 gt 的基线。这些随机 gt 向量保持原始分布。
结果表明,我们方法的性能明显优于随机 gt 基线。这表明,与相同长度和分布的随机向量相比,生成的图像与有意义的架构超参数和损失函数类型的嵌入空间之间确实存在更强的广义相关性。我们还进行了消融研究,以证明指纹估计和分层学习的有效性。

从 100 个 GM 中生成的图像在左侧生成估计的指纹,在右侧生成对应的频谱。许多频谱显示的高频信号是不一样的,而有些似乎比较相似。
除了模型解析之外,我们的 FEN 还可用于 Deepfake 图像检测和图像归因。对于这两个任务,我们添加了一个浅层网络,输入估计的指纹并执行二进制(Deepfake 图像检测)或多类分类(图像归因)。虽然我们的指纹估计不是为这些任务量身定制的,但我们仍然取得了有竞争力的一流成果,表明我们的指纹估计具有优良的泛化能力。
发展对社会负责任的人工智能技术一直是我们的优先战略,所以我们会尽可能采用以人为中心的研究方法。来自 100 个生成模型的 Deepfake 图像的多样化集合,意味着我们的模型是用有代表性的选项构建的,并且有着更好的泛化人类和非人类表征的能力。
尽管用于生成 Deepfake 图像的一些原始图像是公开可用的面部数据集中真实个体的图像,但 MSU 研究团队使用的是 Deepfake 图像(而不是用于创建它们的原始图像)来做取证式分析。由于这种方法会将 Deepfake 图像解构为指纹,因此 MSU 研究团队分析了这种模型是否可以将指纹映射回原始图像内容。结果表明没有发生这种情况,这证实了指纹主要包含生成模型留下的痕迹,而不是原始 Deepfake 图像的内容。
用于本研究的所有伪造人脸图像均由 MSU 生成。逆向工程过程的相关实验也都在 MSU 进行。MSU 将向更广泛的研究社区开源数据集、代码和训练模型,以促进各个领域的研究,包括 Deepfake 图像检测、图像归因和生成模型的逆向工程。
研究的意义
我们的研究突破了 Deepfake 检测的现有局限,引入了更适合现实环境部署的模型解析概念。这项工作将为研究人员和从业人员提供工具,帮助他们更好地调查使用 Deepfake 图像发起的大规模信息误导事件,并为未来的研究开辟新的方向。
MSU 的代码、数据集和训练模型(https://github.com/vishal3477/Reverse_Engineering_GMs?fbclid=IwAR1bZrM484AT-CDEKGiaKXbn4sLYC_Ydwt6CZWo0W8xfeFkvpWeEqzhjQxg)
模型解析是与密歇根州立大学的 Vishal Asnani 和 Xiaoming Liu 合作开发的。
原文链接:https://ai.facebook.com/blog/reverse-engineering-generative-model-from-a-single-deepfake-image




