
本文最初发布于 Yandex。
大家好,我叫 Maxim Babenko,是 Yandex 分布式计算技术部的负责人。今天,我们很高兴地宣布,YTsaurus平台开源发布。YTsaurus 是 Yandex 开发的关键基础设施类大数据系统之一,之前我们称之为 YT。
YTsaurus 是我们近十年努力的成果,我们希望把它与全世界分享。在这篇文章中,我们将介绍 YT 的发展历史、我们开发它的动机、它的主要功能以及最适合的领域。
GitHub存储库中包含 YTsaurus 的服务器代码、使用 K8s 的部署基础设施、系统的 Web 界面,以及 C++、Java、Go 和 Python 等流行编程语言的客户端 SDK。所有内容都遵循 Apache 2.0 许可,也就是说,任何人都可以下载并根据自己的需要修改它。
YT 是如何成为 Yandex 最重要的大数据系统的
故事要从 2006 年说起。那时,Yandex 已经是一家相当大的公司。在哪里存储以及如何处理公司的数据成了不小的难题。当时,我们的关注点是来自多个服务的日志。日志处理涉及各种分析,可以解决从改进机器学习模型到分析用户行为(在服务功能或界面变化时)的各种任务。
可扩展弹性数据存储系统的理念已经开始流行。它可以执行并行计算,而且无需担心数据的物理位置和集群物理组件的容错能力。
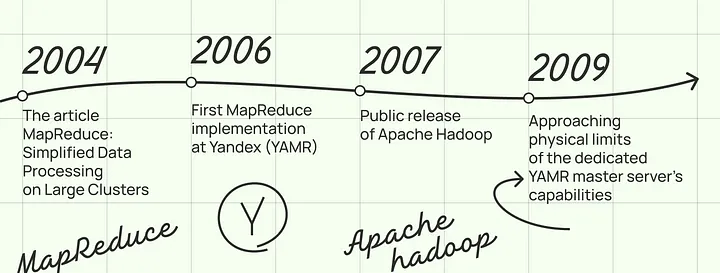
2004 年,来自谷歌的 Jeffrey Dean 和 Sanjay Ghemawat 发布了MapReduce:简化大型集群上的数据处理。在很大程度上,它预测了分布式计算行业未来十年的发展。毫不奇怪,Yandex 开发了类似 MapReduce 模型的实现,我们称之为 YAMR,即 Yet Another MapReduce。
我们以破纪录的速度从零开始构建了 YAMR。无疑,这对公司内部基础设施的发展产生了巨大的影响。然而,随着时间的推移,事情变得越来越明显,YAMR 中许多最初的设计选择使得系统无法有效地演进和扩展。例如,YAMR 主服务器是单一故障点,无法扩展。

乍一看,自己构建基础设施的决定似乎是 NIH 综合症的一个典型案例,我们甚至没有考虑过使用像 Apache Hadoop 这样的开箱即用的解决方案。但也不完全是这样。2015 年 9 月,Yandex 的一队工程师前往加州,与一些在生产环境中使用 Hadoop 技术栈的人会面,询问他们关于限制因素、操作特性以及 Hadoop 将如何发展的问题。
但那时,Hadoop 技术栈已明显落后于 YAMR,我们已经支持纠删码(erasure coding)和 IPv6 连接。问题还不止这些。
经过全方位的分析之后,我们决定放弃使用 Hadoop 的想法。与此同时,我们必须在 YAMR 的渐进式开发和革命性重写之间做出选择,最终,我们选择了后者。在这之前的五年时间里,我有幸成为一小群狂热爱好者中的一员,开始了一个代号为 YT 的项目。只需适当的改进,YT 就完全有可能取代 YAMR。
重要的是要明白,替代 YAMR 并不简单。在高峰期,该系统管理的集群总计有数千个节点,有大量应用程序的代码是基于 YAMR API 的。因此,改进 YT 和从 YAMR 迁移花费了我们许多年的时间。这个故事本身有许多很有趣的细节,或许值得单独写一篇文章。

自 2017 年以来,Yandex 就只有一个 MapReduce 系统,在规模和功能方面的开发一直持续到今天。如今,我们公司运营着数个 YT 集群,规模从几台机器到几万台服务器不等。最大的安装存储着艾字节的数据,使用了几百万核 CPU 内核和几千个 GPU 卡,夜以继日地进行着计算。

YTsaurus:名字起源
“YT 会开源吗?”,我们花了将近 7 年的时间来回答这个问题。我们的答案是:YT 不会开源,但 YTsaurus 会!
我们最初开发的系统叫“YT”。代码库的许多部分中都有这个缩写。Yandex 内部流传着一个说法,“YT”这个缩写代表了“Yandex Table”,可能是受到谷歌著名的 Big Table 系统的启发,但我们并没有找到任何可靠的证据可以支持这个推测。
当决定以开源的方式发布这个系统时,我们发现很难保留原来的名称。其中一个原因是,这个两个字母的组合通常与某个流行的视频托管平台有关。
最终,我们选定了“YTsaurus”这个名字。它有着同样可爱而熟悉的“YT”前缀,我们团队一直把这个项目看成一个有生命的东西。现在,我们终于知道它是什么种族了!
在我们的代码库和文章中,我们经常将“YTsaurus”缩写为“YT”。我们自己也还在适应全名的过程中。
系统功能
我们设计的系统既灵活又可扩展。目前,它的功能并不局限于经典的 MapReduce 技术。在本节中,我将描述 YTsaurus 开源版本提供的主要技术能力,从底层存储到高级计算原语。
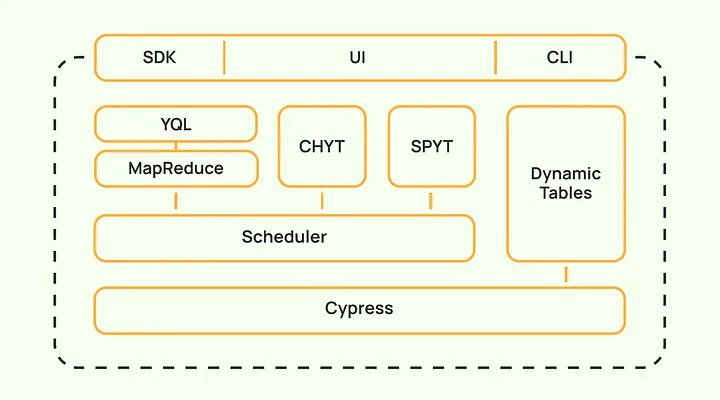
Cypress:可靠高效的数据存储
任何大数据系统的核心都是各种日志、统计数据、索引以及其他结构化或非结构化数据的存储。YTsaurus 以 Cypress 为基础构建。Cypress 是一种基于树的具有容错能力的存储,其功能可以简单描述如下:
以目录、表(结构化或半结构化数据)和文件(非结构化数据)为节点的树状命名空间
透明地将大型表格式数据分片为块,我们可以将表视为单个实体,而无需过多考虑物理存储的细节
支持表格式数据基于行和列的存储机制
支持使用不同压缩级别的各种编解码器(如 lz4 和 zstd)压缩存储
支持使用具有不同控制和计算策略的各种纠删编解码器进行纠删编码,而这些策略具有不同的冗余参数和允许的损失类型
支持层次类型和数据排序标志的表达性数据图式化
后台复制和修复被删除的数据,无需人工干预
事务语义支持嵌套事务和快照/共享/排他级锁
事务可以影响许多 Cypress 对象并无限期持续
灵活的配额核算系统
Cypress 的核心是一个可复制且可横向扩展的主服务器,存储着关于 Cypress 树状结构的元数据,以及集群中所有表的块副本的组成和位置。主服务器以 Hydra 为基础实现为一个可复制状态机。Hydra 是一种类似 Raft 的专有共识算法。
Cypress 实现了一个具有容错能力的弹性数据层。下面将要介绍系统几乎所有方面都用到了这一层。
MapReduce 计算和通用调度器
尽管在人们的眼中,MapReduce 已不再是什么新技术,也没什么与众不同之处,但它在我们系统中的实现还是很值得关注的。我们仍然用它进行需要高吞吐量的 PB 级数据计算。
YTsaurus 中的 MapReduce 具有以下特点:
丰富的基本操作模型:经典的 MapReduce(具有不同的 Shuffle 策略并支持多阶段分区)、Map、Erase、Sort,以及一些考虑了输入数据“排序”的经典模型扩展。
计算可横向扩展:操作被划分成作业,在独立的服务器上运行。
单个操作可支持数十万个作业。
灵活的分层计算池模型可以提供即时和完整性保证,并可以在消费者之间公平地分配未充分利用的资源(无保证)。
向量资源模型支持按不同的比例申请不同的计算资源(CPU、RAM、GPU)。
使用Porto容器化机制按 CPU、RAM、文件系统和进程名称空间隔离在计算节点容器中执行的作业。
可扩展的调度程序可以为集群提供多达一百万个并发任务。
在进行更新或调度器节点出现故障时,几乎所有的计算进度都会保留。
YT 不仅支持执行 MapReduce 操作,还支持在集群上部署用户提供的任何代码。
对于副作用不明确的代码,YT 使用“普通(vanilla)”操作来运行。平台的许多其他组件也都用到了这个功能,下文会进行讨论。
动态 K-V 存储表
实际上,MapReduce 范式不适合构建响应时间低于秒级的交互式计算管道。问题不仅在于如何处理数据,还在于如何存储数据。
YT 的静态表就像 HDFS 中的一组文件,可以作为 MapReduce 计算的输入和输出。但是,它们不能用在交互式场景中,因为它们是与速度缓慢的持久存储介质绑定的。通常,对于交互式场景,应用程序会使用键值存储。键值存储可以横向扩展,并能提供低延迟的读写访问。
幸运的是,2014 年,我们开始在 YT 框架内开发动态表。它们部分基于 Apache HBase 模型,可以横向扩展,并使用分布式文件系统作为底层存储。不过,不同于 Apache HBase,动态表被有机地整合到了整个生态系统中:它们相当于 Cypress 的节点,可以用于许多需要静态表的场景。
例如,在 YT 中,你可以创建一个动态表作为 MapReduce 操作的结果,并将其用于基于键的快速搜索和插入。同时,你可以创建一个后台 MapReduce 进程,处理来自动态表的数据样本,并计算关于它的一些统计信息。
使用MVCC模型存储数据。用户可以通过键或时间戳查找值。
可扩展性:动态表会被划分成片(按键的范围划分),由单独的服务器提供服务。
事务性:动态表是 OLTP 存储,可以修改不同表不同分片中的多个行。
容错能力:提供分片服务的节点如果出现单点故障,那么分片会被移到另一个节点而不丢失数据。
隔离性:为了实现负载隔离,提供分片服务的节点会被分组成包,驻留在不同的机器上。
在单个键甚至单个值的层面上进行冲突检查。
热数据响应来自内存。
内置了类似 SQL 的语言,用于查询扫描和分析。
除了具有 K-V 存储接口的动态表外,系统还支持实现了消息队列抽象的动态表,即主题和流。你也可以把这些队列看成是表,因为它们由行组成,并且有自己的模式。在事务中,你可以同时修改 K-V 动态表和队列中的行。这样一来,你就可以基于 YT 的动态表构建具有 Exactly Once 语义的流处理。
YQL
YQL 是一种基于 SQL 的查询语言;它是 YT 之上构建的第一个高级原语。YQL 之于 YT 相当于 Hive 之于 Hadoop。这种技术让用户可以用 SQL 编写简单的查询,而不是自己编写代码构建一系列 MapReduce 操作。下面是一个例子:
SELECT region, AVG(age) AS avg_age_in_region, COUNT(DISTINCT ip) AS ips_countFROM `//home/production/users`GROUP BY regionORDER BY avg_age_in_region;
如今,许多大数据任务都可以表述为简单的 SQL 查询。没有 YQL,我们的生态系统就是不完整的。它是用于在大型数据集上进行即时分析和常规生产计算的最流行的工具之一。
YQL 有以下好处:
强大的图执行引擎,可以构建具有数百个节点的 MapReduce 管道,并可以在计算过程中进行调整。
通过将子查询存储在变量中,就可以使用 SQL 将复杂的数据处理管道构建成依赖查询和事务链。
任意复杂度的查询,其并行执行都是可预测的。
高效地实现连接、子查询和窗口函数,而且对它们的拓扑或嵌套没什么限制。
大量的函数库。
支持 C++、Python 和 JavaScript 自定义函数。
支持通过 CatBoost 和 TensorFlow 使用机器学习模型。
在准备好的计算实例上自动执行一小部分查询,绕过 MapReduce 以减少延迟。
CHYT
不用说,大多数读者朋友们都听说过 ClickHouse。2016 年,这个 DBMS 成为 Yandex 开源技术的先驱,并于 2021 年成为一家独立的公司 ClickHouse Inc.。
如今,ClickHouse 是最受欢迎的分析型数据库之一,它基于列的执行引擎非常高效,并集成了各种 BI 系统。ClickHouse 其中一个很好的特性是源代码中存储和计算部分实现了良好的隔离,这使得我们在 2018 年构建出了 CHYT——ClickHouse 计算引擎将 YTsaurus 作为存储集成。
在 YTsaurus 生态系统中,CHYT 提供了以下功能:
在 YT 中对静态表进行快速分析查询,延迟只有亚秒级。
重用 YTsaurus 集群中已有的数据,而无需将其复制到单独的 ClickHouse 集群。
能够通过 ClickHouse 的原生 ODBC 和 JDBC 驱动程序集成第三方可视化系统。
我注意到,集成是在相当低的层次上完成的。这让我们可以充分挖掘 YTsaurus 和 ClickHouse 的潜力,即:
支持读取静态和动态表。
部分支持 YTsaurus 事务模型。
支持分布式插入。
将 YTsaurus 内部格式的列式数据 CPU 高效地转换为内存中的 ClickHouse 表示。
主动数据缓存,在某些情况下,允许完全从实例内存中读取查询执行数据。
ClickHouse 服务器代码会在上述普通操作发生时运行,使用的计算资源与 MapReduce 计算相同。从这个意义上讲,YTsaurus 集群于我们内部的 CHYT 集群而言是一朵计算云。
这使得不同的用户或用户团队可以在单个 YT 集群上运行多个 CHYT 集群,彼此完全隔离,用和云类似的方式解决资源隔离问题。
SPYT
2019 年,Yandex 推出了 SPYT,这个系统将 Apache Spark 作为 YT 数据的计算引擎集成。与 CHYT 类似,普通 YTsaurus 操作为 Spark 集群提供计算资源。Apache Spark 的设计初衷就是为了方便连接第三方存储并将其作为数据源。
SPYT 在 YTsaurus 的生态系统中也是根深蒂固。得益于与第三方系统丰富的集成能力,它成了编写 ETL 工作流的主要方法之一。在底层,Spark 使用了一个灵活的分布式计算优化器,可以最大化中间数据的内存存储,并可以实现具有多个连接的计算管道。
各种 SDK
对于用特定语言编写的系统,SDK 通常是自动生成的或由用户社区的某个人编写的(长时间得不到维护)。但我们用当下流行的语言(C++、Python、Java、Go)开发了所有的 API。对于每一种 SDK,我们都仔细考虑了它与系统交互时的所有细微的不同之处。
因为可能存在网络故障和其他错误,所以我们用不同语言编写的客户端库都可以重试请求,包括读写大量数据。在创建每一种库时,我们都考虑了这门语言的特性,并尽可能使用这些特性来简化它与系统的交互。
Web 界面
对于一个有成千上万的用户使用的系统,必须要有一个用户友好的 Web 界面。而且,我们有意没有为用户和管理员创建单独的 Web 界面,这帮助我们避免了爱好者们匆忙创建 Web 管理界面的情况,那很常见:毕竟用户侧更重要,在管理员面前就没什么可尴尬的了。
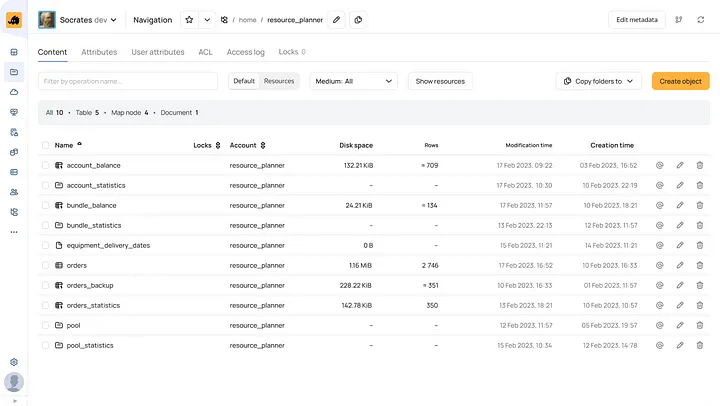
你可以通过 YTsaurus Web 界面完成以下工作:
通过 Cypress 浏览文件、表和其他对象。
创建、重命名或删除 Cypress 对象,并修改它们的属性。
执行和查看 MapReduce 计算。
跨所有引擎执行和查看 SQL 查询历史——YQL、CHYT、动态表 SQL。
管理系统:监控集群组件的运行状况,创建、删除或禁用用户,管理访问权限和配额,查看集群组件版本等。
技术层面看 YTsaurus
服务器端代码大部分都是用 C++编写的。我们喜欢这种语言,因为它的功能很丰富,用它编写的代码很高效。在开源发布 YTsaurus 之后,我们希望把大量的开发成果分享出来,或许你可以把它们作为单独的 C++原语来使用。
服务器端代码是使用 Clang 编译器和 CMake 构建系统构建的。
系统的个别部分是用 Go、Python 和 Java 编写的。还有一个 API,让你可以使用上述 4 种编程语言开发与 YTsaurus 交互的应用程序。
代码库会自动与内部存储库同步。因此,外部总是可以获得 YTsaurus 的最新版本。
YTsaurus 在 x86-64 Linux 服务器上运行。
部署和管理
在 Yandex,我们安装了超过 20 套 YTsaurus。它们的规模和配置差异很大,从单集群 5 台主机到 20K+不等。YTsaurus 还集成了几个内部 Yandex 系统,包括身份验证、访问控制、审计、监控、硬件管理和容器编排。所有这些系统最大限度地减少了管理集群的工作量。
为了方便用户,我们投资开发了二级操作符,用于在 Kubernetes 中自动部署 YTsaurus 集群,并支持标准的升级机制,可以在停机状态下升级到新版本。该操作符让你可以在几分钟内把 YTsaurus 集群部署到 Minikube、公有云或本地 Kubernetes 上。
通过修改元数据树(Cypress)中的系统节点,可以动态地管理集群配置。使用基本的 Cypress 命令(如 list、get、set 和 remove),你可以创建帐户、添加用户或计算池、授予目录访问权限或退役集群节点。
特别值得注意的是动态配置各个组件的能力:通过修改特定属性,你可以调整缓存大小、心跳周期或节点上的日志记录设置。
YTsaurus 是一个计算平台,因此,用户代码的执行是隐式的。为了运行和隔离不受信任的代码,YTsaurus 使用了 Yandex 开发的容器化系统Porto。为了在多租户集群中实现完全的用户隔离,建议将 Porto 安装为Kubernetes CRI。这可以充分释放 YTsaurus 作业隔离和在不同操作中使用自定义环境的能力。
当然,如果没有可观测性工具——日志记录、定量监测和跟踪,运营大型分布式系统是不可能的。YTsaurus 会生成结构化日志,用于审计和监控用户操作,并且提供了详细的调试日志,用于更深层次的问题诊断。此外,该系统支持 Prometheus 格式的指标导出,并通过 Jaeger gRPC 协议进行链路追踪。
基于 YTsaurus 可以构建什么?
让我们通过几个例子看一下 Yandex 是如何使用这个系统的。
YTsaurus 最具启发性、最典型的用例之一是创建 DWH。例如,来自 Yandex Taxi、Yandex Eats、Yandex Deli 和 Yandex Delivery 的订单以原始格式以最小的延迟接收到 YTsaurus 动态表中。每月的数据量可达数百 TB。
然后,我们用各种工具处理订单,例如,大多数分析型数据集市是通过 YQL 和 SPYT 进行准备的。数据总量超过 6PB。CHYT 用于即时分析,各种可视化则在 Yandex DataLens 中创建。Yandex 的其他服务中也存在类似的用例,如 Yandex Market、Yandex Music 和 Yandex Travel。
还有一些非常具体的用例。例如,Yandex所有的三台超级计算机都由 YTsaurus 调度程序管理。许多具有不同类型 GPU 的节点连接到 YT,并分布在不同的池树中。这使得用户可以显式指定所需的 GPU 模型,并使用存储在 YTsaurus 中的数据。
目前,YTsaurus 动态表存储的数据达 PB 级,大量的交互服务都以它们为基础构建。Yandex 广告团队是最大的内部客户之一。在 HighLoad++ 2022 大会上,我的同事们探讨了他们在 YTsaurus 上构建交互式流处理的方法。
结语
YTsaurus 是一个有着丰富历史的大工程。如果你感兴趣,就请看一看 YTsaurus,找一些对自己有用的东西。也许你会喜欢我们在代码中实现的技术解决方案,或者找个机会部署 YTsaurus 并实际地试用一下。
如果你感兴趣并想帮助我们开发这个系统,那就太好了。欢迎通过Telegram聊天室进行反馈,或者发起 pull 请求。
延伸阅读:




