
摘要:为什么工程师要把数据库拆开然后再重新组合起来呢?
数据库界最近的一个趋势是将数据库拆解成它的组成部分。每个组件都是单独提供的,因此基础设施工程师可以将它们集成到数据库中。
大多数数据库都有相同的组成部分:查询解析器、逻辑和物理规划器、优化器、预写日志、客户端连接协议等等。每个数据库通常都实现这些组件的各自版本。(除了MySQL的MyISAM/InnoDB或广泛使用的RocksDB等存储引擎之外。)
单体数据库很有意义。每一层都与它上面和下面的层相集成;抽象这些层是很困难的。可插拔层需要一个灵活的 API,并支持不同的(通常是对立的)用例。
然而,这些层中的大多数最终看起来都差不多。一个特定的数据库可能只在一层中使用了它的大部分创新代币(innovation tokens);比如优化器。但从历史上看,开发人员不得不重新实现每一层,因为现成的组件有限。新的开源项目正在构建这些组件。
在本文中,我将讨论数据库的拆解历史、行业现状、发展方向以及这一趋势的影响。我发现以两个以大象为主题的项目(Apache Hadoop和PostgreSQL)的视角来看拆解是很有启发性的。尽管 Hadoop 和 PostgreSQL 来自数据栈的不同部分,但它们都影响了现代的拆解工作。让我们先从 Hadoop 开始。
Hadoop 对拆解的影响
18 年前,Hadoop 将数据仓库拆分为计算平面、数据平面和控制平面,这一范例一直延续至今。
计算平面负责运行计算;最初是MapReduce。数据平面负责提供存储;最初是HDFS。控制平面负责协调计算的部署和执行;最初是 Hadoop 的JobTracker,然后是YARN。
独立的平面(通常在不同的计算机上)为协议和 API 的开发创造了边界。这样的发展是拆解数据库的先决条件。
下一步是处理存储格式。Hadoop 用户很快发现它们需要以文件格式来将数据写入 HDFS。用户通常从 CSV 开始,但很快发现文本解析很慢。早期优化存储格式的尝试导致了 Twitter 的Elephant Bird和 LinkedIn 的Voldemort存储格式。随后,Apache Avro、Apache ORC和Apache Parquet得到了广泛的采用,并且 Parquet 最终获胜(至少现在是这样)。
Apache Hive和Apache Pig在 MapReduce 的基础上构建了进一步的拆解。这些查询引擎将基于文本的查询(SQL 或Pig Latin)转换为在 Hadoop 上运行的 MapReduce 作业。
我们现在开始可以看到一个拆分后的数据库轮廓了:一个带有解析器的查询引擎(Hive/Pig)、一个查询计划和一个优化器,它位于查询运行时(MapReduce)之上。查询运行时以优化的存储格式(Parquet)从数据平面(HDFS)中读取数据。
我们现在的架构就是这样的。Hive 和 Pig 已被Presto、Apache Spark和Trino所取代。HDFS 已被S3和GCS等云对象存储所取代。Parquet 仍然存在,尽管它现在被用于Apache Iceberg或Delta Lake。YARN 仍在广泛使用,但Kubernetes及其operators现在占据了控制平面的主导地位。然而,这种架构依然存在。
拆解查询引擎
当前的查询引擎(如 Trino)被构建为一个完全集成的查询引擎,具有解析器、逻辑/物理查询计划、优化器、执行引擎和运行时。工程师们现在正在拆解它们。

来自 velox-lib.io
语言前端解析文本(SQL)并将其转换为中间表示(IR),例如具体语法树(CST)、抽象语法树(AST)或逻辑或物理查询计划。与直接操作文本相比,这些中间表示使代码更容易处理查询。
一旦查询引擎有了中间表示,优化器就会用更优的节点来替换 IR 中的节点。例如,Trino 的优化器可能会认为哈希连接(hash-join)是一种最佳策略。
查询计划优化后,将其交给执行引擎。引擎将计划转换为任务(如 MapReduce 任务)。然后,任务由执行运行时(MapReduce、Flink、Spark 等)执行。
在实际应用中,这些层是模糊的。优化可能发生在其他层,引擎和运行时可能会合并,或者可能一个查询引擎只有一个查询计划或另一个。尽管如此,上面的模型仍然是一个有用的起点。
开发人员现在正在为查询引擎的每一层构建可组合的库。所有集成了这些库的查询引擎都将从相同的优化和特性工作中受益。并且可以快速组装新的数据库来解决新出现的用例;矢量搜索就是最近的一个例子。
现在每一层都有新的开源项目。在前端,SQL 仍然占主导地位(尽管有人讨厌它),但Malloy、PRQL和SaneQL都是值得关注的项目。Substrait的兴起,提供了一种中间表示形式,而CMU-DB的optd项目是一个可组合的优化器。再往下走,Meta已经开源了Velox,这是一个执行引擎,现已集成到Presto和Spark中。运行时层是迄今为止最成熟的,有 Spark 和 Flink 等选项。
然后是 Apache Arrow的DataFusion子项目(即将成为 Apache 的顶级项目)。与上面专注于单层的项目不同,DataFusion 什么都做。你可以将其用作像 Trino 或 DuckDB那样的集成查询引擎,也可以将其用作上面任何一个层的库。这是一个完整的数据库工具包。
twitter.com/andygrove_io/status/1745295329468047461
很多新的数据库都在使用 DataFusion,这并不奇怪;据我所知,它很灵活,而且很容易集成。采用者包括GlareDB、Lance、ROAPI、Cube、InfluxDB以及其他数十家公司。
那么 PostgreSQL 呢?
虽然 Hadoop 在数据仓库中推动了拆解,但 PostgreSQL 也为关系型数据库(RDBMS)和混合事务/分析处理(HTAP)做了同样的事情。其强大的存储层、扩展API、简单的架构和开源的Berkeley开发模型使其成为拆解的必然选择。
PostgreSQL 的附加项目涵盖了从 SQL 扩展到自定义复制和存储方案的所有领域。它的协议和语法也被广泛采用,但对于这次讨论来说,最重要的是它的存储层——它的数据平面。
PostgreSQL 的存储层比 Hadoop 的存储层健壮得多;它包括一个预写日志(WAL)、一个真空进程和事务保证。当构建作为数据真实来源(与数据仓库相反)的生产数据库时,这些功能非常有用。
许多扩展为 PostgreSQL 的存储层添加了自定义格式和索引,这些格式和索引针对矢量搜索、文本搜索、图形查询、地理空间查询、在线分析处理(OLAP)查询等进行了优化。
开发人员对待 PostgreSQL 就像对待 DuckDB 一样——一个带有可插拔存储层的集成查询引擎。不过,与 DuckDB 不同的是,PostgreSQL 的存储层要成熟得多(DuckDB故意不记录其存储格式)。扩展自动继承 PostgreSQL 提供的所有事务性优点。
像Neon这样的项目通过拆分 PostgreSQL 的内部结构,使存储层更进一步。它们修改了PostgreSQL,使 PG 的预写日志(WAL)可插拔。Neon 提供了一个远程实现,该实现使用基于Paxos的带有分层对象存储的WAL。
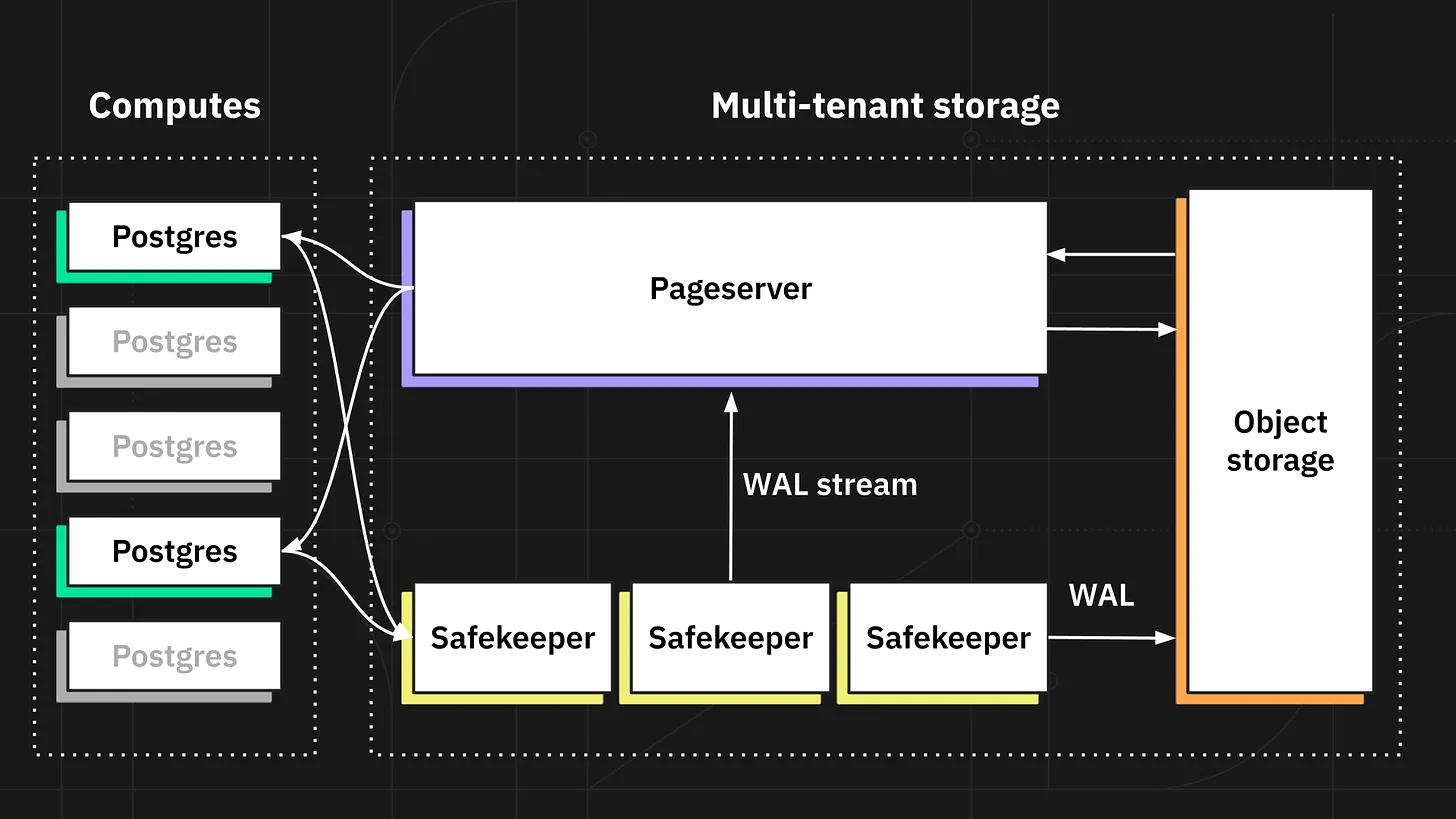
Neon 的架构堪称典范。我相信这是 PG 拆解过程中最重要的部分,并且会产生影响。与查询引擎非常相似,我们将看到提供读和透写缓存、基于共识的WAL和键值存储以及分层对象存储的项目。我并不是唯一一个有这种信念的人。云上的可扩展OLTP问题解决了吗?准确地描述了它的外观。
拆解的影响
拆解将影响整个数据生态系统,从数据仓库到 OLTP、HTAP、多模态数据库,甚至流。
数据仓库将变得越来越无差异和商品化。MotherDuck的首席执行官Jordan Tigani最近写道,仅有Perf是不够的。Jordan 声称,数据库性能将随着时间的推移而趋同;数据库将在特性和开发人员经验方面展开竞争。我相信这种商品化也会发生在功能上。上一节中的项目使性能商品化,但它们也使添加、复制或共享新特性变得更容易。CMU-DB的Meta-Velox演示也反映了这一点:

同时,存储层的新组件将使 OLTP 系统最终实现梦想:低成本、低延迟、高吞吐量、多区域、全事务数据库。当前的 NewSQL 系统只勾选了其中的一个子集。随着分布式WAL+S3架构的商品化(感谢上一节中列出的项目),成本应该会大幅下降。Neon 是我最喜欢的一个例子; TiKV的S3集成是另一个。
最后要解决的问题是将 OLAP 数据仓库和 OLTP 数据库统一为 HTAP 和多模态系统。 随着 OLTP 系统与对象存储的集成,出现了两种新的架构:
OLTP 系统可以将数据持久化为基于行和列的格式。
独立的 OLTP 和 OLAP 系统可以通过对象存储中的松耦合标准进行交互。
这两种架构都使基于行的生产查询和基于列的仓库查询变得既便宜又简单。第一种架构适用于同时为 OLTP 和 OLAP 工作负载提供服务的集成系统。Thomas Neumann等人的HyPer项目就是这一趋势的一个例子。SingleStore 是另一个;《SingleStore中的云原生事务和分析》是一本很好的读物。
第二种架构将针对不同的工作负载提供大量的查询引擎。每个查询引擎都将使用针对其用例优化的存储格式在相同的共享存储上运行。松耦合的系统将依赖于 Parquet、Iceberg 和 Delta Lake 等开放格式来实现集成。
以对象存储为中心的世界对Apache Kafka是一个严重的威胁。Kafka 的主要用例是数据集成——在系统之间移动数据。但是,如果你的所有数据从开始(OLTP)到结束(OLAP、搜索、图等)都存储在对象存储中,那么 Kafka 有什么用呢?流系统将继续适用于亚秒级用例,但这是一个比数据集成更小的市场。
为了继续在数据集成中发挥重要作用,Kafka 应该转变为对象存储的实时摄取系统。这将需要与 Apache Iceberg 和 Delta Lake 等表格格式进行首选集成。KIP-1009通过 Kafka 和 Parquet 的集成暗示了这一点(不过,我相信还有更好的设计)。WarpStream[$]是这个领域的开拓者,Confluent的Kora正朝着这个方向发展,而 Kafka 最终会支持分层对象存储。
到目前为止,我还没有提到SQLite,它是所有数据库中最成功的。SQLite 也正在被拆解,它对边缘数据库产生了重大影响。对象存储、本地存储和缓存实际上只是存储层。开发人员正在使用 SQLite 和无冲突复制数据类型(CRDT)将这种分层扩展到客户端。其他人则从零开始,利用 DataFusion 等库。Fly(通过Litestream和LiteFS)、SQLite Cloud、Turso、SKDB和Ditto只是众多使边缘数据库可行的项目中的一小部分。
所有这些变化都需要时间,但未来看起来是光明的。一个具有专用、低延迟、高吞吐量、多区域、多模态、事务数据库的世界即将到来;这只是时间问题。这是个好消息。
原文链接:





{kind=link}
{kind=link}