
BERT,全称 Bidirectional Encoder Representation from Transformers,是一款于 2018 年发布,在包括问答和语言理解等多个任务中达到顶尖性能的语言模型。它不仅击败了之前最先进的计算模型,而且在答题方面也有超过人类的表现。招商证券希望借助 BERT 提升自研 NLP 平台的能力,为旗下智能产品家族赋能。
在前一篇蒸馏模型中,招商证券信息技术中心 NLP 开发组已经初步实践了 BERT 模型压缩方法,成功将 12 层 BERT 模型缩减为 3 层。在本次分享中,研发人员们将介绍更简洁的模块替换方法,以及削减参数比特位的量化方法,并将这几种方法有机结合实现了将 BERT 体积压缩至 1/10 的目标。
1. BERT-of-Theseus 模块替换
1.1 概述
BERT-of-Theseus[1]主要通过模块替换的方法进行模型压缩。不同于模型蒸馏方法需要根据模型和任务制定复杂的损失函数以及引入大量额外超参,Theseus 压缩方法显得简洁许多:该方法同样需要一个大模型作为“先驱”,而规模较小的目标模型作为“后辈”(类似蒸馏方法中的教师模型和学生模型),对于“先驱”BERT 模型来说,主体部分是由多个结构相同的 Transformer Encoder 组成,“后辈”模型将“先驱”中的每 N 个 Transformer Encoder 模块替换为 1 个 Transformer Encoder 模块,从而实现模型的压缩。具体实现过程如下:
在 BERT 模型中,第 i 个 Encoder 的输出为:
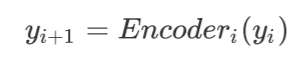
“先驱”和“后辈”中第 i 个模块的输出分别为:
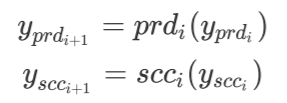
由于“后辈”模型的 1 个 Encoder 模块将会替换 N 个“先驱”Encoder 模块,因此可以将每 N 个“先驱”Encoder 模块分为一个逻辑组,从而与“后辈”模型对应。Theseus 方法就是用“后辈”Encoder 模块替换对应的“先驱”逻辑组,具体的替换的过程比较直观:
首先,设置一个概率 p,通过伯努利分布函数获得模块替换概率:
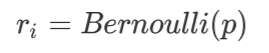
伯努利分布是 0-1 离散分布,替换概率$r_i$有 p 的概率为 1,1-p 的概率为 0。
之后,通过下式获得第 i+1 个模块的输出:
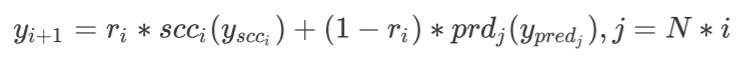
BERT 的其余部分包括 Embedding 及 Pooler 均不做修改,训练时的损失函数与直接使用 BERT 进行微调时完全相同,根据不同的下游任务进行设计选择即可。
1.2 实现
如图 1(a)所示,每个模块的实际输出就是“先驱”或者“后辈”模块输出二选一。
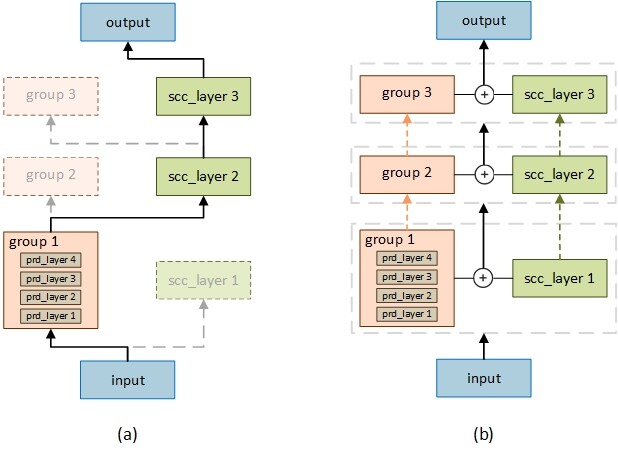
图 1 Theseus 压缩方法训练示意图
在实际实现前向计算的时候,同时运行“先驱”及“后辈”,获得对应模块输出,再进行选择及替换。这种方法比较类似 Layer Dropout[2]的思路,将按层裁减改为模块间的替换,实现也比较类似。在此基础上,我们对这种非 0 即 1 模块选择的过程进行了改进,在保持(4)不变的情况下,修改替换概率$r_i$不再由伯努利分布得到,而通过一个线性函数使之跟随训练步数增长,保证其位于(0,1]区间即可。如图 1(b)所示。
为了实现这个过程,在 Transformer 包以及BERT-of-Theseus官方实现的基础上,我们对BertEncoder进行了改造,实现模块渐进式混合的代码如下:
if self.output_hidden_states: all_hidden_states = all_hidden_states + (hidden_states,)if self.training and self.replacing_rate < 1: prd_hidden_states = hidden_states scc_hidden_states = hidden_states for i in range(self.prd_n_layer): prd_layer_outputs = self.layer[i](prd_hidden_states, attention_mask, head_mask[i], encoder_hidden_states, encoder_attention_mask, True) prd_hidden_states = prd_layer_outputs[0] j, mod = divmod(i, self.compress_ratio) if mod == 0: scc_layer_outputs = self.scc_layer[j](scc_hidden_states, attention_mask, head_mask[i], encoder_hidden_states, encoder_attention_mask, True) scc_hidden_states = scc_layer_outputs[0] mix_hidden_states = ( 1 - self.replacing_rate) * prd_hidden_states + self.replacing_rate * scc_hidden_states prd_hidden_states = mix_hidden_states scc_hidden_states = mix_hidden_states if self.output_attentions: all_attentions = all_attentions + \ (scc_layer_outputs[1],) if self.output_hidden_states: all_hidden_states = all_hidden_states + \ (mix_hidden_states,) outputs = (mix_hidden_states,)# eval or replacing_rate == 1else: for i in range(self.scc_n_layer): layer_outputs = self.scc_layer[i](hidden_states, attention_mask, head_mask[i], encoder_hidden_states, encoder_attention_mask, True) hidden_states = layer_outputs[0] if self.output_attentions: all_attentions = all_attentions + (layer_outputs[1],) if self.output_hidden_states: all_hidden_states = all_hidden_states + (hidden_states,) outputs = (hidden_stat获得替换概率的方法同样非常直观,如图 2 所示,替换概率曲线与训练步数呈线性关系。
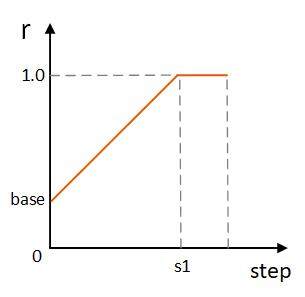
图 2 线性替换概率曲线
在代码实现上,只需要引入一个额外的超参base_replacing_rate,使用上述修改后的BertEncoder初始化后,每训练一步调用该 step()方法即可完成替换概率更新。
class LinearReplacementScheduler: def __init__(self, bert_encoder: BertEncoder, num_training_steps, base_replacing_rate=0.1): self.bert_encoder = bert_encoder self.base_replacing_rate = base_replacing_rate self.step_counter = 0 self.num_training_steps = num_training_steps self.bert_encoder.set_replacing_rate(base_replacing_rate) def reset_step(self): self.step_counter = 0 def step(self): self.step_counter += 1 current_replacing_rate = min( self.step_counter / self.num_training_steps + self.base_replacing_rate, 1.0) self.bert_encoder.set_replacing_rate(current_replacing_rate) return current_replacing_rat在训练过程中,"先驱"的所有层以及“后辈”的除 Encoder 以外的其余层都被冻结不进行参数更新,当达到图 2 中训练阶段 s1 后,模型全部由“后辈”模块组成,意味着此时 Theseus 压缩方法已经完成,继续训练剩下的 step 即可获得我们需要的压缩模型。
1.3 实验结果
我们同样在 clue 数据集上进行了准确率测试,使用 Theseus 压缩得到的模型结构与参数量与前文描述的蒸馏压缩模型以及直接进行预训练的 3 层模型相同。我们对这 3 个模型进行了横向对比,结果如下:
可以看到,经过多次训练后,Theseus 压缩模型在文本分类任务上(tnews、iflytek)达到了蒸馏模型和预训练小模型相当的性能,但是在其余任务上与其余两个模型差距较大,并没有达到预期的效果。总的来看,Theseus 压缩方法相对前文所述的压缩方法更加简洁、直观,压缩过程中也不需要设计额外的结构和损失函数,仅需要 1-2 个额外的超参即可完成训练。在工程实践中,我们针对不同任务分别选择了不同的模型压缩方法:句对相似以及问答类的任务使用蒸馏方法进行压缩,同时分类任务使用 Theseus 方法压缩。
2. 模型量化
2.1 概述
与其他模型压缩方法不同的是,模型量化方法并不试图缩减或改变模型本身结构和规模,而是通过降低模型中参数精度,将模型原本的浮点运算转换为定点的方法对模型进行压缩,从而降低模型体积,提高推断速度。因此模型量化是更偏向工程实践的方法。目前工业界中比较稳定的是 INT8 模型量化技术,即将原本的模型参数类型由 FP32 转为 INT8 格式,这样可以将模型的大小变为原来的 1/4,如果硬件支持[注 1] INT8 加速计算,推理速度通常快 2 到 4 倍。本文涉及的量化格式均为从 FP32 到 INT8。
[注 1]: 根据 intel 研究结果 [3-4],在支持 VNNI 指令集的 Intel Cascade Lake CPU 上,单仅矩阵乘法一项,INT8 格式就能提速 3.7 倍,然而我们现在使用的是上一代 Skylake CPU,没法直接“简单粗暴”地获得如此明显的提速效果。
对于量化的目标对象,主要是以下两个:
weight:权重 weight 是模型中最主要的参数,量化 weight 能够显著减少模型本身规模以及计算复杂度。
activation:激活层输出 activation 在计算过程中同样有较大计算量,量化操作后能够大幅减少内存占用并提高计算速度。
模型量化具体方法可以分为 Dynamic Quantization、Post-Training Static Quantization 方法和 Quantization Aware Training 三类[5]:
Dynamic Quantization: 先按常规方式训练好一个 FP32 格式的模型,之后进行量化操作:首先将 weight 量化为 INT8,之后 activation 在前向计算过程中被动态量化,因此可以使用高效地 INT8 矩阵乘法执行对应层的计算(在 BERT 中主要为 Linear 层),从而加快计算速度。与此同时,activation 仍以 FP32 格式读取和写入内存,每次都要根据实际运算中的浮点数据范围为每一层计算一次量化参数。
Post-Training Static Quantization:该方法同样是在训练完毕的模型中进行量化操作,其中 weight 与 Dynamic Quantization 类似同样先被量化好,而 activation 通过计算数据的不同分布直接进行量化,之后均为 INT8 格式参与计算。相对第一种方法速度会有所提升。
Quantization Aware Training:该方法通过是在训练过程中进行量化操作。在训练过程中,weight 和 activation 都被“伪量化”为 INT8,但是计算实际仍以 FP32 完成。通过这种方法使模型在训练过程中能够“感知”到量化的影响,同时避免直接使用 INT8 训练导致的无法收敛的情况。
其中 Dynamic Quantization 实现最简单,在 pytorch 环境下,核心代码只需在模型训练完毕后增加一行即可:
quantized_model = torch.quantization.quantize_dynamic( model, {torch.nn.Linear}, dtype=torch.qint8)代表着对所有 Linear 全连接层进行 INT8 量化,在 BERT 模型中,除了 Embedding 层,自注意力、中间层计算以及输出层等主要结构的底层实现均为全连接层。在 Pytorch 的官方实现[6]中,对比了进行量化前后的模型规模,模型整体除 Embedding 层以外的大小缩减为原有 1/4,符合 FP32 量化到 INT8 带来的模型缩减水平。在模型性能及推断速度方面,量化后模型在基本不损失模型性能条件下,推断速度产生了约 80%的提升。该例子中,使用的是 MRPC 英文文本分类任务,而我们通过使用中文 BERT 模型及在对应的中文分类任务上无法复现该结果,进行 Dynamic Quantization 量化后准确率下降明显,无法直接作为线上模型使用。
2.2 QAT 量化
而 Quantization Aware Training(QAT)方法将量化操作融入了训练过程,一般能够获得上述 3 种量化方法中最高精度。与 Q8BERT[3]相同,我们使用了对称线性量化方法:
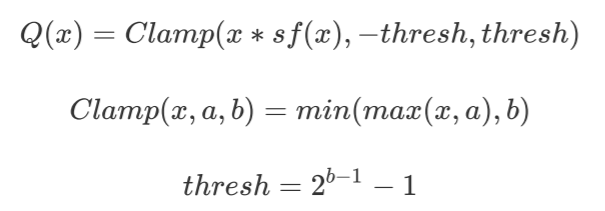
通过一个 scale_factor(sf)函数将原始 FP32 值 x 转换为 INT8 数值。其中 thresh 为 b 位量化时可取的最大值,即 INT8 量化 b=8,thresh=127。使用 Clamp 函数保证结果值域在[-thresh, thresh]之间,避免数值溢出。实现代码如下:
def quantize(input, scale, bits): thresh = 2 ** (bits - 1) - 1 return input.mul(scale).round().clamp(-thresh, thresh)为了最大程度保留原信息,scale_factor 的取值通过使用 M 及指数滑动平均(EMA)值计算获得:
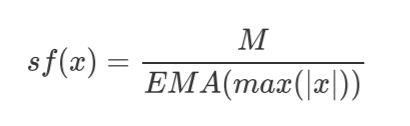
其中 EMA 值在训练过程中的每步前向计算中更新:
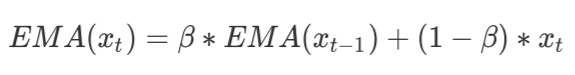
其中$\beta$是衰减率,用于控制更新速率,默认取值为 0.9999,确保值的平滑改变。
def update_ema(ema, beta, input): ema.sub_((1 - beta) * (ema - input.abs().max()))在实际实践中,在训练阶段的前向和反向传播中,所有操作均为“伪量化”[7],直接使用公式(5)进行量化后的值变得离散,会导致无法正常计算该函数的梯度。因此在训练阶段前向传播过程中,在进行量化后紧接着进行一次反量化操作,将输出重新转为 FP32,而在反向传播过程中,不计算梯度,将后一层梯度直接向前传播即可,即为 Straight-Through Estimator(STE)方法。因此,实际训练过程中使用 FP32 模拟 INT8 进行计算;而在推理阶段,被量化的层和参数被转换为 INT8 加速计算。
class STEFakeQuantize(Function): @staticmethod def forward(ctx, input, scale, bits=8): x = quantize(input, scale, bits) return dequantize(x, scale) @staticmethod def backward(ctx, grad_output): return grad_output, None, None与 Dynamic Quantization 量化方法不同,分别在 Linear 层和 Embedding 层应用 QAT 量化方法得到 QuantizedLinear 层和 QuantizedLinear 层。在原有基础上增加weight_fake_quant属性,在训练时使用STEFakeQuantize.apply进行前向"伪量化"计算和反向梯度传播;在推断时直接进行量化计算即可。并以此为基础重写实现 Bert 所需的各个模块,以 BertSelfAttention 模块为例:
class QuantizedBertSelfAttention(BertSelfAttention): def __init__(self, config): super(BertSelfAttention, self).__init__() if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"): raise ValueError( "The hidden size (%d) is not a multiple of the number of attention " "heads (%d)" % (config.hidden_size, config.num_attention_heads) ) self.num_attention_heads = config.num_attention_heads self.attention_head_size = int(config.hidden_size / config.num_attention_heads) self.all_head_size = self.num_attention_heads * self.attention_head_size self.query = QuantizedLinear.from_config(config, "query", config.hidden_size, self.all_head_size) self.key = QuantizedLinear.from_config(config, "key", config.hidden_size, self.all_head_size) self.value = QuantizedLinear.from_config(config, "value", config.hidden_size, self.all_head_size) self.dropout = nn.Dropout(config.attention_probs_dropout_prob)相对原本代码只是将query、key、value从基本的 Linear 层转变为 QuantizedLinear 层,其余模块也进行类似改动即可。
2.3 结果
至此,我们介绍并实践了 3 种 BERT 模型压缩方法:蒸馏、Theseus 替换和量化方法。蒸馏和 Theseus 替换的目的都是压缩模型本身规模,可以认为是同一类方法;而量化方法则是通过降低模型参数精度的方法压缩模型,是另一类方法。这两类方法互不冲突,如果同时作用在 BERT 模型上想必可以实现”1+1>1“的效果。因此我们提出了 BERT 两步压缩方法:以 12 层标准 Roberta 模型为基础,在不同任务上分别使用蒸馏方法、Theseus 替换方法进行第一步压缩,将 BERT 压缩至 3 层;在此基础上叠加 QAT 量化,使参数精度从 FP32 降低至 INT8,完成第二步压缩。
在实践过程中,我们将压缩模型按任务分为两类:对于(长、短文本)分类任务,我们使用了 3 层 Theseus 模型+QAT 方法进行压缩,对于其他(文本相似度、因果推断等)任务,我们使用了 3 层蒸馏+QAT 方法进行压缩,最终结果如下:
可以看出,经过了两步压缩后模型精度下降了 2-3 个点,而 QAT 方法本身对模型性能影响较小,使用 QAT 方法进行量化后,反而在文本分类任务中有所上升,说明量化方法在较简单任务上能够一定程度缓解模型过拟合。并且经过了两步压缩后,模型规模显著降低(392M->37M),推断速度也获得了较明显提升(4x 以上),而在硬件支持的条件下,推断速度预计能够获得更大幅度的提高。
作者简介
招商证券信息技术中心 NLP 开发组,专注于自然语言处理和人工智能技术在金融科技领域的研究、设计、开发与应用落地。目前已孵化出智能搜索、智能推荐、智能助手、智能选股等多项产品,并采用平台化策略服务公司内外各项智能化需求。
参考文献:
[1] C. Xu, W. Zhou, T. Ge, et al. BERT-of-Theseus: Compressing BERT by Progressive Module Replacing[J]. arXiv preprint arXiv:2002.02925,2020
[2] A. Fan, E. Grave and A. Joulin. Reducing Transformer Depth on Demand with Structured Dropout[J]. arXiv preprint arXiv:1909.11556,2019
[3] O. Zafrir, G. Boudoukh, P. Izsak, et al. Q8BERT: Quantized 8Bit BERT[J]. arXiv preprint arXiv:1910.06188,2019
[4] A. Bhandare, V. Sripathi, D. Karkada, et al. Efficient 8-Bit Quantization of Transformer Neural Machine Language Translation Model[J]. arXiv preprint arXiv:1906.00532,2019
[5] https://pytorch.org/blog/introduction-to-quantization-on-pytorch/
[6] https://pytorch.org/tutorials/intermediate/dynamic_quantization_bert_tutorial.html
[7] B. Jacob, S. Kligys, B. Chen, et al. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference[J]. 2018




