
Serverless,全称 Serverless Computing,即无服务器计算,也有一些场景称之为函数即服务(Function-as-a-Service,缩写为 FaaS),是一种新型的云计算模型。
大约 10 年前,Serverless 作为一种未来的软件服务概念被正式提出[1x]。2014 年,AWS 率先用 Lambda 开启了 Serverless 的产品化,再到 2017 年云厂商纷纷布局 Serverless 领域。国内外比较出名的产品包括有 AWS Lambda、Microsoft Azure Functions、Google Cloud Run、Alibaba Function Compute 等。更进一步,Kubernetes 的蓬勃发展也催生了一系列 Serverless Kubernetes 形态的服务,得益于 Kubernetes 的标准化和 Serverless 的弹性和免运维,Serverless Kubernetes 得到了许多用户的垂青。
2019 年,UC Berkeley 研究人员在“Serverless Computing: One Step Forward, Two Steps Back”论文[2]中分析判断道:“Serverless 将引领云计算的下一个十年”。时至 2021 年,Forrester 发布报告[3x]称,统计中 31%主流企业的核心应用,从原来的主机架构迁移到了 Serverless 架构,并且这个规模还在持续高速增长。
经过近 10 年的技术磨砺,Serverless 架构已经凭借着细粒度计算资源分配、无需预先分配资源、真正意义上的高度扩容和弹性等方面的功能优势,给很多基于云计算开发的业务和应用带来了丰富的技术红利,更是被广泛采纳,逐渐在越来越多的业务中发挥重要价值。这项当年概念性的 Serverless 技术,已经“飞入寻常百姓家”,也成为各大云厂商都落地支持的重要服务模式。
高延时,Serverless 的阿喀琉斯之踵
即便如此,Serverless 在带来很多发展新机遇的同时,在主流场景大规模实际落地方面也面临诸多挑战。
同样来自 UC Berkeley 的论文也分析了 Serverless 的局限性,文章称其为“进一退二(One Step Forward, Two Steps Back)”——无限弹性的计算平台愿景下面临着数据访问的掣肘和黑盒性阻碍数据一致性、leader 选举、分布式事务等分布式技术的发展。
One Step Forward:
通过提供自动缩放功能,如今的 Serverless 产品在云编程方面迈出了一大步,它提供了一种看似无限的计算平台。
原文:By providing autoscaling, today’s FaaS offerings take a big step forward for cloud programming, offering a practically manageable, seemingly unlimited compute platform.
Two Steps Back:
但并非一切都已尽善尽美,将 Serverless 大规模推广到一些现有应用中还有些明确的障碍。
首先,Serverless 忽视了高效数据处理的重要性; 其次,它们给分布式系统的开发添加了阻碍。其中第二点不在本文的讨论范围内。
原文:First, they painfully ignore the importance of efficient data processing. Second, they stymie the development of distributed systems.
对于很多数据应用而言,迁移到 Serverless 面临的一大问题就是数据访问的高延时和并发访问造成的分布式存储 IO 瓶颈。归根结底这是由于:
Serverless 是 Data-shipping 架构,其工作机制是将数据传输到代码所在处执行,而不是将代码传输到数据所在处执行,而数据往往比代码的传输量要大得多。同时,目前主流的 Serverless 平台都是『将数据传输到代码所在处执行』这种架构,这就导致数据的传输成为了运行效率的最大瓶颈。
与之相伴的是,每个 Serverless 的计算单元都是运行在独立的容器或者虚拟机当中,而且生命周期短且难以定位,这就限制了多次相同的请求对缓存的使用,会造成比较大的性能损耗。
Serverless 的无限弹性给存储系统造成了巨大访问压力,甚至会触发存储系统访问限流。
比如在机器学习场景下,在初始化的时候加载机器学习模型,而有些模型的大小达到几 GB 甚至几十 GB,根据实测单个实例拉取模型的时间至少 60 秒以上,整个启动时间在 2 分钟左右,如果考虑扩容数量成百上千的场景,严重的 IO 竞争影响了 Serverless 的启动性能。
这就引起了数据科学家的担忧:大数据运算和 AI 负载在 Serverless 上是不是要以牺牲性能为代价换取成本上的收益?当启动速度慢到一定程度的时候,Serverless 所擅长的弹性优势不复存在;如果运行时间太长的话,Serverless 相比于包年包月的虚拟机租赁收费模式成本上孰优孰劣也不能清晰确定。
数据访问的高延时俨然成为了 Serverless 应用的阿喀琉斯之踵,阻碍其在数据密集型应用场景的规模化落地。
与近地缓存理念相结合的 Fluid
Serverless 数据访问延时的问题,本质上是由云上的计算存储分离架构导致的。如果能够将数据以分布式的方式加载到计算集群中,并充分发挥数据本地性和数据访问可复用的特性,则可以提升数据访问的性能。CNCF 旗下开源沙箱项目 Fluid 秉持着这个理念应运而生。
Fluid 是一个开源的 Kubernetes 原生的分布式数据集编排和加速引擎,主要服务于云原生场景下的数据密集型应用,例如大数据应用、AI 应用等。通过 Kubernetes 服务提供的数据层抽象,Fluid 可以让数据像流体一样在诸如 HDFS、OSS、Ceph 等存储源,并在 Kubernetes 上层云原生应用计算之间灵活高效地移动、复制、驱逐、转换和管理。
另外,具体数据操作对用户透明,用户不必再担心访问远端数据的效率、管理数据源的便捷性,以及如何帮助 Kuberntes 做出运维调度决策等问题,只需以最自然的 Kubernetes 原生数据卷方式直接访问抽象出来的数据即可,剩余任务和底层细节全部交给 Fluid 处理。
Fluid 项目当前主要关注数据集和使用应用编排这两个重要场景。数据集编排可以将指定数据集的数据缓存到指定特性的 Kubernetes 节点,而应用编排将使用该数据集的应用调度到可以或已经存储了指定数据集的节点上。这两者还可以组合形成协同编排场景,即协同考虑数据集和应用需求进行节点资源调度。
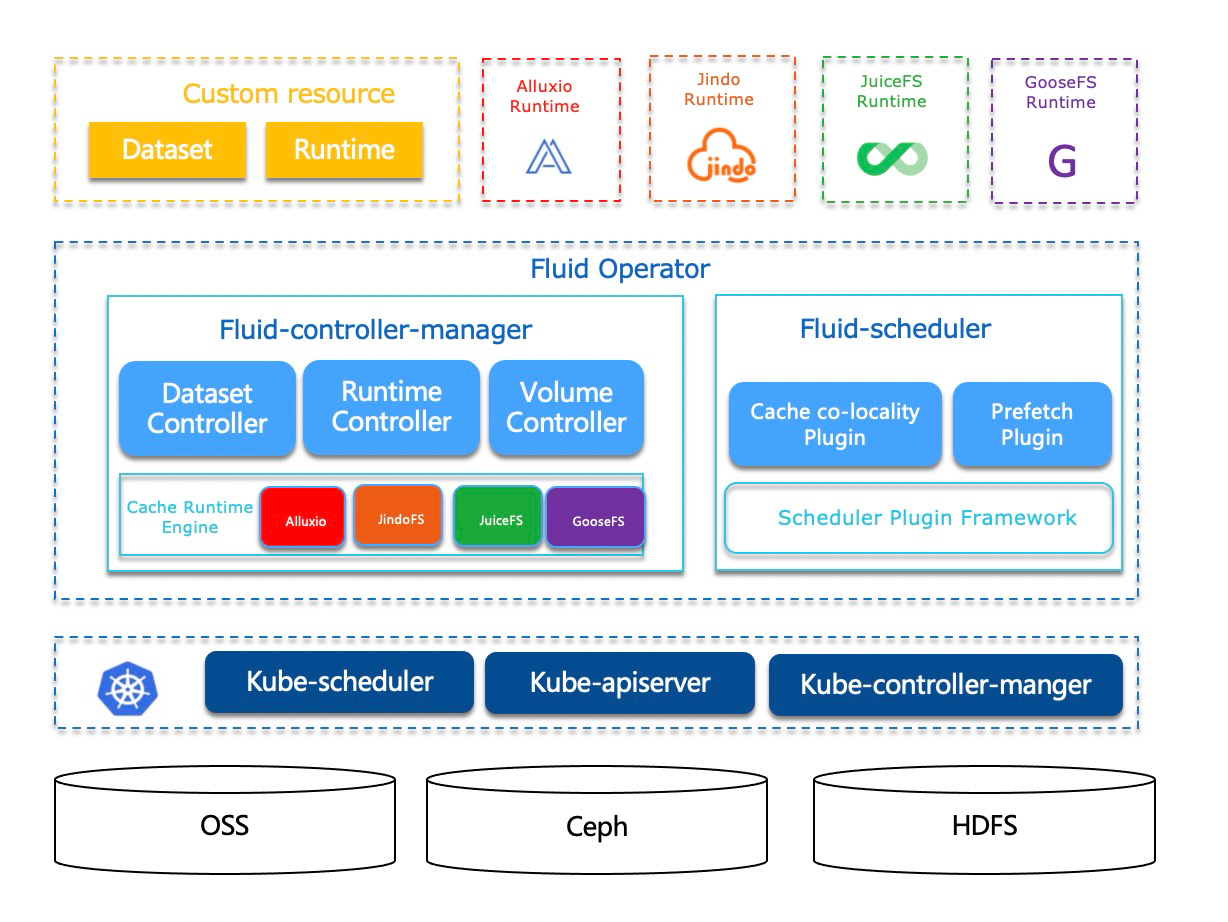
Fluid 设计之初是为了 Serverful 场景使用(Serverful 与 Serverless 相对,意思是应用对所运行的服务器有感知,并且在服务器为中心的前提下实现架构设计),通过计算任务与数据本地性和复用性调度相结合实现数据访问性能最大化。
然而,许多用户在实践中还是选用了缓存和计算节点分离的架构,就是将计算集群中的部分节点专门用作缓存,另外一部分节点用来作为计算。由于缓存节点和计算在同样的网络环境下(VPC),并且分布式缓存可以实现 P2P 的数据访问,这样避免了存储服务限流和网络限流。这种模式被称为近地缓存。它虽然不能和本地缓存的性能相比,但是一方面缩短了计算与存储的物理距离,从漂洋过海变成了同一个数据中心甚至同一个机柜,有效缩减了访问延时,另一方面通过 P2P 的数据传输突破了存储服务器端的网络带宽的限制。
在此基础上,Fluid 支持数据弹性和可操作性,能够根据计算吞吐需求实现:
数据集合的可伸缩性——Fluid 是一套可复制,易扩展的模式,这样才能面对数据集合的伸缩、集群规模的伸缩具备良好的应对能力。
数据集合的可操作性——Fluid 支持通过 Dataload CRD 来进行多种模式的预热,包括指定文件列表、文件夹的元数据进行预热。
因此,如果用户能够了解(有很多自动化的方式做到)自己的数据使用模式和对吞吐性能的需求,就能实现性能提升的有的放矢。通过使用更多节点 SSD 的缓存节点,将数据缓存设置更多的备份,设置分布式缓存访问的随机性,都可以有效地避免热点数据成为访问瓶颈。
面向 Serverless 场景的数据应用支持
Fluid 0.7 之前的版本是不支持 Serverless 的,实际上多数流行的开源软件都不能大规模地部署在 Serverless 平台上,毕竟目前很多开源软件(尤其是数据系统)并不是针对 Serverless 执行环境的而设计的。这背后主要有两个问题:
Serverless 平台是黑盒系统,运行时支持都是由平台提供商开发的,对于 Kubernetes 生态的支持并不完善。比如多数 Serverless 不支持社区广泛支持的 CSI Plugin、Device Plugin 机制等。因此,如何对接 Fluid 就变成了问题。
Serverless 假设执行的是简单的、独立的任务,相互间不通信,同时计算任务完全无状态。 然而,Fluid 本身是要通过分布式缓存系统实现提速的。这里涉及到的分布式(网络通信)和有状态(缓存),又是一个矛盾点。
为了支持 Serverless 场景,Fluid 解决问题的基本思路是对不同的问题分而治之,具体来说:
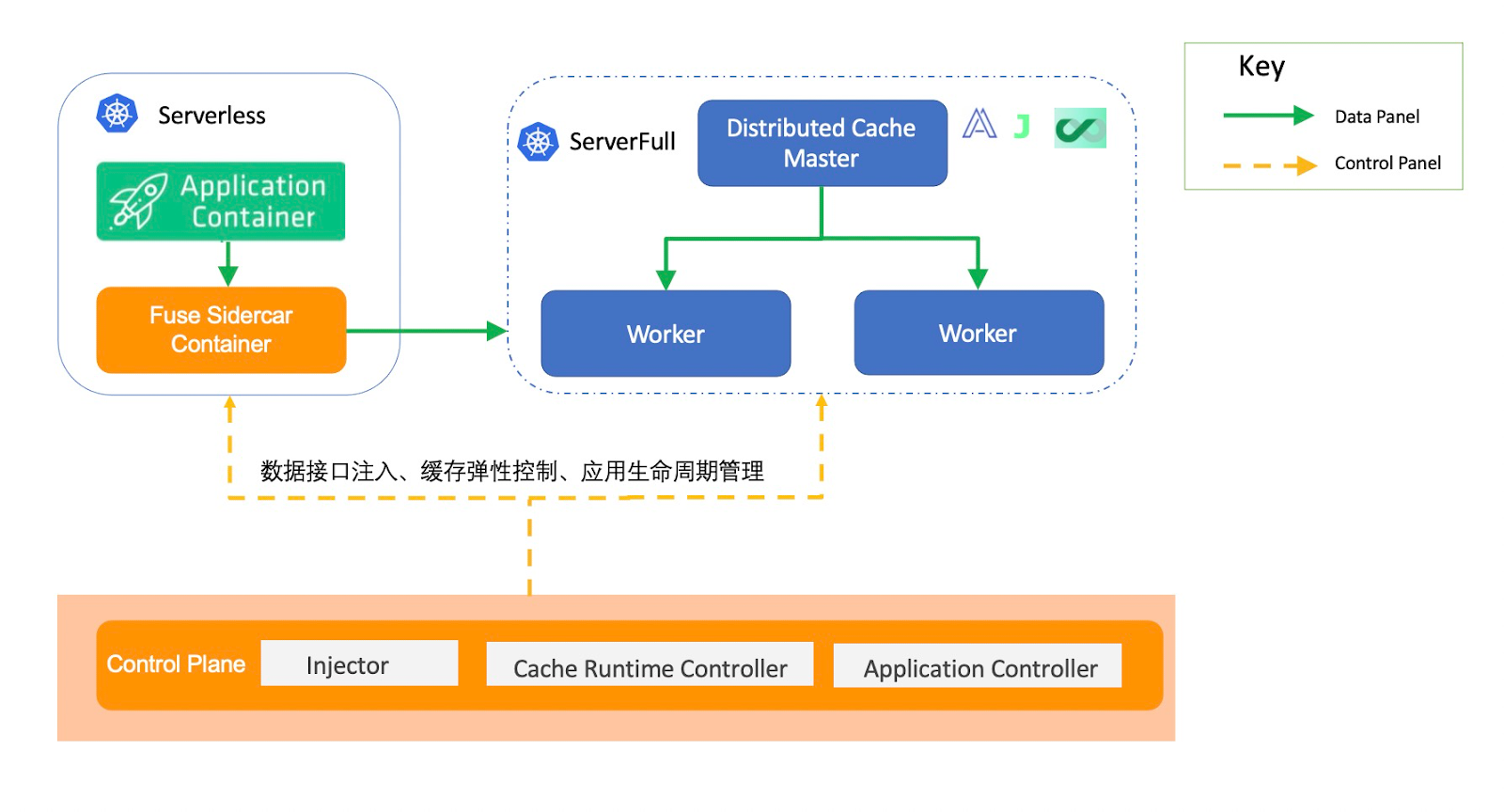
Sidecar 注入实现数据访问对接。自动识别用户提交应用中使用的 Fluid Persistent Volume Claim,并通过 Sidecar 模式将不同缓存 Runtime 的 Fuse 客户端注入到 Serverless Pod 中,并且在确保 Fuse 容器正常启动后再启动应用读取数据。在此基础上,该 Fuse 容器还接管了用户应用的数据读写操作,同时配合 Fluid Controller 的控制平面管理数据访问权限,数据吞吐控制以及数据弹性等功能。
将分布式缓存编排管理委托 ServerFull 组件代理。将单纯的 Serverless Kubernetes 模式变成混合节点模式,一部分是真实的虚拟机节点用来作为数据缓存池,另一部分是由Virtual Kubelet(https://github.com/virtual-kubelet/virtual-kubelet) 负责调度和管理 Serverless Pod。由于 Virtual Kubelet 已经成了云厂商实现 Serverless Kubernetes 的实施标准,比如 AWS Fargate、Azure ACI 和阿里云 ECI 等 Serverless 平台都已经提供完整支持。将数据访问的能力放置在 Serverless 应用中,但是其依赖的数据缓存编排和弹性能力则由 ServerFull 部分提供。
以下为 Fluid 在 Serverless 场景的架构,可以分为数据平面(Data Plane)和控制平面(Control Plane):
数据平面由不同 Runtime 对应的 Fuse container 组成,而 Fuse container 以 sidecar 的形式和应用一起部署。而 sidecar 负责接管应用访问数据的功能。
管理平面分为三部分:
Injector:负责将不同数据访问、runtime 实现信息转换为 sidecar 可以识别的信息,注入到读取数据的应用中,同时控制应用中容器的启动顺序。该应用不限于 Pod,还包括类似 Spark、TFJob、MPIJob 等大数据 AI 场景下常见的工作负载。
Cache Runtime Controller: 结合 Fuse Sidecar 中的数据吞吐效果控制数据缓存弹性,同时管理数据访问权限。
Application Controller:对于类似 BatchJob、TFJob、SparkJob 等任务类型负载,当其中的用户任务退出后,需要 Fuse container 也可以主动退出。
由于 Serverless 的架构也在不断升级换代,相信未来 Serverful 的部分会不断被云厂商以服务化方式提供,从而演变成一个可以弹性并且按需付费的加速服务。
总结
本文介绍了 Fluid 完成了对 Serverless 场景的第一步支持,后续我们会通过一系列的文章介绍其设计方案以及在 Knaitve 等开源 Serverless 平台的实践。
作者简介:
车漾,阿里云高级技术专家
顾荣,南京大学副研究员
Reference:
[1] https://en.wikipedia.org/wiki/Serverless_computing
[2] Joseph M. Hellerstein, Jose Faleiro, Joseph E. Gonzalez, Johann Schleier-Smith, Vikram Sreekanti, Alexey Tumanov and Chenggang Wu. Serverless Computing: One Step Forward, Two Steps Back, CIDR 2019.




