
数据导入吞吐是 OLAP 系统性能的重要衡量标准之一,高效的数据导入能力能够加速数据实时处理和分析的效率。随着 Apache Doris 用户规模的不断扩大, 越来越多用户对数据导入提出更高的要求,这也为 Apache Doris 的数据导入能力带来了更大的挑战。
为提供快速的数据写入支持,Apache Doris 存储引擎采用了类似 LSM Tree 结构。在进行数据导入时,数据会先写入 Tablet 对应的 MemTable 中,MemTable 采用 SkipList 的数据结构。当 MemTable 写满之后,会将其中的数据刷写(Flush)到磁盘。数据从 MemTable 刷写到磁盘的过程分为两个阶段,第一阶段是将 MemTable 中的行存结构在内存中转换为列存结构,并为每一列生成对应的索引结构;第二阶段是将转换后的列存结构写入磁盘,生成 Segment 文件。
具体而言,Apache Doris 在导入流程中会把 BE 模块分为上游和下游,其中上游 BE 对数据的处理分为 Scan 和 Sink 两个步骤:首先 Scan 过程对原始数据进行解析,然后 Sink 过程将数据组织并通过 RPC 分发给下游 BE。当下游 BE 接收数据后,首先在内存结构 MemTable 中进行数据攒批,对数据排序、聚合,并最终下刷成数据文件(也称 Segment 文件)到硬盘上来进行持久化存储。
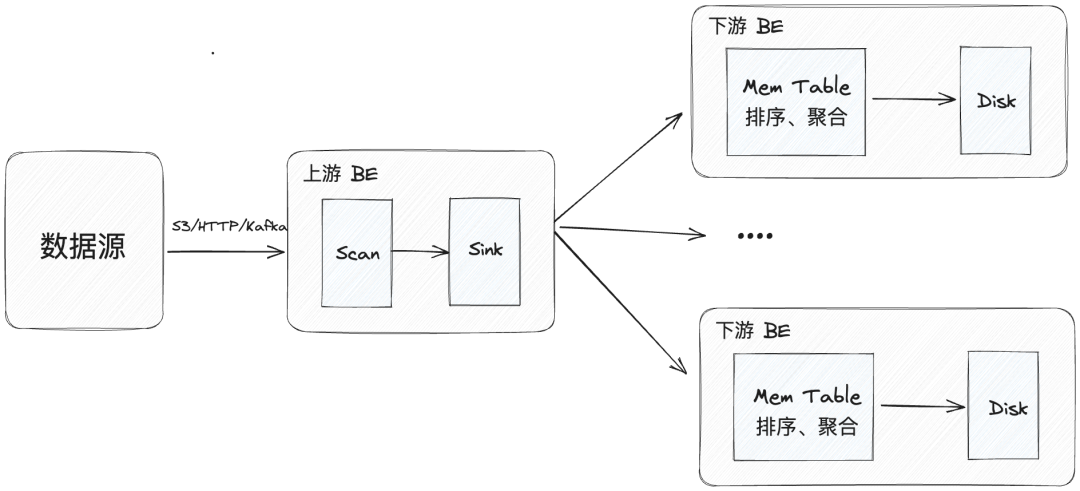
而我们在实际的数据导入过程中,可能会出现以下问题:
因上游 BE 跟下游 BE 之间的 RPC 采用 Ping-Pong 的模式,即下游 BE 一个请求处理完成并回复到上游 BE 后,上游 BE 才会发送下一个请求。如果下游 BE 在 MemTable 的处理过程中消耗了较长的时间,那么上游 BE 将会等待 RPC 返回的时间也会变长,这就会影响到数据传输的效率。
当对多副本的表导入数据时,需要在每个副本上重复执行 MemTable 的处理过程。然而,这种方式使每个副本所在节点都会消耗一定的内存和 CPU 资源,不仅如此,冗长的处理流程也会影响执行效率。
为解决以上问题,我们在刚刚发布不久 Apache Doris 2.0 版本中(https://github.com/apache/doris/tree/2.0.1-rc04 ),对导入过程中 MemTable 的攒批、排序和落盘等流程进行优化,提高了上下游之间数据传输的效率。此外我们在新版本中还提供 “单副本导入” 的数据分发模式,当面对多副本数据导入时,无需在多个 BE 上重复进行 MemTable 工作,有效提升集群计算和内存资源的利用率,进而提升导入的总吞吐量。
MemTable 优化
01 写入优化
在 Aapche Doris 过去版本中,下游 BE 在写入 MemTable 时,为了维护 Key 的顺序,会实时对 SkipList 进行更新。对于 Unique Key 表或者 Aggregate Key 表来说,遇到已经存在的 Key 时,将会调用聚合函数并进行合并。然而这两个步骤可能会消耗较多的处理时间,从而延迟 RPC 响应时间,影响数据写入的效率。
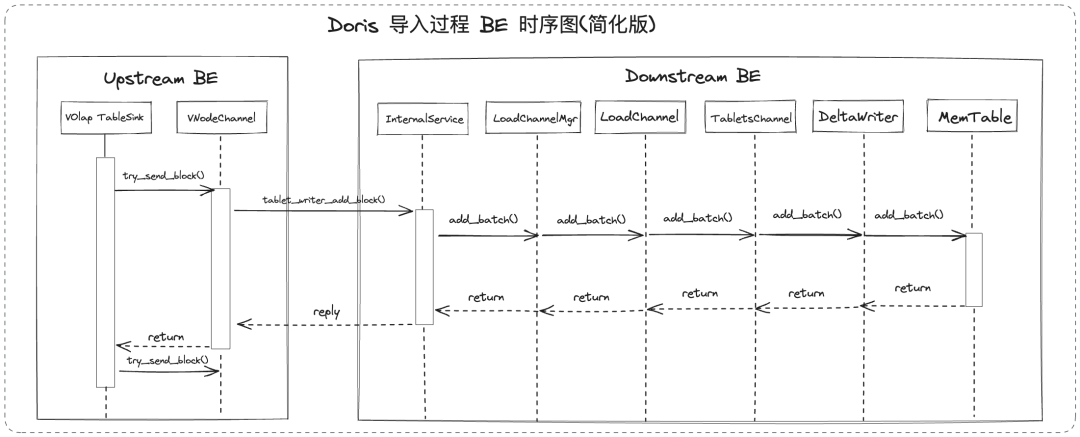
因此我们在 2.0 版本中对这一过程进行了优化。当下游 BE 在写入 MemTable 时,不再实时维护 MemTable 中 Key 的顺序,而是将顺序的保证推迟到 MemTable 即将被下刷成 Segment 之前。此外,我们采用更高效的 pdqsort 来替代 std::sort ,实现了缓存友好的列优先排序方式,并取得了更好的排序性能。通过上述两种手段来保证 RPC 能够被及时响应。
02 并行下刷
在导入过程中,当下游 BE 将一个 MemTable 写入一定大小之后,会把 MemTable 下刷为 Segment 数据文件来持久化存储数据并释放内存。为了保证前文提到的 Ping-Pong RPC 性能不受影响,MemTable 的下刷操作会被提交到一个线程池中进行异步执行。
在 Apache Doris 过去版本中,对于 Unique Key 的表来说,MemTable 下刷任务是串行执行的,原因是不同 Segment 文件之间可能存在重复 Key,串行执行可以保持它们的先后顺序,而 Segment 序号是在下刷任务被调度执行时分配的。同时,在 Tablet 数量较少无法提供足够的并发时,串行下刷可能会导致系统的 IO 资源无法重复被利用。而在 Apache Doris 2.0 版本中,由于我们将 Key 的排序和聚合操作进行了后置,除了原有的 IO 负载以外,下刷任务中还增加了 CPU 负载(即后置的排序和聚合操作)。此时若仍使用串行下刷的方式,当没有足够多 Tablet 来保证并发数时,CPU 和 IO 会交替成为瓶颈,从而导致下刷任务的吞吐量大幅降低。
为解决这个问题,我们在下刷任务提交时就为其分配 Segment 序号,确保并行下刷后生成的 Segment 文件顺序是正确的。同时,我们还对后续 Rowset 构建流程进行了优化,使其可以处理不连续的 Segment 序号。通过以上改进,使得所有类型的表都可以并行下刷 MemTable,从而提高整体资源利用率和导入吞吐量。
03 优化效果
通过对 MemTable 的优化,面对不同的导入场景,Stream Load 的吞吐量均有不同幅度的提升(详细对比数据可见下文)。这项优化不仅适用于 Stream Load ,还对 Apache Doris 支持的其他导入方式同样有效,例如 Insert Into、Broker Load、S3 Load 等,均在不同程度提升了导入的效率及性能。
单副本导入
01 原理和实现
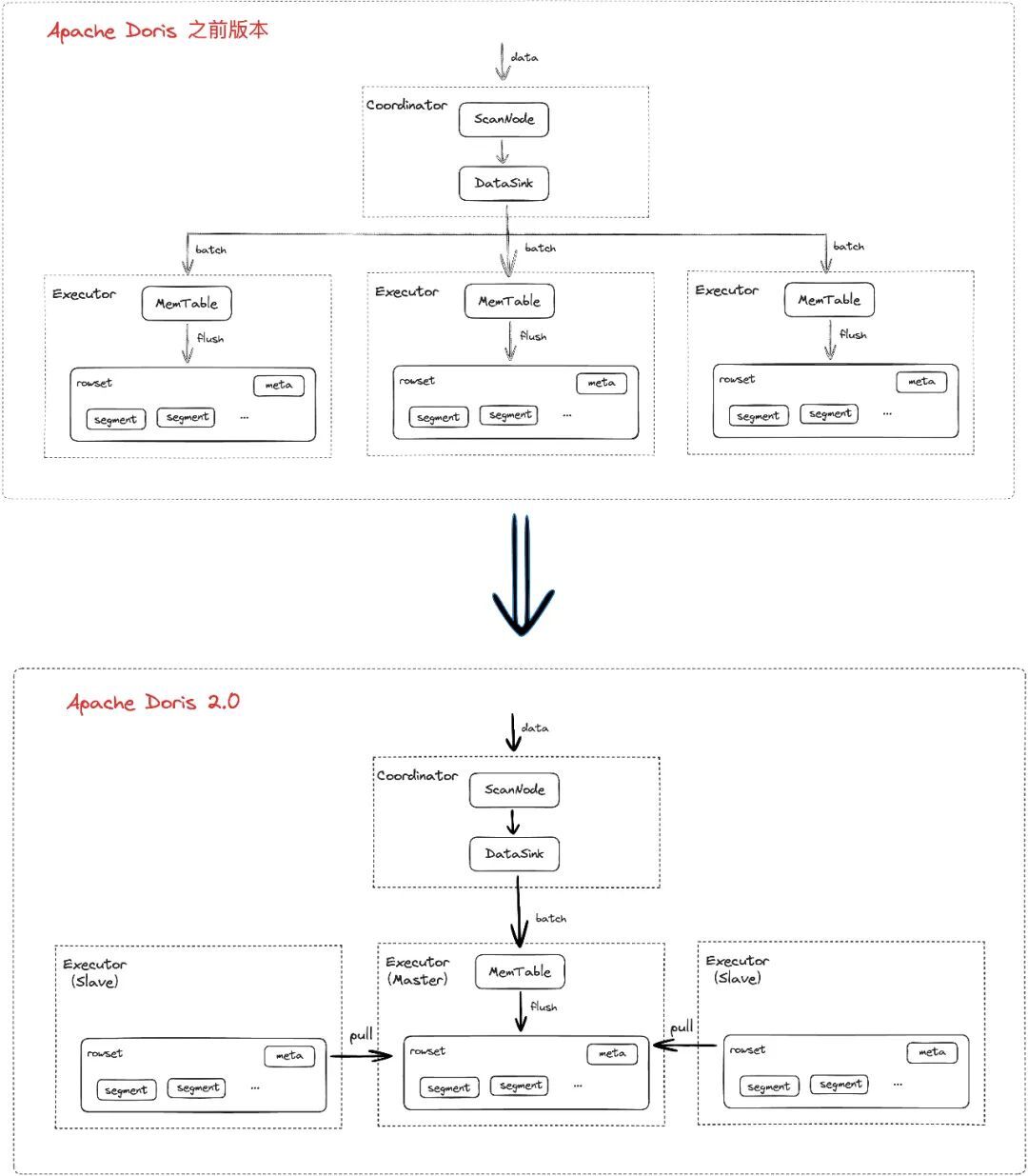
在过去版本中,当面对多副本数据写入时,Apache Doris 的每个数据副本均需要在各自节点上进行排序和压缩,这样会造成较大的资源占用。为了节约 CPU 和内存资源,我们在 Apache Doris 在 2.0 版本中提供了单副本导入的能力,该能力会从多个副本中选择一个副本作为主副本(其他副本为从副本),且只对主副本进行计算,当主副本的数据文件都写入成功后,通知从副本所在节点直接接拉取主副本的数据文件,实现副本间的数据同步,当所有从副本节点拉取完后进行返回或超时返回(大多数副本成功即返回成功)。该能力无需一一在节点上进行处理,减少了节点的压力,而节约的算力和内存将会用于其它任务的处理,从而提升整体系统的并发吞吐能力。
02 如何开启
FE 配置:
enable_single_replica_load = trueBE 配置:
enable_single_replica_load = true环境变量(insert into)
SET experimental_enable_single_replica_insert=true;03 优化效果
对于单并发导入来说,单副本数据导入可以有效降低资源消耗。单副本导入所占的内存仅为三副本导入的 1/3(单副本导入时只需要写一份内存,三副本导入时需要写三份内存)。同时从实际测试可知,单副本导入的 CPU 消耗约为三副本导入的 1/2,可有效节约 CPU 资源。
对于多并发导入来说,在相同的资源消耗下,单副本导入可以显著增加任务吞吐。同时在实际测试中,同样的并发导入任务, 三副本导入方式耗时 67 分钟,而单副本导入方式仅耗时 27 分钟,导入效率提升约 2.5 倍。具体数据请参考后文。
性能对比
测试环境及配置:
3 个 BE (16C 64G),每个 BE 配置 3 块盘 (单盘读写约 150 MB/s)
1 个 FE,共享其中一个 BE 的机器
原始数据使用 TPC-H SF100 生成的 Lineitem 表,存储在 FE 所在机器的一个独立的盘上(读约 150 MB/s)。
01 Stream Load(单并发)
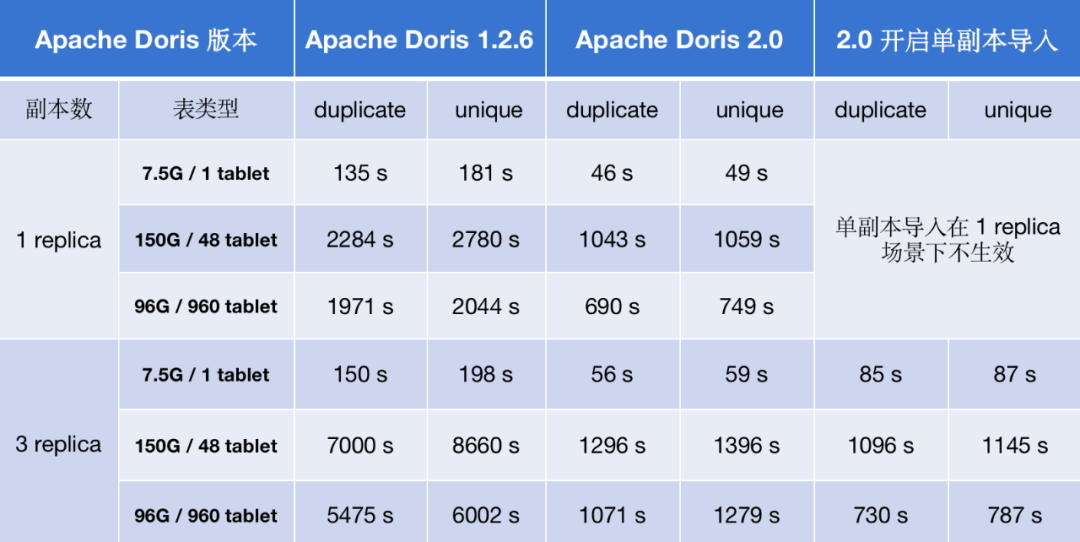
以上述列举的单并发场景来说,Apache Doris 2.0 版本整体的导入性能比 1.2.6 版本提升了 2-7 倍;在多副本前提下,开启新特性单副本导入,导入性能提升了 2-8 倍。
02 INSERT INTO (多并发)
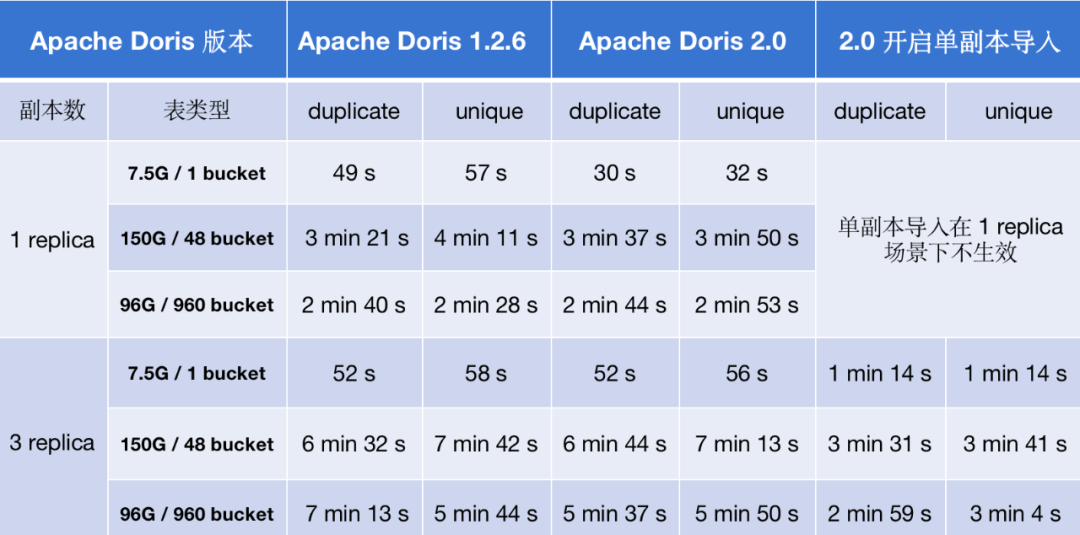
以上述列举的多并发场景来说,Apache Doris 2.0 版本整体比 1.2.6 版本有小幅提升;开启新特性单副本导入后,对在多副本提导入性能提升效果明显,导入速度较 1.2.6 版提升约 50% 。
结束语
社区一直致力于提升 Apache Doris 导入性能这一核心能力,为用户提供更佳的高效分析体验,通过在 2.0 版本对 Memtable、单副本导入等能力进行优化,导入性能相较于之前版本已经呈现数倍提升。未来我们还将在 2.1 版本中持续迭代,结合 MemTable 的优化方法、单副本优化资源能效理念,以及基于 Streaming RPC 优化后的 IO 模型和精简的 IO 路径对导入性能进一步优化,同时减少导入对查询性能的影响,为用户提供更加卓越的数据导入体验。
# 作者介绍:
陈凯杰,SelectDB 高级研发工程师
张正宇,SelectDB 资深研发工程师




